









目录
1 服务搜索
1.1 需求分析
服务搜索的入口有两处:
-
在门户最上端的搜索入口对服务信息进行搜索。


-
在门户最下方点击“全部服务”进入全部服务界面。
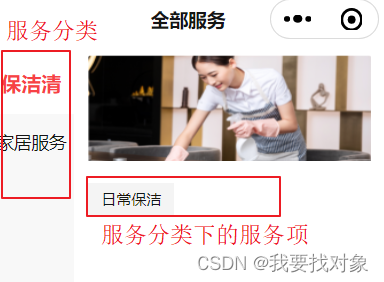
如下图:
点击服务分类查询分类下的服务。
1.2 技术方案
1.2.1 使用Elasticsearch进行全文检索(为什么数据没有那么多还要用ES?)
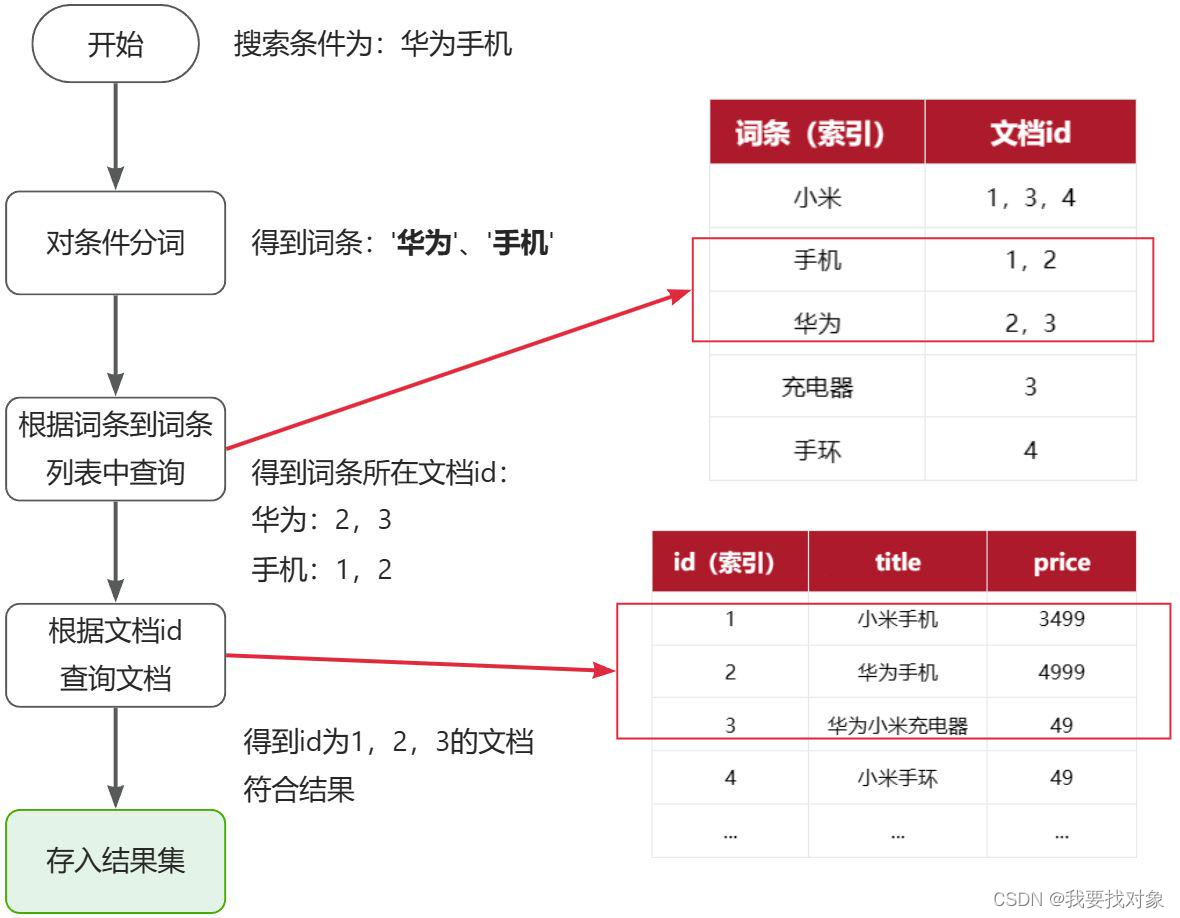
根据需求分析,对服务进行搜索除了根据服务类型查询其下的服务以外还需要根据关键字去搜索与关键字匹配的服务
通过关键字去匹配服务的哪些信息呢?比如:输入关键字“家庭保洁”,它会去匹配服务相关的信息,比如:服务类型的名称、服务项的名称,甚至根据需要也可能去匹配服务介绍的信息,只要与“家庭保洁”相关的服务都会展示出来。如下效果:
![[图片]](https://img-blog.csdnimg.cn/direct/9cbcde1549b440259ad87fb61f52477b.png#pic_center)
这里最关键的是根据关键字去匹配,使用数据库的like搜索能否实现呢?
上图的搜索效果是一种全文检索方式,在搜索“家庭保洁”关键字时会对关键字先分词,分为“家庭”和“保洁”,再根据分好的词去匹配索引库中的服务类型的名称、服务项的名称、服务项的描述等字段。Like搜索不具有分词功能,它不是一种全文检索的方式。
用Mysql不行吗?行,但是c端用户肯定访问量很大,这样做会增加数据库压力
如果要实现全文检索且对接口性能有一定的要求,最常用的是Elasticsearch,本项目使用ES完成服务搜索功能的开发。
复习下:
1.2.2 索引同步方案
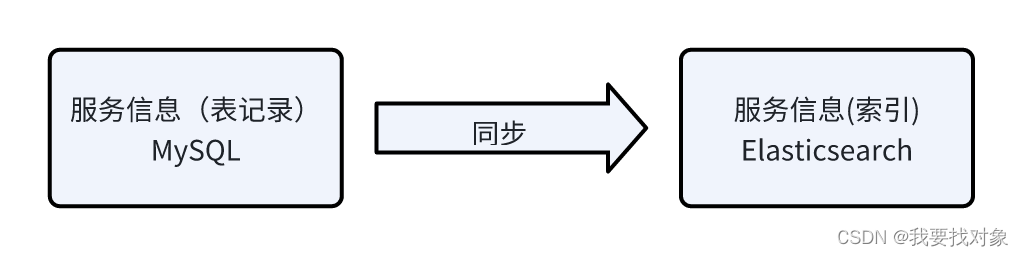
如果要使用ES去搜索服务信息需要提前对服务信息在ES中创建索引,运营端在管理服务时是将服务信息保存在数据库,如何对数据库中的服务信息去创建索引,保证数据库中的信息与ES的索引信息同步呢,本节对索引同步的方案进行分析与确定。
想到同步最简单的就是
在服务项的增删改查Service方法中添加维护ES索引的代码。
在区域服务的增删改查Service方法中添加维护ES索引的代码。
例如下边的代码:
public Serve onSale(Long id){
//操作serve表
//添加向ES创建索引的代码
}
上边的代码存在分布式事务,比如:向ES写成功了由于网络问题抛出网络超时异常,最终数据库操作回滚了ES操作没有回滚,数据库的数据和ES中的索引不一致。所以肯定不用这种同步的方法,那就用异步。
使用Canal+MQ
1.2.2.1 Canal介绍
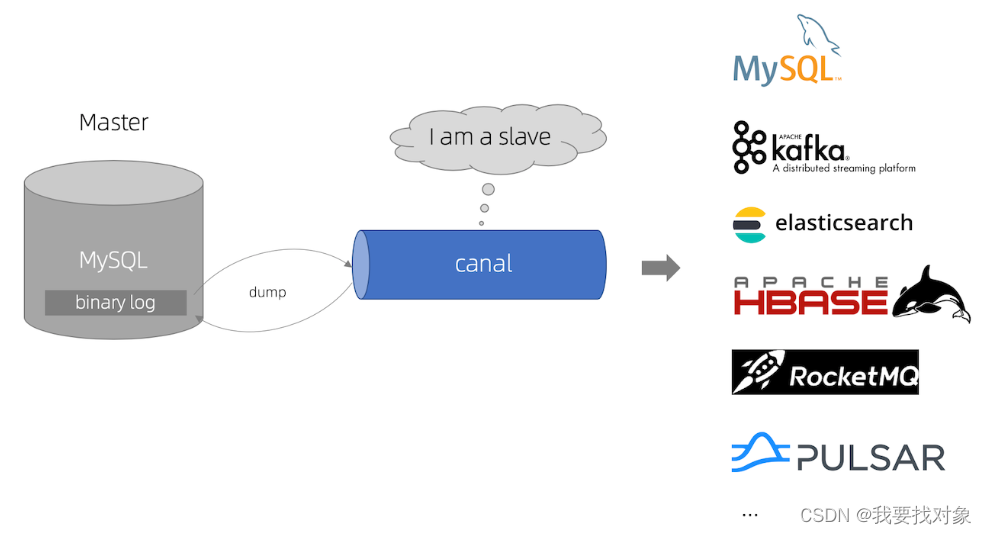
Canal是什么?
