






目录
4、空间单维自我注意 Spatially Unidimensional Self-Attention(SUSA)
4.1、Stripe Context Modeling (SCM)
4.2、Spatially Unidimensional Transform (SUT)
4.3、Relationship to global context block
6.3、Ablation study about SUSA modules
6.5、Ablation study about different fusion types
引言
本周在Lite-hrnet的基础上阅读了一篇关于一种基于空间单维自注意力的轻量级人体姿势估计方法,通过引入SUSA模块构建X-HRNet骨干网络的文献,用于高分辨率姿势估计。SUSA通过在空间单维特征上执行计算来降低计算复杂性,并且深度学习中,通过代码实现对LSTM型的多输入多输出单步时间序列预测。
Abstract
This week, based on Lite hrnet, I read a literature on a lightweight human pose estimation method based on spatial single dimensional self attention, which constructs an X-HRNet backbone network by introducing SUSA modules for high-resolution pose estimation. SUSA reduces computational complexity by performing calculations on single dimensional spatial features, and in deep learning, it implements LSTM type multi input multi output single step time series prediction through code.
文献阅读
1、题目
X-HRNET: TOWARDS LIGHTWEIGHT HUMAN POSE ESTIMATION WITH SPATIALLY UNIDIMENSIONAL SELF-ATTENTION
2、引言
高分辨率表示是人体姿态估计实现高性能所必需的,随之而来的问题是高计算复杂度。特别地,主要的姿态估计方法通过2D单峰热图来估计人体关节。每个2D热图可以水平和垂直地投影到一对1D热图向量并由一对1D热图向量重建。受这一观察的启发,我们引入了一个轻量级和强大的替代方案,空间一维自注意(SUSA),逐点(1× 1)卷积是dependency可分离3×3卷积中的主要计算瓶颈。我们的SUSA将逐点(1×1)卷积的计算复杂度降低了96%,而不牺牲精度。此外,我们使用SUSA作为主要模块来构建我们的轻量级姿势估计骨干X-HRNet,其中X表示估计的十字形注意力向量。COCO基准上的大量实验证明了我们的X-HRNet的优越性,全面的消融研究表明了SUSA模块的有效性。
3、创新点
- 引入了Spatially Unidimensional Self-Attention(SUSA)模块,通过Stripe Context Modeling(SCM)和Spatially Unidimensional Transform(SUT)实现了轻量级人体姿势估计。
- 提出了X-HRNet网络,利用SUSA模块作为主要模块,实现了轻量级的人体姿势估计网络。
4、空间单维自我注意 Spatially Unidimensional Self-Attention(SUSA)
SUSA模块遵循全局上下文块(GC块)的设计模式,其详细结构如下图(a)所示
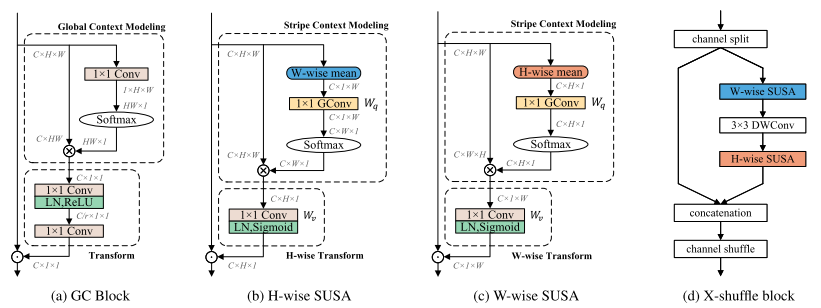
GC块的架构,本文的SUSA和X-shuffle块。为了直观理解,特征被抽象为特征维度,例如,C ×H ×W表示具有通道号C、高度H和宽度W的特征图。表示矩阵内积,表示逐元素乘法,以及表示逐元素加法。
对于输入特征映射x ∈ ,存在两个空间维度:H和W。提出了两个相应的SUSA:H-wise和W-wise SUSA。如上图b和图c所示,除了处理不同的空间维度之外,它们完全相同。SUSA可以分为三个过程:1)条带上下文建模(SCM)。SCM仅使用分组矩阵xq沿沿着一个空间维度(H或W)对特征进行分组,并输出条带上下文特征,这与将所有位置的特征分组在一起的GC块中的全局上下文建模不同。2)空间一维变换(SUT)。SUT通过逐点(1 × 1)卷积对分组特征进行变换,该卷积在剩余的空间维度上学习注意力向量。3)功能聚合。采用逐元素乘法将学习的注意力向量与输入特征图聚合。
本文的SUSA公式如下:
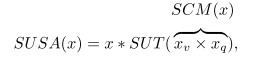
4.1、Stripe Context Modeling (SCM)
为了达到表示容量和效率的折衷,我们采用1 × 1群卷积 (group=C)对
∈
计算分组矩阵
,
由x沿沿着H维加权平均计算得到.随后通过Softmax归一化激活
,以增加注意力的动态范围。
的计算公式如下:
![]()
