






作者 | 张小七
导读
日志中台承载了百度千亿量级PV的埋点流量,如何对这些流量进行准确监控,并支持个性化字段的抽取、下钻,是日志中台的一大难题。本文简单介绍了日志中台的基本概念及实时流架构,并基于此深入讲解了低成本实现可扩展、高准确度的埋点监控的技术方案。
全文5899字,预计阅读时间11分钟。
01 引言
日志中台,作为百度数据埋点的全套一站式解决方案,目前已覆盖了厂内以手机百度 APP 作为代表的大多数重点产品,承载着每天千亿量级的埋点日志 PV。
埋点日志的实时监控,在日志中台应对突发流量、业务迭代埋点逻辑、埋点计费结算等场景中均发挥着不可或缺的作用。而在海量的数据下,如何对埋点日志进行精准地监控,保证监控的易用性、稳定性与准确性,是日志中台的一大难题。
本文首先对日志中台的 UBC 埋点相关概念进行了简单介绍,分析了埋点监控的需求,并深入讲解了埋点监控的架构设计,最后重点分析了实现过程中的难点、解决方案以及实践过程中的思考。
02 概念简介&需求分析
UBC(User Behavior Collection)即用户行为收集,是日志中台数据埋点的主流协议。按上报端的类型,分为 UBC 端日志、UBC Server 日志、UBC H5 日志三大类。
每条 UBC 日志中,都携带日志的 UBC ID,用于区分用户的不同行为。
2.1 UBC 打点类型
根据打点所表达的场景,UBC 日志可分为事件打点和流式打点。
事件打点用来记录一个单次行为,例如一次点击、一次列表页展示等,通常以 pv 作为统计值。
