






目录
引言
本周阅读了一篇关于RNN Encoder-Decoder的文献,它将可变长度的序列编码为固定长度的向量表示,并将向量解码回可变长度的序列,并且了解了RNN在长序列情况下会出现梯度爆炸和消失的情况,在此基础上学习了LSTM的出现来对解决RNN的问题,设计一个记忆细胞,具备选择性记忆的功能,可以选择记忆重要信息,过滤掉噪声信息,减轻记忆负担。
Abstract
This week, I read a literature on RNN Encoder Decoder, which encodes variable length sequences into fixed length vector representations and decodes the vectors back into variable length sequences. I also learned about the gradient explosion and disappearance of RNN in long sequences. Based on this, I learned about the emergence of LSTM to solve RNN problems and designed a memory cell with selective memory function, You can choose to remember important information, filter out noisy information, and reduce the burden of memory.
一、文献阅读
1、题目
Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation
2、引言
在本文中,我们提出了一种新的神经网络模型,称为RNN编码器-解码器,由两个递归神经网络(RNN)组成。一个RNN将一个符号序列编码为固定长度的矢量表示,另一个则将该表示解码为另一符号序列。所提出的模型的编码器和解码器被联合训练,以在给定源序列的情况下最大化目标序列的条件概率。通过使用RNN编码器-解码器计算的短语对的条件概率作为现有对数线性模型中的附加特征,实证发现统计机器翻译系统的性能有所提高。定性地,我们表明所提出的模型学习了语言短语的语义和句法意义的表示。
3、方法
RNN Encoder-Decoder是一种神经网络架构,它将可变长度的序列编码为固定长度的向量表示,并将向量解码回可变长度的序列。编码器RNN读取输入序列的每个符号,并相应地更新其隐藏状态。在读取序列的末尾后,隐藏状态成为整个输入序列的摘要。解码器RNN通过基于隐藏状态、前一个符号和输入序列的摘要来预测下一个符号,从而生成输出序列。编码器和解码器一起训练,以最大化给定源序列的条件对数似然下目标序列的概率。
整体架构图如下:
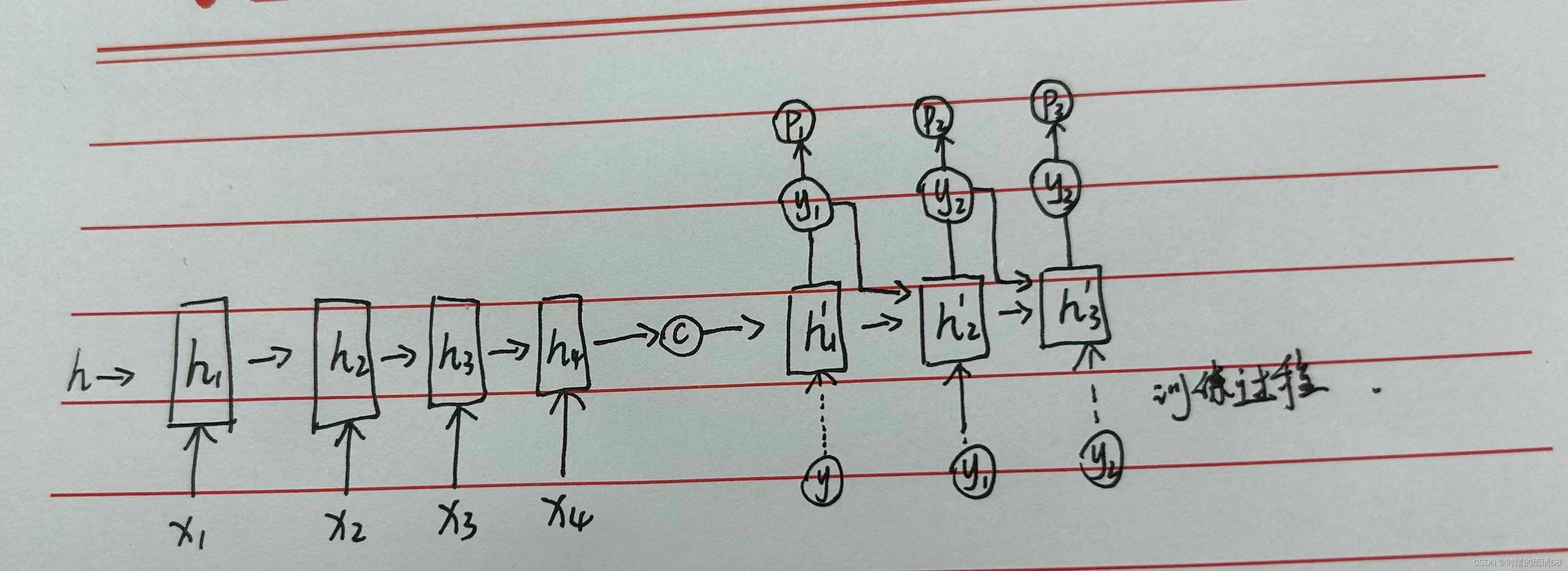
从这个结构图中我们可以看出来RNN-Encoder-Decoder 分为两部分,Encoder的作用是编码,也就是将输入序列{x1,x2…..xt}生成一个中间编码向量,然后再利用这个中间编码向量输入到Decoder中,生成输出序列,这就可以实现n-m的效果,因为对于SMT系统来说,输入序列长度和输出序列长度一般是不同的。
