









问题的提出
上一篇说过的
用于获取某个网址源码的方式
#首先导入库
import urllib.request
#使用urllib将网页源码抓取下来
response = urllib.request.urlopen("https://github.com/lihn1987/CoinCollector").read().decode('utf-8')
此方式非常简单好用,但是如果经常使用问题也很明显。
就是。。。经常会抛出异常,所以。。。。。。。
如何解决稳定性的问题?
于是写了一个函数
import urllib.request
import time
def func(url):
for i in range(10):
try:
#设置5s超时
response = urllib.request.urlopen(url=url, timeout=5).read().decode('utf-8')
#数据抓取成功则返回网页内容
return response
except:
#发生异常则延时5s再试
time.sleep(5)
pass
return ""
print(func("https://github.com/lihn1987/CoinCollector"))
这是我用的方式,意思是如果抓取失败则延时5s继续抓,如果连续失败10次则返回空字符串。
虽然不聪明,但是还蛮实用的。
抓取的问题解决了,另外就是分析网页的问题了。
那么爬虫中如何解决网页分析的问题呢?
对于网页,之前前端很常用的一个工具叫做jquery,虽然现在被各种嫌弃,但是在爬虫里面分析网页还是相当好用的。
这个工具就是pyquery,
先说说pyquery是如何安装的
pip3 install pyquery
简单,一行搞定
有了pyquery于是关于上一篇文章中的问题有了新的,更加通用的解法
import urllib.request
from pyquery import PyQuery as pq
import time
def open_url(url):
for i in range(10):
try:
#设置5s超时
response = urllib.request.urlopen(url=url, timeout=5).read().decode('utf-8')
#数据抓取成功则返回网页内容
return response
except:
#发生异常则延时5s再试
print("retry")
time.sleep(5)
pass
return ""
response = open_url("https://github.com/lihn1987/CoinCollector")
doc = pq(response)
print(doc(".text-gray-dark").text())
这样就直接拿到数据了,另外.text-gray-dark是什么鬼?
这其实是一个基本兼容jquery选择器的一个语法简单的说
.xxx表示class选择器
#xxx表示id选择器
xxx表示类型选择器
具体的我们可以参照这里
https://www.runoob.com/jquery/jquery-ref-selectors.html
这样就可以轻松的分析网页的内容了!!!!但是问题又来了~
抓取网页能抓到所有展示的内容么?
来试试我做的币小站能爬信息么?
网页是这样的

而抓出来的源码是这样的
<!DOCTYPE html>
<html>
<head>
<meta charset=utf-8>
<meta name=viewport content="width=device-width,user-scalable=no,initial-scale=1,maximum-scale=1,minimum-scale=1">
<title>币小站</title>
<meta name=keywords content="区块链 新闻 行情 汇总 twitter">
<meta name=description content=让区块链回归技术的本质,一个越来越客观的网站。一个用于汇总所有币圈相关新闻和交易所所有价格的综合性网站。>
<meta name=author content=骨刀>
<link href=/static/css/app.478bec1cafbfb47360d93fa5fdfae513.css rel=stylesheet>
</head><body style=margin:0;><div id=app></div>
<script type=text/javascript src=/static/js/manifest.2ae2e69a05c33dfc65f8.js></script>
<script type=text/javascript src=/static/js/vendor.819f64e38c7bf9a15e47.js></script>
<script type=text/javascript src=/static/js/app.e578d90495f8b0491383.js></script>
</body>
<script>var _hmt = _hmt || [];
(function() {
var hm = document.createElement("script");
hm.src = "https://hm.baidu.com/hm.js?da027fc509c97b7eed276be86e37e1ee";
var s = document.getElementsByTagName("script")[0];
s.parentNode.insertBefore(hm, s);
})();</script><script async src="https://www.googletagmanager.com/gtag/js?id=UA-153688786-1"></script><script>window.dataLayer = window.dataLayer || [];
function gtag(){dataLayer.push(arguments);}
gtag('js', new Date());
gtag('config', 'UA-153688786-1');</script></html>
这TMD抓出来的东东,明明什么都没有啊!!!!!!!!!
没错,这个网站前端是使用vue框架的,所以他的html页面中几乎什么内容都没有,全部是加载js以后,通过渲染才展示出的界面。所以直接抓取网页几乎拿不到任何信息,那么怎么办呢?
有办法!