流式打点用来记录一个持续行为,例如一次视频观看、某功能的使用时长等。流式打点特有 duration 字段,用来表达行为的持续时间,通常 pv 和 duration 都会作为统计值。
2.2 公共参数与业务参数
UBC 日志中,部分参数是广泛存在于所有打点的,由 UBC 的打点 SDK 统一获取并上报,例如系统类型(Android/IOS 等)、设备 ID、APP 名称、APP 版本等。这些参数被称作公共参数。
除公共参数外,业务在打点时可自行定义其他参数,对同一类 UBC ID 的行为日志进行进一步细分。
例如:我们用 UBC ID = 10397 表达 Feed 业务的一次点击行为,这个点击可能来自不同的页面,便可以定义名为 from 的字段,用于区分点击的页面来源,按不同页面分别点击量 pv 和占比。
这些参数按照 UBC ID 粒度进行参数的管理,支持不同行为下,由业务个性化定义,被称作业务参数。
2.3 埋点监控需求分析
作为监控,需要应对突发流量、埋点变更等场景,必然对时效性有较高的要求。
同时,监控维度需要尽可能多样化,除了公共参数外,还需要能支持业务参数的自由组合。
结合上面的基本概念,我们可以得到埋点监控的核心目标:
1.能够有较高的时效性,在分钟级的延迟内查看埋点的数据趋势。
2.对于事件类型的打点,以 PV 作为统计口径;对于流式类型的打点,以PV和 总时长作为统计口径。
3.埋点数据和趋势,同时支持按照公共参数与业务参数组装筛选条件。
基于上述目标,我们结合目前日志中台的实时流架构,对埋点监控能力进行了方案设计。