具体实现方面,我们分为train和predict,在train时,输入为<x1,x2….xt>和<y1,y2,…yt>两个序列数组。将<x1,x2….xt>输入到encoder中,并不输出值,而是最后输出一个C隐藏量表示整体的输入序列(这个地方便是前面可能会出现的长时记忆问题,可以通过LSTM进行改进)。对于Decoder来说,隐藏变量ht取决于encoder中的C,上一级的隐藏变量ht-1以及yt-1(这个地方yt-1在train阶段输入的为训练集中的y,在predict阶段为上一级输入的y)h(t)=f(h(t-1),yt-1,c),同样,最终输出yt,并由softmax转为Pt。
4、实验过程
在这项研究中,使用了RNN Encoder-Decoder模型进行实验,选择了WMT'14翻译任务中的英语/法语翻译任务作为评估任务。使用了大量的双语语料库进行训练,包括Europarl、新闻评论、联合国等。为了减少计算开销并确保模型能够学习语言的规律性,使用了数据选择方法来选择最相关的子集进行语言建模和训练RNN Encoder-Decoder模型。
在训练RNN Encoder-Decoder模型时,忽略了原始语料库中每个短语对的频率。使用了具有1000个隐藏单元和编码器和解码器中的门控单元的RNN Encoder-Decoder模型。模型的权重参数使用了高斯分布进行初始化,并使用了Adadelta和随机梯度下降算法进行训练。每次更新时,从短语表中随机选择64个短语对进行训练。整个模型的训练过程大约持续了三天。
此外,还尝试了使用传统的神经网络进行目标语言建模的方法,即CSLM模型。通过比较使用CSLM模型和使用RNN Encoder-Decoder模型进行短语评分的SMT系统,可以确定在SMT系统的不同部分使用多个神经网络的贡献是否累加或冗余。
5、实验结果
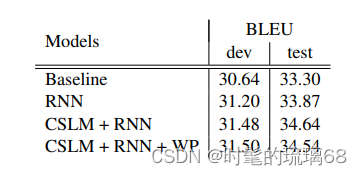