4.2、Spatially Unidimensional Transform (SUT)
CCW和GC块都使用两个具有瓶颈结构的级联1 × 1卷积来学习条件权重。这个技巧减少了FLOP,但引入了额外的卷积,实际上降低了推理速度。为了简化,本文的H-wise SUT通过单个1 × 1卷积对 进行编码,并输出最终的水平注意力向量
。具体地,ah通过C维上的LayerNorm(LN)(如GC块)来归一化,并通过Sigmoid函数来激活。估计
被广播倍增到x作为横向关注。相应地,W方向的SUT学习垂直注意,并通过按元素相乘将其合并为x。SUT的公式如下:
![]()
4.3、Relationship to global context block
本文的SUSA模块借鉴了GC模块的设计方案,GC块是Non-Local Network 的一个有效变体,它旨在捕获整个2D空间中的长程依赖关系。本文利用的能力,捕获长程依赖成组功能沿着一个空间维度和估计的条纹上下文功能,而不是全局上下文功能。值得注意的是,本文通过乘法将条带上下文特征聚合到输入特征作为水平或垂直注意力向量,而GC Block通过加法聚合全局上下文。下图展示出了一个玩具示例如下
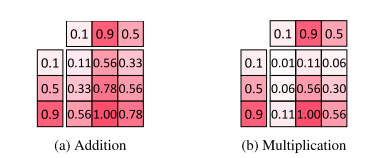
倍增融合产生比加法融合更尖锐的峰值和更小的聚焦区域。融合后对输出值进行归一化处理。
乘法融合比加法融合产生整形器峰值和更小的激活区域。GC块被设计为对长程依赖性进行建模,并且加法融合学习大的感受野。然而,我们的SUSA模块的目标像素级峰值最大化,乘法融合更适合。
5、X-HRNet网络
使用SUSA模块来替换shuffle块中的两个昂贵的逐点(1 × 1)卷积,并将其命名为X-shuffle块,其中X表示估计的十字形注意力向量。在上图d所示的X-shuffle块中,两个逐点(1 × 1)卷积都依次被H-wise和W-wise SUSA替换。基于X-shuffle块,按HRNet的结构堆叠它们,以保持高分辨率表示并构建轻量级骨干X-HRNet。特别地,X-HRNet中有三个阶段,并且每个阶段分别具有2、3、4个分支。每个分辨率分支的通道尺寸为C、2C、4C、8 C,其中C设置为40。此外,HRNet融合模块中的所有标准1 × 1卷积都被类似于的可分离3 × 3卷积所取代。
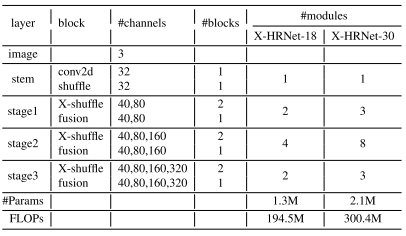
XHRNet-N中的N表示块的数量,channels表示当前阶段包含多个分支,具有相应数量的通道。
6、实验
6.1、COCO val2017
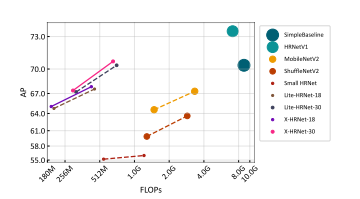
当输入大小为256 × 192时,X-HRNet-30获得了67.5的AP分数,优于现有的轻量级方法。与为分类任务设计的主要轻量级网络:MobileNetV2和ShuffleNetV2相比,X-HRNet实现了上级性能,远远低于计算成本和参数。与ShuffleNetV2相比,X-HRNet-30通过ImageNet数据集上预训练的权重进行初始化,显著实现了7.6 AP增益,仅需要15%的参数和28%的FLOP。
至于现有的姿态估计方法,XHRNet-18比小型HRNet高出9.9个AP点,只需要35%的FLOP。当输入尺寸扩展到384×288时,性能差距进一步扩大到11.8,本文的SUSA模块在捕获高分辨率细节方面的优势。无论不同的输入大小或模型深度,X-HRNet在性能上全面超越Lite-HRNet,FLOP更少。与大型姿态估计网络SimpleBaseline相比,X-HRNet-30显著降低了复杂度降低了97%,但性能仅下降了4%。
6.2、COCO test-dev2017
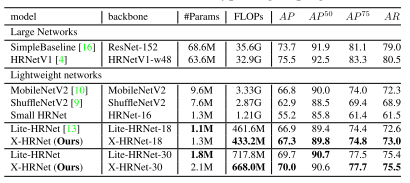
在输入大小为384 × 288的情况下,XHRNet-18和X-HRNet-30在COCO test-dev 2017数据集上分别获得了67.3和70.0的AP评分,如上表所示。与Lite-HRNet相比,X-HRNet保持了优越性,这证明了X-HRNet的鲁棒性。与大型网络相比,X-HRNet 30也实现了相当的性能,但需要更少的FLOP和参数。
6.3、Ablation study about SUSA modules
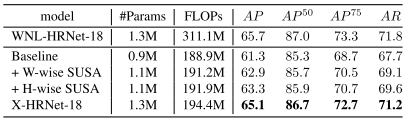
WNL-HRNet实现了65.7 AP得分,当删除shuffle块中的两个1 × 1卷积时,AP得分下降了4.4分。同时,在shuffle块中,每1 × 1卷积的FLOPs减少了122.2M,MFLOPs减少了61.1。通过在每个不完全混洗块中的dependent3 × 3卷积之后插入一个Hwise或W-wise SUSA,基线分别提高了2.0,1.6。使用这两种方法(X-HRNet),性能始终提高3.8,大于添加任何一种方法的AP改进之和(3.6)。值得注意的是,SUSA模块的成本仅为2.7 MFLOP,仅为1 × 1卷积的4%,但获得了相当的AP分数,65.1。1 × 1卷积在跨通道的信息交换中起着重要作用,但它的计算成本很高。SUSA模块通过学习十字形注意力向量来扮演类似于1 × 1卷积的角色,并且只需要在单个空间维度上执行卷积计算。
