






我们要爬取金融数据,首先就得分析一下网页结构,因为这个网站是数据是公开且不涉及保密问题,所以数据并没有涉及加密等情况,故好爬很多,本文只给参考思路,具体问题欢迎私信讨论。
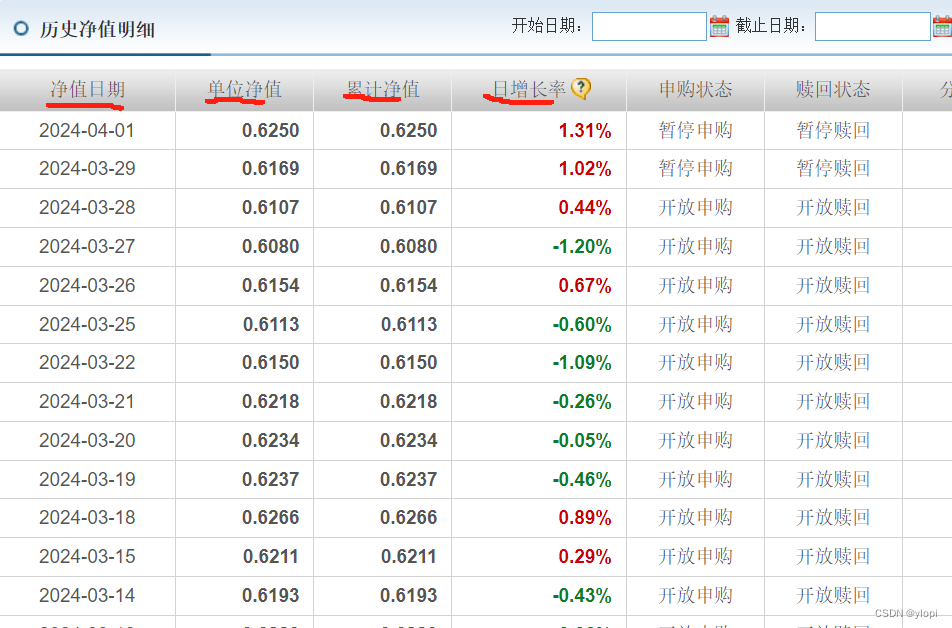
本文所需的数据有净值日期,单位净值,累计净值,以及净增长率,如图这是我们所需要的数据。
通过查看网页源码发现网页源码并没有具体数据,可以推断数据为js渲染而成,所以我们就不能之间通过reques方式去获取网页源码,本文利用selenium库进行自动加载网页并获得js渲染后的网页。利用selenium库需要下载浏览器相对于的webdrive,而且这个webdrive版本必须和你的浏览器版本匹配,否则会报错!!!
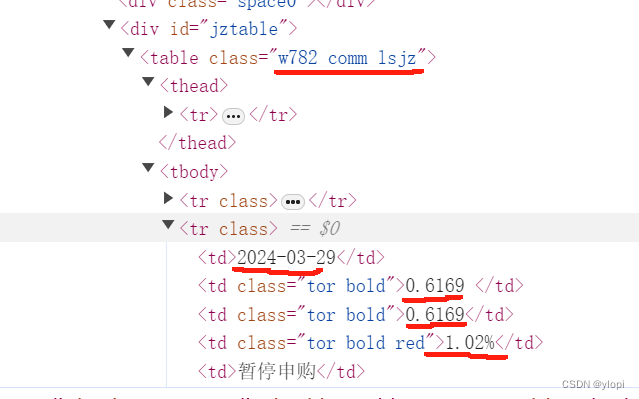
如上图所示,所需要的数据在名为class=“w782.......”类(属性)中,所以我们在获取网页源码数据后, 利用BeautifulSoup去解析网页源码,本文指定的解析器是lxml(Note:BeautifulSoup支持多种解析器,分别是python内置的html.parser,lxml,html5lib。其中lxml速度最快)。然后利用BeautifulSoup的查找方法find_all,查找属性为class=“w782.....",缩小数据范围后利用re去筛选哪些数据为日期,浮点,百分号和汉字。进一步将数据分类后将不同数据保存至不同列表。分类方法是通过筛选后的数据进行按位余4的操作进行(前提是你要确保前面的数据处理没问题)。得到4本页的列表后利用WebDriverWait函数进行了条件判定,判断下一页的源码是否加载完成。符合条件后进行click操作。值得注意的是该操作是有必要的因为我们是通过这个操作去判断是否已点击至最后一页。如果报出超时错误,则会进行保存操作,以上就会将一个url内的所有数据进行保存。为了让其在保存时可以自动将对应的将爬取数据的名字作为文档名称如图![]() 则此文档的名称应该为“达城价值.....(011030)”,我们利用request又进行了获取,获取了改标题,并进行了一些处理使其只保留名字加代码的形式。到这位置一个页面的数据已经爬取完毕。剩下的就是鸟枪换大炮。分析了其每个网页的url规律,进行了设置,以如图的连接为例:
则此文档的名称应该为“达城价值.....(011030)”,我们利用request又进行了获取,获取了改标题,并进行了一些处理使其只保留名字加代码的形式。到这位置一个页面的数据已经爬取完毕。剩下的就是鸟枪换大炮。分析了其每个网页的url规律,进行了设置,以如图的连接为例:

我们发现每个url只是最后的数字变为其基金唯一表示代码。故 我们利用了format_string = '{:06d}'方法进行在url上更改基金代码的操作,我们初始的是000000,然后利用request判断返回状态码,当其返回的是200时,则开始进行数据爬取工作,否则将其转换为int形式进行累加(这步骤是有必要的因为format_string返回的是字符串,并不能直接进行累加和判断)。ps:这个方法并不好,有点慢。
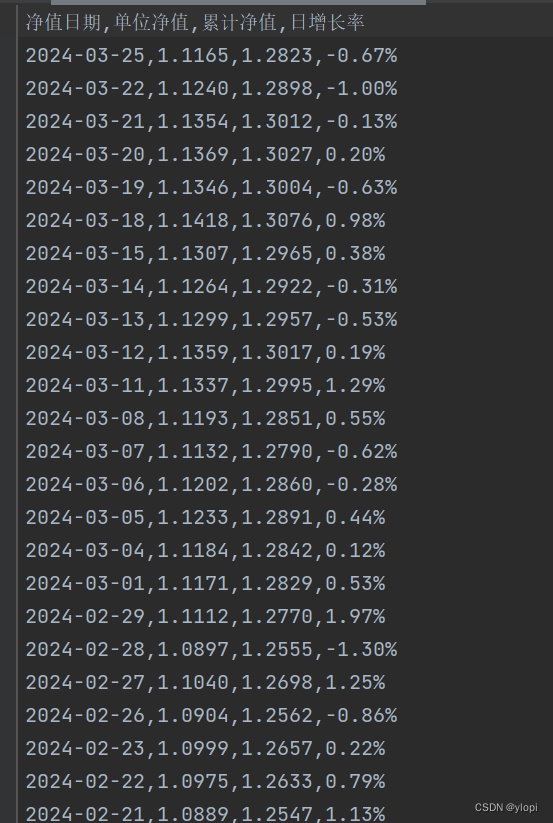
最后获取到的数据效果如图:
完整代码:
from selenium.webdriver.chrome.service import Service
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
import pandas as pd
from selenium.common.exceptions import TimeoutException
import requests
import re
def get_id(fund_url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/your_chrome_version Safari/537.36',
}
# 发送请求
response = requests.get(fund_url, headers=headers)
# 检查响应状态码是否成功
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'lxml')
reselt = soup.find_all(class_='title')
name_id = ''
for i in reselt[0]:
for y in i:
name_id += str(y)
# 输出或处理提取的数据
return name_id
else:
print(f"请求失败,状态码:{response.status_code}")
return None
def web_drive(driver,fund_url, data_date, data_Net_unit_value, data_Cumulative_net_worth, data_Daily_growth_rate):
while True:
try:
grouped_data = get_data(driver)
try:
result_data = process_data(grouped_data)
print(result_data)
except IndexError as e:
print(f"发生错误:{e},数据未加载完完成,等待加载.........")
