









文章目录
- Linux
- 力扣合集
- 牛客shell脚本合集
- [SHELL1 统计文件的行数]
- [SHELL2 打印文件的最后5行]
- SHELL3 输出7的倍数
- [SHELL4 输出第5行的内容]
- [SHELL5 打印空行的行号]
- [SHELL6 去掉空行]
- [SHELL7 打印字母数小于8的单词]
- [SHELL8 统计所有进程占用内存大小的和]
- [SHELL9 统计每个单词出现的个数]
- [SHELL10 第二列是否有重复]
- [SHELL11 转置文件的内容]
- SHELL12 打印每一行出现的数字个数
- SHELL13 去掉所有包含this的句子
- SHELL14 求平均值
- SHELL15 去掉不需要的单词
- SHELL16 判断输入的是否为IP地址
- SHELL17 将字段逆序输出文件的每行
- SHELL18 域名进行计数排序处理
- SHELL19 打印等腰三角形
- SHELL20 打印只有一个数字的行
- SHELL21 格式化输出
- SHELL22 处理文本
- SHELL23 nginx日志分析1-IP统计
- SHELL24 nginx日志分析2-统计某个时间段的IP
- SHELL25 nginx日志分析3-统计访问3次以上的IP
- SHELL26 nginx日志分析4-查询某个IP的详细访问情况
- SHELL27 nginx日志分析5-统计爬虫抓取404的次数
- SHELL28 nginx日志分析6-统计每分钟的请求数
- SHELL29 netstat练习1-查看各个状态的连接数
- SHELL30 netstat练习2-查看和3306端口建立的连接
- SHELL31 netstat练习3-输出每个IP的连接数
- SHELL32 netstat练习4-输出和3306端口建立连接总的各个状态的数目
- SHELL33 业务分析-提取值
- SHELL34 ps分析-统计VSZ,RSS各自总和
Linux
课程
Linux 体系结构
体系结构主要分为用户态(用户上层活动)和内核态
内核:本质是一段管理计算机硬件设备的程序
系统调用:内核的访问接口,是一种能再简化的操作
公用函数库:系统调用的组合拳
Shell :命令解释器,可编程
ls: 当前目录文件
cat noh.out :查看文件内容
vi empy.sql:对文件做增删改查
vim empy.sql:对文件做增删改查(常用)
如何查找特定文件find
find 作用:在指定目录下查找文件
从当前目录递归查找
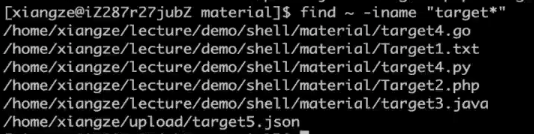
find -name "target3.java"

进行全局搜索
find / -name "target3.java"
所有以target开头的文件
find ~ -name "target*"

将大小写一网打尽
find ~ -iname "target*"
总结
如何查找特定的文件
面试里常用的方式
find ~ -name"target3.java"精确查找文件
find ~ -name"target*":模糊查找文件
find ~ -iname"target*":不区分文件名大小写去查找文件
man find:更多关于find指令的使用说明
检索文件内容grep
全称:Global Regular Expression Print
作用:查找文件中符合条件的字符串
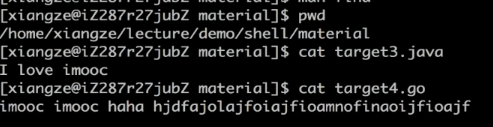
查找包含moo的以target打头的文件
grep "moo" target*

查找包含haha的以target打头的文件
grep "haha" target*

只会筛选出目标字符串所在的行
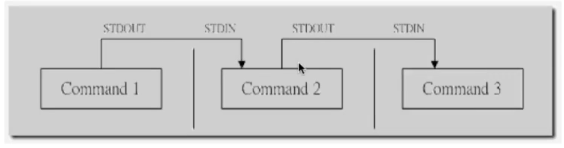
**管道操作符| **
可将指令连接1起来,前一个指令的输出作为后一个指令的输入
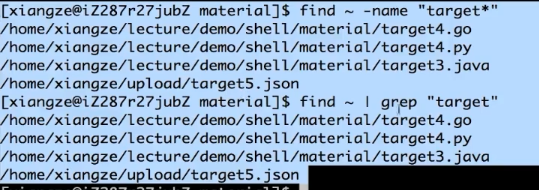
显示已target打头的文件
find ~ -name "target*"

find ~ | grep "target"
左边递归列出所有的文件以及目录
右边将左边作为输入进行检索
使用管道注意的要点
只处理前一个命令正确输出,不处理错误输出

右边命令必须能够接收标准输入流,否则传递过程中数据会被抛弃

常用来检索文件内容的命令有
sed,awk,grep,cut,head,top,less,more,wc.join,sort,split等
退出
:q
筛选出bsc-plat-al-data.info.log文件中partial为true的行
grep 'partial\[true\]' bsc-plat-al-data.info.log
做进一步筛选
grep 'partial\[true\]' bsc-plat-al-data.info.log | grep -o 'engine\[[0-9a-z]*\]'
ps -ef | grep tomcat

过滤最后一行的命令 grep -v
ps -ef | grep tomcat | grep -v "grep"

总结
检索文件内容
面试里常用的方式
查找包含某个字段的文件并将文件的行展示出来
grep'partial[truel'bsc-plat-al-data.info.log
选择符合正则表达式的内容
grep -o 'engine\[[0-9a-z]*\]'
过滤掉包含字符串的内容
grep -v 'grep'
对文件内容做统计 awk
语法:
一次读取一行文本,按输入分隔符进行切片,切成多个组成部分
将切片直接保存在内建的变量中,$1,$2…($0表示行的全部)
支持对单个切片的判断,支持循环判断,默认分隔符为空格

要获取第一列和第四列的信息
awk '{print $1,$4}' netstat.txt
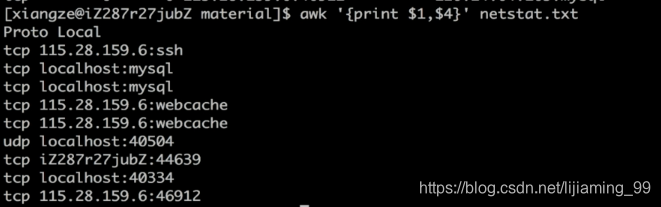
在netstat.txt文件中筛选出第一列为tcp第二列为1的所有行
awk '$1=="tcp" && $2==1{print $0}' netstat.txt

显示出表头NR==1
awk '($1=="tcp"&& $2==1) || NR==1 {print $0}' netstat.txt

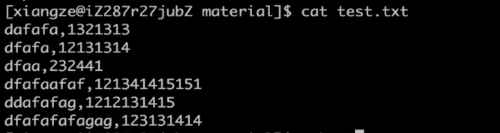
在test.txt中以逗号进行分割
-F 表示以什么符号作为分割符
awk -F "," '{print $2}' test.txt
awk还可以进行统计操作
分析:
定义一个数组,用他的下标来保存引擎的名字,一旦出现相同的名字就在原来基础上累加
END 扫描结束后什么操作,一跟操作相关,后面就需要加{},结束之后遍历数组,将下标和对应的值打印出来
grep 'partial\[true\]' bsc-plat-al-data.info.log | grep -o 'engine\[[0-9a-z]*\]' | awk '{enginearr[$1]++}END{for(i in enginearr)print i "\t" enginearr[i]}'