03 整体方案
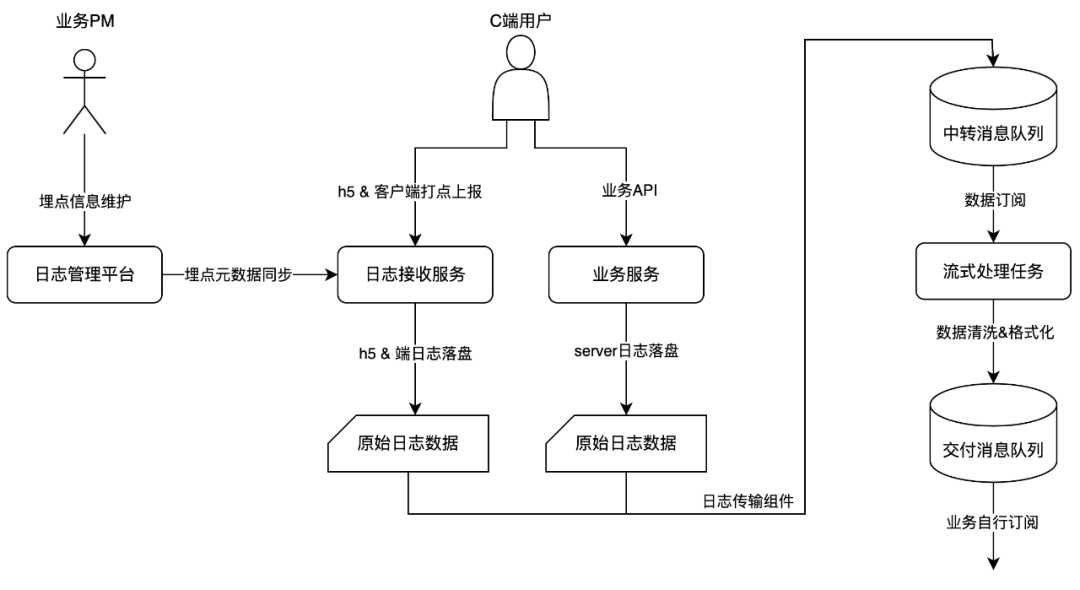
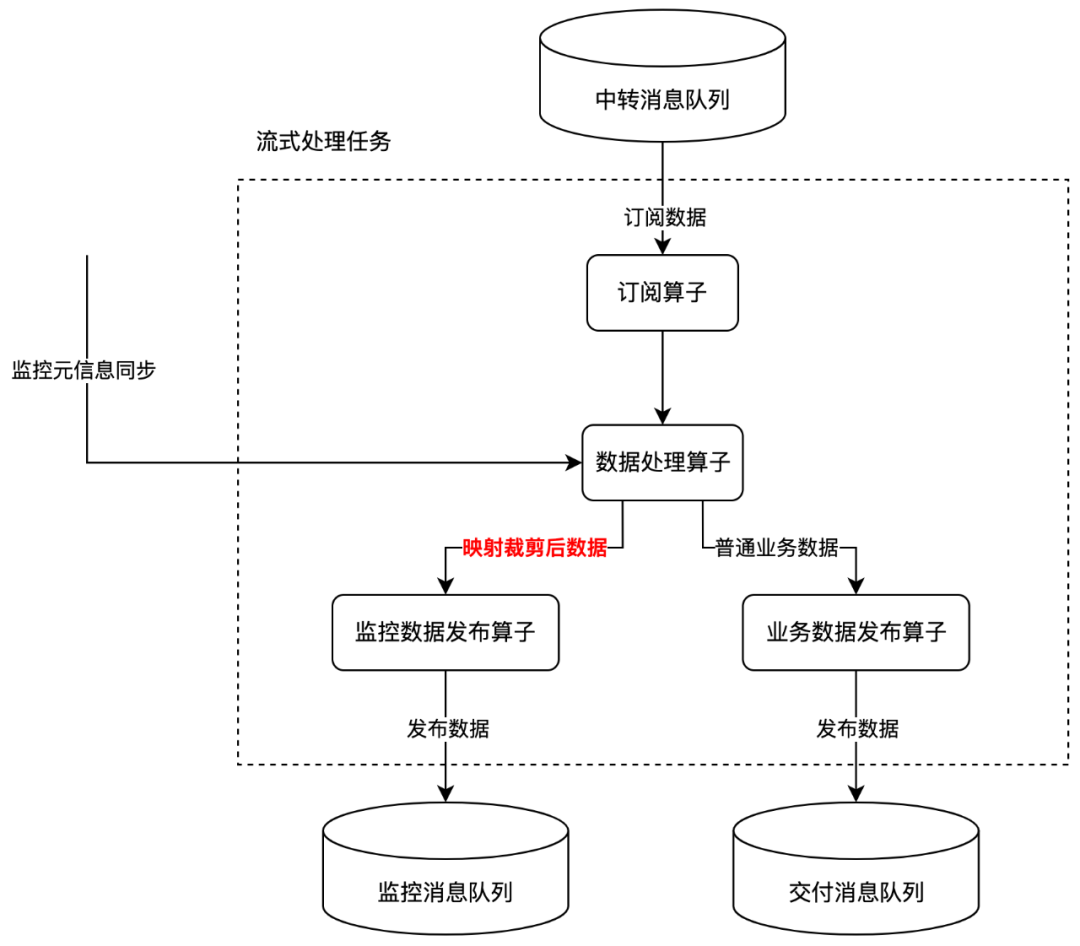
3.1 日志中台架构现状
日志中台的端日志与 H5 日志经由客户端 SDK 上报至专门的日志接收 server,初步解析后进行原始日志落盘。
Server 日志则有对应的业务服务直接按照指定的格式进行原始日志落盘。
落盘后的原始日志经由日志传输组件采集至中转消息队列,由流式任务订阅处理后交付给业务使用。
整体流程图大致如下:
3.2 埋点监控架构设计
尽管在线服务(日志接收服务、业务服务)作为日志处理链路的最上游,在时效性上有很大的优势(秒级)。
但考虑到以下几点:
1.日志接收服务仅对日志上报的部分公共参数做了简单的解析处理,作为数据上报的第一站,应当尽可能规避业务逻辑的入侵。
2.业务服务由各个业务团队维护,埋点监控的设计也不宜对业务由过多耦合,否则长期难以维护。
3.原始日志数据以字符串形式保留了绝大部分日志信息,对各种业务参数都未做解析。
不论基于在线服务,还是基于原始日志数据,产出我们期望的低延迟、可由业务参数个性化筛选的监控数据,都是不合适的。
所以我们考虑基于流式任务产出的数据去统计所需的监控,牺牲少量的时效性(从秒级到分钟级),去换取更高的可维护性和架构合理性。
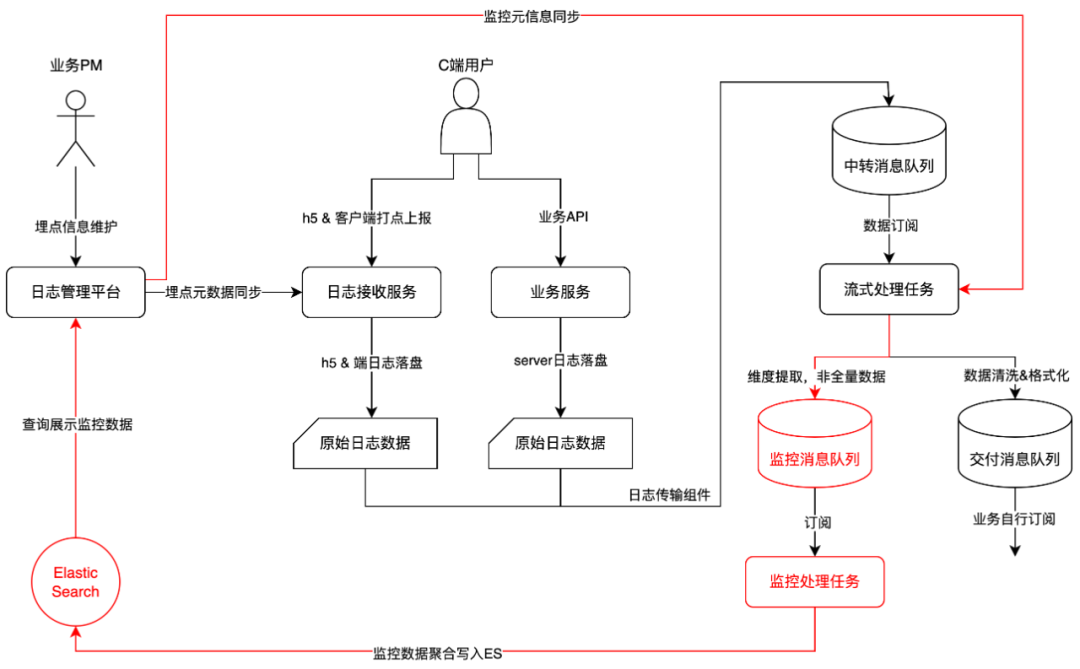