6.5、Ablation study about different fusion types

不同的融合选择对SUSA模块实现高性能有影响。本文分别在GC模块和SUSA模块上应用加法和乘法融合来验证。不同融合的消融结果如上表所示,乘法融合比加法融合更适合于人体姿态估计任务,加法融合对于对象检测或分割是逆的。
7、结论
本文提出了一种轻量级的人体姿态估计方法X-HRNet。探索了姿态估计任务的基本特征:通过2D单峰热图估计人体关节,其中每个2D热图可以水平和垂直投影到一对1D热向量并由其重建。受此启发,提出了一个轻量级的模块命名为空间一维自注意(SUSA)。由此产生的轻量级姿态估计网络X-HRNet实现了最先进的COCO基准测试的复杂性和准确性权衡。
深度学习 基于LSTM模型的多输入多输出单步时间序列预测
1、数据展示
数据集为某天气预报数据,该数据集时间维度为2013年1月1日至2017年4月24日,存在 3 个特征分别是meantemp, humidity, meanpressure,接下来将以这三个特征为输入、输出,建立一个多输入多输出的LSTM模型
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = 'SimHei' # 设置中文显示
plt.rcParams['axes.unicode_minus'] = False
df_train = pd.read_excel('训练集.xlsx', index_col=0, parse_dates=['date'])
df_test = pd.read_csv('测试集.csv', index_col=0, parse_dates=['date'])
df_train结果如下

其中df_train和df_test分别为模型的训练集和测试集,数据不存在缺失值、异常值
2、时序图
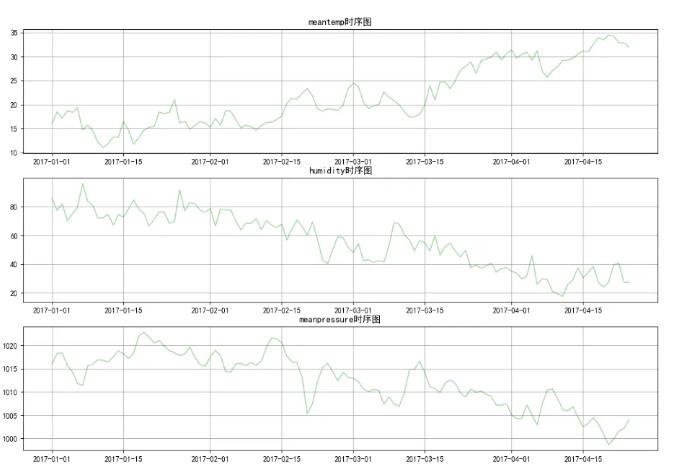
2.1、训练集时序图
plt.figure(figsize=(15, 10))
plt.subplot(3, 1, 1)
plt.plot(df_train['meantemp'], color='y', alpha=0.3)
plt.title('meantemp时序图')
plt.grid(True)
plt.subplot(3, 1, 2)
plt.plot(df_train['humidity'], color='y', alpha=0.3)
plt.title('humidity时序图')
plt.grid(True)
plt.subplot(3, 1, 3)
plt.plot(df_train['meanpressure'], color='y', alpha=0.3)
plt.title('meanpressure时序图')
plt.grid(True)
plt.show()结果如下
 2.2、测试集时序图
2.2、测试集时序图
plt.figure(figsize=(15, 10))
plt.subplot(3, 1, 1)
plt.plot(df_test['meantemp'], color='g', alpha=0.3)
plt.title('meantemp时序图')
plt.grid(True)
plt.subplot(3, 1, 2)
plt.plot(df_test['humidity'], color='g', alpha=0.3)
plt.title('humidity时序图')
plt.grid(True)
plt.subplot(3, 1, 3)
plt.plot(df_test['meanpressure'], color='g', alpha=0.3)
plt.title('meanpressure时序图')
plt.grid(True)
plt.show()结果如下
3、数据0-1标准化
from sklearn.preprocessing import MinMaxScaler
def normalize_dataframe(train_df, test_df):
scaler = MinMaxScaler()
scaler.fit(train_df) # 在训练集上拟合归一化模型
train_data = pd.DataFrame(scaler.transform(train_df), columns=train_df.columns, index = df_train.index)
test_data = pd.DataFrame(scaler.transform(test_df), columns=test_df.columns, index = df_test.index)
return train_data, test_data
data_train, data_test = normalize_dataframe(df_train, df_test)
data_train结果如下

归一化时只使用训练集的统计量,并将归一化后的转换应用于训练集和测试集,避免直接对所有数据集进行归一化处理从而产生信息泄露
4、滑动窗口划分数据
def prepare_data(data, win_size, target_feature_idxs):