打开chrome浏览器,按下F12键,在调试选项中选择NetWork,然后输入要采集的站点的网址www.bxiaozhan.com
如图所示
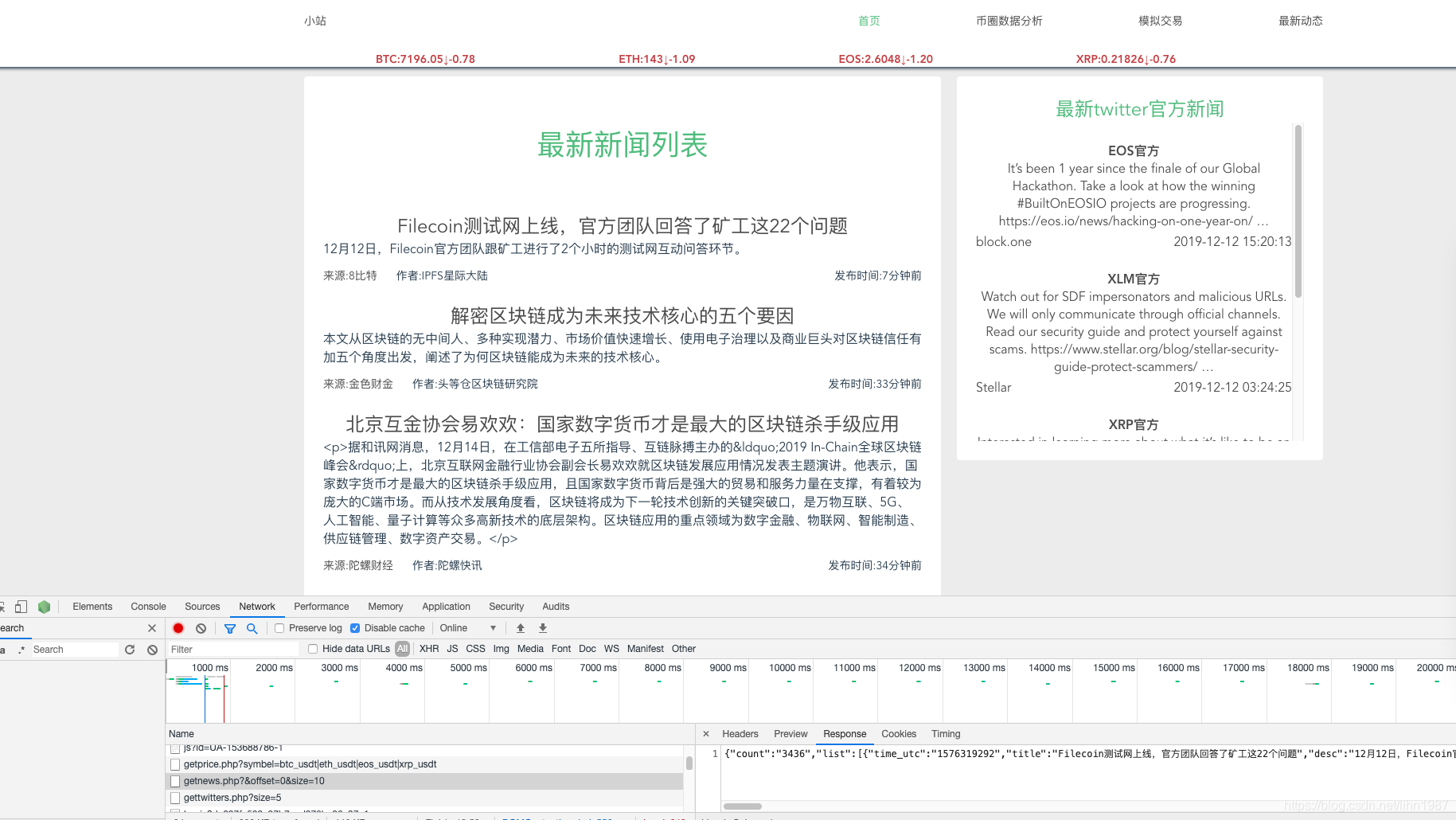
发现了么这些信心是网站打开后从后台加载的,于是如果我们要获取新闻列表和内容的话,直接通过这个接口就可以了,回来的就是json的值,连处理都不需要!!!!