日志管理平台:与业务 PM 交互,负责维护监控元信息(例如打点类型、监控采集规则等)与监控数据查询展示。
流式处理任务:定期同步监控元信息,根据元信息将 UBC 日志数据转化为带维度信息的监控数据,剔除冗余信息。
监控消息队列:传输维度提取后的监控数据,解耦监控处理任务和流式处理任务,避免监控处理影响原有的实时数据交付。
监控处理任务:对监控进行聚合,从单条日志聚合为时间区间统计值(区间内 pv、区间内 duration)。
04 难点与解决
4.1 如何避免维度膨胀
埋点上报的公共参数是有限个可枚举的,但一旦涉及业务参数,监控维度的取值就可能千变万化。
如果在监控指标中每个配置的业务字段都映射为一个维度列,将产生大量膨胀冗余的维度:
1.行为 A 的业务参数,在行为 B 中是没有定义,不会上报的。
2.监控所需的业务字段可能会动态变化,曾经采集过的维度有历史数据,但将来可能不再使用。
为了避免不同 UBC ID 的业务字段差异,导致的维度膨胀冗余问题,我们在维度提取时对维度进行了映射,提供了至多6个自定义筛选维度项,并支持了1对1、多对1两种映射逻辑:
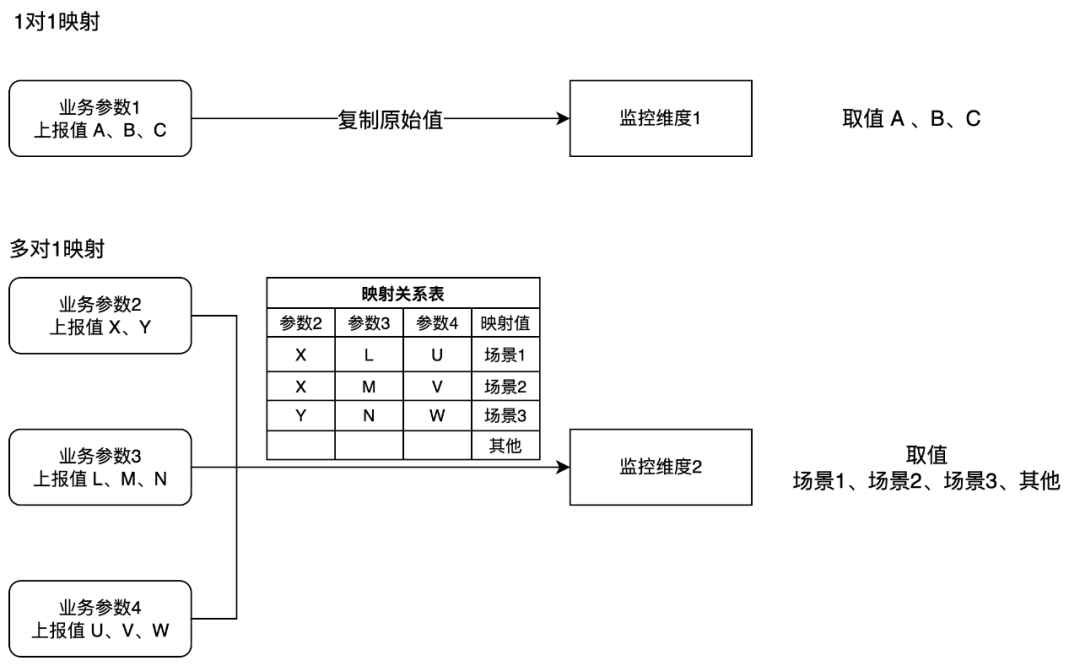
映射逻辑由业务 PM 在日志管理平台上动态维护,并打包为监控元信息,以接口形式定时同步给流式处理任务。
通过映射,我们支持了理论上无限多个业务参数参与维度筛选计算,同时也保证了维度列数不会无限制膨胀。
4.2 如何防止数据偏移
日志中台的实时流架构,保障了数据的不重&不丢。