Canal可与很多数据源进行对接,将数据由MySQL同步到ES、MQ、DB等各个数据源。
官方文档:https://github.com/alibaba/canal/wiki
1.2.2.1 Canal工作原理
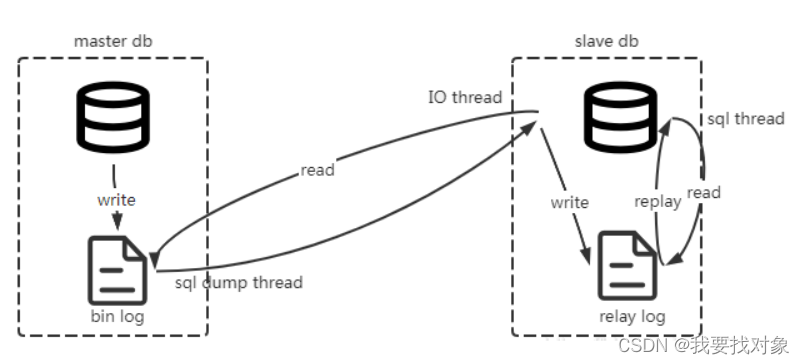
理解Canal的工作原理需要首先要知道MySQL主从数据同步的原理
MySQL主从集群由MySQL主服务器(master)和MySQL从服务器(slave)组成,MySQL主从数据同步是一种数据库复制技术,进行写数据会先向主服务器写,写成功后将数据同步到从服务器,流程如下:
1、主服务器将所有写操作(INSERT、UPDATE、DELETE)以二进制日志(binlog)的形式记录下来。
2、从服务器连接到主服务器,发送dump 协议,请求获取主服务器上的binlog日志。
MySQL的dump协议是MySQL复制协议中的一部分。
3、MySQL master 收到 dump 请求,开始推送 binary log 给 slave
4、从服务器解析日志,根据日志内容更新从服务器的数据库,完成从服务器的数据保持与主服务器同步。
那么回到原来的话题,Canal在整个过程充当什么角色呢?
1、Canal模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
MySQL的dump协议是MySQL复制协议中的一部分。
2、MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
。一旦连接建立成功,Canal会一直等待并监听来自MySQL主服务器的binlog事件流,当有新的数据库变更发生时MySQL master主服务器发送binlog事件流给Canal。
3、Canal会及时接收并解析这些变更事件并解析 binary log
通过以上流程可知Canal和MySQL master主服务器之间建立了长连接。
简单来所就是,Canal充当从节点,监听mysql并获取mysql的binlog日志,之后解析这个binlog日志
本方案需要借助Canal和消息队列,具体实现方案如下:
通过上边的技术分析下边对本项目服务搜索方案进行总结。
本项目使用Elasticsearch实现服务的搜索功能,使用Canal+MQ完成服务信息与ES索引同步。
如下图:
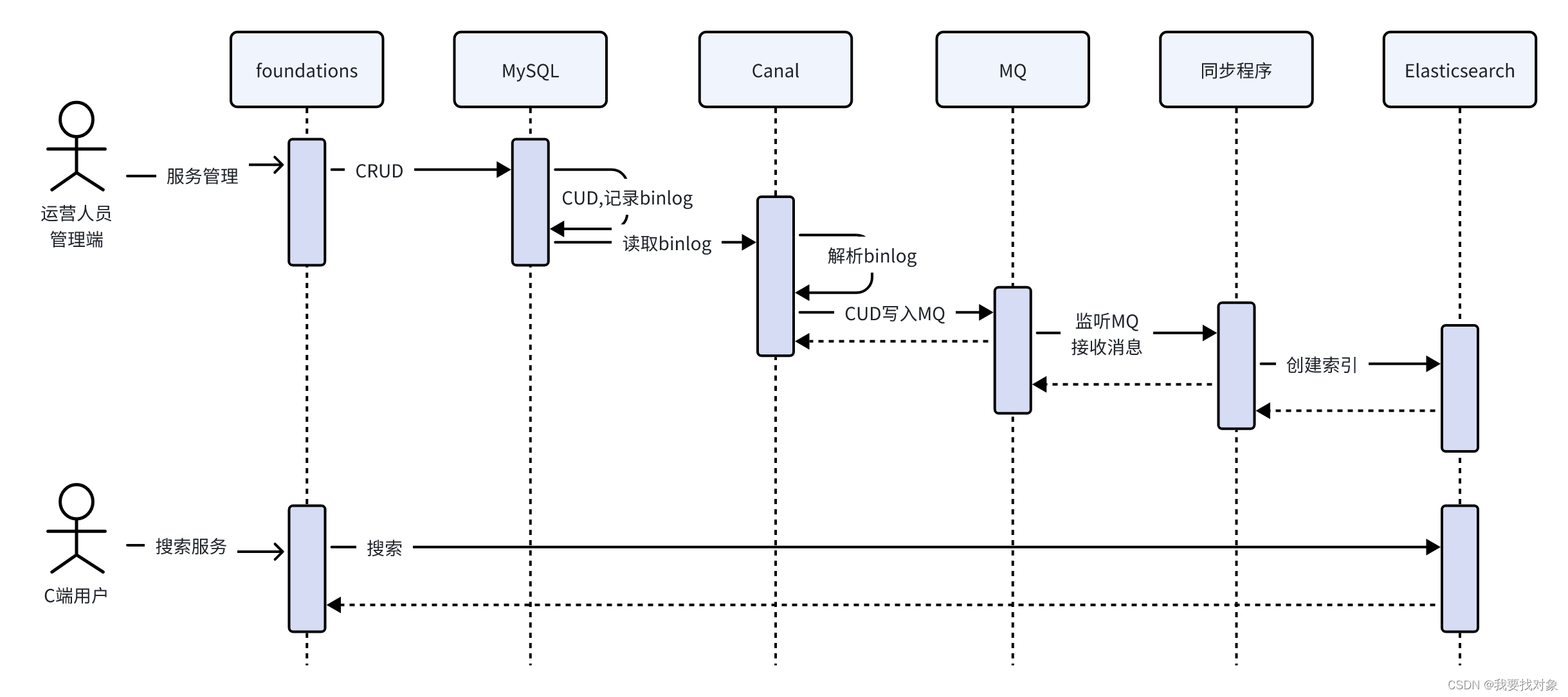
流程如下:
运营人员对服务信息进行增删改操作,MySQL记录binlog日志。
Canal定时读取binlog 解析出增加、修改、删除数据的记录。
Canal将修改记录发送到MQ。
同步程序监听MQ,收到增加、修改、删除数据的记录,请求ES创建、修改、删除索引。
C端用户请求服务搜索接口从ES中搜索服务信息。
1.2.3 MQ技术方案
1.2.3.1 保证生产消息可靠性
1. 首先发送消息的方法如果执行失败会进行重试,重试次数耗尽记录失败消息
RabbitMQ提供生产者确认机制保证生产消息的可靠性,技术方案如下 :
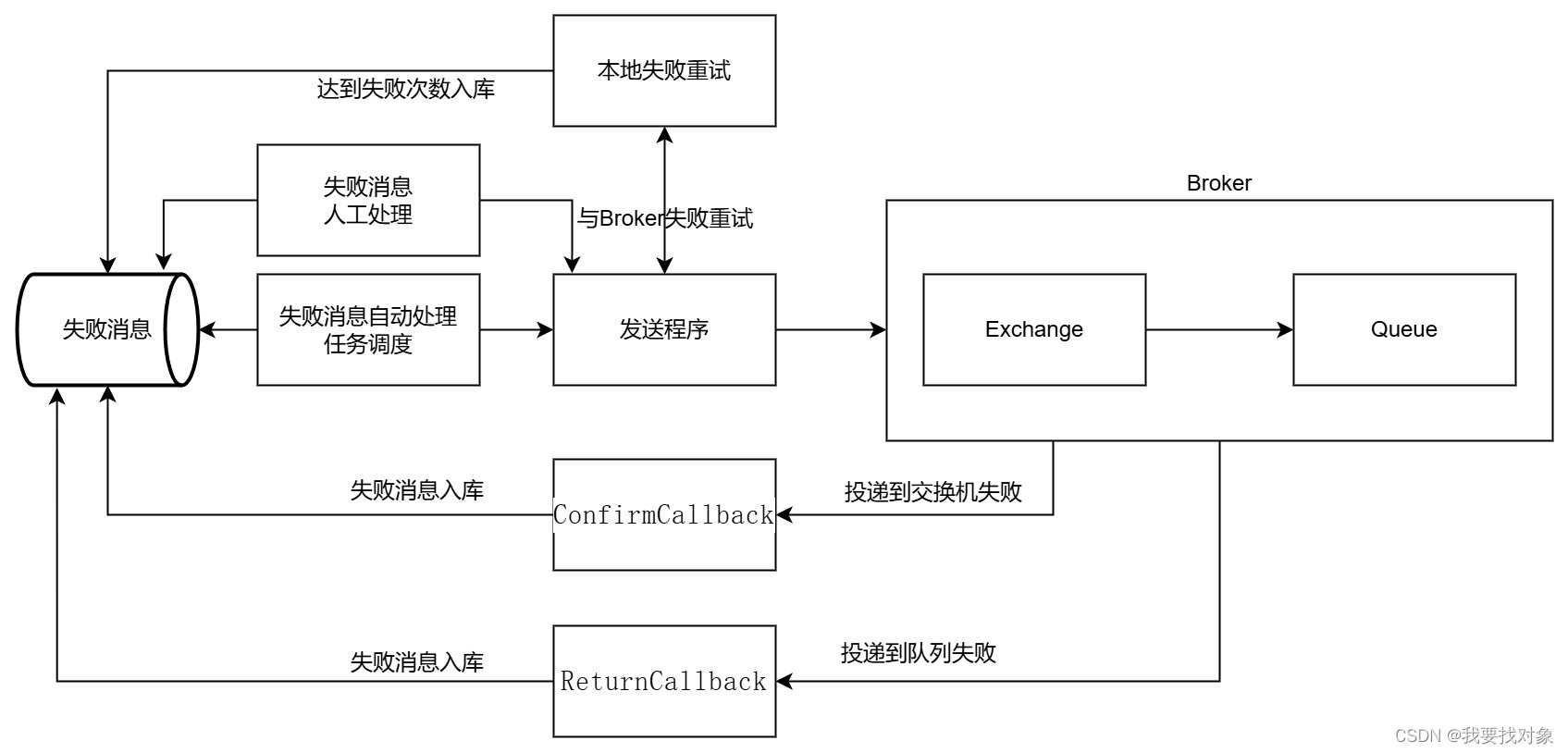
简单来说就是如果消息提交到交换机失败,则重拾几次,如果还是不行,就归档失败消息,下面是实现代码:
@Retryable(value = MqException.class, maxAttempts = 3, backoff = @Backoff(value = 3000, multiplier = 1.5), recover = "saveFailMag")
下面就是将MQ异常消息记录到数据库:
/**
* @param mqException mq异常消息
* @param exchange 交换机
* @param routingKey 路由key
* @param msg mq消息
* @param delay 延迟消息
* @param msgId 消息id
*/
@Recover
public void saveFailMag(MqException mqException, String exchange, String routingKey, Object msg, Integer delay, String msgId) {
//发送消息失败,需要将消息持久化到数据库,通过任务调度的方式处理失败的消息
failMsgDao.save(mqException.getMqId(), exchange, routingKey, JsonUtils.toJsonStr(msg), delay, DateUtils.getCurrentTime() + 10, ExceptionUtil.getMessage(mqException));
}
如果还是不行,就人工处理
2. 通过MQ的提供的生产者确认机制保证生产消息的可靠性
使用生产者确认机制需要给每个消息指定一个唯一ID,生产者确认机制通过异步回调的方式进行,包括ConfirmCallback和Return回调。
ConfirmCallback:消息发送到Broker会有一个结果返回给发送者表示消息是否处理成功:
1)消息成功投递到交换机,返回ack
2)消息未投递到交换机,返回nack
具体实现如下,在发送消息时指定回调对象:
// 1.4.构建回调
RabbitMqListenableFutureCallback futureCallback = RabbitMqListenableFutureCallback.builder()
.exchange(exchange)
.routingKey(routingKey)
.msg(jsonMsg)
.msgId(msgId)
.delay(delay)
.isFailMsg(isFailMsg)
.failMsgDao(failMsgDao)
.build();
// 1.5.CorrelationData设置
CorrelationData correlationData = new CorrelationData(msgId.toString());
correlationData.getFuture().addCallback(futureCallback);
回调类中回调方法源代码:
@Override
public void onSuccess(CorrelationData.Confirm result) {
if(failMsgDao == null){
return;
}
if(!result.isAck()){
// 执行失败保存失败信息,如果已经存在保存信息,如果不在信息信息
failMsgDao.save(msgId, exchange, routingKey, msg, delay,DateUtils.getCurrentTime() + 10, "MQ回复nack");
