







目录
实验目的
实验目的
掌握词典编码的基本原理,用C/C++/Python等语言编程实现LZW解码器并分析编解码算法。
实验原理
- LZW编码
LZW的编码思想是不断地从字符流中提取新的字符串,通俗地理解为新“词条”,然后用“代号”也就是码字表示这个“词条”。这样一来,对字符流的编码就变成了用码字去替 换字符流,生成码字流,从而达到压缩数据的目的。LZW编码是围绕称为词典的转换表 来完成的。LZW编码器通过管理这个词典完成输入与输出之间的转换。LZW编码器的输 入是字符流,字符流可以是用8位ASCII字符组成的字符串,而输出是用n位(例如12位)表 示的码字流。
具体步骤如下图

- LZW解码
LZW解码算法开始时,译码词典和编码词典相同,包含所有可能的前缀根。
具体步骤如下图

实验结果
- LZW编码文件
创建txt文件如下
 经过编码,得到如下比特流文件
经过编码,得到如下比特流文件

- LZW编码实现
1.代码实现
DecodeString函数
int DecodeString( int start, int code){
//对当前码字的解码
int count;
count =start;
while(0 <= code){
d_stack[count] = dictionary[code].suffix;//写入d_stack
code = dictionary[code].parent;
count++;
}
return count;//返回字符串长度
}LZWDecode函数
void LZWDecode( BITFILE *bf, FILE *fp){
int character;//c
int new_code;//cw
int last_code;//pw
int phrase_length; //字符大小
unsigned long file_length; //文件大小
file_length = BitsInput(bf, 4 * 8);//得到文件长度
if (-1 == file_length){
file_length = 0;
}
InitDictionary();//dictionary初始化
last_code = -1;//码字为空
while (0 < file_length) {
new_code = input(bf);//读入码字
if (new_code >= next_code) //不存在码字
{
d_stack[0] = character;//c存入d_stack
phrase_length = DecodeString(1, last_code);//解码并计算字符串长度
}
else//存在码字
{
phrase_length = DecodeString(0, new_code);//解码
}
character = d_stack[phrase_length - 1];//第一个字符为c
while (0 < phrase_length) {
phrase_length--;//字符串大小
fputc(d_stack[phrase_length], fp);//写入文件
file_length--;//文件大小
}
if (MAX_CODE > next_code) {
AddToDictionary(character, last_code);//写入dictionary
}
last_code = new_code;//cw=pw
}
}2.解码结果
对1中编码得到比特流文件进行解码得到txt文件


- 压缩效率分析
1.压缩结果
选取了十种不同格式的文件如下

经过LZW编码,得到如下比特流文件

对比得到如下表格
| 文件格式 | 编码前文件大小 | 编码后文件大小 | 压缩效率(%) |
| txt | 154字节 | 142字节 | 92.2 |
| 13KB | 22KB | 169.2 | |
| jpg | 116KB | 156KB | 134.5 |
| png | 861KB | 1.1MB | 130.8 |
| bmp | 1.8MB | 2MB | 111.1 |
| yuv | 786KB | 829KB | 105.5 |
| mp3 | 590KB | 729KB | 123.6 |
| wav | 1.1MB | 1.2MB | 109.1 |
| avi | 2.3MB | 2.7MB | 117.4 |
| mp4 | 333KB | 413KB | 124.0 |
2.分析
LZW编码对于数据部分重复性高的文件压缩效果较好。以txt文件为例,我进行了两次txt压缩尝试,可以发现没有重复字节的txt文件没有被压缩。对重复性文字更多的文件,压缩效率获得了显著的提高。
| 原文件 | 原文件 大小 | 比特流文件 | 编码后 大小 | 压缩 效率 |
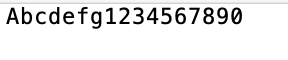 | 17字节 |  | 38字节 | 223.5% |
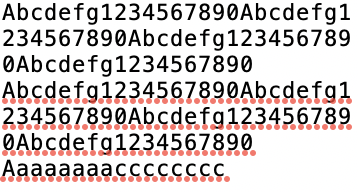 | 153 字节 |  | 142 字节 | 92.2% |
在几种图像文件格式中,是yuv或bmp的压缩效果较好,也是因为数据部分所展示的重复的像素数据部分较多,便于LZW的压缩。















 2791
2791











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









