






目录
引言
本周我阅读一篇关于DenseNet的文献,DenseNet架构以前一层的所有特征图作为输入,以前向传递的方式将每一层连接到其他每一层。通过鼓励特征重用和大幅减少参数数量,DenseNets改善了网络中的信息流和梯度流,同时减少了对较小训练集的过拟合,并且通过代码对DenseNet进行了实现。
Abstract
This week, I read a literature on DenseNet, where all feature maps from the previous layer of the DenseNet architecture are used as inputs, and each layer is connected to each other layer through forward propagation. By encouraging feature reuse and significantly reducing the number of parameters, DenseNets improved the information flow and gradient flow in the network, while reducing overfitting on smaller training sets, and implemented DenseNet through code.
文献阅读
1、题目
Densely Connected Convolutional Networks
2、引言
最近的工作表明,如果卷积网络在靠近输入的层和靠近输出的层之间包含较短的连接,那么卷积网络可以进行更深入、更准确和高效的训练。在本文中,我们接受了这一观察结果,并引入了密集卷积网络(DenseNet),它以前馈的方式将每一层连接到另一层。具有L层的传统卷积网络具有L个连接——每层与其后续层之间有一个连接——而我们的网络具有L(L+1)/ 2个直接连接。对于每个层,所有先前层的特征图都用作输入,其自身的特征图也用作所有后续层的输入。DenseNet有几个引人注目的优势:它们缓解了消失梯度问题,加强了特征传播,鼓励了特征重用,并大大减少了参数的数量。我们在四个高度竞争的对象识别benc上评估了我们提出的架构
3、DenseNet和ResNet的差异
ResNet 的工作表面,只要建立前面层和后面层之间的“短路连接”(shortcut),就能有助于训练过程中梯度的反向传播,从而能训练出更“深”的 CNN 网络。DenseNet 网络的基本思路和 ResNet 一致,但是它建立的是前面所有层与后面层的密集连接(dense connection)。传统的 L 层卷积网络有 L 个连接 —— 每一层与它的前一层和后一层相连—,而 DenseNet 网络有 L(L+1)/2 个连接。
4、DenseNet网络结构
DenseNet 模型主要是由 DenseBlock 组成的。
用公式表示,传统直连(plain)的网络在 l 层的输出为:
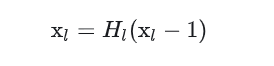
对于残差块(residual block)结构,增加了一个恒等映射(shortcut 连接):

而在密集块(DenseBlock)结构中,每一层都会将前面所有层 concate 后作为输入:
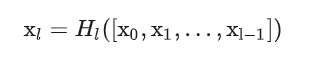
表示网络层,0,...l-1 输出特征图的拼接。
4.1、Dense Block
DenseBlock包含很多层,每个层的特征图大小相同(才可以在通道上进行连结),层与层之间采用密集连接方式。

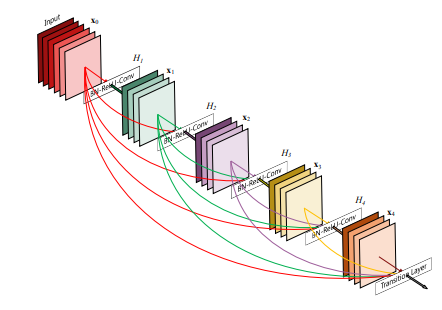
上图是一个包含5层layer的Dense Block。可以看出Dense Block互相连接所有的层,具体来说就是每一层的输入都来自于它前面所有层的特征图,每一层的输出均会直接连接到它后面所有层的输入。所以对于一个L层的DenseBlock,共包含 L*(L+1)/2 个连接(等差数列求和公式),如果是ResNet的话则为(L-1)*2+1。从这里可以看出:相比ResNet,Dense Block采用密集连接。而且Dense Block是直接concat来自不同层的特征图,这可以实现特征重用(即对不同“级别”的特征——不同表征进行总体性地再探索),提升效率,这一特点是DenseNet与ResNet最主要的区别。
另外一个特殊的点:DenseBlock中采用BN+ReLU+Conv的结构,平常我们常见的是Conv+BN+ReLU。这么做的原因是:卷积层的输入包含了它前面所有层的输出特征,它们来自不同层的输出,因此数值分布差异比较大,所以它们在输入到下一个卷积层时,必须先经过BN层将其数值进行标准化,然后再进行卷积操作。
4.2、Transition层
它主要用于连接两个相邻的DenseBlock,整合上一个DenseBlock获得的特征,缩小上一个DenseBlock的宽高,达到下采样效果,特征图的宽高减半。Transition层包括一个1x1卷积(用于调整通道数)和2x2AvgPooling(用于降低特征图大小),结构为BN+ReLU+1x1 Conv+2x2 AvgPooling。因此,Transition层可以起到压缩模型的作用 。
4.3、网络结构
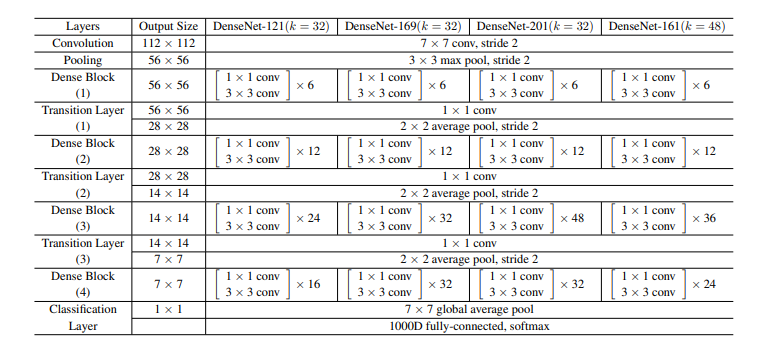
ImageNet的DenseNet架构。前3个网络的增长率为k=32,DenseNet-161为k=48。请注意,表中显示的每个“conv”层对应于序列BN-ReLU-conv。并且使用4个DenseNet-BC,输入图像大小为224x224,第一层卷积包含2k个7x7卷积,滑动为2;其它层的卷积核数量根据 k 的大小而定