}else if(isFailMsg && msgId != null){
// 如果发送的是失败消息,当收到ack需要从fail_msg删除该消息
failMsgDao.removeById(msgId);
}
}
如果没有返回ack则将消息记录到失败消息表,如果经过重试后返回了ack说明消息发送成功,此时将消息从失败消息表删除。
Return回调:如果消息发送到交换机成功了但是并没有到达队列,此时会调用ReturnCallback回调方法,在回调方法中我们可以收到失败的消息存入失败消息表以便进行补偿。
要使用Return回调需要开启设置:
首先在shared-rabbitmq.yaml中配置rabbitMQ参数,如下:
spring:
rabbitmq:
publisher-confirm-type: correlated
publisher-returns: true
template:
mandatory: true
说明:
publish-confirm-type:开启publisher-confirm,这里支持两种类型:
simple:同步等待confirm结果,直到超时
correlated:异步回调,定义ConfirmCallback,MQ返回结果时会回调这个ConfirmCallback
publish-returns:开启publish-return功能,同样是基于callback机制,不过是定义ReturnCallback
template.mandatory:定义消息路由失败时的策略。true,则调用ReturnCallback;false:则直接丢弃消息
写入失败消息表的逻辑:
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
// 获取RabbitTemplate
RabbitTemplate rabbitTemplate = applicationContext.getBean(RabbitTemplate.class);
//定义returnCallback回调方法
rabbitTemplate.setReturnsCallback(
new RabbitTemplate.ReturnsCallback() {
@Override
public void returnedMessage(ReturnedMessage returnedMessage) {
byte[] body = returnedMessage.getMessage().getBody();
//消息id
String messageId = returnedMessage.getMessage().getMessageProperties().getMessageId();
String content = new String(body, Charset.defaultCharset());
log.info("消息发送失败,应答码{},原因{},交换机{},路由键{},消息id{},消息内容{}",
returnedMessage.getReplyCode(),
returnedMessage.getReplyText(),
returnedMessage.getExchange(),
returnedMessage.getRoutingKey(),
messageId,
content);
if (failMsgDao != null) {
failMsgDao.save(NumberUtils.parseLong(messageId), returnedMessage.getExchange(), returnedMessage.getRoutingKey(), content, null, DateUtils.getCurrentTime(), "returnCallback");
}
}
}
);
}
1.2.3.2 保证消费消息可靠性
首先设置消息持久化,保证消息发送到MQ消息不丢失。具体需要设置交换机和队列支持持久化,发送消息设置deliveryMode=2。消息持久化:
// 1.6.构造消息对象
Message message = MessageBuilder.withBody(StrUtil.bytes(jsonMsg, CharsetUtil.CHARSET_UTF_8))
//持久化
.setDeliveryMode(MessageDeliveryMode.PERSISTENT)
//消息id
.setMessageId(msgId.toString())
.build();
RabbitMQ是通过消费者回执来确认消费者是否成功处理消息的:消费者获取消息后,应该向RabbitMQ发送ACK回执,表明自己已经处理完成消息,RabbitMQ收到ACK后删除消息。
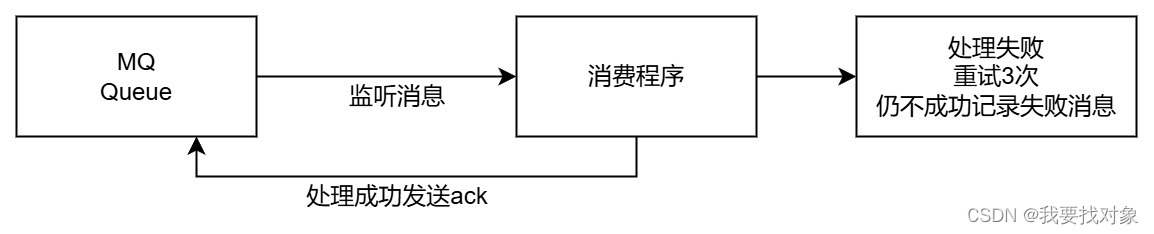
消费消息失败重试3次,仍失败则将消费失败的消息入库。
通过任务调度扫描失败消息表重新发送,达到一定的次数还未成功则由人工处理。
RabbitMQ提供三个确认模式:
•manual:手动ack,需要在业务代码结束后,调用api发送ack。
•auto:自动ack,由spring监测listener代码是否出现异常,没有异常则返回ack;抛出异常则返回nack
•none:关闭ack,MQ假定消费者获取消息后会成功处理,因此消息投递后立即被删除
由此可知:
- none模式下,消息投递是不可靠的,可能丢失
- auto模式类似事务机制,出现异常时返回nack,消息回滚到mq;没有异常,返回ack
- manual:自己根据业务情况,判断什么时候该ack
在shared-rabbitmq.yaml中配置:
spring:
rabbitmq:
....
listener:
simple:
acknowledge-mode: auto #,出现异常时返回nack,消息回滚到mq;没有异常,返回ack
retry:
enabled: true # 开启消费者失败重试
initial-interval: 1000 # 初识的失败等待时长为1秒
multiplier: 10 # 失败的等待时长倍数,下次等待时长 = multiplier * last-interval
max-attempts: 3 # 最大重试次数
stateless: true # true无状态;false有状态。如果业务中包含事务,这里改为false
本项目使用自动ack模式,当消费消息失败会重试,重试3次如果还失败会将消息投递到失败消息队列,由定时任务程序定时读取队列的消息,达到一定的次数还未成功则由人工处理。
1.2.3.2 保证消息幂等性
什么是幂等性?
