







1 Master启动流程
1、在start-master.sh脚本中调用Mater.scala中的main方法
2、在main方法中封装spark参数,并调用startRpcEnvAndEndpoint()创建RpcEnv
3、在startRpcEnvAndEndpoint中创建RpcEnv(AkkaSystem),创建masterEndPoint(actor),new Master(),实例化Master
4、实例化Master后会调用Master的Onstart()方法
5、在onStart()中启动webinfo,然后通过定时器循环发送消息给自己
self.send(CheckForWorkerTimeOut),通过case object执行
6、在case Object中调用timeOutDeadWorker(),检查超时的work
7、在timeOutDeadWorker()中检查超时的worker,调用removeWorker(worker)删除节点,原理就是修改3个集合,其中,会对每个节点尝试15次检查。
8、master启动完成后,在recive()方法中定义大量的case object,等待接受其他actor的请求
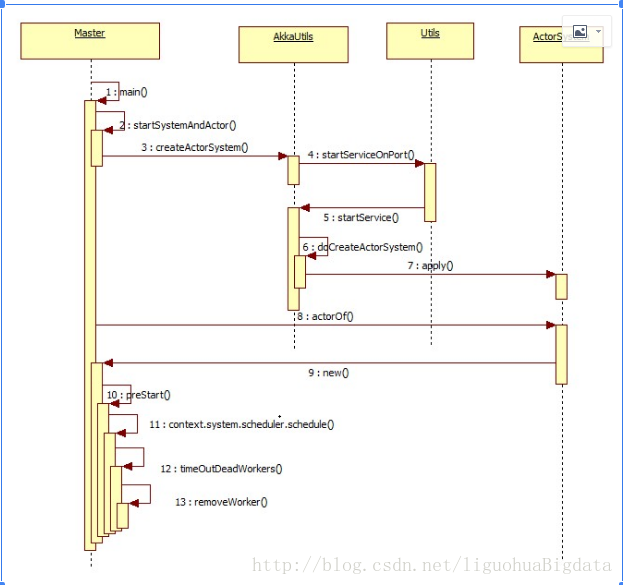
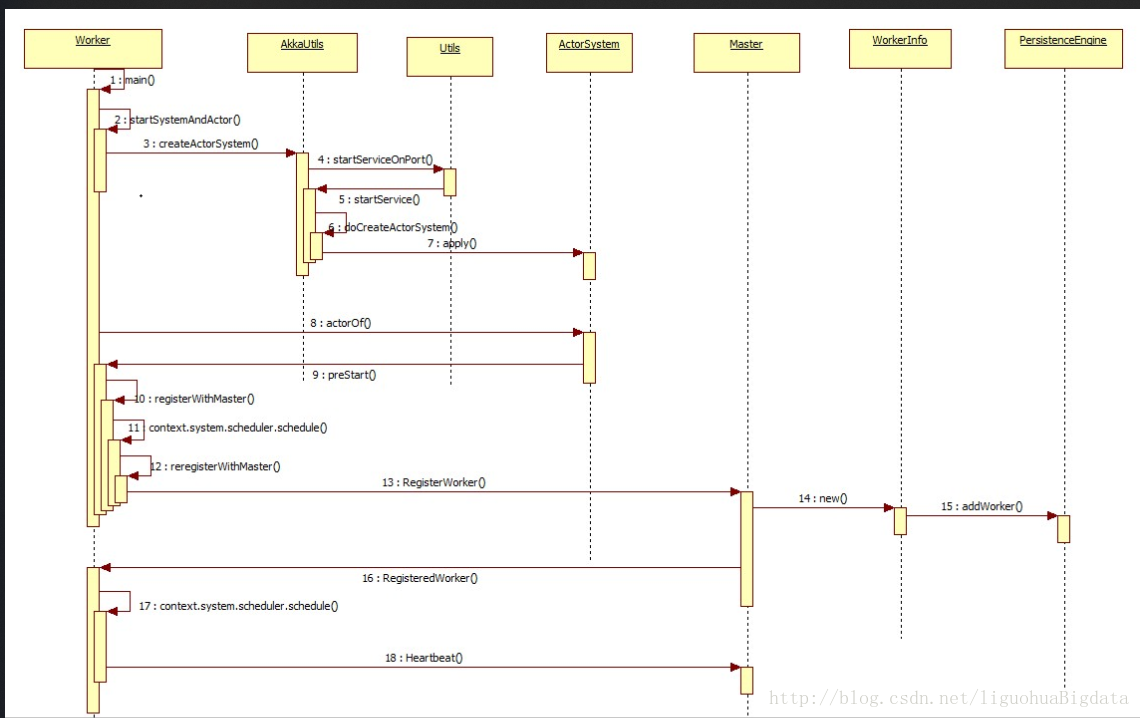
2 worker启动流程
- 在worker启动时,通过脚本start-slave.sh脚本中调用main()
- 在main()中封装参数,调用startRpcEnvAndEndpoint()创建RpcEnv
- 在startRpcEnvAndEndpoint()中创建RpcEnv和endpiont,并实例化Worker,执行Worker的onStart()方法
- 在onStart()方法中主要流程:
a. 创建工作目录
b. 启动shuffleservice
c. 创建worker webui
d. 调用registerWithMaster()向master注册worker - 在registerWithMaster()方法中”
a. 首先worker回向master注册自己
b. 其次会启动定时任务,不断的向自己发送caseclass,调用reregisterWithMaster() - 在reregisterWithMaster()方法中,如果之前的注册失败,会重复(15、16次)注册自己
- 如果在registerWithMaster()中注册成功,master会向worker发送case object RegisteredWorker,worker接收到消息后,会定时向master发送心跳
- master接收到心跳信息后,会修改worker的上次心跳时间
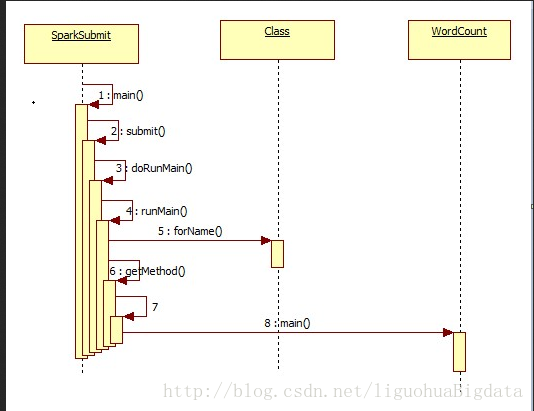
3 任务启动流程submit
- 在脚本spark-submit中调用SparkSubmit的main方法
- 在main方法中执行如下:
a. 获取提交参数,繁琐就打印
b. 通过提交的action匹配是什么行为