num_features = data.shape[1]
X = []
y = []
for i in range(len(data) - win_size):
temp_x = data[i:i + win_size, :]
temp_y = [data[i + win_size, idx] for idx in target_feature_idxs]
X.append(temp_x)
y.append(temp_y)
X = np.asarray(X)
y = np.asarray(y)
return X, y
win_size = 12 # 时间窗口
target_feature_idxs = [0, 1, 2] # 指定待预测特征列索引
train_x, train_y = prepare_data(data_train.values, win_size, target_feature_idxs)
test_x, test_y = prepare_data(data_test.values, win_size, target_feature_idxs)
print("训练集形状:", train_x.shape, train_y.shape)
print("测试集形状:", test_x.shape, test_y.shape)结果如下

训练集形状 (1449, 12, 3) 表示:
1449:样本数,即训练集中有1449个样本。
12:时间窗口大小,每个样本有12个时间步长的数据,用于预测下一个时间步的数据。
3:特征数,每个时间步长有3个特征(meantemp、humidity 和 meanpressure)
测试集形状 (102, 12, 3) 表示:
102:样本数,即测试集中有102个样本
12:时间窗口大小,每个样本有12个时间步长的数据,用于预测下一个时间步的数据
3:特征数,每个时间步长有3个特征(meantemp、humidity 和 meanpressure)
5、模型建立
from keras.layers import LSTM, Dense
from keras.models import Model
from keras.layers import Input
# 输入维度
input_shape = Input(shape=(train_x.shape[1], train_x.shape[2]))
# LSTM层
lstm_layer = LSTM(128, activation='relu')(input_shape)
# 全连接层
dense_1 = Dense(64, activation='relu')(lstm_layer)
dense_2 = Dense(32, activation='relu')(dense_1)
# 输出层
output_1 = Dense(1, name='meantemp')(dense_2)
output_2 = Dense(1, name='humidity')(dense_2)
output_3 = Dense(1, name='meanpressure')(dense_2)
model = Model(inputs = input_shape, outputs = [output_1, output_2, output_3])
model.compile(loss='mse', optimizer='adam')
# 模型拟合
history = model.fit(train_x, [train_y[:,i] for i in range(train_y.shape[1])], epochs=100, batch_size=32, validation_data=(test_x, [test_y[:,i] for i in range(test_y.shape[1])]))
plt.figure()
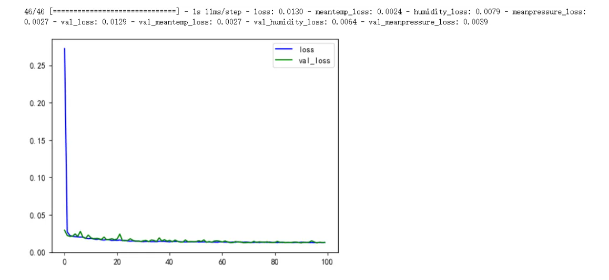
plt.plot(history.history['loss'], c='b', label='loss')
plt.plot(history.history['val_loss'], c='g', label='val_loss')
plt.legend()
plt.show()结果如下
model.summary()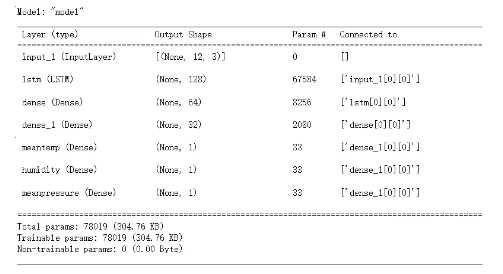
这是一个多输入多输出的 LSTM 模型,接受包含12个时间步长和3个特征的输入序列,在经过一层128个神经元的 LSTM 层和两个全连接层后,输出三个单独的预测结果,分别是 meantemp、humidity 和 meanpressure
6、模型评价
from sklearn import metrics
y_pred = model.predict(test_x)
# 计算均方误差(MSE)
mse_meantemp = metrics.mean_squared_error(test_y[:,0], np.array([i for arr in y_pred[0] for i in arr]))
# 计算均方根误差(RMSE)
rmse_meantemp = np.sqrt(mse_meantemp)