幂等性是指不论执行多少次其结果是一致的。
通过以上分析进行总结:
1、使用数据库的唯一约束去控制。
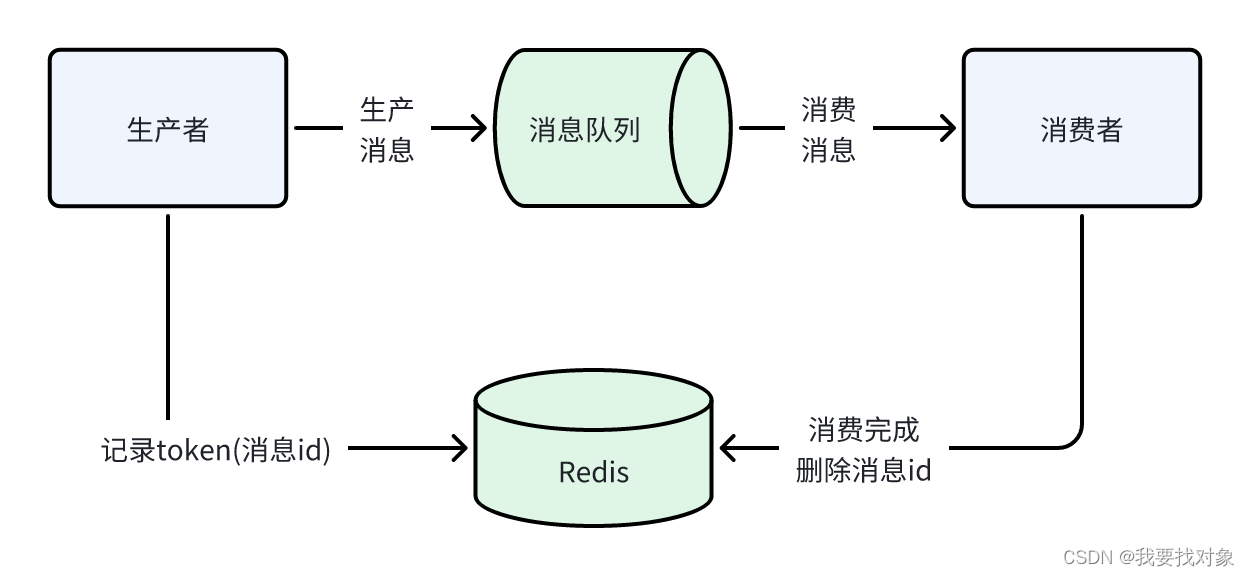
2、使用token机制,如下:
消息具有唯一的ID
发送消息时将消息ID写入Redis
消费时根据消息ID查询Redis判断是否已经消费,如果已经消费则不再消费。
1.2.4 配置数据同步环境
1.2.4.1 Canal+MQ同步流程
下边回顾Canal的工作原理
1、Canal模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
MySQL的dump协议是MySQL复制协议中的一部分。
2、MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
。一旦连接建立成功,Canal会一直等待并监听来自MySQL主服务器的binlog事件流,当有新的数据库变更发生时MySQL master主服务器发送binlog事件流给Canal。
3、Canal会及时接收并解析这些变更事件并解析 binary log
通过以上流程可知Canal和MySQL master主服务器之间建立了长连接。
基于Canal+MQ数据同步流程: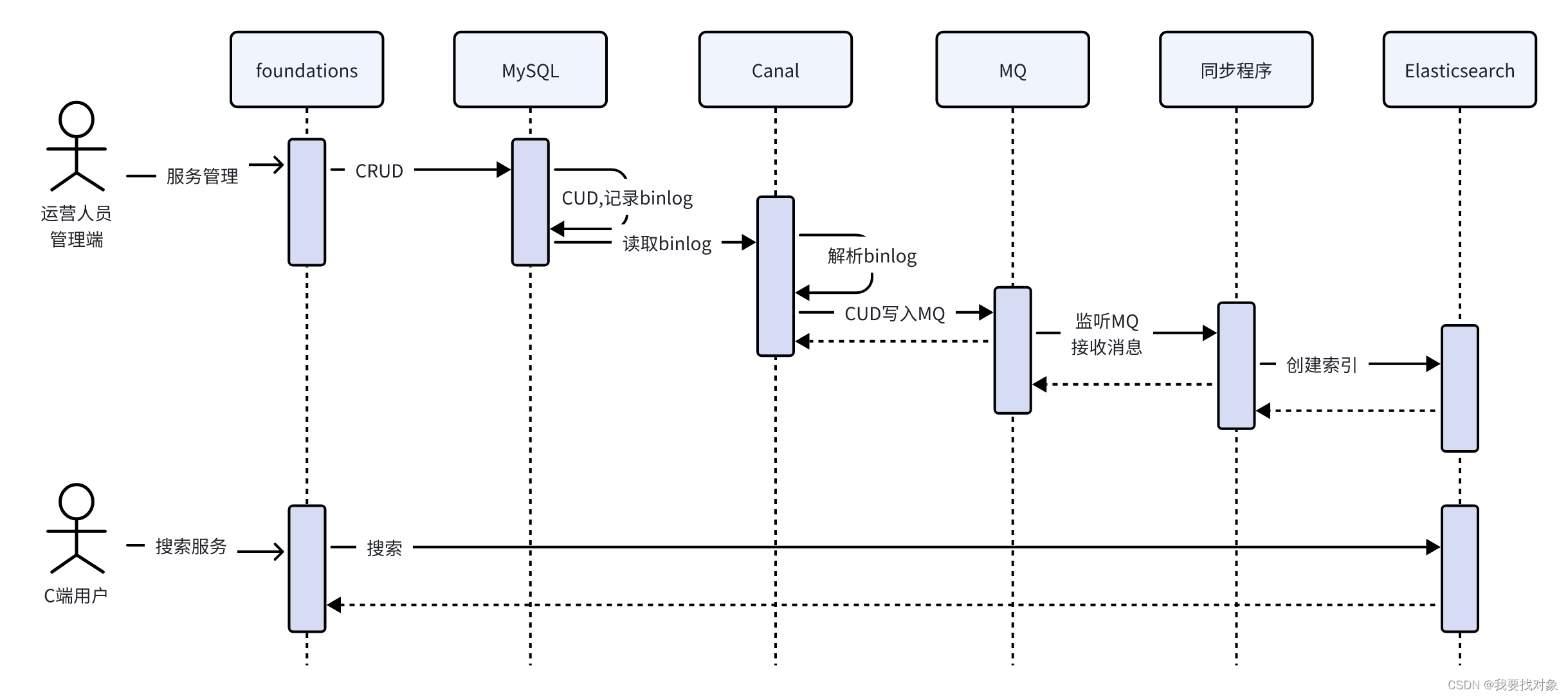
- 服务管理不仅向serve、serve_item、serve_type表写数据,同时也向serve_sync表写数据,serve_sync用于Canal同步数据使用。
- 向serve_sync写数据产生binlog
- Canal请求读取binlog,并解析出serve_sync表的数据更新日志,并发送至MQ的数据同步队列。
- 异步同步程序监听MQ的数据同步队列,收到消息后解析出serve_sync表的更新日志。
- 异步同步程序根据serve_sync表的更新日志请求Elasticsearch添加、更新、删除索引文档。
最终实现了将MySQL中的serve_sync表的数据同步至Elasticsearch
1.2.4.2 配置Canal+MQ数据同步环境
根据Canal+MQ同步流程,下边进行如下配置:
- 配置Mysql主从同步,开启MySQL主服务器的binlog
- 安装Canal并配置,保证Canal连接MySQL主服务器成功
- 安装RabbitMQ,并配置同步队列。
- 在Canal中配置RabbitMQ的连接信息,保证Canal收到binlog消息写入MQ
对于异步程序监听MQ通过Java程序中实现。
配置Mysql主从同步
1.在MySQL中需要创建一个用户,并授权
进入mysql容器:
docker exec -it mysql /bin/bash
– 使用命令登录:
mysql -u root -p
– 创建用户 用户名:canal 密码:canal
create user 'canal'@'%' identified WITH mysql_native_password by 'canal';
– 授权 *.*表示所有库
GRANT SELECT,REPLICATION SLAVE,REPLICATION CLIENT ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;
- SELECT: 允许用户查询(读取)数据库中的数据。
- REPLICATION SLAVE: 允许用户作为 MySQL 复制从库,用于同步主库的数据。
- REPLICATION CLIENT: 允许用户连接到主库并获取关于主库状态的信息。
在MySQL配置文件my.cnf设置如下信息,开启 Binlog 写入功能,配置 binlog-format 为 ROW 模式
ROW 模式表示以行为单位记录每个被修改的行的变更
修改如下:
vi /usr/mysql/conf/my.cnf
[mysqld]
#打开binlog
log-bin=mysql-bin
#选择ROW(行)模式
binlog-format=ROW
#配置MySQL replaction需要定义,不要和canal的slaveId重复
server_id=1
expire_logs_days=3
max_binlog_size = 100m
max_binlog_cache_size = 512m
2、重启MySQL,查看配置信息
- 使用命令查看是否打开binlog模式:
SHOW VARIABLES LIKE ‘log_bin’;

ON表示开启binlog模式。
show variables like ‘binlog_format’;
![[图片]](https://img-blog.csdnimg.cn/direct/08490ff7bf3847819fa486f7c113e8d5.png)
当 binlog_format 的值为 row 时,表示 MySQL 服务器当前配置为使用行级别的二进制日志记录,这对于数据库复制和数据同步来说更为安全,因为它记录了对数据行的确切更改。
-
查看binlog日志文件列表:
SHOW BINARY LOGS;
![[图片]](https://img-blog.csdnimg.cn/direct/4acf08bd04a4469ba6a1afe87302fb92.png)
-
查看当前正在写入的binlog文件:
SHOW MASTER STATUS;
![[图片]](https://img-blog.csdnimg.cn/direct/923cb94c5a2a4e5cb7f22aeadbc63b8b.png)
配置Canal+RabbitMQ
首先注意配置canal.properties,注意修改mq的配置信息:
........