总结
对文件内容做统计
面试里常用的方式
筛选文件某些列的数据(筛选文件可以是多个)
awk '(print $1,$4)' netstat.txt
依据某些条件筛选文件某些列的数据
awk '$1=="tcp" && $2==1{print $0}' netstat.txt
对内容逐行进行统计操作并列出相应的统计结果
awk '{enginearr[$1]++}END{for(i in enginearr)print i "\t" enginearr[i]}'
批量替换掉文档里面的内容

sed 对文本内容进行处理
全名stream editor,流编辑器适合用于对文本的行内容进行处理
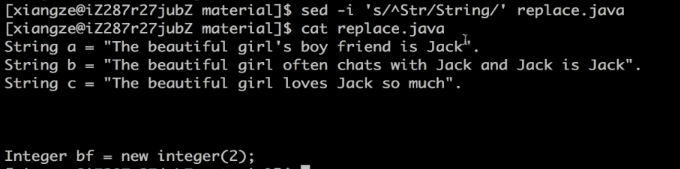
替换Str为String
^Str以某某打头的被替换的内容
s字母表示要进行字符串的操做
Sting表示要被替换成的目标内容
-i 改变文档内容,要不是只是输出在终端
sed -i 's/^Str/String/' replace.java
将结尾的.变为;号
.转义对.号转义
$ 以某某结尾
sed -i 's/\.$/\;/' replace.java
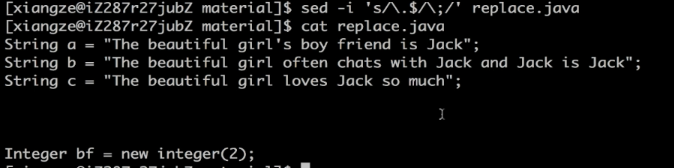
替换jack为me
g表示全部替换,不加的话每一行只替换一个
sed -i 's/Jack/me/g' replace.java
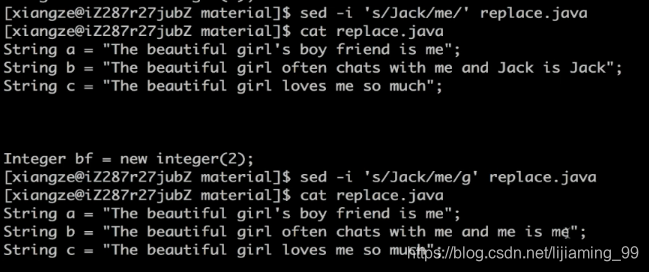
总结:
批量替换文本内容
面试里常用的方式
筛选出以Str打头的行,并将Str替换为String,-i 为了在目标文本上进行修改
sed -i 's/^Str/String/' replace.java
筛选出.号结尾的行,并将.号替换为;号
sed -i 's/\.$/\;/' replace.java
筛选出Jack的行,并将Jack替换为me
g 表示对整行的内容进行替换,没有g表示只替换第一个符合条件的字符串
sed -i 's/Jack/me/g' replace.java
删除空行
d表示要删除符合条件的行
^ 与*$要有空行
sed -i '/^ *$/d' replace.java
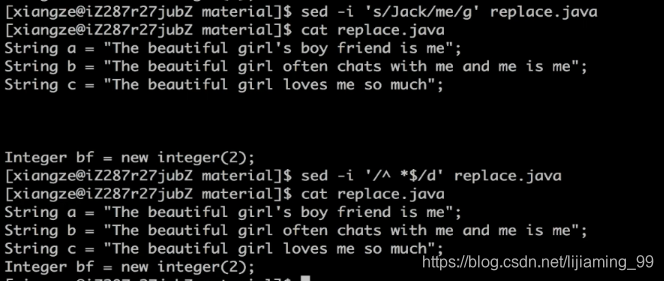
删除Integer所在的行
sed -i '/Integer/d' replace.java