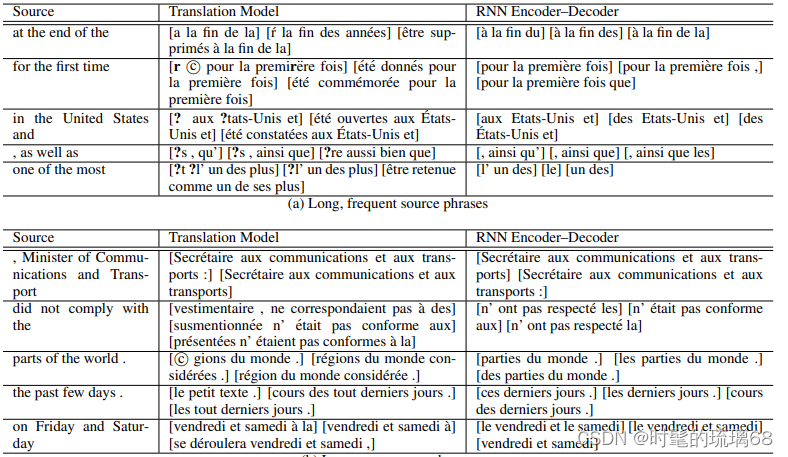
根据论文中的实验数据结果,使用了大量的资源来构建一个英法SMT系统,包括Europarl(6100万词)、新闻评论(550万词)、联合国(4.21亿词)以及两个爬取的语料库,分别包含9000万和7.8亿词。作者使用了Moore和Lewis提出的数据选择方法以及Axelrod等人对双语文本的扩展方法,从超过20亿词中选择了4180万词用于语言建模和3480万词用于训练RNN编码器-解码器。使用了newstest2012和2013作为数据选择和权重调整的测试集,newstest2014作为测试集。还限制了英语和法语的源语言和目标语言词汇表,只使用了最常见的1.5万个词,覆盖了约93%的数据集。还构建了基线的短语翻译SMT系统,并使用Moses进行了默认设置。该系统在开发集和测试集上的BLEU分数分别为30.64和33.3。还使用了RNN编码器-解码器和CSLM + RNN等不同方法进行了实验,并给出了相应的BLEU分数。实验结果表明,该方法在翻译任务中取得了较好的性能。
6、结论
研究结果表明,RNN Encoder-Decoder能够捕捉短语的语义和句法结构,并且在BLEU分数方面取得了改进。此外,该论文还提出了一种新的神经网络架构,可以学习从一个任意长度的序列到另一个任意长度的序列的映射。该架构还包括一种新颖的隐藏单元,可以自适应地控制每个隐藏单元在读取/生成序列时记住或遗忘的程度。
二、RNN&LSTM
1、RNN梯度消失/爆炸
梯度消失和梯度爆炸是困扰RNN模型训练的关键原因之一,产生梯度消失和梯度爆炸是由于RNN的权值矩阵循环相乘导致的,相同函数的多次组合会导致极端的非线性行为。梯度消失和梯度爆炸主要存在RNN中,因为RNN中每个时间片使用相同的权值矩阵。