# 计算平均绝对误差(MAE)
mae_meantemp = metrics.mean_absolute_error(test_y[:,0], np.array([i for arr in y_pred[0] for i in arr]))
from sklearn.metrics import r2_score # 拟合优度
r2_meantemp = r2_score(test_y[:,0], np.array([i for arr in y_pred[0] for i in arr]))
print("meantemp均方误差 (MSE):", mse_meantemp)
print("meantemp均方根误差 (RMSE):", rmse_meantemp)
print("meantemp平均绝对误差 (MAE):", mae_meantemp)
print("meantemp拟合优度:", r2_meantemp)结果如下

mse_humidity = metrics.mean_squared_error(test_y[:,1], np.array([i for arr in y_pred[1] for i in arr]))
rmse_humidity = np.sqrt(mse_humidity)
mae_humidity = metrics.mean_absolute_error(test_y[:,1], np.array([i for arr in y_pred[1] for i in arr]))
r2_humidity = r2_score(test_y[:,1], np.array([i for arr in y_pred[1] for i in arr]))
print("humidity均方误差 (MSE):", mse_humidity)
print("humidity均方根误差 (RMSE):", rmse_humidity)
print("humidity平均绝对误差 (MAE):", mae_humidity)
print("humidity拟合优度:", r2_humidity)结果如下

mse_meanpressure = metrics.mean_squared_error(test_y[:,2], np.array([i for arr in y_pred[2] for i in arr]))
rmse_meanpressure = np.sqrt(mse_meanpressure)
mae_meanpressure= metrics.mean_absolute_error(test_y[:,2], np.array([i for arr in y_pred[2] for i in arr]))
r2_meanpressure = r2_score(test_y[:,2], np.array([i for arr in y_pred[2] for i in arr]))
print("meanpressure均方误差 (MSE):", mse_meanpressure)
print("meanpressure均方根误差 (RMSE):", rmse_meanpressure)
print("meanpressure平均绝对误差 (MAE):", mae_meanpressure)
print("meanpressure拟合优度:", r2_meanpressure)结果如下

7、模型向后预测
def predict_next_11_days(model, input_data):
input_sequence = input_data.copy()
# 预测未来 11 天的数据
future_predictions = []
for _ in range(11):
predictions = model.predict(np.expand_dims(input_sequence[-1], axis=0))
next_data = np.append(input_sequence[-1, 1:], np.array(predictions).reshape(1,3), axis=0)
input_sequence = np.append(input_sequence, [next_data], axis=0)
future_predictions.append(predictions)
future_predictions = np.array(future_predictions).reshape(11, 3)
return future_predictions
future_predictions = predict_next_11_days(model, test_x[-1:])
future_predictions结果如下

8、预测可视化
# 反归一化
train_max_meantemp = np.max(df_train['meantemp'])
train_min_meantemp = np.min(df_train['meantemp'])
train_max_humidity = np.max(df_train['humidity'])
train_min_humidity = np.min(df_train['humidity'])
