







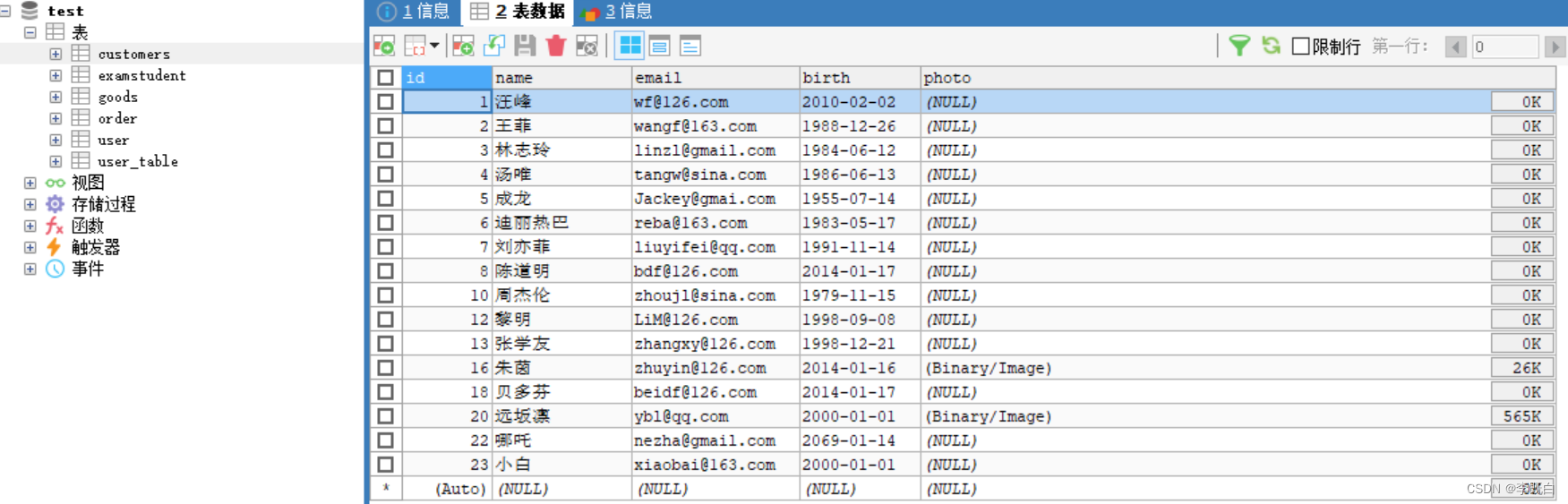
本文使用的数据表如下
目录
Apache-DBUtils
commons-dbutils 是 Apache 组织提供的一个开源 JDBC 工具类库,它是对 JDBC 的简单封装,学习成本极低,并且使用 dbutils 能极大简化 JDBC 编码工作量,同时也不会影响程序的性能
QueryRunner实现查询操作
QueryRunner 依托其下的实现类与接口进行查询操作,我们下面介绍一些实现类的使用
本文连接数据库方式采用 Druid 连接池,有不清楚的小伙伴可以参考博文
【JDBC笔记】Druid数据库连接池实现连接_李既白的博客-CSDN博客
创建Customer实现类
在进行查询之前,我们需要把使用的 customers 数据表以 Java 实现类的形式呈现出来,方便具体操作
import java.sql.Date;
public class Customer {
private int id;
private String email;
private String name;
private Date birth;
public Customer() {
super();
}
public Customer(int id, String email, String name, Date birth) {
super();
this.id = id;
this.email = email;
this.name = name;
this.birth = birth;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Date getBirth() {
return birth;
}
public void setBirth(Date birth) {
this.birth = birth;
}
@Override
public String toString() {
return "Customer [id=" + id + ", email=" + email + ", name=" + name + ", birth=" + birth + "]";
}
}
BeanHandler
是 ResultSetHandler 接口的实现类,用于封装表中的一条记录
import java.io.InputStream;
import java.sql.Connection;
import java.sql.SQLException;
import java.util.Properties;
import javax.sql.DataSource;
import org.apache.commons.dbutils.QueryRunner;
import org.apache.commons.dbutils.handlers.BeanHandler;
import org.junit.Test;
import com.alibaba.druid.pool.DruidDataSourceFactory;
public class QueryRunnerSearchTest {
@Test
public void BeanHandlerTest() throws Exception {
Properties pros = new Properties();
InputStream is = ClassLoader.getSystemClassLoader().getResourceAsStream("Druid.properties");
pros.load(is);
DataSource source = DruidDataSourceFactory.createDataSource(pros);
Connection conn = source.getConnection();
QueryRunner runner = new QueryRunner();
String sql = "select id,name,email,birth from Customers where id = ?";
BeanHandler<Customer> handler = new BeanHandler<>(Customer.class);
Customer customer = runner.query(conn, sql, handler, 23);
System.out.println(customer);
conn.close();
}
}
BeanListHandler
是 ResultSetHandler 接口的实现类,用于封装表中的多条记录构成的集合
import java.io.IOException;
import java.io.InputStream;
import java.sql.Connection;
import java.util.List;
import java.util.Properties;
import javax.sql.DataSource;
import org.apache.commons.dbutils.QueryRunner;
import org.apache.commons.dbutils.handlers.BeanListHandler;
import org.junit.Test;
import com.alibaba.druid.pool.DruidDataSourceFactory;
public class QueryRunnerSearchTest {
@Test
public void BeanListHandlerTest() throws Exception {
Properties pros = new Properties();
InputStream is = ClassLoader.getSystemClassLoader().getResourceAsStream("Druid.properties");
pros.load(is);
DataSource source = DruidDataSourceFactory.createDataSource(pros);
Connection conn = source.getConnection();
QueryRunner runner = new QueryRunner();
String sql = "select id,name,email,birth from customers where id < ?";
BeanListHandler<Customer> handler = new BeanListHandler<>(Customer.class);
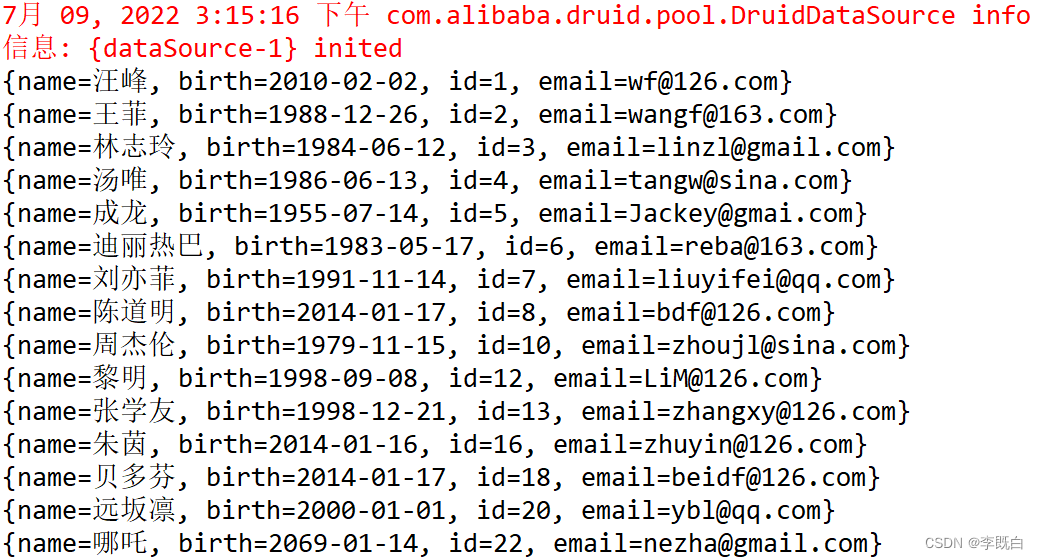
List<Customer> list = runner.query(conn,sql,handler,23);
list.forEach(System.out::println);
conn.close();
}
}
MapHandler