梯度消失:梯度消失是指在训练RNN时,梯度信号(反向传播过程中的导数)变得非常小,以至于在更新网络权重时,权重的变化几乎可以忽略不计。这通常发生在较深的RNN中,尤其是在长序列上。梯度消失问题是由于循环神经网络的循环结构导致了多次连乘梯度的效应,使得梯度迅速减小。这会导致模型无法有效地学习长距离的依赖关系,因为它不能捕捉到长期间隔之间的信息。
梯度爆炸:梯度爆炸是梯度的相反问题,它发生在训练过程中,梯度变得非常大,以至于更新权重时会导致权重值急剧增加,最终导致数值不稳定。梯度爆炸通常出现在具有大权重初始化或者在循环结构中的权重被多次乘以大于1的数值的情况下。
2、LSTM设计思路
RNN是想把所有信息都记住,不管是有用的信息还是没用的信息。
LSTM:设计一个记忆细胞,具备选择性记忆的功能,可以选择记忆重要信息,过滤掉噪声信息,减轻记忆负担。
3、LSTM结构
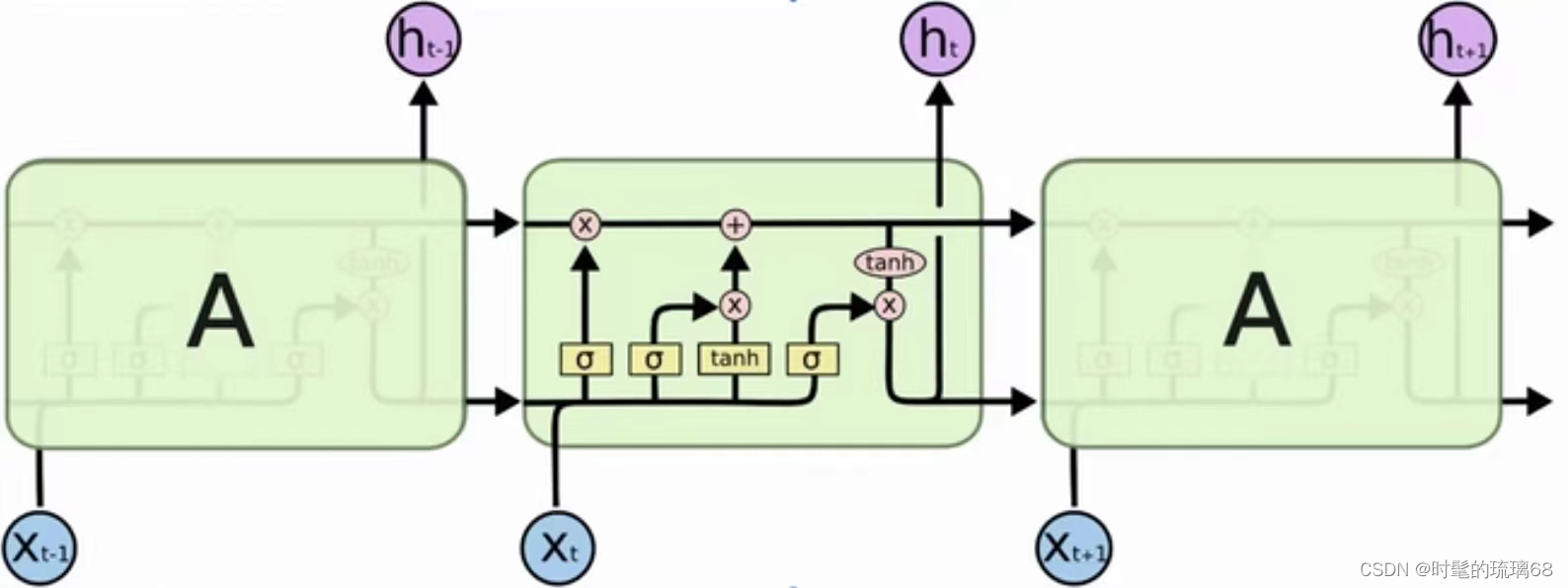
记忆单元(Memory Cell):这是LSTM的核心组件,它类似于一个存储器,负责记住和维护信息。记忆单元可以看作是一个水缸,可以储存各种信息。
遗忘门(Forget Gate):遗忘门决定在当前时间步骤是否保留或清除记忆单元中的信息。它由一个sigmoid激活函数组成,输出值介于0和1之间。值为1表示保留所有信息,值为0表示清除所有信息。
输入门(Input Gate):输入门负责决定新信息应该加入到记忆单元的哪些位置。它包括两个部分:一个sigmoid激活函数和一个tanh激活函数。sigmoid函数决定哪些信息需要更新,tanh函数用于生成候选信息,这些信息将被添加到记忆单元中。
更新记忆(Update Memory):在输入门的帮助下,LSTM计算要添加到记忆单元的新信息。