train_max_meanpressure = np.max(df_train['meanpressure'])
train_min_meanpressure = np.min(df_train['meanpressure'])
series_meantemp = np.array(future_predictions[:, 0])*(train_max_meantemp - train_min_meantemp)+train_min_meantemp
series_humidity = np.array(future_predictions[:, 1])*(train_max_humidity - train_min_humidity)+train_min_humidity
series_meanpressure = np.array(future_predictions[:, 2])*(train_max_meanpressure - train_min_meanpressure)+train_min_meanpressure
plt.figure(figsize=(20, 15), dpi =300)
plt.subplot(3,2,1)
plt.plot(pd.date_range(start='2013-01-13', end='2016-12-31', freq='D'), df_train.iloc[12::]['meantemp'],
label='训练集', color='blue', alpha=0.8)
plt.plot(pd.date_range(start='2017-01-01', end='2017-04-24', freq='D'), df_test['meantemp'],
label='测试集', color='gold', alpha=0.8)
plt.plot(pd.date_range(start='2017-01-13', end='2017-04-24', freq='D'),
y_pred[0]*(train_max_meantemp-train_min_meantemp)+train_min_meantemp,
label='测试集预测', color='navy', alpha=0.8)
plt.plot(pd.date_range(start='2017-04-24', end='2017-05-04', freq='D'),
series_meantemp, label='向后预测10天', color='limegreen', alpha=0.8)
plt.legend()
plt.title('meantemp')
plt.grid(True)
plt.xlabel('time')
plt.ylabel('°C')
plt.subplot(3,2, 2)
plt.plot(pd.date_range(start='2017-01-01', end='2017-04-24', freq='D'), df_test['meantemp'],
label='测试集', color='gold', alpha=0.8)
plt.plot(pd.date_range(start='2017-01-13', end='2017-04-24', freq='D'),
y_pred[0]*(train_max_meantemp-train_min_meantemp)+train_min_meantemp,
label='测试集预测', color='navy', alpha=0.8)
plt.plot(pd.date_range(start='2017-04-24', end='2017-05-04', freq='D'),
series_meantemp, label='向后预测10天', color='limegreen', alpha=0.8)
plt.legend()
plt.title('meantemp')
plt.grid(True)
plt.xlabel('time')
plt.ylabel('°C')
plt.subplot(3,2,3)
plt.plot(pd.date_range(start='2013-01-13', end='2016-12-31', freq='D'), df_train.iloc[12::]['humidity'],
label='训练集', color='blue', alpha=0.8)
plt.plot(pd.date_range(start='2017-01-01', end='2017-04-24', freq='D'), df_test['humidity'],
label='测试集', color='gold', alpha=0.8)
plt.plot(pd.date_range(start='2017-01-13', end='2017-04-24', freq='D'),
y_pred[1]*(train_max_humidity-train_min_humidity)+train_min_humidity,
label='测试集预测', color='navy', alpha=0.8)