c. 如果是提交任务,执行submit(args)方法 - 在submit(args)方法中执行如下:
a. 准备运行环境
b. 定义doRunMain()方法
i. 调用runmain()方法,执行用户提交主类的main()方法
c. 调用doRunMain()方法
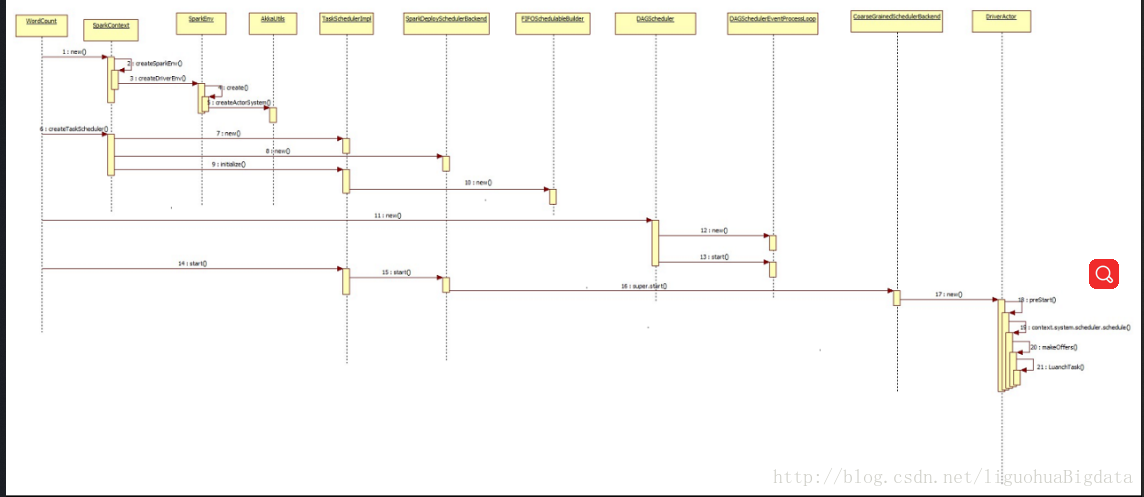
4 任务提交流程
- 在任务启动时,sparksubmit已经通过反射的方式调用了用户提交任务的主类中的main方法,所以,本节以wordcount为例讲解
- 在wordcount中主要由以下几步:
a. 创建SparkConf,设置名字
b. 创建SparkContent,书写程序
c. 程序逻辑,启动任务
d. 停止任务 - 所以最重要的源码分析应该在new SparkContent()这个步骤里
a. 在281行定义了createSparkEnv()方法,用来创建sparkEnv,但是还没
b. 在526行定义了createTaskScheduler()方法,创建了taskscheduler
i. 匹配master的模式,SPARK_REGEX(sparkUrl)为standalone模式
ii. 创建TaskSchedulerImpl - 定义initialize()方法,接受参数为SchedulerBackend;逻辑中定义调度器类型(默认是FIFO),在创建rootPool等
- 定义start()方法,创建executor的通信actor
iii. 创建SparkDeploySchedulerBackend()
iv. 执行TaskSchedulerImpl 的initialize方法,将SparkDeploySchedulerBackend最为参数传入
v. 返回SparkDeploySchedulerBackend和TaskSchedulerImpl
c. 在529行new DAGScheduler(this),创建了DAGScheduler
i. new DAGSchedulerEventProcessLoop() - 定义inRecive()方法,调用doOnRecive()方法
- 定义doOnRecive()方法中匹配任务方式
a. 匹配JobSubmit,调用dagScheduler.handleJobSubmitted()
ii. 在new DAGScheduler()最后一行,1473行调用eventProcessLoop.start() - 调用父类EventLoop的start()方法
a. 在父类的start()方法中,调用onStart()方法
b. 然后调用线程eventThread()的start()方法
c. 启动线程的run()方法
i. 从队列中获取事件
ii. 回调DAGSchedulerEventProcessLoop的onRecive()方法处理事件
d. 调用TaskSchedulerImpl 的start()方法
i. 调用子类SparkDeploySchedulerBackend的start方法,因为在init方法中已经传入了子类
ii. 在SparkDeploySchedulerBackend的start方法中: - 调用父类CoarseGrainedSchedulerBackend的start方法