5、创新点
1、减轻了vanishing-gradient(梯度消失)
2、加强了feature的传递,更有效地利用了不同层的feature
3、网络更易于训练,并具有一定的正则效果
4、因为整个网络并不深,所以一定程度上较少了参数数量
6、实验过程
DenseNets使用直接连接将任意一层与所有后续层连接起来,从而实现了密集连接,这通过连接不同层学习到的特征图的串联来改善层之间的信息流。网络架构具有称为生长率的超参数k,它调节每一层对网络全局状态的贡献程度。全局状态是网络的集体知识。在每个3x3卷积之前可以引入具有1x1卷积层的瓶颈层,以减少输入特征图的数量,提高计算效率。
通过在任意两个具有相同特征图大小的层之间引入直接连接,实现了特征的重用和更紧凑、准确的模型学习。在多个目标识别基准测试上,包括CIFAR-10、CIFAR-100、SVHN和ImageNet,DenseNets在大多数测试中优于现有算法,并且需要更少的参数来达到相当的准确性。DenseNets还具有深度监督的特性,并且与ResNets相比,易于训练且参数效率高。与Inception Networks相比,DenseNets更简单、更高效。未来的研究可以进一步调整超参数和学习率计划,以提高DenseNets的准确性,并研究其在计算机视觉任务中作为特征提取器的潜力。
7、实验结果分析
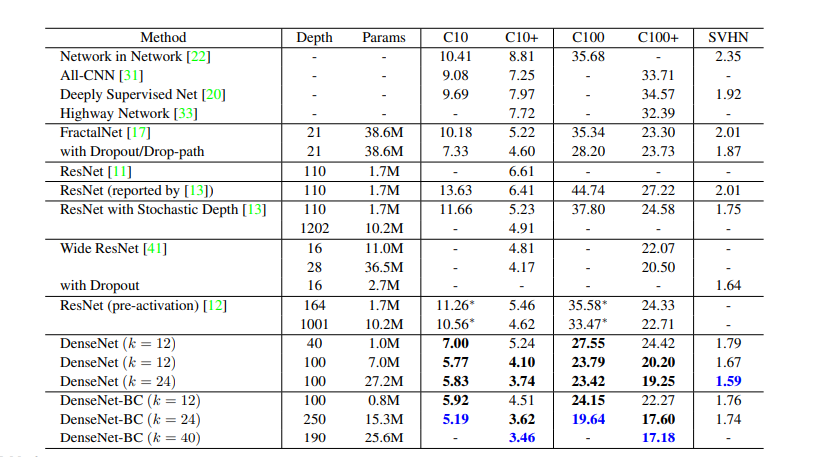
准确率
- 【CIFAR】表格最后一行,L=190、k=40的DenseNet-BC网络的结果,性能超过先存在的所有模型。
- 【SVHM】L=100、k=24的DenseNet(使用dropout)也远超wideResNet的最好结果。但是250层DenseNet-BC并没有进一步改善性能,分析是因为SVHM是一个相对容易的任务,过深的模型可能会过拟合。
容量
在没有压缩或瓶颈层的情况下,DenseNets的总体趋势是随着L 和 k 的增加而表现更好。我们将此主要归因于模型容量的相应增长。这表明DenseNets可以利用更大和更深层模型的增强表示能力。这也表明它们没有残留网络的过度拟合或优化困难。
参数效率
DenseNets比其他体系结构(尤其是ResNets)更有效地利用参数。具有瓶颈结构并在转换层减小尺寸的DenseNet-BC特别有效。
过拟合
DenseNet-BC的压缩和瓶颈层是抑制过拟合趋势的有效方式
DenseNet实现
1、DenseLayer
import torch
import torch.nn as nn
import torch.nn.functional as F
class DenseLayer(nn.Sequential):
"""Basic unit of DenseBlock (using bottleneck layer) """
def __init__(self, num_input_features, growth_rate, bn_size, drop_rate):
super(DenseLayer, self).__init__()
self.bn1 = nn.BatchNorm2d(num_input_features)
self.relu1 = nn.ReLU()
self.conv1 = nn.Conv2d(num_input_features, bn_size*growth_rate,
kernel_size=1, stride=1, bias=False)
self.bn2 = nn.BatchNorm2d(bn_size*growth_rate)
self.relu2 = nn.ReLU()
self.conv2 = nn.Conv2d(bn_size*growth_rate, growth_rate,
kernel_size=3, stride=1, padding=1, bias=False)
self.drop_rate = drop_rate
def forward(self, x):
output = self.bn1(x)
output = self.relu1(output)
output = self.conv1(output)
output = self.bn2(output)
output = self.relu2(output)
output = self.conv2(output)
if self.drop_rate > 0:
output = F.dropout(output, p=self.drop_rate)
return torch.cat([x, output], 1)2、DenseBlock
class DenseBlock(nn.Sequential):
def __init__(self, num_layers, num_input_features, bn_size, growth_rate, drop_rate):
super(DenseBlock, self).__init__()
for i in range(num_layers):
if i == 0:
self.layer = nn.Sequential(
DenseLayer(num_input_features+i*growth_rate, growth_rate, bn_size,drop_rate)
)
else:
layer = DenseLayer(num_input_features+i*growth_rate, growth_rate, bn_size,drop_rate)