sed还能移动和搜索数据
本章小结
面试经常涉及到的Shell指令
find 文件检索需求
grep 文件内容检索需求
管道操作符|
awk 数据抽取和统计
sed 批量编辑文件
Linux目录结构
FHS标准(Filesystem Hierarchy Standard):
/boot:启动目录,内核存放地
/etc:配置文件存放地
/tmp:程序产生的临时文件
/home:用户的目录,新增用户账号时,用户的家目录都存放在此目录
/ib:库文件,程序在执行过程中,需要调用一些额外的参数时需要函数库的协助
/bin:可执行文件和常用的Linux命令
/sbin:系统管理员的命令和工具
/usr:应用程序和文件的安装地
/mnt:挂接其他文件系统
/root:root帐户的home目录
/dev:存放linux系统下的设备文件
查看特定文件下的文件
ls /dat01
根目录下的东西
ls /
以详细形势展示文件
ls -l /home/shaofa
查看当前位置
pwd
切换位置
cd
切换到主目录或者上级目录
~ 代表当前用户的主目录1
. 代表当前目录
.. 代表上一级目录
cd ~ 切换到主目录
cd ~/example切换到主目录下的example目录
cd ../www 切换到上级目录、再到www子目录
在1s命令中,也可以使用- . ..表示的路径
ls ~
ls ./www
目录操作
目录操作
mkdir,即make directory创建目录
mkdir abc
mkdir -p abc/123/test 使用-p参数,可以将路径的层次目录全部创建rmdir,创建多级目录
即remove directory删除空目录rmdir abc如果目录非空,则删除失败
目录操作
rm,即remove删除文件或者目录
rm-rf abc删除abc目录,和子项一并删除
其中,r表示recursive,f表示force
一个程序员界的玩笑:rm-rf /*删库跑路?
目录操作
cp,即copy复制文件或者目录
将example复制为example2
cp -rf example example2
mv,即move,移动文件或目录(重命名)
将hello改为helloworld
move hello helloworld
要点与细节
对于文件,rm/cp/mv这三个命令同样适用
归档
tar,即tape archive档案打包1创建档案包
tar -cvf example.tar example
其中,c,表示create创建档案
v,表示verbose显示详情
f,表示file
也可以多个目录打包
tar-cvf xxx.tar file1 file2 file3
归档
还原档案包
tar -xvf example.tar
tar-xvf example.tar-C outdir/
其中,-C参数指定目标目录 后面加outdir/表示要解压的目录,默认解到当前目录下
归档并压缩
先前的tar格式并没有压缩,体积较大
并档并压缩
tar-zcvf example.tar.gz example/
解压缩
tar-zxvf xample.tar.gz
tar-zxvf example.tar.gz-C outdir/
通常我们所见的,都是*tar.gz这种格式
软链接
软链接,即Windows下的"快捷方式"
使用In命令(link)来创建软链接
ln-s source link
其中,-s表示soft软链接(默认为硬)
比如
为example创建example2的快捷方式
ln -s example example2
软链接
软链接的特点:
1删除软件接,对原文件没有影响
2删除原文件,则软链接失效
以ls -l查看文件详情时,可以看到目标路径比如,ls -l/
可以发现,/bin实际指向的是/usr/bin目录
添加用户
本章介绍用户的管理操作
比如,添加一个用户
sudo useradd -m testl
其中,sudo,表示以管理员身份执行
用户管理
1添加用户
sudo useradd -m test1
其中,-m参数表示在/home下添加用户目录
2修改用户密码
sudo passwd test1
3删除用户
sudo userdel test1
删完用户之后还需要额外删除文件
sudo rm -rf /home/test1/
要点与细节
1在登录系统时,默认不允许以root用户登录
2只有特殊的用户,才能执行sudo
比如,shaofa可以执行sudo,但test1不行
Linux下,把能执行sudo命令的用户叫sudoer
超级用户
超级用户root
类似于Windows下的Administrator用户
切换到root用户,有全部权限,可以直接useradd等命令
超级用户
1 首次使用时,需要给root设置密码
sudo passwd root
2 切换到root用户
su root
其中,su表示switch user
3 退出
exit
要点与细节
1 su root仅仅对当前会话(终端)有效
不影响当前桌面环境
2 root 权力 太大,需要小心使用
用户和组
Linux下可以创建多个用户,可以用组进行管理用户。
比如:
男生组 boys
ming bo gang qiang
女生组 girls
fang hong yue yuan
创建组
groupadd boys
创建用户
useradd -m -g boys ming
其中,-g表示在添加用户,同时将用户加到boys组
修改现有用户到新的组
usermod -g boys shaofa
其中,usermod表示修改用户信息
如何查看用户和组?
cat /etc/group
每一行表示一个group的信息,名称+ID
如何查看用户列表?
cat /etc/passwd
每一行表示一个用户的信息
要点与细节
1用户不多时,管理的时候并不使用组的概念
useradd a1
useradd b1
一个root,两个普通用户a1,b1,够用了!
默认地,会给a1用户建立一个同名的组a1,也就是说这个组里只有他一个人。
文件的权限
本章讨论文件的权限问题
考虑以下几个方面:
-owner:文件的 owner
-r:文件是否可读read
-w:文件是否可写write
-x:文件是否可以执行excute
文件的权限
使用ls命令查看一个文件
Is -l simple.txt
-rw-r–r–.1 shaofa shaofa 13 4月21 03:48 simple.txt
其中,-rw-r–r–表示该文件的访问权限
可执行脚本
脚本Script,一种解释执行的程序
Linux下常见的三种脚本程序
-Shell脚本*.sh
Perl脚本*.pl
-Python脚本*.py
可执行脚本
脚本程序,本质是一个文本文件
1它是一个文本文件
2它具有可执行权限
执行
./hello.sh
或者
/bin/sh hello.sh
./hello.py
或者
/bin/python3 hello.py
Shell脚本
Shell脚本,按Shell的语法写出来的脚本
是Linux自带的脚本语言
相当于Windows下的DOS批处理脚本
Shell 脚本
1编辑一个文本文件,保存为hello.sh
#!/bin/sh echo"hello,world"
2添加可执行权限
chmod +x hello.sh
3执行程序
./hello.sh
或者
/bin/sh hello.sh
要点与细节
1第一行必须声明解释器
#!/bin/sh
2必须有x权限,才能够执行比如,一个程序只有作者执行,别人不能执行
rwxr–r–
3执行程序时,必须加上路径
./hello.sh
/home/shaofa/hello.sh
Python脚本
1 编辑一个文本文件,保存为hello.py
2 添加可执行权限
chmod +x hello.py
3 执行程序
./hello.py
环境变量
定义环境变量
export OUTDIR=/opt/
显示环境变量
echo ${OUTDIR}
查看所有环境变量
printenv
环境变量
环境变量的使用:
1、可以在当前终端中使用
2、可以在SHELL脚本中调用
用户环境变量
用户环境变量:
定义在~/.profile中
在主目录下
ls -la
其中,a表示all,显示所有文件
注:在Linux下,以.开头的文件为 隐藏文件
ls 查看文件
ls -a 查看所有的文件包含隐藏文件
用户环境变量
1 用文本编辑打~/.profile
gedit ~/.profile
2 添加
export JAVA_HOME=/opt/jdk1.8
保存并关闭
3 注销,重新登录后生效
echo $JAVA_HOME
要点与细节
1 以点号,开头的文件为隐藏文件
ls -a
查看所有文件
2 此配置只对当前用户有效
因为每个用户都h自己t配置文件 .profile
3 有的Linux系统上,使用 .bash_profile
系统环境变量
系统环境变量:定义在/etc/profile中
此中的环境变量对所有用户有效
以root身份执行
gedit /etc/profile
但是,一般不直接修改/etc/profile
而是在/etc/profile.d/创建一个自定义的脚本
系统环境变量
演示:
1 用gedit创建一个脚本
gedit /etc/profile.d/myprofile.sh
2 定义环境变量
export TOMCAT=/opt/tomcat
3 注销并重新登录