a. 注册driverEndPoint
b. new DriverEndPoint()
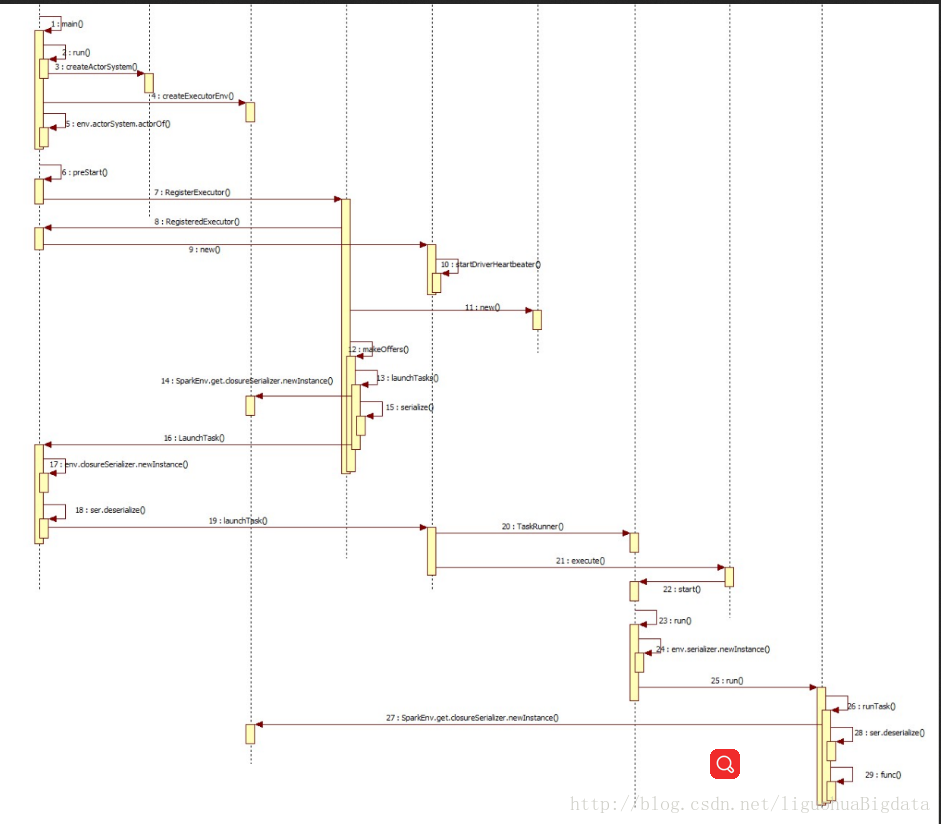
i. 执行onstart() - 定期接收任务,向自己发送ReviveOffers的case object
- 调用makeOffers()方法
- 在makeOffers()方法中,调用launchTask()
- 在launchTask()中,判断集群是否有资源,决定是否发送任务
- 发送任务到CoarseGrainedExecutorBackend
- 在 CoarseGrainedExecutorBackend中提交任务
- 创建AppClient()
a. 创建ClientEndPoint,用于和master通信 - 调用AppClient的start()方法,创建AppClient的endpoint
5 Executor启动和任务处理流程
- 在创建taskScheduler的时候SparkContext.createTaskScheduler(this, master),进行了 new SparkDeploySchedulerBackend()的步骤,在SparkDeploySchedulerBackend的84行,执行了app运行使用的调度器为CoarseGrainedExecutorBackend
val command = Command("org.apache.spark.executor.CoarseGrainedExecutorBackend", //-----------指定调用的executor是哪个- 在下面的new AppClient()中,有传入commond
- 查看AppClient的onStart()方法,调用了registerWithMaster(),然后调用了tryRegisterAllMasters()方法
- 在tryRegisterAllMasters()方法中向master发送了消息RegisterApplication(appDescription, self)
- master接收到消息后,向appclient发送消息RegisteredApplication,监听任务运行状态,然后调用schedule()方法
- 在schedule()方法中调用startExecutorOnWorks()方法,在worker上调度和启动executor,在此方法中计算每个worker上可用的资源,并且分配每个worker上需要启动的资源,调用allocateWorkerResourceExecutor方法启动executor
- allocateWorkerResourceExecutor方法中,调用lauchExecutor()方法,启动executor
向worker发送消息,启动executor,向appclient发送消息,改变executor的状态















 682
682

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