输出门(Output Gate):输出门决定在当前时间步骤输出哪些信息。它由一个sigmoid激活函数和一个tanh激活函数组成。sigmoid函数决定哪些记忆单元中的信息应该输出,tanh函数用于缩放输出。
4、LSTM前向传播过程
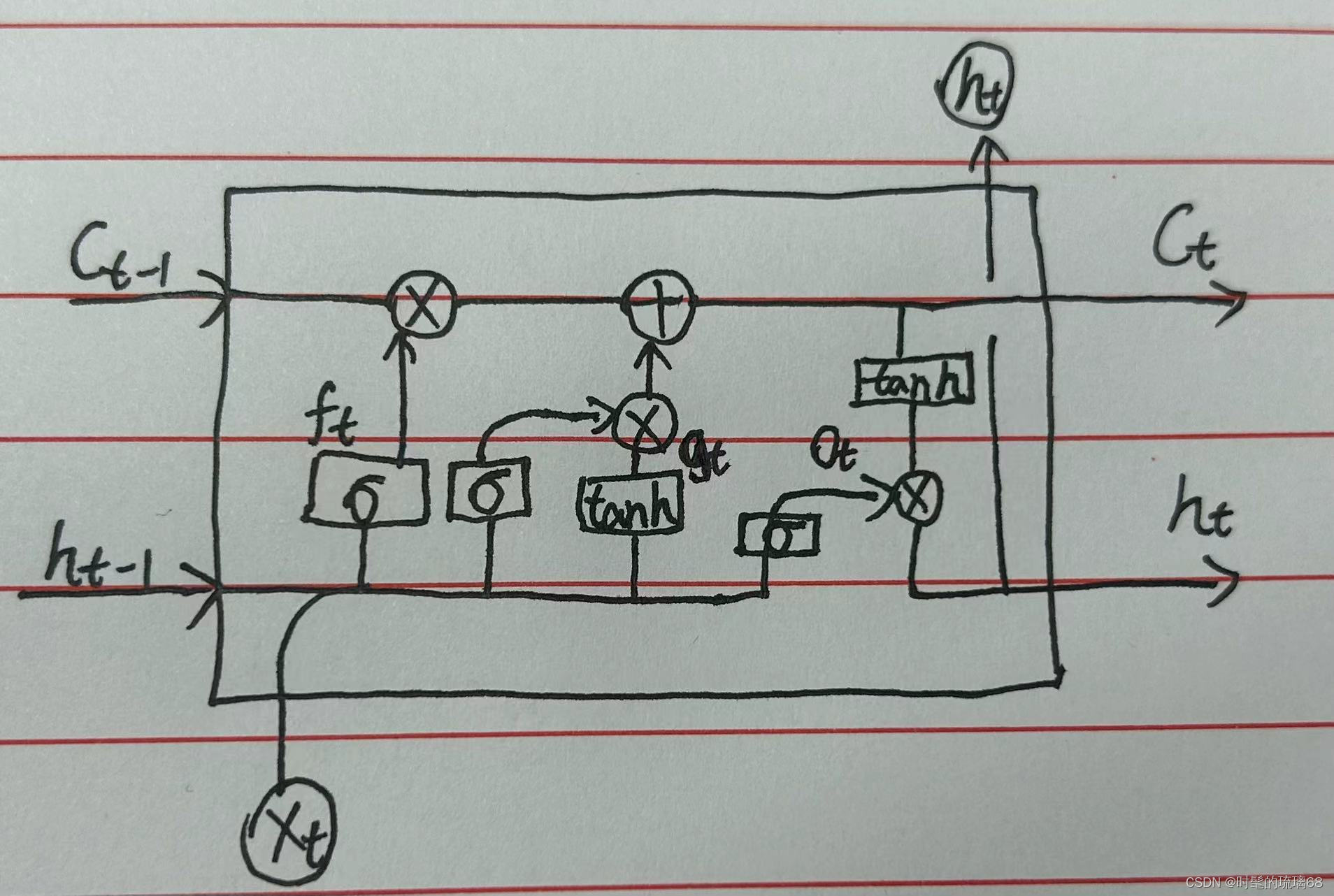
由上图所示,C表示记忆细胞,h表示状态,在t-1时刻输入后得到t时刻新的记忆细胞和状态,表示门单元,
表示遗忘门,
表示更新门,
表示输出门,x表示输入向量。前向传播过程以公式形式如下图所示。
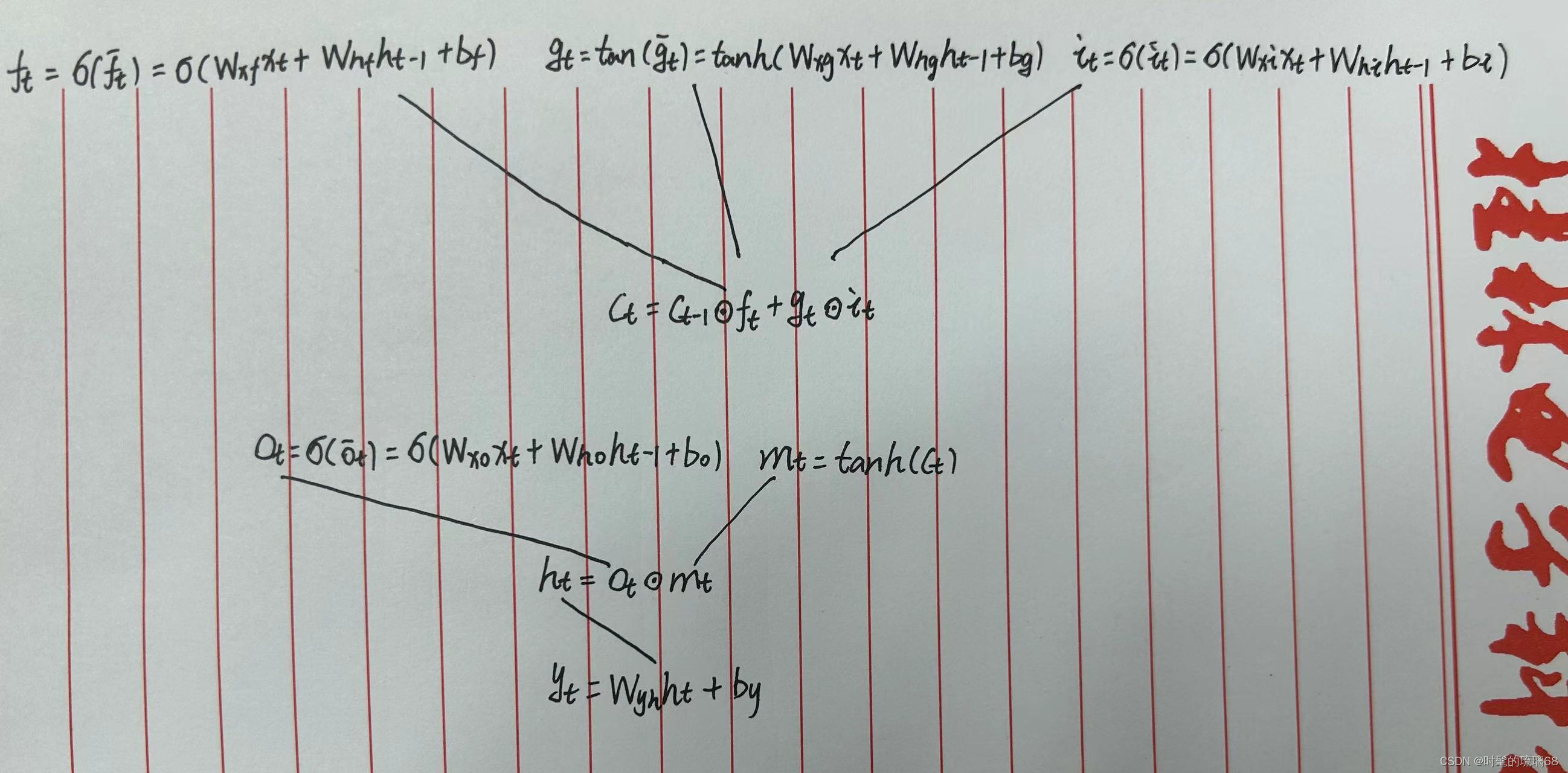
5、LSTM模型原理
- 遗忘门 (确定从细胞状态中丢弃什么信息)
在我们 LSTM 中的第一步是决定我们会从细胞状态中丢弃什么信息。这个决定通过一个称为忘记门层完成。该门会读取ht−1和xt,输出一个在 0到 1之间的数值给每个在细胞状态Ct−1中的数字。1 表示“完全保留”,0 表示“完全舍弃”。
- 输入门 (确定什么样的新信息要输入细胞状态中)
下一步是决定让多少新的信息加入到 cell 状态 中来。实现这个需要包括两个 步骤:首先,一个叫做“input gate layer ”的 sigmoid 层决定哪些信息需要更新;一个 tanh 层生成一个向量,也就是备选的用来更新的内容,gt 。在下一步,我们把这两部分联合起来,对 cell 的状态进行一个更新。
- 输出门 (确定输出什么值)
最终,我们需要确定输出什么值。这个输出将会基于我们的细胞状态,但是也是一个过滤后的版本。首先,我们运行一个 sigmoid 层来确定细胞状态的哪个部分将输出出去。接着,我们把细胞状态通过 tanh 进行处理(得到一个在 -1 到 1 之间的值)并将它和 sigmoid 门的输出相乘,最终我们仅仅会输出我们确定输出的那部分。