重新登录后,环境变量生效
echo $TOMCAT
PATH环境变量
PATH,最常见的一个环境变量
用于描述可执行程序的搜索路径
echo $PATH
多个路径之间以冒号分隔
usr/local/bin:/usr/local/sbin:/usr/bin:/usr/sbin
PATH环境变量
默认地,系统从以下目录中搜索可执行程序
/usr/bin 比如,/usr/bin/tar
/usr/sbin 比如,/usr/sbin/useradd
/usr/local/bin
/usr/local/sbin
其中,sbin为超级用户root才能执行的程序
/usr/下系统自带的程序,/usrlocal/是用户安装的程序
PATH环境变量
演示:修改PATH环境变量。
1 编辑/etc/profile.d/myprofile.sh
设定PATH环境变量
export PATH=$PATH:/opt/tomcat/bin
2 注销,重新登录后生效
FTP服务器
思考:怎么把文件传到Ubuntu主机上?
1 U盘拷贝
2 网络传输
- FTP
- SFTP
文本编辑vi
vi/vim,一个基于控制台的文本编辑器
gedit,一个基于GUI的文本编辑器
其中,vim是vi的升级版,演示使用vim命令
文本编辑vi
1 打开文本编辑
vim abc.txt
如果目标文件存在,则打开编辑;如果不存在,会新建一个文件
如果系统上没有vim,就安装一下:
sudo apt install vim
文本编辑vi
2 切换模式
编辑模式Insert Mode:按 i 键
命令模式Command Mode:按ESC键
3退出编辑
(1)按ESC键,进入命令模式
(2)
输入:wq 保存并退出
输入 :q退出
输入 :q!强制退出(放弃保存)
文本的编辑
Linux文本文件的编辑
1、桌面环境:gedit
2、终端环境:
-少量修改:vim
大量修改:在Windows上编辑,然后上传到Linux
注意:只有在编辑SHELL脚本时,才需要转换
文本文件的换行符
演示:Shel脚本的编辑。。
1用Notepad++打开编辑
2转成Unix格式
3上传至Linux
4 chmod +x
本章内容
本章介绍在Ubuntu下的Java环境
1 JDK/JRE的安装
2 Java的环境变量
3 运行普通Java程序
4 Java程序的运行脚本
Java及环境变量
安装openjdk-8-jre-headless
ls /usr/bin/java
默认放在/usr/bin下,不需要额外设置PATH
提示:如果放在自定义位置,需要设置PATH
export PATH-$PATH:/optjdk8/bin
运行Java程序
1 在Windows上开发和调试
2 发布
class文件
普通JAR文件/可执行JAR文件
两种JAR文件的运行方式不同:
java-cp your program.jar your.MainClass
java-jar your program.jar
Java控制台程序
3 上传至Linux:FTP/SFTP
4 运行程序
java-jar simple.jar
5 权限因素,自行检查
程序里需要访问系统文件,如/etc/,得用root运行
程序里需要开启TCP端口,如80,得用root运行。。
创建运行脚本
使用run_java.sh来运行java程序
1 修改run_java.sh
2 转成UNIX风格
3 上传至Linux
4 添加+x权限,运行脚本
要点与细节
在Windows上编辑SHELL脚本时,记得设置换行符
Windows:\r\n
Linux:\n
Tomcat服务器
以下操作用root身份执行
1 上传到Ubuntu
2 解压缩
tar-zxvf apache-tomcat-8.5.54.tar.gz
mv apache-tomcat-8.5.54 tomcat
3 运行Tomcat
tomcat/bin/startup.sh
4 检查tomcat进程是否在运行
ps-ef | grep java
netstat-anp | grep 8080
6 关闭防火墙ufw disable
7 访问网站http://192.168.43.128:8080
8 关闭Tomcat:
tomcat/bin/shutdown.sh
要点与细节
1 Tomcat需要有JAVA的运行环境
2 Tomcat作为网络服务器,应该以root执行
启动 startup.sh
关闭 shutdown.sh
Tomcat的配置
Tomcat的配置文件:
/opt/tomcat/conf/server.xml
至少需要修改:端口,应用目录
程序与进程
程序Program:指一个程序文件,如notepad.exe
进程Process:当一个程序运行起来,在操作系统内创建一条记录,用于描述和控制它的运行
比如,打开多个notepad.exe,则得到多个进程
程序与进程
演示:运行多个/usr/bin/vim,并观察进程信息
ps -ef
其中,各个字段的含义:
User:执行者
PID:进程ID
PPID:父进程ID
STIME:启动时间
CMD:启动时调用的命令行
程序与进程
按名称查找某个进程
ps -ef | grep java
其中,将前者输出的信息,重定向给grep命令过滤处理
进程监视
top命令,相当于Windows的任务管理器查看所有进程
top
-按上下键翻阅
-按q或CTRL+C中止退出
进程监视
查看某个进程
top -p NNN
其中,NNN为目标进程的PID
所以,可以先用ps命令查找目标进程的PID
杀死进程
使用kill命令,杀死一个进程
kill -9 NNN
或者
pkill name_of_progress
小结
进程管理的几个命令:
ps-ef
ps-ef I grep xx
top
top-p NNN
kill-9 NNN
okill name of program
CTRL + с中止当进程(台进程)
前台与后台进程
前台进程:运行在前台
后台进程:运行在后台
演示:
./run_tomcat run以前台方式运行(CTRL+C中止)
./run_tomcat start以后台方式运行
前台与后台进程
区别1:有无控制台
前台进程:
有控制台,输出至当前终端
后台进程:
无控制台,看不到输出
区别2:有无父进程
前台进程:
有父进程,父进程即为当前终端
当终端关闭时,前台进程被一同关闭
后台进程:
父进程为系统进程(1号进程)
当终端关闭时,后台进程不受影响
区别3:强行终山
前台进程:
使用CTRL+ C强行终止
后台进程:
使用kill -9 NNN强行终止
前台与后台进程
前台进程:
1 控制台:有控制台,输出至当前终端
2 关闭终端时将关闭前台进程
3 使用CTRL+C强行终止
后台进程:
1 无控制台,看不到输出
2 关闭终端对后台进程没有影响
3 使用kill -9 NNN强行终止
技巧:
1在输入命令和路径时,按TAB键可以自动补全
ls/ho 1s/home
2输入历史可以翻阅
按上下 +箭头键可以上下翻阅
3宿主机与虚拟机之间可以拷贝粘贴一般情况下,文本和文件都可以拷贝
4 ctrl+l 清屏操作或者输入clear
跳槽容易忽略的细节
面试要偷偷摸摸地进行
面试时间不要一味将就对方
提离职要谨慎
好聚好散
跳槽时间衔接:一般15号之后离职,下个月15号前入职社保不会断
力扣合集
195. 第十行
假设 file.txt 有如下内容:
Line 1
Line 2
Line 3
Line 4
Line 5
Line 6
Line 7
Line 8
Line 9
Line 10
你的脚本应当显示第十行:
Line 10
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/tenth-line
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
解题思路
打 印 第 十 行 :sed -n '10p' file.txt
打 印 一 到 十 行 :sed -n '1,10p' file.txt
查 找 指 定 字 符 :grep -n 'KeyWord' file.txt
打印指定字符上下5行:grep -C 5 'KeyWord' file.txt
打印指定字符上下N行:grep -A 100 -B 100 'KeyWord' file.txt
(-A after 后面, -B before 前面)
查找指定字符出现次数: grep -o 'KeyWord' file.txt | wc -l
......
代码
# Read from the file file.txt and output the tenth line to stdout.
sed -n '10p' file.txt
awk '{if(NR==10){print $0}}' file.txt
或者
NR表示行号
awk 'NR==10' file.txt
sed -n 10p file.txt
tail -n +10 file.txt|head -1
其中
tail -n +10 file.txt | head -1
注意:tail -n +10 与 tail -n 10 不一样,-n +10 表示从第 10 行开始显示,若文件不足 10 行则什么也不会输出;-n 10 表示显示最后的 10 行。
192. 统计词频