continue
data_date, data_Net_unit_value, data_Cumulative_net_worth, data_Daily_growth_rate = split_data(result_data, data_date, data_Net_unit_value, data_Cumulative_net_worth, data_Daily_growth_rate)
next_button = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.XPATH, "//*[@id='pagebar']/div[1]/label[8]"))
)
next_button.click()
time.sleep(0.05)
except TimeoutError as e:
print(f"发生错误,已跳过,错误详情:{e}")
continue
except TimeoutException as te:
fund_url_id = fund_url
#global data_date, data_Net_unit_value, data_Cumulative_net_worth, data_Daily_growth_rate
save_data(data_date, data_Net_unit_value, data_Cumulative_net_worth, data_Daily_growth_rate, fund_url_id)
break
# 关闭浏览器
driver.quit()
def get_data(driver):
html_content = driver.page_source
soup = BeautifulSoup(html_content, 'lxml')
result = soup.find_all(class_='w782 comm lsjz')
grouped_data = []
curren_group = []
for td in result:
if 'class' in td.attrs and 'red unbold' in td['class']:
if curren_group:
grouped_data.append(curren_group)
curren_group = []
else:
curren_group.append(td.text)
if curren_group:
grouped_data.append(curren_group)
return grouped_data
def process_data(grouped_data):
result_data = []
date_pattern = r'\d{4}-\d{2}-\d{2}' #日期
float_pattern = r'\d+\.\d+' # 浮点
negative_percent_pattern = r'-?\d+(\.\d+)?%' #百分号
pattern_ch = r'[\u4e00-\u9fff]+' #汉字
#patterns = [date_pattern, float_pattern, float_pattern, negative_percent_pattern]
#print(result_data)
for sublist in grouped_data[0]:
lines = sublist.split('\n')
for i in lines:
if re.search(date_pattern, i) != None:
result_data.append(i)
elif re.search(float_pattern, i) != None and re.search(pattern_ch,i) == None:
result_data.append(i)
elif re.search(negative_percent_pattern, i) != None:
result_data.append(i)
elif re.search(pattern_ch, i) != None:
continue
elif i == '--':
result_data.append('0.00%')
else:
continue
"""
if i == '':
continue
elif i == '净值日期':
continue
elif i == '单位净值':
continue
elif i == '累计净值':
continue
elif i == '日增长率':
continue
elif i == '申购状态':
continue
elif i == '赎回状态':
continue
elif i == '红送配':
continue
elif i == ' ':
continue
elif i == '开放申购':
continue
elif i == '开放赎回':
continue
elif i == '限制大额申购':
continue
elif i == '每份派现金0.0860元':
continue
elif i == '分红送配':
continue
elif i == ' ':
continue
elif '每份派' in i:
continue
elif i == '暂停申购':
continue
elif i == '暂停赎回':
continue
elif '收益' or '*' in i:
continue
else:
result_data.append(i)
"""
return result_data
def split_data(result_data,data_date, data_Net_unit_value, data_Cumulative_net_worth, data_Daily_growth_rate):
step = 0
for i in result_data:
if step % 4 == 0:
data_date.append(i)
if step % 4 == 1:
data_Net_unit_value.append(i)
if step % 4 == 2:
data_Cumulative_net_worth.append(i)
if step % 4 == 3:
if i == '--':
break
data_Daily_growth_rate.append(i)
step += 1
return data_date, data_Net_unit_value, data_Cumulative_net_worth, data_Daily_growth_rate
def save_data(data_date, data_Net_unit_value, data_Cumulative_net_worth, data_Daily_growth_rate, fund_url):
# 创建一个DataFrame,将这些列表作为列
df = pd.DataFrame(list(zip(data_date, data_Net_unit_value, data_Cumulative_net_worth, data_Daily_growth_rate)),
columns=['净值日期', '单位净值', '累计净值', '日增长率'])
fund_url_id = fund_url
name_id = get_id(fund_url_id)
save_path = './data/'
# 写入CSV文件
try:
df.to_csv(save_path+name_id, index=False, encoding='utf-8')
print('写入完成')
except FileNotFoundError as e:
print(f"发生错误{e},已跳过")
return
def web_dfing(fund_url):
chrome_exe_path = r"C:/Program Files (x86)/Google/Chrome/Application/chrome.exe"
# 创建浏览器实例
chromedrives = 'D:/python/Python37/Lib/site-packages/selenium/webdriver/chrome/chromedriver.exe'
options = webdriver.ChromeOptions()
options.binary_location = chrome_exe_path
options.add_argument('--disable-dev-shm-usage') # 禁用共享内存
options.add_argument('--no-sandbox') # 忽略沙箱
options.add_argument('--remote-debugging-port=9222') # 设置调试端口
service = Service(chromedrives)
driver = webdriver.Chrome(service=service, options=options)
driver.get(fund_url)
time.sleep(3)
return driver
def run():
# 目标基金URL
e = int("011030")
format_string = '{:06d}'
while True:
url = f'https://fundf10.eastmoney.com/jjjz_{e}.html'
print(url)
fund_url = test_id(url)
if fund_url == 200:
driver = web_dfing(url)
data_date = []
data_Net_unit_value = []
data_Cumulative_net_worth = []
data_Daily_growth_rate = []
web_drive(driver, url, data_date, data_Net_unit_value, data_Cumulative_net_worth, data_Daily_growth_rate)
e = int(e)
e += 1
e = format_string.format(e)
print(e)
else:
e = int(e)
if e < 591000:
e += 1
e = format_string.format(e)
print(e)
else:
break
def test_id(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/your_chrome_version Safari/537.36',
}
# 发送请求
response = requests.get(url, headers=headers)
# 检查响应状态码是否成功
return response.status_code
if __name__ =='__main__':
run()


















 1153
1153

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