在系统面临极端场景,例如流量短时间内暴涨、基建故障等情况时,为保障数据的准确性,打点数据可能发生拥堵或停发,导致数据暂时延迟,待异常恢复后追齐。
业内常见的在线服务监控设计下,监控指标是对在线服务运行状态的观测值,也即监控曲线图上会因为数据的拥堵/停发,到最终恢复而发生数据偏移:
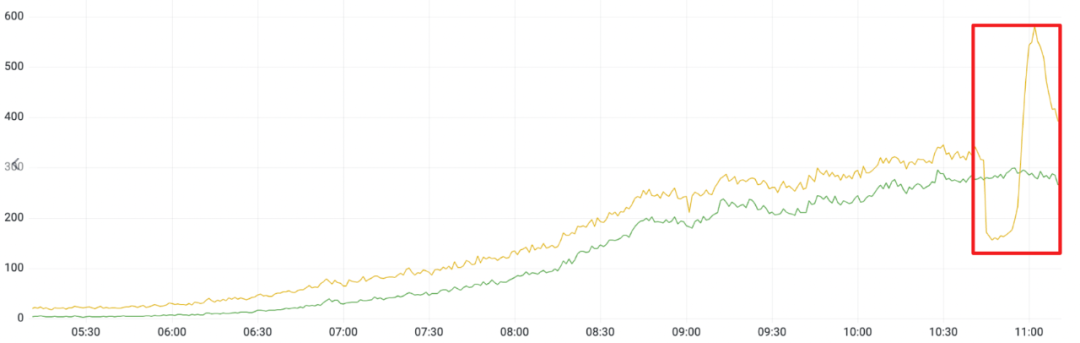
△异常导致部分数据延迟,恢复后追齐
虽然这个曲线反映了服务端的处理流量,但埋点作为对真实用户行为的观测,追求的是更真实源自客户端上报的流量曲线,理应不受服务端任何异常的影响。
因此,常见的基于在线服务监控的技术方案并不适用于埋点监控的场景。
为了使埋点监控能真实反映打点上报的趋势,不受服务端拥堵停发影响,我们参考了流式数据处理的思想,在监控中引入了水位(watermark)的概念。
4.2.1 水位概念简介
水位(watermark)是流式数据处理中的一个常见概念,通常是一个时间戳,表达已经处理完毕数据的最大时间戳。
举例:当前水位推进到时间 t 时,意味着 t 时刻以前的数据都已处理完毕,不会再出现。基于这个设定,我们可以认定 t 时刻之前的统计数据不会再发生变化。
实际生产环境中,由于存在长尾数据,难以达到所有 t 时刻以前的数据都已完成处理的理想情况,所以我们通常会设定一个容忍度百分比(例如 99.9%)。
4.2.2 水位在埋点监控中的应用
业内常规的在线服务监控中,通常以自然时间作为横轴。
为了规避数据偏移的问题,我们抛弃了这个设定,改用打点日志的上报时间作为横轴,以水位作为监控推进的基线。