假设 words.txt 内容如下:
the day is sunny the the
the sunny is is
你的脚本应当输出(以词频降序排列):
the 4
is 3
sunny 2
day 1
参考题解
本题先用cat命令和管道命令|将文件内容传给awk。
在awk中我们用一个字典(?)count储存每个单词的词频,先遍历每一行(awk自身机制)的每一个字段(i<=NF),然后用该字段本身作为key,将其value++;最后用一个for循环输出count数组中的每个元素的key(词)及其value(词频)。
最后用|管道命令传给sort命令:
-r是倒序排序,相当于DESC
-n是将字符串当作numeric数值排序
-k则指定用于排序的字段位置,后跟2指将第二位的countk作为排序的key
awk '{for(i=1;i<=NF;i++){res[$i]+=1}}END{for(k in res){print k" "res[k]} }' words.txt | sort -nr -k2
NR是指awk正在处理的记录位于文件中的位置(行号)
NF是指awk正在处理的记录包含几个域(字段),这于域分隔符有关,默认为空
。
$i 文件中每行以间隔符号分割的不同字段
首先
对于words.txt文件进行词频统计,首先要做的事情就是把words.txt文件当中的每一个单词分割出来,分割出每一个单词可以使用以下两种方式:
使用awk命令:
[root@localhost ~]# awk '{for(i=1;i<=NF;i++){print $i}}' words.txt
the
day
is
sunny
the
the
the
sunny
is
is
其中NF表示当前记录的字段数(即列数)
$i 文件中每行以间隔符号分割的不同字段
如果对awk命令不熟悉,可以参考之前分享的一篇文章学习:
号称三剑客之首的awk,开始秀!
https://mp.weixin.qq.com/s/rIvOa5yvXFCAWiidxFz_ug
或者
使用xargs命令:
[root@localhost ~]# cat words.txt | xargs -n1
the
day
is
sunny
the
the
the
sunny
is
is
[root@localhost ~]# cat words.txt | xargs -n2
the day
is sunny
the the
the sunny
is is
xargs命令是用于给其他命令传递参数的一个过滤器,也是组合多个命令的一个工具。
-n选项,指定 输出时每行输出的列数
当我们将words.txt文件中的所有单词都分割出来之后,就可以统计这些单词当中每一个单词出现的次数了。
我们仅考虑使用awk命令来完成这个任务的话很简单,在进行分割的过程中直接用一个关联数组直接保存每一个单词出现的次数,关于关联数组的更多内容可以阅读:SHELL编程之变量与四则运算,此处我们可以暂时将关联数组理解为一个字典,关键字为单词,值为单词出现的次数(这样理解只是一种通俗的说法)
[root@localhost ~]# awk '{for(i=1;i<=NF;i++){asso_array[$i]++;}};END{for(w in asso_array){print w,asso_array[w];}}' words.txt
day 1
sunny 2
the 4
is 3
当然我们也可以在xargs的基础之上使用一些shell小工具来得到每个单词出现的次数。sort 工具及 uniq 工具,这里仅介绍我们解决问题使用的参数,关于小工具(grep、cut、sort、uniq、tee、diff、past、tr)可以参考之前的文章:
解题思路
对于words.txt文件进行词频统计,首先要做的事情就是把words.txt文件当中的每一个单词分割出来,分割出每一个单词可以使用以下两种方式:
使用awk命令:
[root@localhost ~]# awk '{for(i=1;i<=NF;i++){print $i}}' words.txt
the
day
is
sunny
the
the
the
sunny
is
is
其中NF表示当前记录的字段数(即列数)
$i 文件中每行以间隔符号分割的不同字段
如果对awk命令不熟悉,可以参考之前分享的一篇文章学习:
号称三剑客之首的awk,开始秀!
使用xargs命令:
[root@localhost ~]# cat words.txt | xargs -n1
the
day
is
sunny
the
the
the
sunny
is
is
[root@localhost ~]# cat words.txt | xargs -n2
the day
is sunny
the the
the sunny
is is
xargs命令是用于给其他命令传递参数的一个过滤器,也是组合多个命令的一个工具。
-n选项,指定 输出时每行输出的列数
当我们将words.txt文件中的所有单词都分割出来之后,就可以统计这些单词当中每一个单词出现的次数了。
我们仅考虑使用awk命令来完成这个任务的话很简单,在进行分割的过程中直接用一个关联数组直接保存每一个单词出现的次数,关于关联数组的更多内容可以阅读:SHELL编程之变量与四则运算,此处我们可以暂时将关联数组理解为一个字典,关键字为单词,值为单词出现的次数(这样理解只是一种通俗的说法)
[root@localhost ~]# awk '{for(i=1;i<=NF;i++){asso_array[$i]++;}};END{for(w in asso_array){print w,asso_array[w];}}' words.txt
day 1
sunny 2
the 4
is 3
当然我们也可以在xargs的基础之上使用一些shell小工具来得到每个单词出现的次数。sort 工具及 uniq 工具,这里仅介绍我们解决问题使用的参数,关于小工具(grep、cut、sort、uniq、tee、diff、past、tr)可以参考之前的文章:Shell编程之文本处理工具与bash的特性
[root@localhost ~]# cat words.txt | xargs -n1 | sort
day
is
is
is
sunny
sunny
the
the
the
the
[root@localhost ~]# cat words.txt | xargs -n1 | sort | uniq -c
1 day
3 is
2 sunny
4 the
sort工具用于排序,它将文件的每一行作为一个单位,从首字母向后按照ASCII码值进行比较,默认将他们升序输出。
-r : 降序排列
-n : 以数字排序,默认是按照字符排序的。
uniq用去取出连续的重复行
-c :统计重复行的次数
最后我们仅需要对上面的结果进行排序啦,很简单的使用sort就可以啦!
可运行代码
awk '{for(i=1;i<=NF;i++){asso_array[$i]++;}};END{for(w in asso_array){print w,asso_array[w];}}' words.txt | sort -rn -k2
cat words.txt | xargs -n1 | sort | uniq -c | sort -rn | awk '{print $2,$1}'
可以参考文章LeetCode上稀缺的四道shell编程题解析,内有更多资源。(这个必看好吧)
193. 有效电话号码
示例:
假设 file.txt 内容如下:
987-123-4567
123 456 7890
(123) 456-7890
你的脚本应当输出下列有效的电话号码:
987-123-4567
(123) 456-7890
方法1:
grep "^\(([0-9]\{3\}) \|[0-9]\{3\}-\)[0-9]\{3\}-[0-9]\{4\}$" file.txt
注意""不要丢了,其中的空格,()是普通字符," "不要丢了
^:表示行首,以...开始,这里表示以(xxx) 或者xxx-开始,注意空格
():选择操作符,要么是([0-9]\{3\}) ,要么是[0-9]\{3\}-
|:或者连接操作符,表示或者
[]:单字符占位,[0-9]表示一位数字
{n}:匹配n位,[0-9]\{3\}匹配三位连续数字
$:表示行尾,结束
一定要看链接,讲的太好了!!!!
awk '/^([0-9]{3}-|\([0-9]{3}\) )[0-9]{3}-[0-9]{4}$/' file.txt
194. 转置文件
示例:
假设 file.txt 文件内容如下:
name age
alice 21
ryan 30
应当输出:
name alice ryan
age 21 30
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/transpose-file
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
awk是一行一行地处理文本文件,运行流程是:
先运行BEGIN后的{Action},相当于表头
再运行{Action}中的文件处理主体命令
最后运行END后的{Action}中的命令
有几个经常用到的awk常量:NF是当前行的field字段数;NR是正在处理的当前行数。