是 ResultSetHandler 接口的实现类,对应表中的一条记录,将字段及相应字段的值作为 map 中的 key 和 value
import java.io.IOException;
import java.io.InputStream;
import java.sql.Connection;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import javax.sql.DataSource;
import org.apache.commons.dbutils.QueryRunner;
import org.apache.commons.dbutils.handlers.MapHandler;
import org.junit.Test;
import com.alibaba.druid.pool.DruidDataSourceFactory;
public class QueryRunnerSearchTest {
@Test
public void MapHandlerTest() throws Exception {
Properties pros = new Properties();
InputStream is = ClassLoader.getSystemClassLoader().getResourceAsStream("Druid.properties");
pros.load(is);
DataSource source = DruidDataSourceFactory.createDataSource(pros);
Connection conn = source.getConnection();
QueryRunner runner = new QueryRunner();
MapHandler handler = new MapHandler();
String sql = "select id,name,email,birth from customers where id = ?";
Map<String,Object> map = runner.query(conn,sql,handler,23);
System.out.println(map);
conn.close();
}
}
MapListHandler
是 ResultSethandler 接口的实现类,对应表中的多条记录,将字段及相应字段的值作为 map 中的 key 和 value,将这些 map 添加到 List 中
import java.io.IOException;
import java.io.InputStream;
import java.sql.Connection;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import javax.sql.DataSource;
import org.apache.commons.dbutils.QueryRunner;
import org.apache.commons.dbutils.handlers.MapListHandler;
import org.junit.Test;
import com.alibaba.druid.pool.DruidDataSourceFactory;
public class QueryRunnerSearchTest {
@Test
public void MapListHandlerTest() throws Exception {
Properties pros = new Properties();
InputStream is = ClassLoader.getSystemClassLoader().getResourceAsStream("Druid.properties");
pros.load(is);
DataSource source = DruidDataSourceFactory.createDataSource(pros);
Connection conn = source.getConnection();
MapListHandler handler = new MapListHandler();
QueryRunner runner = new QueryRunner();
String sql = "select id,name,email,birth from customers where id < ?";
List<Map<String, Object>> list = runner.query(conn, sql, handler, 23);
list.forEach(System.out::println);
conn.close();
}
}
ScalarHandler
查询特殊字段
import java.io.IOException;
import java.io.InputStream;
import java.sql.Connection;
import java.sql.Date;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import javax.sql.DataSource;
import org.apache.commons.dbutils.QueryRunner;
import org.apache.commons.dbutils.handlers.ScalarHandler;
import org.junit.Test;
import com.alibaba.druid.pool.DruidDataSourceFactory;
public class QueryRunnerSearchTest {
@Test
public void ScalarHandlerTest() throws Exception {
Properties pros = new Properties();
InputStream is = ClassLoader.getSystemClassLoader().getResourceAsStream("Druid.properties");
pros.load(is);
DataSource source = DruidDataSourceFactory.createDataSource(pros);
Connection conn = source.getConnection();
QueryRunner runner = new QueryRunner();
ScalarHandler handler = new ScalarHandler();
String sql = "select max(birth) from customers";
Date maxBirth = (Date) runner.query(conn, sql, handler);
System.out.println(maxBirth);
conn.close();
}
}
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