rabbitmq.host = 192.168.101.68
rabbitmq.virtual.host = /xzb
rabbitmq.exchange = exchange.canal-jzo2o
rabbitmq.username = xzb
rabbitmq.password = xzb
rabbitmq.deliveryMode = 2
创建instance.properties,内容如下:
canal.instance.master.journal.name 用于指定主库正在写入的 binlog 文件的名称。
如果不配置 canal.instance.master.journal.name,Canal 会尝试自动检测 MySQL 主库的 binlog 文件,并从最新位置开始进行复制。
#################################################
## mysql serverId , v1.0.26+ will autoGen
canal.instance.mysql.slaveId=1000
# enable gtid use true/false
canal.instance.gtidon=false
# position info
canal.instance.master.address=192.168.101.68:3306
canal.instance.master.journal.name=mysql-bin.000001
canal.instance.master.position=0
canal.instance.master.timestamp=
canal.instance.master.gtid=
# rds oss binlog
canal.instance.rds.accesskey=
canal.instance.rds.secretkey=
canal.instance.rds.instanceId=
# table meta tsdb info
canal.instance.tsdb.enable=true
#canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb
#canal.instance.tsdb.dbUsername=canal
#canal.instance.tsdb.dbPassword=canal
#canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp =
#canal.instance.standby.gtid=
# username/password
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
canal.instance.connectionCharset = UTF-8
# enable druid Decrypt database password
canal.instance.enableDruid=false
#canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ==
# table regex
# canal.instance.filter.regex=test01\\..*,test02\\..*
#canal.instance.filter.regex=test01\\..*,test02\\.t1
#canal.instance.filter.regex=jzo2o-foundations\\.serve_sync,jzo2o-orders-0\\.orders_seize,jzo2o-orders-0\\.orders_dispatch,jzo2o-orders-0\\.serve_provider_sync,jzo2o-customer\\.serve_provider_sync
#这里主要定义监听哪些表的binlog日志
canal.instance.filter.regex=jzo2o-orders-1\\.orders_dispatch,jzo2o-orders-1\\.orders_seize,jzo2o-foundations\\.serve_sync,jzo2o-customer\\.serve_provider_sync,jzo2o-orders-1\\.serve_provider_sync,jzo2o-orders-1\\.history_orders_sync,jzo2o-orders-1\\.history_orders_serve_sync,jzo2o-market\\.activity
# table black regex
canal.instance.filter.black.regex=mysql\\.slave_.*
# table field filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.field=test1.t_product:id/subject/keywords,test2.t_company:id/name/contact/ch
# table field black filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.black.field=test1.t_product:subject/product_image,test2.t_company:id/name/contact/ch
# mq config
#canal.mq.topic=topic_test01
# dynamic topic route by schema or table regex
#canal.mq.dynamicTopic=mytest1.user,mytest2\\..*,.*\\..*
#canal.mq.dynamicTopic=topic_test01:test01\\..*,topic_test02:test02\\..*
#canal.mq.dynamicTopic=canal-mq-jzo2o-orders-dispatch:jzo2o-orders-0\\.orders_dispatch,canal-mq-jzo2o-orders-seize:jzo2o-orders-0\\.orders_seize,canal-mq-jzo2o-foundations:jzo2o-foundations\\.serve_sync,canal-mq-jzo2o-customer-provider:jzo2o-customer\\.serve_provider_sync,canal-mq-jzo2o-orders-provider:jzo2o-orders-0\\.serve_provider_sync
#在Canal配置MQ的topic
canal.mq.dynamicTopic=canal-mq-jzo2o-orders-dispatch:jzo2o-orders-1\\.orders_dispatch,canal-mq-jzo2o-orders-seize:jzo2o-orders-1\\.orders_seize,canal-mq-jzo2o-foundations:jzo2o-foundations\\.serve_sync,canal-mq-jzo2o-customer-provider:jzo2o-customer\\.serve_provider_sync,canal-mq-jzo2o-orders-provider:jzo2o-orders-1\\.serve_provider_sync,canal-mq-jzo2o-orders-serve-history:jzo2o-orders-1\\.history_orders_serve_sync,canal-mq-jzo2o-orders-history:jzo2o-orders-1\\.history_orders_sync,canal-mq-jzo2o-market-resource:jzo2o-market\\.activity
canal.mq.partition=0
# hash partition config
#canal.mq.partitionsNum=3
#canal.mq.partitionHash=test.table:id^name,.*\\..*
#canal.mq.dynamicTopicPartitionNum=test.*:4,mycanal:6
#################################################
1、在Canal中配置RabbitMQ的连接信息
修改/data/soft/canal/canal.properties
##################################################
######### RabbitMQ #############
##################################################
rabbitmq.host = 192.168.101.68
rabbitmq.virtual.host = /xzb
rabbitmq.exchange = exchange.canal-jzo2o
rabbitmq.username = xzb
rabbitmq.password = xzb
rabbitmq.deliveryMode = 2
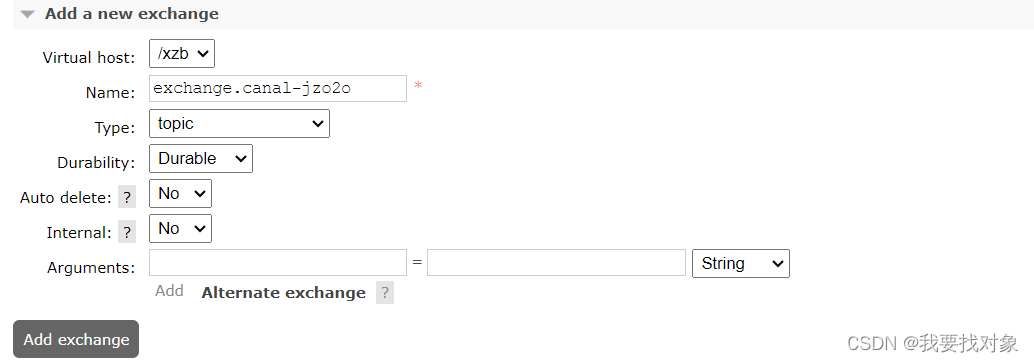
本项目用于数据同步的MQ交换机:exchange.canal-jzo2o
虚拟主机地址:/xzb
账号和密码:xzb/xzb
rabbitmq.deliveryMode = 2 设置消息持久化
2、设置需要监听的mysql库和表
修改/data/soft/canal/instance.properties
- canal.instance.filter.regex 需要监听的mysql库和表
- 全库: .\…
- 指定库下的所有表: canal\…*
- 指定库下的指定表: canal\.canal,test\.test
- 库名\.表名:转义需要用\,使用逗号分隔多个库
这里配置监听 jzo2o-foundations数据库下serve_sync表,如下:
- 库名\.表名:转义需要用\,使用逗号分隔多个库
canal.instance.filter.regex=jzo2o-foundations\\.serve_sync
3、在Canal配置MQ的topic
这里使用动态topic,格式为:topic:schema.table,topic:schema.table,topic:schema.table
配置如下:
canal.mq.dynamicTopic=canal-mq-jzo2o-foundations:jzo2o-foundations\\.serve_sync
上边的配置表示:对jzo2o-foundations数据库的serve_sync表的修改消息发到topic为canal-mq-jzo2o-foundations关联的队列
在之后就是进入rabbitMQ配置交换机和队列
创建exchange.canal-jzo2o交换机:
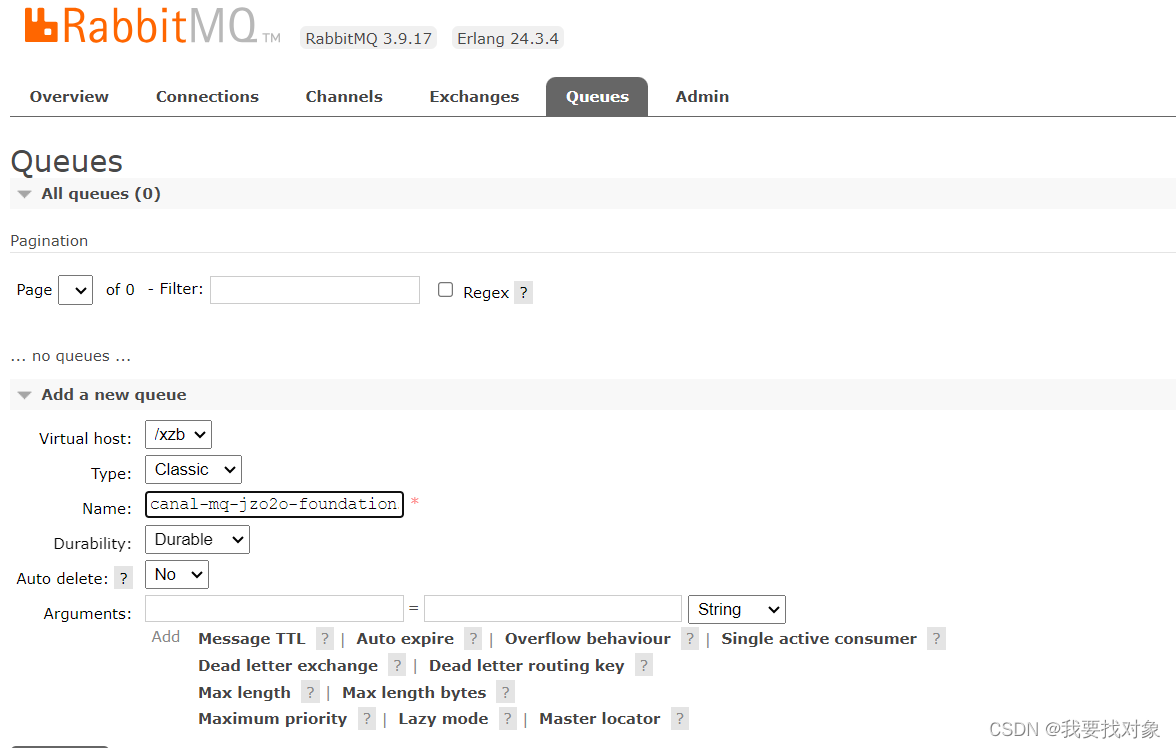
创建队列:canal-mq-jzo2o-foundations:
绑定交换机:
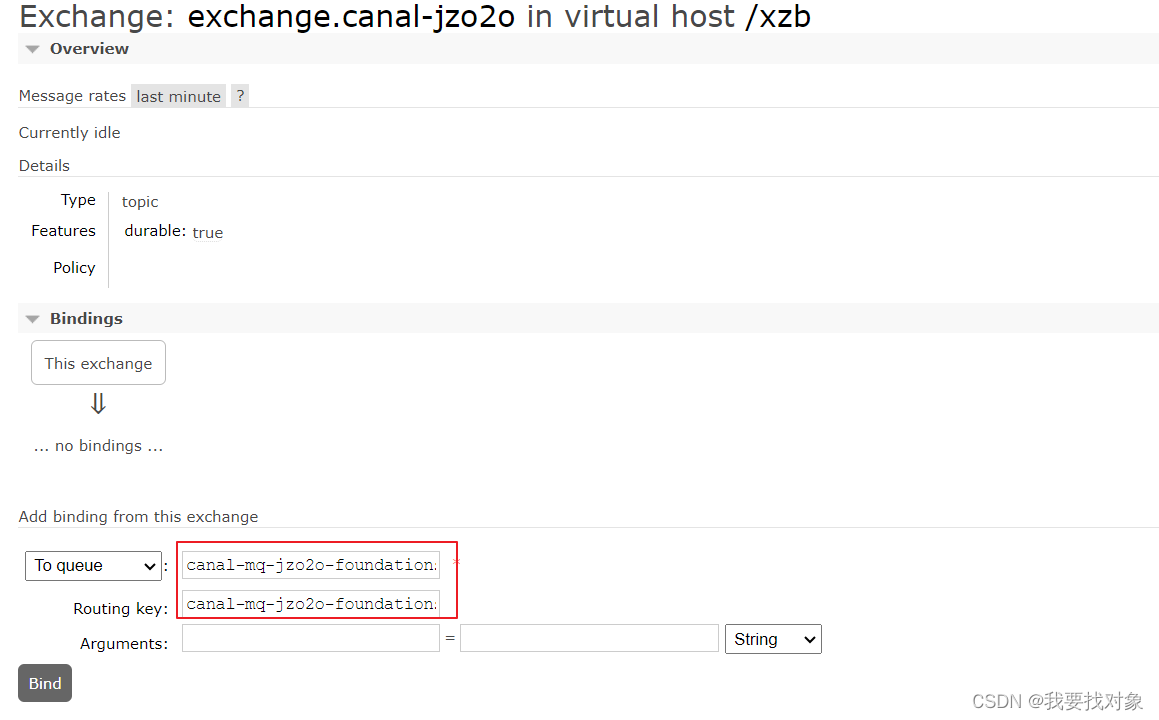
绑定成功: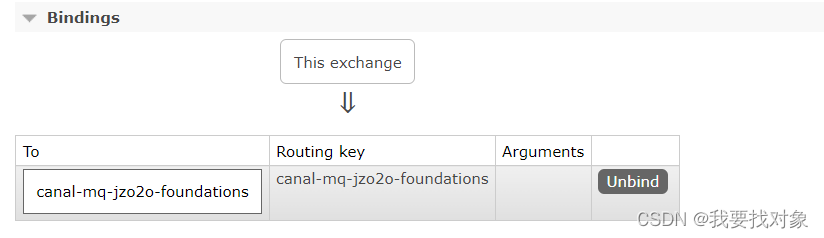
测试数据同步
重启canal
修改jzo2o-foundations数据库的serve_sync表的数据,稍等片刻查看canal-mq-jzo2o-foundations队列,如果队列中有的消息说明同步成功,如下 图:
![[图片]](https://img-blog.csdnimg.cn/direct/274fd9c1443d46bca077accac22f72d1.png)
我们可以查询队列中的消息内容发现它一条type为"UPDATE"的消息,如下所示:
{
"data" : [
{
"city_code" : "010",
"detail_img" : "https://yjy-xzbjzfw-oss.oss-cn-hangzhou.aliyuncs.com/be1449d6-1c2d-4cca-9f8a-4b562b79998d.jpg",
"hot_time_stamp" : "1692256062300",
"id" : "1686352662791016449",
"is_hot" : "1",
"price" : "5.0",
"serve_item_icon" : "https://yjy-xzbjzfw-oss.oss-cn-hangzhou.aliyuncs.com/8179d29c-6b85-4c08-aa13-08429a91d86a.png",
"serve_item_id" : "1678727478181957634",
"serve_item_img" : "https://yjy-xzbjzfw-oss.oss-cn-hangzhou.aliyuncs.com/9b87ab7c-9592-4090-9299-5bcf97409fb9.png",
"serve_item_name" : "日常维修ab",
"serve_item_sort_num" : "6",
"serve_type_icon" : "https://yjy-xzbjzfw-oss.oss-cn-hangzhou.aliyuncs.com/c8725882-1fa7-49a6-94ab-cac2530b3b7b.png",
"serve_type_id" : "1678654490336124929",
"serve_type_img" : "https://yjy-xzbjzfw-oss.oss-cn-hangzhou.aliyuncs.com/00ba6d8a-fd7e-4691-8415-8ada95004b33.png",
"serve_type_name" : "日常维修12",
"serve_type_sort_num" : "2",
"unit" : "1"
}
],
"database" : "jzo2o-foundations",
"es" : 1697443035000.0,
"id" : 1,
"isDdl" : false,
"mysqlType" : {
"city_code" : "varchar(20)",
"detail_img" : "varchar(255)",
"hot_time_stamp" : "bigint",
"id" : "bigint",
"is_hot" : "int",
"price" : "decimal(10,2)",
"serve_item_icon" : "varchar(255)",
"serve_item_id" : "bigint",
"serve_item_img" : "varchar(255)",
"serve_item_name" : "varchar(100)",
"serve_item_sort_num" : "int",
"serve_type_icon" : "varchar(255)",
"serve_type_id" : "bigint",
"serve_type_img" : "varchar(255)",
"serve_type_name" : "varchar(255)",
"serve_type_sort_num" : "int",
"unit" : "int"
},
"old" : [
{
"serve_item_name" : "日常维修a"
}
],
"pkNames" : [ "id" ],
"sql" : "",
"sqlType" : {
"city_code" : 12,
"detail_img" : 12,
"hot_time_stamp" : -5,
"id" : -5,
"is_hot" : 4,
"price" : 3,
"serve_item_icon" : 12,
"serve_item_id" : -5,
"serve_item_img" : 12,
"serve_item_name" : 12,
"serve_item_sort_num" : 4,
"serve_type_icon" : 12,
"serve_type_id" : -5,
"serve_type_img" : 12,
"serve_type_name" : 12,
"serve_type_sort_num" : 4,
"unit" : 4
},
"table" : "serve_sync",
"ts" : 1697443782457.0,
"type" : "UPDATE"
}
配置完成
1.2.5 索引同步
1.2.5.1 编写同步程序
上一届通过配置Canal+MQ的数据同步环境实现了Canal从数据库读取binlog并且将数据写入MQ。
下边编写同步程序监听MQ,收到消息后向ES创建索引。
创建索引结构
下边创建索引serve_aggregation,serve_aggregation索引的结构与jzo2o-foundations数据库的serve_sync表结构对应。
PUT /serve_aggregation
{
"mappings" : {
"properties" : {
"city_code" : {
"type" : "keyword"
},
"detail_img" : {
"type" : "text",
"index" : false
},
"hot_time_stamp" : {
"type" : "long"
},
"id" : {
"type" : "keyword"
},
"is_hot" : {
"type" : "short"
},
"price" : {
"type" : "double"
},
"serve_item_icon" : {
"type" : "text",
"index" : false
},
"serve_item_id" : {
"type" : "keyword"
},
"serve_item_img" : {
"type" : "text",
"index" : false
},
"serve_item_name" : {
"type" : "text",
"analyzer": "ik_max_word",
"search_analyzer":"ik_smart"
},
"serve_item_sort_num" : {
"type" : "short"
},
"serve_type_icon" : {
"type" : "text",
"index" : false
},
"serve_type_id" : {
"type" : "keyword"
},
"serve_type_img" : {
"type" : "text",
"index" : false
},
"serve_type_name" : {
"type" : "text",
"analyzer": "ik_max_word",
"search_analyzer":"ik_smart"
},
"serve_type_sort_num" : {
"type" : "short"
}
}
}
}
编写同步程序
首先在添加下边的依赖:
<dependency>
<groupId>com.jzo2o</groupId>
<artifactId>jzo2o-canal-sync</artifactId>
</dependency>
<dependency>
<groupId>com.jzo2o</groupId>
<artifactId>jzo2o-es</artifactId>
</dependency>
配置连接foundations项目的配置文件来连接Es和Mq:
file-extension: yaml
shared-configs: # 共享配置
- data-id: shared-redis-cluster.yaml # 共享redis配置
refresh: false
- data-id: shared-xxl-job.yaml # xxl-job配置
refresh: false
- data-id: shared-rabbitmq.yaml # rabbitmq配置
refresh: false
- data-id: shared-es.yaml # rabbitmq配置
refresh: false
- data-id: shared-mysql.yaml # mysql配置
refresh: false
AbstractCanalRabbitMqMsgListener类:
public abstract class AbstractCanalRabbitMqMsgListener<T> implements CanalDataHandler<T> {
/**
* 解析消息内容
* @param message
* @throws Exception
*/
public void parseMsg(Message message) throws Exception {
try {
// 1.数据格式转换
CanalMqInfo canalMqInfo = JsonUtils.toBean(new String(message.getBody()), CanalMqInfo.class);
// 2.过滤数据,没有数据或者非插入、修改、删除的操作均不处理
if (CollUtils.isEmpty(canalMqInfo.getData()) || !(OperateType.canHandle(canalMqInfo.getType()))) {
return;
}
if (canalMqInfo.getData().size() > 1) {
// 3.多条数据处理
batchHandle(canalMqInfo);
} else {
// 4.单条数据处理
singleHandle(canalMqInfo);
}
} catch (Exception e) {
//出现错误延迟1秒重试
Thread.sleep(1000);
throw new RuntimeException(e);
}
}
/**
* 单条数据处理
*
* @param canalMqInfo
*/
private void singleHandle(CanalMqInfo canalMqInfo) {
// 1.数据转换
CanalBaseDTO canalBaseDTO = BeanUtils.toBean(canalMqInfo, CanalBaseDTO.class);
Map<String, Object> fieldMap = CollUtils.getFirst(canalMqInfo.getData());