注意到是转置,假如原始文本有m行n列(字段),那么转置后的文本应该有n行m列,即原始文本的每个字段都对应新文本的一行。我们可以用数组res来储存新文本,将新文本的每一行存为数组res的一个元素。
在END之前我们遍历file.txt的每一行,并做一个判断:在第一行时,每碰到一个字段就将其按顺序放在res数组中;从第二行开始起,每碰到一个字段就将其追加到对应元素的末尾(中间添加一个空格)。
文本处理完了,最后需要输出。在END后遍历数组,输出每一行。注意printf不会自动换行,而print会自动换行。
两种遍历shell的方式 我们可以把res理解为 Java里面的hashmap即可,是一个键值对,遍历的话直接遍历键再根据键取值即可
# Read from the file file.txt and print its transposed content to stdout.
awk '{ #这个大括号里的代码是 对正文的处理
# NF表示列数,NR表示已读的行数
# 注意for中的i从1开始,i前没有类型
for (i=1; i<=NF; i++){#对每一列
if(NR==1){ #如果是第一行
#将第i列的值存入res[i],$i表示第i列的值,i为数组的下标,以列序号为下标,
#数组不用定义可以直接使用
res[i]=$i;
}
else{
#不是第一行时,将该行对应i列的值拼接到res[i]
res[i]=res[i] " " $i
}
}
}
# BEGIN{} 文件进行扫描前要执行的操作;END{} 文件扫描结束后要执行的操作。
END{
#输出数组
for (i=1; i<=NF; i++){
print res[i]
}
}' file.txt
牛客shell脚本合集
[SHELL1 统计文件的行数]
awk 可以打印所有行的行号
$ awk '{print NR}' ./nowcoder.txt
1
2
3
4
5
6
7
8
9
该输出的最后一行就是文件的行数,结合 tail 就可以获取到文件的行数
$ awk '{print NR}' ./nowcoder.txt |tail -n 1
9
[SHELL2 打印文件的最后5行]
这个就是知道tail和head的用法就可以了
tail 文件名 默认显示文件后10行
tail -n 文件名 显示文件后n行
head 文件名 默认显示文件前10行
head -n 文件名 显示文件前n行
tail -n 5 nowcoder.txt
SHELL3 输出7的倍数
写一个 bash脚本以输出数字 0 到 500 中 7 的倍数(0 7 14 21…)的命令
输出0到500中7个倍数;
一、awk输出
awk '{for(i=0;i<=500;i++){
if(i%7==0){
print i
}
}}' nowcoder.txt
二、新学到的方案:
seq 0 7 500
【关于seq指令】
seq命令用于输出 连续的数字、 固件间隔的数字、指定格式的数字; 具体示例如下:
seq 用法
用法:seq [选项]... 尾数
或:seq [选项]... 首数 尾数
或:seq [选项]... 首数 增量 尾数
以指定增量从首数开始打印数字到尾数。
-f, --format=格式 使用printf 样式的浮点格式
-s, --separator=字符串 使用指定字符串分隔数字(默认使用:\n)
-w, --equal-width 在列前添加0 使得宽度相同【自动补位】
--help 显示此帮助信息并退出
--version 显示版本信息并退出
一、输出连续的数字
seq 1 100
表示: 输出所有1到100之间的数字;
二、输出固定间隔的数字
seq 0 7 500
表示: 输出所有 0到500内 7个倍数;
三、输出指定格式的数字
seq -s "+" 1 100
表示:输出1到100之间的数字,每个数字间由+号间隔;
seq -f "file%g" 1 10
表示:输出给是为: file1 到 file10 ; 如下:
file1
file2
file3
file4
file5
file6
file7
file8
file9
file10
[SHELL4 输出第5行的内容]
awk语法: awk ‘pattern{命令}’ 文件名 awk是数据解析工具,对数据逐行解析,默认以空格分隔
pattern 匹配模式 NR 是行数 NR==5 匹配第五行
{}中放匹配后要执行的命令, $0输出行的所有内容
awk 'NR==5{print $0}' nowcoder.txt
或者
awk '{if(NR==5){print $0}}' nowcoder.txt
sed 命令中的 p 子命令,打印第五行
p表示打印匹配行
sed -n 5p nowcoder.txt
head 和 tail 混用
head 命令拿到前五行,再通过通道,通过tail取出来最后一行,即第五行
head -n 5 nowcoder.txt | tail -n 1
[SHELL5 打印空行的行号]
#!/bin/bash
awk '/^$/{print NR}' nowcoder.txt
#!/bin/bash是设置Shell解析器类型为bash类型
awk是数据解析工具 对文件或管道数据、终端输入数据逐行解析 默认以空格分隔
awk语法:awk ‘pattern{命令}’ 文件名
// 是 awk 正则匹配模式的符号
^ 匹配输入字符串的开始位置
$ 匹配输入字符串的结束位置
NR 属于 awk 内部变量,表示:已经读出的记录数,就是行号
/^$/表示空字符串即该行是空字符串即空行
{}是对匹配的行执行的命令 NR是行号,即匹配行的行号
或者
sed正则匹配空行,=输出行数
sed使用: -n:使用安静(silent)模式; //是sed正则表达式匹配模式, 最后一个=,=作为sed命令打印行号: 例如(sed = nowcoder.txt),该命令会输出文件内容,且给每一行都加上行号,但是行号都在对应行内容的上一行,独立成行,因此使用-n,忽略内容等输出,只有经过sed特殊处理的那一行(或者动作)才会被列出来;
sed -n '/^$/=' nowcoder.txt
[SHELL6 去掉空行]
awk '{if($0!=""){print $0}}' ./nowcoder.txt
awk '!/^$/{print $0}' ./nowcoder.txt
#!/bin/bash
sed '/^$/d' nowcoder.txt
sed 是流式编辑器,主要用来对文件做增删改操作
sed是对文件做逐行读取,逐行匹配,匹配通过,执行sed命令,匹配不通过原样输出,默认不对源文件做修改,要修改加 -i 选项
sed命令语法:sed ‘pattern 命令’ 文件名
/^$/是空行匹配
d是删除命令,删除匹配的空行
grep 正则:匹配空行并删除 用-v(两种写法)
# 排除文件中符合表达式的行,并显示其他行
grep -v '^$' nowcoder.txt
[SHELL7 打印字母数小于8的单词]
NF是当前记录的字段数,也可以说是单词数;
awk '{for(i=1;i<=NF;i++){if(length($i)<8){print $i}}}' nowcoder.txt
[SHELL8 统计所有进程占用内存大小的和]
描述
假设 nowcoder.txt 内容如下:
root 2 0.0 0.0 0 0 ? S 9月25 0:00 [kthreadd]
root 4 0.0 0.0 0 0 ? I< 9月25 0:00 [kworker/0:0H]
web 1638 1.8 1.8 6311352 612400 ? Sl 10月16 21:52 test
web 1639 2.0 1.8 6311352 612401 ? Sl 10月16 21:52 test
tangmiao-pc 5336 0.0 1.4 9100240 238544 ?? S 3:09下午 0:31.70 /Applications
以上内容是通过ps aux | grep -v 'RSS TTY' 命令输出到nowcoder.txt文件下面的
请你写一个脚本计算一下所有进程占用内存大小的和:
利用awk的强大功能,由第一行开始读写,读到最后一行结束
awk 'BEGIN{sum=0}{sum+=$6}END{print sum}' nowcoder.txt
[SHELL9 统计每个单词出现的个数]
写一个 bash脚本以统计一个文本文件 nowcoder.txt 中每个单词出现的个数。
为了简单起见,你可以假设:
nowcoder.txt只包括小写字母和空格。
每个单词只由小写字母组成。
单词间由一个或多个空格字符分隔。
示例:
假设 nowcoder.txt 内容如下:
welcome nowcoder
welcome to nowcoder
nowcoder
你的脚本应当输出(以词频升序排列):
to 1
welcome 2
nowcoder 3
awk '{for(i=1;i<=NF;i++)a[$i]+=1}END{for(x in a){print x" "a[x]}}' nowcoder.txt|sort -nk 2
错误解答 r表示降序输出
awk '{for(i=1;i<=NF;i++)a[$i]+=1}END{for(x in a){print x" "a[x]}}' nowcoder.txt|sort -nrk 2