类似于浏览器里面直接输入http://www.bxiaozhan.com/back/getnews.php?&offset=0&size=10
得到的结果如下所示
{"count":"3436","list":[{"time_utc":"1576319292","title":"Filecoin测试网上线,官方团队回答了矿工这22个问题","desc":"12月12日,Filecoin官方团队跟矿工进行了2个小时的测试网互动问答环节。","author":"IPFS星际大陆","source_media":"8比特","source_addr":"https:\/\/www.8btc.com\/article\/533100"},{"time_utc":"1576317734","title":"解密区块链成为未来技术核心的五个要因","desc":"本文从区块链的无中间人、多种实现潜力、市场价值快速增长、使用电子治理以及商业巨头对区块链信任有加五个角度出发,阐述了为何区块链能成为未来的技术核心。","author":"头等仓区块链研究院","source_media":"金色财金","source_addr":"https:\/\/www.jinse.com\/blockchain\/549564.html"},{"time_utc":"1576317668","title":"北京互金协会易欢欢:国家数字货币才是最大的区块链杀手级应用","desc":"
据和讯网消息,12月14日,在工信部电子五所指导、互链脉搏主办的“2019 In-Chain全球区块链峰会”上,北京互联网金融行业协会副会长易欢欢就区块链发展应用情况发表主题演讲。他表示,国家数字货币才是最大的区块链杀手级应用,且国家数字货币背后是强大的贸易和服务力量在支撑,有着较为庞大的C端市场。而从技术发展角度看,区块链将成为下一轮技术创新的关键突破口,是万物互联、5G、人工智能、量子计算等众多高新技术的底层架构。区块链应用的重点领域为数字金融、物联网、智能制造、供应链管理、数字资产交易。<\/p>","author":"陀螺快讯","source_media":"陀螺财经","source_addr":"https:\/\/www.tuoluocaijing.cn\/kuaixun\/detail-98330.html"},{"time_utc":"1576316330","title":"火币大学校长于佳宁:把握5G最好的切入点就是区块链","desc":"
12月14日,在互链脉搏主办的“IN-Chain全球区块链峰会”上,火币大学校长于佳宁发表主题为《5G时代的“区块链+产业协同”》的主题演讲。他表示,把握5G最好的切入点就是区块链,在5G时代要有区块链思维。区块链本身是重要的新物种,不能简单用旧物种类比的方式看待。其威力就在于,它将网络效应、金融杠杆两个最重要的商业工具融合在了一起。<\/p>\n
于佳宁最后总结称,区块链思维将是破解一切的钥匙,产业升级的关键点。<\/p>","author":"陀螺快讯","source_media":"陀螺财经","source_addr":"https:\/\/www.tuoluocaijing.cn\/kuaixun\/detail-98329.html"},{"time_utc":"1576315805","title":"传统金融或将迎来收益最惨淡的十年:是否能催生加密货币的春天?","desc":"许多华尔街资深人士都认为, 未来十年,股票和债券的回报速度将减慢。","author":"头等仓","source_media":"8比特","source_addr":"https:\/\/www.8btc.com\/article\/533116"},{"time_utc":"1576315586","title":"科普 | 加密衍生品的流动性机制","desc":"在本文中,我们将介绍不同的流动性和交易机制。","author":"以太坊爱好者","source_media":"8比特","source_addr":"https:\/\/www.8btc.com\/article\/533174"},{"time_utc":"1576314887","title":"瑞典央行表示将启动数字货币试点项目","desc":"瑞典中央银行周五表示将与咨询公司埃森哲(Accenture)签署协议,为其数字货币电子克朗(e-krona)创建一个试点平台。","author":"金色财经 meio","source_media":"金色财金","source_addr":"https:\/\/www.jinse.com\/news\/blockchain\/549589.html"},{"time_utc":"1576314690","title":"中国移动10086:提醒用户警惕以区块链名义的非法集资","desc":"据区块律动消息,12 月 13 日,中国移动10086推送短信提醒,提醒用户警惕以区块链名义的非法集资。 中国移动短信显示:省处非办提示您,科学理性看待区块链技术创新和应用,警惕不法分子炒作区块链概念,以虚拟货币、区块链商城、区块链游戏等名义非法集资,谨防受骗。","author":"陀螺快讯","source_media":"陀螺财经","source_addr":"https:\/\/www.tuoluocaijing.cn\/kuaixun\/detail-98328.html"},{"time_utc":"1576313123","title":"观察 | 5 张图描绘 2019 年 Web3 堆栈全景","desc":"时隔一年有余,投资机构 Multicoin 更新了 Web3 堆栈全景,用 5 张图描绘 2019 年 Web3 生态现状。","author":"区块链资讯","source_media":"8比特","source_addr":"https:\/\/www.8btc.com\/article\/533086"},{"time_utc":"1576312962","title":"中国人民大学副校长吴晓求:区块链的核心价值是数字经济的确权","desc":"区块链最重要的是数字经济的确权。数字经济时代许多产品的权属需要确认,确认了产权归属,市场经济才能健康稳定发展。","author":"雷锋网","source_media":"金色财金","source_addr":"https:\/\/www.jinse.com\/news\/blockchain\/549698.html"}]}
这样依照前面的方法,如果想获取新闻列表的话,直接访问获取
http://www.bxiaozhan.com/back/getnews.php?&offset=0&size=10
这个网址的就可以,而不需要在从页面上的html进行分析了。
至此!
爬虫的技术又近了一步!
附:
本文所说的币小站网址为:http://www.bxiaozhan.com
该网站所有代码位于:https://github.com/lihn1987/CoinCollector














 1926
1926











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