canalBaseDTO.setId(parseId(fieldMap));
canalBaseDTO.setFieldMap(fieldMap);
canalBaseDTO.setIsSave(canalMqInfo.getIsSave());
Class<T> messageType = getMessageType();
if (messageType == null) {
return;
}
if (canalBaseDTO.getIsSave()) {
T t1 = JsonUtils.toBean(JsonUtils.toJsonStr(canalBaseDTO.getFieldMap()), messageType);
List<T> ts = Arrays.asList(t1);
batchSave(ts);
} else {
Long id = canalBaseDTO.getId();
List<Long> ids = Arrays.asList(id);
batchDelete(ids);
}
}
private void batchHandle(CanalMqInfo canalMqInfo) {
Class<T> messageType = getMessageType();
if (messageType == null) {
return;
}
if(canalMqInfo.getIsSave()){
List<T> collect = canalMqInfo.getData().stream().map(fieldMap -> {
CanalBaseDTO canalBaseDTO = CanalBaseDTO.builder()
.id(parseId(fieldMap))
.database(canalMqInfo.getDatabase())
.table(canalMqInfo.getTable())
.isSave(canalMqInfo.getIsSave())
.fieldMap(fieldMap).build();
return JsonUtils.toBean(JsonUtils.toJsonStr(canalBaseDTO.getFieldMap()), messageType);
}).collect(Collectors.toList());
batchSave(collect);
}else{
List<Long> ids = canalMqInfo.getData().stream().map(fieldMap -> {
return parseId(fieldMap);
}).collect(Collectors.toList());
batchDelete(ids);
}
}
private Long parseId(Map<String, Object> fieldMap) {
Object objectId = fieldMap.get(FieldConstants.ID);
return NumberUtils.parseLong(objectId.toString());
}
/**
* 批量保存
*
* @param data
*/
public abstract void batchSave(List<T> data);
/**
* 批量删除
*
* @param ids
*/
public abstract void batchDelete(List<Long> ids);
//获取泛型参数
public Class<T> getMessageType() {
Type superClass = getClass().getGenericSuperclass();
if (superClass instanceof ParameterizedType) {
ParameterizedType parameterizedType = (ParameterizedType) superClass;
Type[] typeArgs = parameterizedType.getActualTypeArguments();
if (typeArgs.length > 0 && typeArgs[0] instanceof Class) {
return (Class<T>) typeArgs[0];
}
}
return null;
}
}
同步程序继承AbstractCanalRabbitMqMsgListener类,泛型中指定同步表对应的类型。
根据数据同步环境去配置监听MQ:
/**
* 实现canal同步数据
*/
@Component
public class ServeCanalDataSyncHandler extends AbstractCanalRabbitMqMsgListener<ServeSync> {
@Autowired
private ElasticSearchTemplateImpl elasticSearchTemplate;
/**
* 监听MQ
* @param message
*/
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "canal-mq-jzo2o-foundations"),
exchange = @Exchange(name = "exchange.canal-jzo2o",type = ExchangeTypes.TOPIC),
key = "canal-mq-jzo2o-foundations"
),concurrency = "1") //指定消费线程为1
public void onMessage(Message message) throws Exception {
//调用canal抽象类进行解析消息并处理
parseMsg(message);
}
/**
* 向ES保存数据 解析到binlog的新增和更新消息 都执行该方法
* @param data
*/
@Override
public void batchSave(List<ServeSync> data) {
//向es保存索引,有则更新,没有则保存
Boolean serveAggregation = elasticSearchTemplate.opsForDoc().batchUpsert("serve_aggregation", data);
//消费失败 抛出异常, 给mq回nack
if(!serveAggregation){
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
throw new RuntimeException("同步失败");
}
}
/**
* 向ES批量删除 解析binlog中的删除消息
* @param ids
*/
@Override
public void batchDelete(List<Long> ids) {
Boolean serveAggregation = elasticSearchTemplate.opsForDoc().batchDelete("serve_aggregation", ids);
if(!serveAggregation){
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
throw new RuntimeException("同步失败");
}
}
}
其中关于es的操作写在了es模块:
@Override
public <T> Boolean batchInsert(String index, List<T> documents) {
BulkRequest.Builder br = new BulkRequest.Builder();
for (T document : documents) {
br.operations(op -> op.index(idx -> idx.index(index)
.id(getId(document))
.document(document)));
}
try {
BulkResponse bulk = elasticsearchClient.bulk(br.build());
Boolean success = isSuccess(bulk);
return success;
} catch (IOException e) {
log.error(e.getMessage(),e);
throw new CommonException(500,e.getMessage());
}
}
@Override
public <ID> Boolean batchDelete(String index, List<ID> ids) {
BulkRequest.Builder builder = new BulkRequest.Builder();
ids.stream().forEach(id ->
builder.operations(b -> b.delete(d -> d.index(index).id(id.toString())))
);
try {
BulkResponse bulk = elasticsearchClient.bulk(builder.build());
Boolean success = isSuccess(bulk);
return success;
} catch (Exception e) {
log.error(e.getMessage(),e);
throw new CommonException(500,e.getMessage());
}
}
如何保证Canal+MQ同步消息的顺序性?
场景:
如下图:
首先明确Canal解析binlog日志信息按顺序发到MQ的队列中,现在是要保证消费端如何按顺序消费队列中的消息。
生产中同一个jzo2o-foundations服务会启动多个jvm进程,每个进程作为canal-mq-jzo2o-foundations的消费者,如下图:
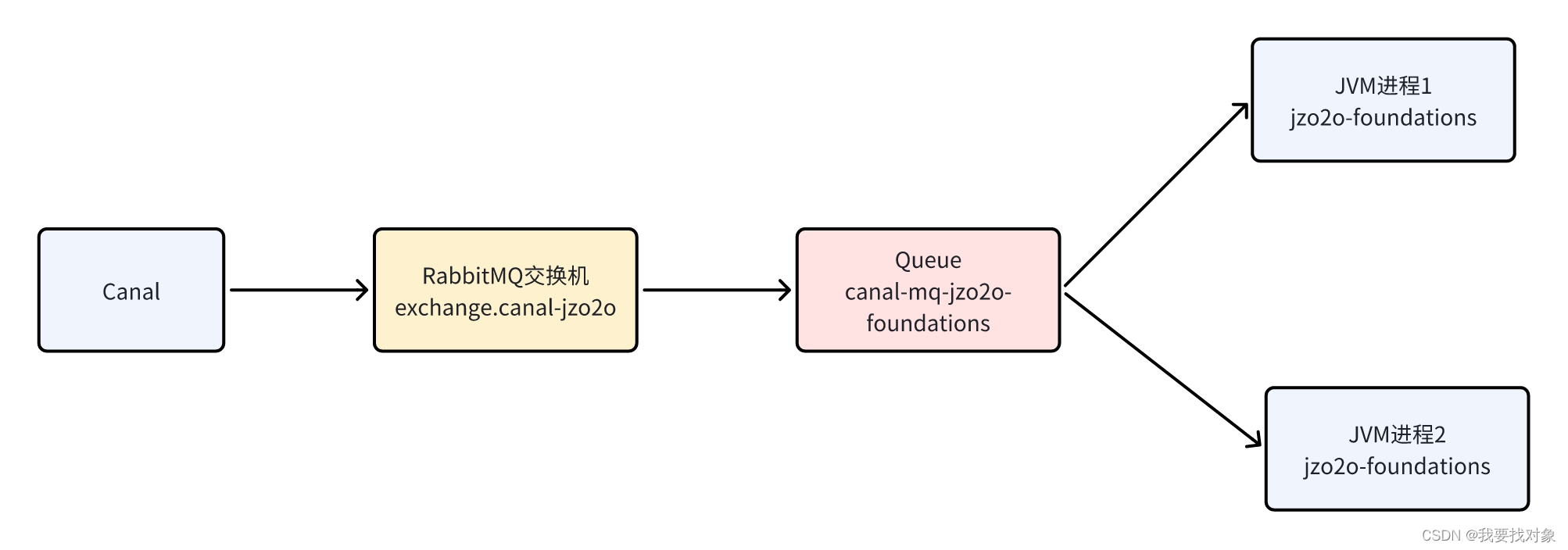
解决方法:
多个jvm进程监听同一个队列保证只有消费者活跃,即只有一个消费者接收消息。
如何保证只有一个消费者接收消息?
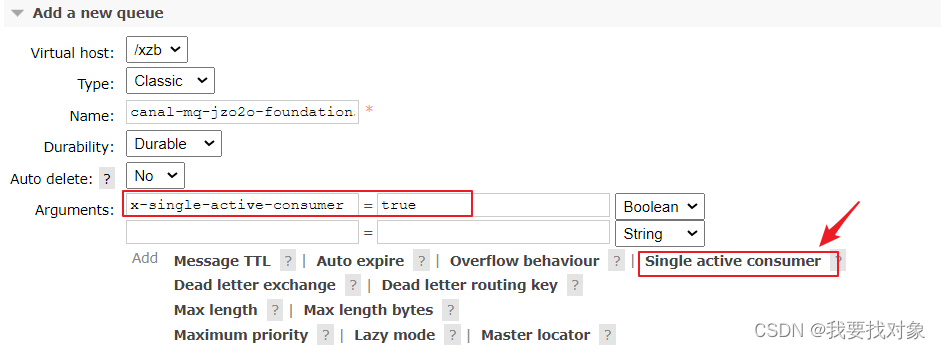
队列需要增加x-single-active-consumer参数,表示否启用单一活动消费者模式。
首先监听队列的线程设为1
/**
* 监听MQ
* @param message
*/
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "canal-mq-jzo2o-foundations"),
exchange = @Exchange(name = "exchange.canal-jzo2o",type = ExchangeTypes.TOPIC),
key = "canal-mq-jzo2o-foundations"
),concurrency = "1") //指定消费线程为1
public void onMessage(Message message) throws Exception {
//调用canal抽象类进行解析消息并处理
parseMsg(message);
}
队列需要增加x-single-active-consumer参数,表示否启用单一活动消费者模式
1.2.5.2 管理同步表
现在如何去维护serve_sync这张表呢?