[SHELL10 第二列是否有重复]
描述
给定一个 nowcoder.txt文件,其中有3列信息,如下实例,编写一个shell脚本来检查文件第二列是否有重复,且有几个重复,并提取出重复的行的第二列信息:
实例:
20201001 python 99
20201002 go 80
20201002 c++ 88
20201003 php 77
20201001 go 88
20201005 shell 89
20201006 java 70
20201008 c 100
20201007 java 88
20201006 go 97
结果:
2 java
3 go
awk '{a[$2]+=1}END{for(x in a){if(a[x]>1){print a[x]" "x}}}' nowcoder.txt
[SHELL11 转置文件的内容]
写一个 bash脚本来转置文本文件nowcoder.txt中的文件内容。
为了简单起见,你可以假设:
你可以假设每行列数相同,并且每个字段由空格分隔
示例:
假设 nowcoder.txt 内容如下:
job salary
c++ 13
java 14
php 12
你的脚本应当输出(以词频升序排列):
job c++ java php
salary 13 14 12
awk '{
for(i=1;i<=NF;i++){
if(NR==1){
arr[i] = $i
}else{
arr[i] = arr[i]" "$i;
}
}
}END{
for(i=1;i<=NF;i++){
print arr[i]
}
}' nowcoder.txt
两种遍历shell的方式 我们可以把arr 理解为 Java里面的hashmap即可,是一个键值对,遍历的话直接遍历键再根据键取值即可
awk '{
for(i=1;i<=NF;i++){
if(NR==1){
arr[i] = $i
}else{
arr[i] = arr[i]" "$i;
}
}
}END{
for(w in arr){
print arr[w]
}
}' nowcoder.txt
SHELL12 打印每一行出现的数字个数
示例:
假设 nowcoder.txt 内容如下:
a12b8
10ccc
2521abc
9asf
你的脚本应当输出:
line1 number: 2
line2 number: 1
line3 number: 4
line4 number: 0
sum is 7
说明:
不要担心你输出的空格以及换行的问题
substr用法
(1)awk中函数substr substr(源字符串,开始索引,长度) 开始索引以1开始
示例:
awk ‘{$a=substr($0,1,2);print $a;}’ filename 假设文件中为只有一行为abcdefg,则返回结果为ab
(2)expr substr 字符串 开始索引 长度 开始索引以1开始
示例:
expr substr “abc” 2 2 显示bc
(3)echo ${str:开始索引} 或 echo ${str:开始索引:长度} 开始索引为0
示例:
str=“abc” echo ${str:1},显示bc echo ${str:1:2},显示bc
awk '{
count=0;
len = length($0);
for(i=1;i<=len;i++){
s = substr($0,i,1);
if(0<s && s<6){
count+=1;
total++;
}
}
printf("line%d number:%d\n",NR,count);
}END{
printf("sum is %d\n",total);
}' nowcoder.txt
我们打印看一下,可以看到自动遍历所有的行
awk '{
count=0;
len=length($0);
print(len)
for(i=1;i<=len;i++)
{s=substr($0,i,1)
if(0<s && s<6)
{total++;
count++}};
printf("line%d number:%d\n",NR,count);}
END{printf("sum is %d\n",total)}'