水位之前的统计数据为确定值,水位之后的数据因为还在处理中,可能随时间发生变化。
最终剔除了服务端导致的数据偏移问题,效果如下:
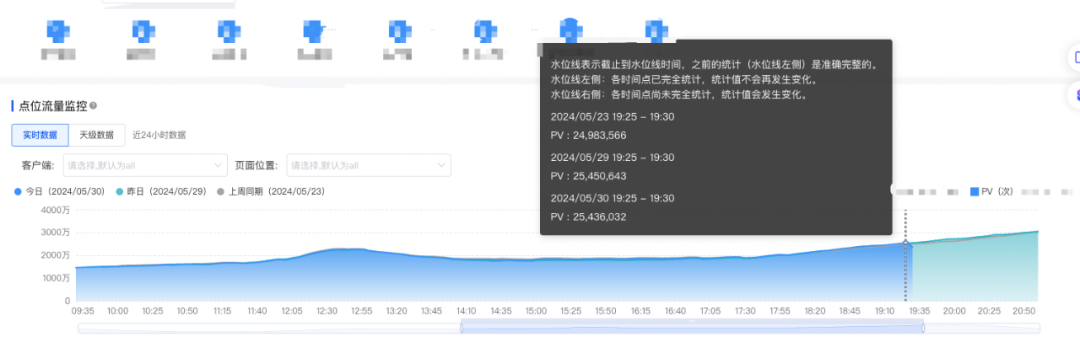
△以上报时间为横轴的监控
4.3 如何降低监控成本
日志中台承载了百度厂内几乎所有 APP 的埋点流量,数据的峰值超过 200W QPS,天级的 PV 也是千亿级别。
在这个数据量级下,保留原始的数据条数和内容,不论是处理、存储还是检索,成本都将是一个天文数字。
监控不同于数据报表,只需要按照既定的维度条件检索出统计值即可,所以对监控数据进行简化、降维聚合是必要的。
4.3.1 监控数据裁剪
在4.1节中,我们提到了通过数据映射的方式解决维度膨胀的问题。
这意味着经过数据映射后,原始字段在后续的流程中已经冗余,真正有效的是映射后的字段,且数量可控。
我们在流式任务处理中定义了有别于常规业务数据的裁剪格式,由数据处理算子单独输出。
常规数据的平均长度为10KB/条,经过映射裁剪可降低到0.2 KB/条,减少了98% 的体积。
4.3.2 按时间聚合
埋点监控需要的是每个维度排列组合下的统计值,不需要每条数据的详情。
并且,在经过4.3.1节的裁剪后,数据详情也不再有实际意义。
故我们考虑将裁剪后的监控数据,按照时间区间聚合,仅保留 count (PV)与 sum(duration)运算后的统计值。
聚合通过监控处理流式任务实现:
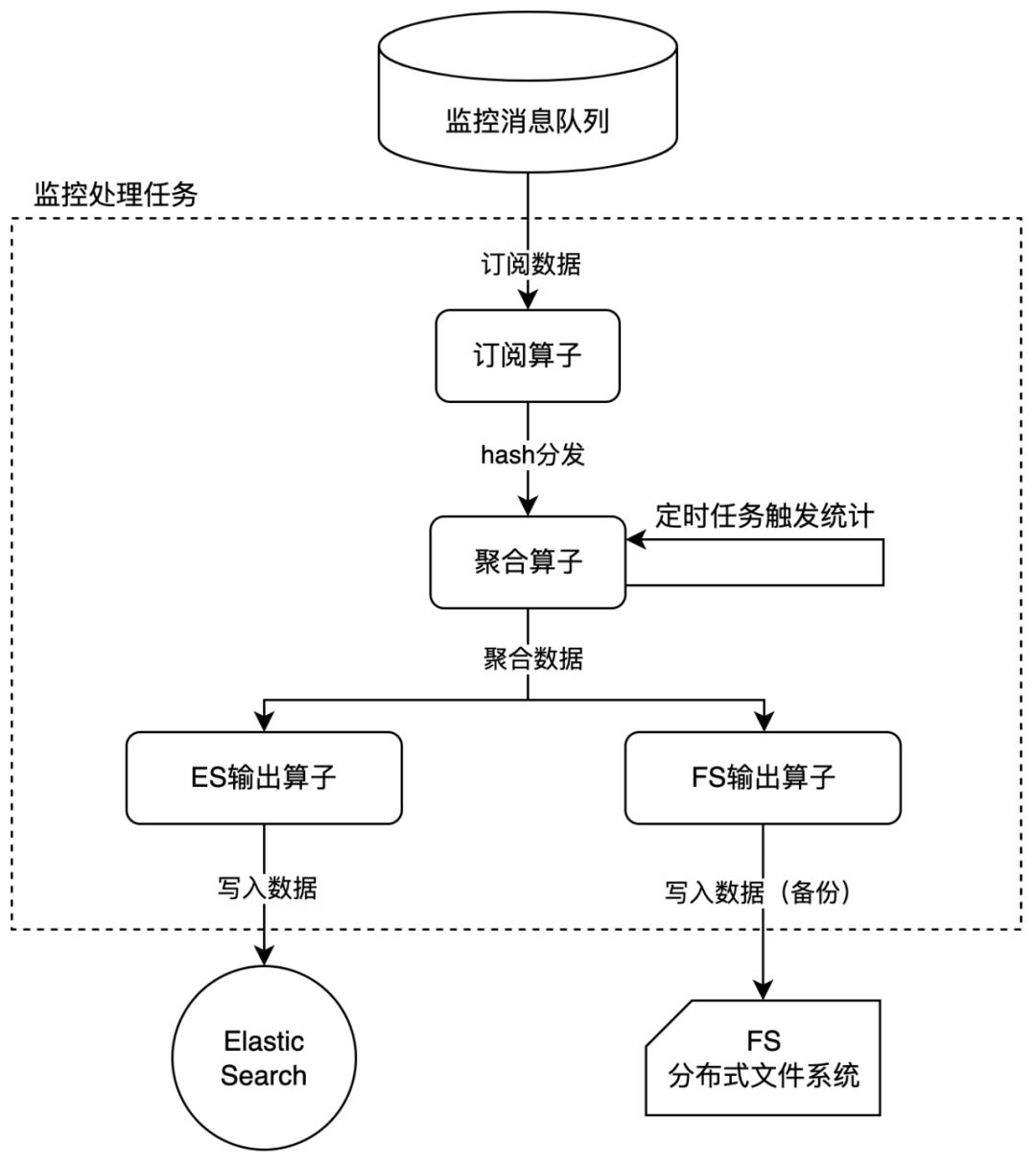