根据serve_sync表的结构分析:
添加:区域服务上架向serve_sync表添加记录,同步程序新增索引记录。
删除:区域服务下架从serve_sync表删除记录,同步程序删除索引记录。
修改:
修改服务项修改serve_sync的记录。
修改服务分类修改serve_sync的记录。
修改服务价格修改serve_sync的记录。
设置热门/取消热门修改serve_sync的记录。
在ServeServiceImpl增加私有方法,如下:
/**
* 新增服务同步数据
*
* @param serveId 服务id
*/
private void addServeSync(Long serveId) {
//服务信息
Serve serve = baseMapper.selectById(serveId);
//区域信息
Region region = regionMapper.selectById(serve.getRegionId());
//服务项信息
ServeItem serveItem = serveItemMapper.selectById(serve.getServeItemId());
//服务类型
ServeType serveType = serveTypeMapper.selectById(serveItem.getServeTypeId());
ServeSync serveSync = new ServeSync();
serveSync.setServeTypeId(serveType.getId());
serveSync.setServeTypeName(serveType.getName());
serveSync.setServeTypeIcon(serveType.getServeTypeIcon());
serveSync.setServeTypeImg(serveType.getImg());
serveSync.setServeTypeSortNum(serveType.getSortNum());
serveSync.setServeItemId(serveItem.getId());
serveSync.setServeItemIcon(serveItem.getServeItemIcon());
serveSync.setServeItemName(serveItem.getName());
serveSync.setServeItemImg(serveItem.getImg());
serveSync.setServeItemSortNum(serveItem.getSortNum());
serveSync.setUnit(serveItem.getUnit());
serveSync.setDetailImg(serveItem.getDetailImg());
serveSync.setPrice(serve.getPrice());
serveSync.setCityCode(region.getCityCode());
serveSync.setId(serve.getId());
serveSync.setIsHot(serve.getIsHot());
serveSyncMapper.insert(serveSync);
}
之后对上架方法修改:
/**
* 启用服务
* @param id 服务id
* @return
*/
@Override
@Transactional
@CachePut(value = RedisConstants.CacheName.SERVE,key = "#id",cacheManager = RedisConstants.CacheManager.ONE_DAY)
public Serve onSale(Long id){
Serve serve = baseMapper.selectById(id);
if(ObjectUtil.isNull(serve)){
throw new ForbiddenOperationException("区域服务不存在");
}
//上架状态
Integer saleStatus = serve.getSaleStatus();
//草稿或下架状态方可上架
if (!(saleStatus==FoundationStatusEnum.INIT.getStatus() || saleStatus==FoundationStatusEnum.DISABLE.getStatus())) {
throw new ForbiddenOperationException("草稿或下架状态方可上架");
}
//服务项id
Long serveItemId = serve.getServeItemId();
ServeItem serveItem = serveItemMapper.selectById(serveItemId);
if(ObjectUtil.isNull(serveItem)){
throw new ForbiddenOperationException("所属服务项不存在");
}
//服务项的启用状态
Integer activeStatus = serveItem.getActiveStatus();
//服务项为启用状态方可上架
if (!(FoundationStatusEnum.ENABLE.getStatus()==activeStatus)) {
throw new ForbiddenOperationException("服务项为启用状态方可上架");
}
//更新上架状态
LambdaUpdateWrapper<Serve> updateWrapper = Wrappers.<Serve>lambdaUpdate()
.eq(Serve::getId, id)
.set(Serve::getSaleStatus, FoundationStatusEnum.ENABLE.getStatus());
update(updateWrapper);
//向servce_sync表写记录
addServeSync(id);
return baseMapper.selectById(id);
}
修改下架:
/**
* 禁用服务
* @param id 服务id
* @return
*/
@Override
@Transactional
@CacheEvict(value = RedisConstants.CacheName.SERVE,key = "#id")
public Serve offSale(Long id){
Serve serve = baseMapper.selectById(id);
if(ObjectUtil.isNull(serve)){
throw new ForbiddenOperationException("区域服务不存在");
}
//上架状态
Integer saleStatus = serve.getSaleStatus();
//上架状态方可下架
if (!(saleStatus==FoundationStatusEnum.ENABLE.getStatus())) {
throw new ForbiddenOperationException("上架状态方可下架");
}
//更新下架状态
LambdaUpdateWrapper<Serve> updateWrapper = Wrappers.<Serve>lambdaUpdate()
.eq(Serve::getId, id)
.set(Serve::getSaleStatus, FoundationStatusEnum.DISABLE.getStatus());
update(updateWrapper);
//删除serve_sync表的记录
serveSyncMapper.deleteById(id);
return baseMapper.selectById(id);
}
等等。。。。
1.2.6 搜索接口
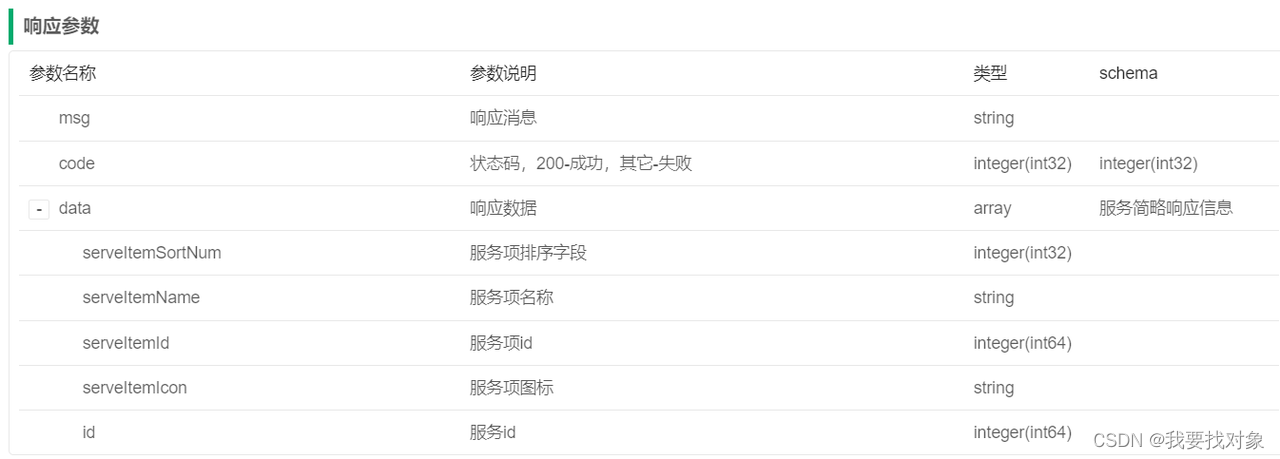
1.2.6.1 接口分析
参数内容:区域编码,服务类型id、关键字
区域编码:用户定位成功前端记录区域编码(city_code),搜索时根据city_code搜索该区域的服务。
服务类型id:在全部服务界面选择一个服务类型查询其它下的服务列表。
关键字:输入关键字搜索服务项名称、服务类型名称。
接口名称:服务搜索接口
接口路径:GET/foundations/customer/serve/search

1.2.6.1 接口开发
Controller
@GetMapping("/search")
@ApiOperation("首页服务搜索")
@ApiImplicitParams({
@ApiImplicitParam(name = "cityCode", value = "城市编码", required = true, dataTypeClass = String.class),
@ApiImplicitParam(name = "serveTypeId", value = "服务类型id", dataTypeClass = Long.class),
@ApiImplicitParam(name = "keyword", value = "关键词", dataTypeClass = String.class)
})
public List<ServeSimpleResDTO> findServeList(@RequestParam("cityCode") String cityCode,
@RequestParam(value = "serveTypeId", required = false) Long serveTypeId,
@RequestParam(value = "keyword", required = false) String keyword) {
return null;
}
Service层
/**
* 搜索
*/
public interface ServeAggregationService {
/**
* 查询服务列表
*
* @param cityCode 城市编码
* @param serveTypeId 服务类型id
* @param keyword 关键词
* @return 服务列表
*/
List<ServeSimpleResDTO> findServeList(String cityCode, Long serveTypeId, String keyword);
}
首先通过ES的查询语言进行查询,如下:
GET /serve_aggregation/_search
{
"query" : {
"bool" : {
"must" : [
{
"term" : {
"city_code" : {
"value" : "010"
}
}
},
{
"multi_match" : {
"fields" : [ "serve_item_name", "serve_type_name" ],
"query" : "保洁"
}
}
]
}
},
"sort" : [
{
"serve_item_sort_num" : {
"order" : "asc"
}
}
]
}
接下来写Service实现类
@Service
@Slf4j
public class ServeAggregationServiceImpl implements ServeAggregationService {
@Autowired
private ElasticSearchTemplate elasticSearchTemplate;
/**
* 搜索
* @param cityCode 城市编码
* @param serveTypeId 服务类型id
* @param keyword 关键词
* @return
*/
@Override
public List<ServeSimpleResDTO> findServeList(String cityCode, Long serveTypeId, String keyword) {
SearchRequest.Builder builder = new SearchRequest.Builder();
//拼装查询条件
//根据city_code查询
builder.query(query->query.bool(bool-> {
bool.must(must ->
must.term(term ->
term.field("city_code").value(cityCode)));
//根据服务类型查询
if(ObjectUtils.isNotEmpty(serveTypeId)){
bool.must(must->must.term(term->term.field("serve_type_id").value(serveTypeId)));
}
//根据keyword查询
if(ObjectUtils.isNotEmpty(keyword)){
//拼接条件
bool.must(must->
must.multiMatch(multiMatch->
multiMatch.query(keyword).fields("serve_type_name","serve_item_name")));
}
return bool;
}));
//添加排序
List<SortOptions> sortOptionsList = new ArrayList<>();
sortOptionsList.add(SortOptions.of(sortOptions->sortOptions.field(filed->filed.field("serve_item_sort_num").order(SortOrder.Asc))));
builder.sort(sortOptionsList);
//请求es查询
builder.index("serve_aggregation");
SearchRequest searchRequest = builder.build();
SearchResponse<ServeAggregation> searchResponse = elasticSearchTemplate.opsForDoc().search(searchRequest, ServeAggregation.class);
if(SearchResponseUtils.isSuccess(searchResponse)){
List<ServeAggregation> collect = searchResponse.hits().hits().stream().map(item -> {
ServeAggregation source = item.source();
return source;
}).collect(Collectors.toList());
//转为List<ServeSimpleResDTO>
List<ServeSimpleResDTO> serveSimpleResDTOS = BeanUtils.copyToList(collect, ServeSimpleResDTO.class);
//结果集返回
return serveSimpleResDTOS;
}
return Collections.emptyList();
}
}
1.2.6.3 功能测试
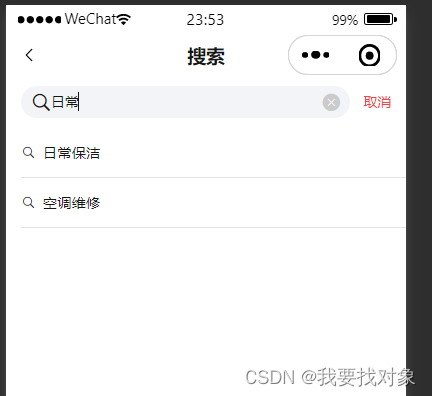

搜索功能完成















 1209
1209

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