通过引入这些门控机制,LSTM能够更好地控制信息的流动,减轻梯度消失问题。遗忘门和输入门的操作使模型能够选择性地记住或忘记信息,而输出门允许模型选择性地输出信息。这种精细的控制允许LSTM更好地捕获长期依赖关系,因为它可以选择性地传递有用的信息,而不受梯度消失的限制,因此更好的解决了RNN中梯度消失的问题。
三、Tensorboard画图
根据pytorch内嵌的tensorboard,画了一个关于y=2x的函数图像。
#导入Summarywriter
from torch.utils.tensorboard import SummaryWriter
#创建实例,把对应的事件文件存储到logs文件夹下
writer =SummaryWriter("logs")
#主要使用到两种方法
#writer.add_image()
#writer.add_scalar()的参数中,global_step对应x轴,scalar_value对应y轴
#如y=x
for i in range(100):
#第一个参数是表达式(标签),第二个是y轴,第三个是x轴
writer.add_scalar("y=2x",2*i,i)
writer.close()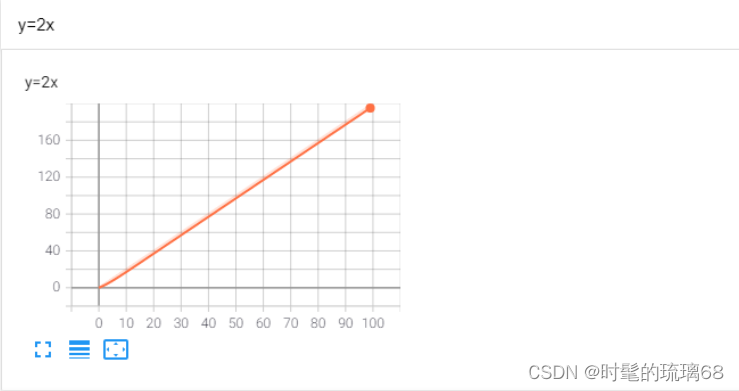
总结
本周通过对RNN和LSTM的进一步学习,以及LSTM对RNN产生的梯度消失问题的解决,还初步学习了tensorboard怎么样去画图,之后还会对tensorboard和transformer进行学习。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