通过订阅算子通过维度组合的 hash 值,对监控数据进行分发,确保同一维度需要聚合的数据会被分发到同一个算子,规避多实例聚合问题。
聚合算子在内存中不断累加聚合值,由定时任务触发统计,输出聚合数据,并对当前累加值清零,进行下一个时间窗口的计算。
在输出数据给 ES 的同时,在分布式文件系统上同时进行了数据备份。
经过时间聚合,最终监控数据的量级仅由排列维度数时间区间长度决定。
以5min一个时间窗口为例,数据条数由原始的6亿条量级被聚合压缩到了10w条以内,下降幅度达到99.98%。
05 总结与展望
早在19世纪,热力学之父开尔文就曾提出「To measure is to know」。观测与监控的思想在自然科学中至关重要,在软件工程领域更是如此。
埋点监控功能在支持高度定制化筛选数据的同时,也通过添加映射、引入水位等手段,保障了数据的稳定性。同时通过数据裁剪、时间聚合等方式,极大降低了监控的运算、存储与检索成本。
日志中台作为观测用户行为的一站式解决方案,以支撑服务好百度的各个业务为己任,再未来的规划中,也将持续秉承简单可依赖的价值观,为业务提供更准确、更可靠、更优质的服务。
——————END——————
推荐阅读
Baidu Comate帮开发者“代码搬砖”,2天搞定原先3周工作量
















 971
971











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