total不能初始化为0,要作为一个全局变量在问题中
awk '{
count=0;
total=0;
len = length($0);
for(i=1;i<=len;i++){
s=substr($0,i,1);
if(0<s && s<6){
count++;
total++;
}
}
printf("line%d number:%d\n",NR,count);
print(total);
}END{
printf("sum is %d",total);
}' nowcoder.txt

print与printf的区别
1,print是ksh的内置命令,而printf是bash的内置命令
2,print 中不能使用%s ,%d 或%c;
3,print 自动换行,printf 没有自动换行。
SHELL13 去掉所有包含this的句子
方法1
grep 命令 -v 显示不包含匹配文本的所有行
grep -v 'this'
方法2
sed 命令 -> d 删除 -> // 包含要搜索的字符串
sed '/this/d'
方法3
awk 命令,检查当前 $0 不包含 this 随机输出
awk '$0!~/this/ {print $0}'
方法4
awk表达式判断来进行输出
awk '{
flg = 0;
for(i=1;i<=NF;i++){
if($i=="this"){
flg=1;
}
}
if(flg == 0){
print $0;
}
}' nowcoder.txt
SHELL14 求平均值
写一个bash脚本以实现一个需求,求输入的一个的数组的平均值
第1行为输入的数组长度N
第2~N行为数组的元素,如以下为:
数组长度为4,数组元素为1 2 9 8
示例:
4
1
2
9
8
那么平均值为:5.000(保留小数点后面3位)
你的脚本获取以上输入应当输出:
5.000
awk '{
if(NR==1){
N = $1
}else{
sum+=$1
}}END{
printf("%.3f",sum/N);
}'
SHELL15 去掉不需要的单词
写一个 bash脚本以实现一个需求,去掉输入中的含有B和b的单词
示例:
假设输入如下:
big
nowcoder
Betty
basic
test
你的脚本获取以上输入应当输出:
nowcoder test
说明:
你可以不用在意输出的格式,空格和换行都行
grep -v 省略输出
i表示忽略大小写
cat nowcoder.txt|grep -vi "b"
awk '$0!~/[Bb]/ {print $0}' nowcoder.txt
sed '/B/d' nowcoder.txt|sed '/b/d'
SHELL16 判断输入的是否为IP地址
写一个脚本统计文件nowcoder.txt中的每一行是否是正确的IP地址。
如果是正确的IP地址输出:yes
如果是错误的IP地址,四段号码的话输出:no,否则的话输出:error
假设nowcoder.txt内容如下
192.168.1.1
192.168.1.0
300.0.0.0
123
你的脚本应该输出
yes
yes
no
error
NR是指awk正在处理的记录位于文件中的位置(行号)
NF是指awk正在处理的记录包含几个域(字段),这于域分隔符有关,默认为空
。(列号)
# 使用 . 作为分隔符
awk -F '.' '{
if (NF == 4) {
for (i = 1; i < 5; i++) {
if ($i > 255 || $i < 0) {
print("no")
break
}
}
if (i == 5) {
print("yes")
} else {
print("error")
}
}
}'
SHELL17 将字段逆序输出文件的每行
描述
将字段逆序输出文件nowcoder.txt的每一行,其中每一字段都是用英文冒号: 相分隔。
假设nowcoder.txt内容如下:
nobody::-2:-2:Unprivileged User:/var/empty:/usr/bin/false
root::0:0:System Administrator:/var/root:/bin/sh
你的脚本应当输出
/usr/bin/false:/var/empty:Unprivileged User:-2:-2::nobody
/bin/sh:/var/root:System Administrator:0:0::root
shell 自动按行输出了,所以只需要遍历列即可
awk -F ":" '{
for(i=NF;i>0;i--){
if(i==1){
print($i)
}else{
printf("%s:",$i)
}
}
}' nowcoder.txt
SHELL18 域名进行计数排序处理
描述
假设我们有一些域名,存储在nowcoder.txt里,现在需要你写一个脚本,将域名取出并根据域名进行计数排序处理。
假设nowcoder.txt内容如下:
http://www.nowcoder.com/index.html
http://www.nowcoder.com/1.html
http://m.nowcoder.com/index.html
你的脚本应该输出:
2 www.nowcoder.com
1 m.nowcoder.com
shell sort命令
用法:sort [选项]… [文件]…
串联排序所有指定文件并将结果写到标准输出。
排序选项:
-b, --ignore-leading-blanks 忽略前导的空白区域
-d, --dictionary-order 只考虑空白区域和字母字符
-f, --ignore-case 忽略字母大小写
-g, --general-numeric-sort 按照常规数值排序
-i, --ignore-nonprinting 只排序可打印字符
-n, --numeric-sort 根据字符串数值比较
-r, --reverse 逆序输出排序结果
其他选项:
-c, --check, --check=diagnose-first 检查输入是否已排序,若已有序则不进行操作
-k, --key=位置1[,位置2] 在位置1 开始一个key,在位置2 终止(默认为行尾)
-m, --merge 合并已排序的文件,不再进行排序
-o, --output=文件 将结果写入到文件而非标准输出
-t, --field-separator=分隔符 使用指定的分隔符代替非空格到空格的转换
-u, --unique 配合-c,严格校验排序;不配合-c,则只输出一次排序结果
awk -F "/" '{
arr[$3]++;
}END{
for(i in arr){
# 两种写法
# printf("%d %s\n",arr[i],i);
print arr[i]" "i;
}
}' nowcoder.txt | sort -nrk 1
SHELL19 打印等腰三角形
awk '{for(i=1;i<=5;i++){
for(j=5-i;j>0;j--){
row[i]=row[i]" ";
}
for(j=1;j<=i;j++){
row[i]=row[i]"* "
}
print row[i]
}}'
SHELL20 打印只有一个数字的行
描述
假设我们有一个nowcoder.txt,现在需要你写脚本,打印只有一个数字的行。
假设nowcoder.txt内容如下
haha
1
2ab
cd
77
那么你的脚本应该输出
1
2ab
方法1、
筛选出现一次数字的行(也会选出出现两次的,因为出现两次数字也属于出现一次里),再去除出现两次数字的行即可
awk '($0~/[0-9]{1}/)&&($0!~/[0-9]{2}/){print $0}' nowcoder.txt
方法2
打印只有一个数字的行#脑筋最直的办法
1.以数字开头,非数字结尾
awk '/^[0-9]([a-z]+$)/
2 .以字母开头,数字结尾
awk '/^[a-z]*[0-9]$/'
3.以字母开头,字母结尾,中间一个数字
awk '/^[a-z][0-9][a-z]$/'
awk '/(^[0-9]([a-z]+)$)|(^[a-z]*[0-9]$)|(^[a-z][0-9][a-z]$)/' nowcoder.txt
SHELL21 格式化输出
我们有一个文件nowcoder.txt,里面的每一行都是一个数字串,假设数字串为“123456789”,那么我们要输出为123,456,789。
假设nowcoder.txt内容如下
1
12
123
1234
123456
那么你的脚本输出如下
1
12
123
1,234
123,456
awk自动按行遍历
其中涉及到print和printf的区别
print与printf的区别
1,print是ksh的内置命令,而printf是bash的内置命令
2,print 中不能使用%s ,%d 或%c;
3,print 自动换行,printf 没有自动换行。
awk '{
l = length($0)
f = l%3
for(i = 1;i<=l;i++){
printf substr($0,i,1)
if((i-f)%3==0 && i!=l){
printf ","
}
}
print ""
# printf "\n"
}' nowcoder.txt
SHELL22 处理文本
假设我们有一个nowcoder.txt,假设里面的内容如下
111:13443
222:13211
111:13643
333:12341
222:12123
现在需要你写一个脚本按照以下的格式输出
[111]
13443
13643
[222]
13211
12123
[333]
12341
进行字符串拼接然后输出即可
awk -F ":" '{
a[$1] = a[$1] $2 "\n"
}
END {for (i in a){
printf("[%s]\n%s",i,a[i])
}
}' nowcoder.txt
SHELL23 nginx日志分析1-IP统计
sort用法
sort用法
利用 awk 中的 substr 函数
# substr从1开始计数
# sort -t表示以什么字符进行分割排序
awk '{
if(substr($4,2,11)=="23/Apr/2020"){
res[$1]++;
}
}END{
for(k in res){
print res[k]" "k
}
}' nowcoder.txt| sort -nrk 1 -t " "
使用正则匹配
awk '{
if ($4 ~ /\[23\/Apr\/2020.*/) {
res[$1]++;
}
}END {
for(k in res) {
print res[k] " " k
}
}' | sort -nr -k 1 -t " "
SHELL24 nginx日志分析2-统计某个时间段的IP
awk数组方法
得到数组长度(length方法使用)
awk '{
if($0~/\[23\/Apr\/2020:2[0-3]/){
a[$1] = 1
}
}END{
# 得到数组长度(length方法使用)
print(length(a))
}'
SHELL25 nginx日志分析3-统计访问3次以上的IP
printf用法
%s %c %d %f 都是格式替代符,%s 输出一个字符串,%d 整型输出,%c 输出一个字符,%f 输出实数,以小数形式输出。
%-10s 指一个宽度为 10 个字符(- 表示左对齐,没有则表示右对齐),任何字符都会被显示在 10 个字符宽的字符内,如果不足则自动以空格填充,超过也会将内容全部显示出来。
%-4.2f 指格式化为小数,其中 .2 指保留2位小数。
# format-string为双引号
printf "%d %s\n" 1 "abc"
# 单引号与双引号效果一样
printf '%d %s\n' 1 "abc"
# 没有引号也可以输出
printf %s abcdef
# 格式只指定了一个参数,但多出的参数仍然会按照该格式输出,format-string 被重用
printf %s abc def
printf "%s\n" abc def
printf "%s %s %s\n" a b c d e f g h i j
# 如果没有 arguments,那么 %s 用NULL代替,%d 用 0 代替
printf "%s and %d \n"
执行脚本,输出结果如下所示:
1 abc
1 abc
abcdefabcdefabc
def
a b c
d e f
g h i
j
and 0
awk '{
arr[$1]++;
}END{
for(k in arr){
if(arr[k]>3){
print arr[k]" "k
# printf("%d %s\n",arr[k],k)
}
}
}' nowcoder.txt | sort -nrk 1
SHELL26 nginx日志分析4-查询某个IP的详细访问情况
awk '$1=="192.168.1.22"{a[$7]++}
END{
for(i in a){
print a[i]" "i
}
}
'| sort -nrk 1
SHELL27 nginx日志分析5-统计爬虫抓取404的次数
awk '{
if($0~/baidu/ && $9==404){
a++;
}
}END{
print a
}' nowcoder.txt
或者
awk '{
if($0~/baidu/ && $0~"404"){
a++
}
}END{
print a
}' nowcoder.txt
SHELL28 nginx日志分析6-统计每分钟的请求数
awk -F ":" '{
res[$2":"$3]++;
}END{
for(k in res){
print res[k]" "k;
}
}' nowcoder.txt| sort -nrk 1
SHELL29 netstat练习1-查看各个状态的连接数
现在需要你查看系统tcp连接中各个状态的连接数,并且按照连接数降序输出。你的脚本应该输出如下:
ESTABLISHED 22
TIME_WAIT 9
LISTEN 3
awk '{
if($1~/tcp/) a[$6]++
}END{
for(k in a){
print k" "a[k];
}
}' nowcoder.txt | sort -nrk 2
SHELL30 netstat练习2-查看和3306端口建立的连接
现在需要你查看和本机3306端口建立连接并且状态是established的所有IP,按照连接数降序排序。你的脚本应该输出
10 172.16.0.24
9 172.16.34.144
1 172.16.34.143
awk '{
if($5 ~/3306$/ && $6=="ESTABLISHED"){
print($5)
}
}' nowcoder.txt | awk -F ":" '{
map[$1]+=1;
}END{
for(key in map){
print map[key]" "key;
}
}' | sort -nrk 1
SHELL31 netstat练习3-输出每个IP的连接数
awk '{
if($1 ~/tcp/){
print $5
}
}' nowcoder.txt | awk -F":" '{
a[$1]++
}END{
for(k in a){
print k" "a[k]
}
}
' | sort -nrk 2
SHELL32 netstat练习4-输出和3306端口建立连接总的各个状态的数目
awk '{
if($1=="tcp" && $5 ~/3306$/){
if($6 == "ESTABLISHED"){
es++
}
ans++
## 单纯用来计数
arr[$5]=0
}
}END{
printf("TOTAL_IP %d\nESTABLISHED %d\nTOTAL_LINK %d",length(arr),es,ans)
}' nowcoder.txt
SHELL33 业务分析-提取值
现在需要你提取出对应的值,输出内容如下
serverVersion:Apache Tomcat/8.5.15
serverName:8.5.15.0
osName:Windows
osVersion:10
awk -F ":" '{
if($0 ~/Server version/){
printf("serverVersion:%s\n",$4)
}
if($0~ /Server number/){
printf("serverName:%s\n",$4)
}
if($0 ~/OS Name/){
printf("osName:%s\n",substr($4,1,7))
}
if($0 ~/OS Version/){
printf("osVersion:%s\n",$5)
}
}' nowcoder.txt
SHELL34 ps分析-统计VSZ,RSS各自总和
现在需要你统计VSZ,RSS各自的总和(以M兆为统计),输出格式如下
MEM TOTAL
VSZ_SUM:3250.8M,RSS_SUM:179.777M
shell 中printf用法
%s %c %d %f 都是格式替代符,%s 输出一个字符串,%d 整型输出,%c 输出一个字符,%f 输出实数,以小数形式输出。
%-10s 指一个宽度为 10 个字符(- 表示左对齐,没有则表示右对齐),任何字符都会被显示在 10 个字符宽的字符内,如果不足则自动以空格填充,超过也会将内容全部显示出来。
%-4.2f 指格式化为小数,其中 .2 指保留2位小数。
awk '{
vsz +=$5;
rss+=$6;
}END{
printf("MEM TOTAL \nVSZ_SUM:%0.1fM,RSS_SUM:%0.3fM",vsz/1024,rss/1024)
}' nowcoder.txt

















 1810
1810

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