plt.plot(pd.date_range(start='2017-04-24', end='2017-05-04', freq='D'),
series_humidity, label='向后预测10天', color='limegreen', alpha=0.8)
plt.legend()
plt.title('humidity')
plt.grid(True)
plt.xlabel('time')
plt.ylabel('°C')
plt.subplot(3,2,4)
plt.plot(pd.date_range(start='2017-01-01', end='2017-04-24', freq='D'), df_test['humidity'],
label='测试集', color='gold', alpha=0.8)
plt.plot(pd.date_range(start='2017-01-13', end='2017-04-24', freq='D'),
y_pred[1]*(train_max_humidity-train_min_humidity)+train_min_humidity,
label='测试集预测', color='navy', alpha=0.8)
plt.plot(pd.date_range(start='2017-04-24', end='2017-05-04', freq='D'),
series_humidity, label='向后预测10天', color='limegreen', alpha=0.8)
plt.legend()
plt.title('humidity')
plt.grid(True)
plt.xlabel('time')
plt.ylabel('°C')
plt.subplot(3,2,5)
plt.plot(pd.date_range(start='2013-01-13', end='2016-12-31', freq='D'), df_train.iloc[12::]['meanpressure'],
label='训练集', color='blue', alpha=0.8)
plt.plot(pd.date_range(start='2017-01-01', end='2017-04-24', freq='D'), df_test['meanpressure'],
label='测试集', color='gold', alpha=0.8)
plt.plot(pd.date_range(start='2017-01-13', end='2017-04-24', freq='D'),
y_pred[2]*(train_max_meanpressure-train_min_meanpressure)+train_min_meanpressure,
label='测试集预测', color='navy', alpha=0.8)
plt.plot(pd.date_range(start='2017-04-24', end='2017-05-04', freq='D'),
series_meanpressure, label='向后预测10天', color='limegreen', alpha=0.8)
plt.legend()
plt.title('meanpressure')
plt.grid(True)
plt.xlabel('pa')
plt.ylabel('°C')
plt.subplot(3,2,6)
plt.plot(pd.date_range(start='2017-01-01', end='2017-04-24', freq='D'), df_test['meanpressure'],
label='测试集', color='gold', alpha=0.8)
plt.plot(pd.date_range(start='2017-01-13', end='2017-04-24', freq='D'),
y_pred[2]*(train_max_meanpressure-train_min_meanpressure)+train_min_meanpressure,
label='测试集预测', color='navy', alpha=0.8)
plt.plot(pd.date_range(start='2017-04-24', end='2017-05-04', freq='D'),
series_meanpressure, label='向后预测10天', color='limegreen', alpha=0.8)
plt.legend()
plt.title('meanpressure')
plt.grid(True)
plt.xlabel('time')
plt.ylabel('pa')
plt.show()结果如下

总结
本周在针对高分辨率人体姿态估计的基础上阅读了一种基于空间单维自注意力的轻量级人体姿势估计方法,通过引入SUSA模块构建X-HRNet骨干网络,对姿态估计的知识有了进一步的加强,同时对LSTM的模型进行了应用学习。















 852
852











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