self.layer.add_module("denselayer%d" % (i+1), layer)
def forward(self,input):
return self.layer(input)3、Transition
class Transition(nn.Sequential):
def __init__(self, num_input_feature, num_output_features):
super(Transition, self).__init__()
self.bn = nn.BatchNorm2d(num_input_feature)
self.relu = nn.ReLU()
self.conv = nn.Conv2d(num_input_feature, num_output_features,
kernel_size=1, stride=1, bias=False)
self.pool = nn.AvgPool2d(2, stride=2)
def forward(self,input):
output = self.bn(input)
output = self.relu(output)
output = self.conv(output)
output = self.pool(output)
return output4、DenseNet整体构建
class DenseNet(nn.Module):
def __init__(self, growth_rate=32, block_config=(6, 12, 24, 16), num_init_features=64,bn_size=4, compression_rate=0.5, drop_rate=0, num_classes=1000):
super(DenseNet, self).__init__()
# 前部
self.features = nn.Sequential(
#第一层
nn.Conv2d(3, num_init_features, kernel_size=7, stride=2, padding=3, bias=False),
nn.BatchNorm2d(num_init_features),
nn.ReLU(),
#第二层
nn.MaxPool2d(3, stride=2, padding=1)
)
# DenseBlock
num_features = num_init_features
for i, num_layers in enumerate(block_config):
block = DenseBlock(num_layers, num_features, bn_size, growth_rate,drop_rate)
if i == 0:
self.block_tran = nn.Sequential(
block
)
else:
self.block_tran.add_module("denseblock%d" % (i + 1), block)#添加一个block
num_features += num_layers*growth_rate#更新通道数
if i != len(block_config) - 1:#除去最后一层不需要加Transition来连接两个相邻的DenseBlock
transition = Transition(num_features, int(num_features*compression_rate))
self.block_tran.add_module("transition%d" % (i + 1), transition)#添加Transition
num_features = int(num_features * compression_rate)#更新通道数
# 后部 bn+ReLU
self.tail = nn.Sequential(
nn.BatchNorm2d(num_features),
nn.ReLU()
)
# classification layer
self.classifier = nn.Linear(num_features, num_classes)
# params initialization
for m in self.modules():
if isinstance(m, nn.Conv2d):#如果是卷积层,参数kaiming分布处理
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, nn.BatchNorm2d):#如果是批量归一化则伸缩参数为1,偏移为0
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1)
elif isinstance(m, nn.Linear):#如果是线性层偏移为0
nn.init.constant_(m.bias, 0)
def forward(self, x):
features = self.features(x)
block_output = self.block_tran(features)
tail_output = self.tail(block_output)
out = F.avg_pool2d(tail_output, 7, stride=1).view(tail_output.size(0), -1)#平均池化
out = self.classifier(out)
return out总结
本周阅读了DenseNet架构文献,并且通过代码进行了复现,对卷积神经网络有了更深的认识。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









