






 本文介绍了FP16在深度学习训练中遇到的溢出错误和舍入误差问题,详细阐述了混合精度训练如何通过结合FP16和FP32来减轻误差,并探讨了动态损失放大技术如何解决下溢出,确保模型收敛。同时,提到了torch.cuda.amp的自动混合精度训练在DP和DDP模式下的应用。
本文介绍了FP16在深度学习训练中遇到的溢出错误和舍入误差问题,详细阐述了混合精度训练如何通过结合FP16和FP32来减轻误差,并探讨了动态损失放大技术如何解决下溢出,确保模型收敛。同时,提到了torch.cuda.amp的自动混合精度训练在DP和DDP模式下的应用。
原文连接: https://www.sohu.com/a/336981343_500659
FP16带来的问题:量化误差
FP16 带来的问题主要有两个:1. 溢出错误;2. 舍入误差。
溢出错误(Grad Overflow / Underflow)
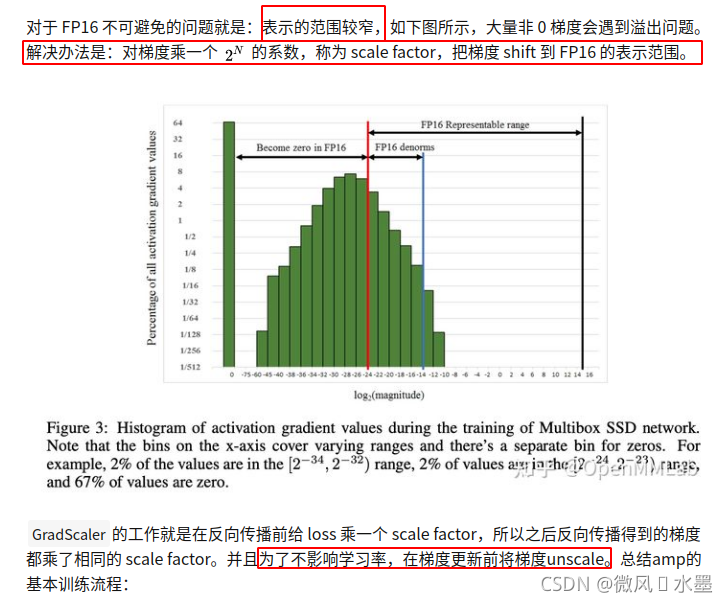
由于 FP16 的动态范围比 FP32 的动态范围要狭窄很多,因此在计算过程中很容易出现上溢出(Overflow,g>65504)和下溢出(Underflow,)的错误,溢出之后就会出现“Nan”的问题。
在深度学习中,由于激活函数的的梯度往往要比权重梯度小,更易出现下溢出的情况。
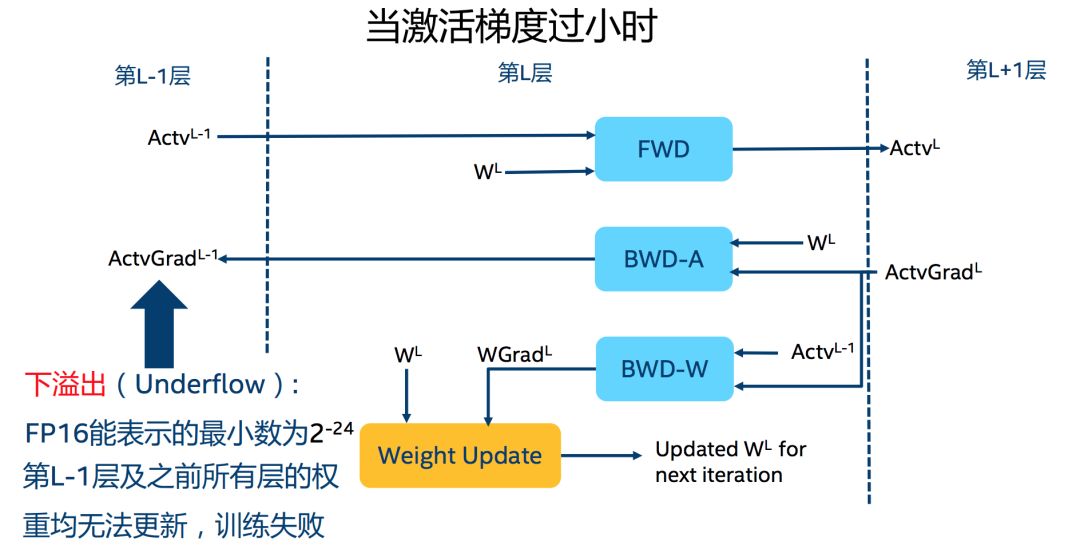
舍入误差(Rounding Error)
舍入误差指的是当梯度过小,小于当前区间内的最小间隔时,该次梯度更新可能会失败,用一张图清晰地表示:

解决问题的办法:混合精度训练+动态损失放大
混合精度训练(Mixed Precision)
混合精度训练的精髓在于“在内存中用 FP16 做储存和乘法从而加速计算,用 FP32 做累加避免舍入误差”。混合精度训练的策略有效地缓解了舍入误差的问题。
损失放大(Loss Scaling)
即使用了混合精度训练,还是会存在无法收敛的情况,原因是激活梯度的值太小,造成了下溢出(Underflow)。损失放大的思路是:
- 反向传播前,将损失变化(dLoss)手动增大,因此反向传播时得到的中间变量(激活函数梯度)则不会溢出;
- 反向传播后,将权重梯度缩小倍,恢复正常值。
动态损失放大(Dynamic Loss Scaling)
AMP 默认使用动态损失放大,为了充分利用 FP16 的范围,缓解舍入误差,尽量使用最高的放大倍数(),如果产生了上溢出(Overflow),则跳过参数更新,缩小放大倍数使其不溢出,在一定步数后(比如 2000 步)会再尝试使用大的 scale 来充分利用 FP16 的范围:

----------------------------------------------------------------------------
torch.cuda.amp: 自动混合精度详解
原文连接: https://zhuanlan.zhihu.com/p/140937175 非常推荐去学习,受益良多.我这里仅摘抄部分,推荐去原文学习记录.


对于DP, DDP模式下, amp正确打开姿势:

其他关于scale, 梯度裁剪等,都有详细介绍,强推!
-------------------------------------------------------------------------------------------------------------------
2020 ECCV,英伟达官方做了一个 tutorial 推广 amp,里面干货很多,值的学习.


Reference
[1] Intel的低精度表示用于深度学习训练与推断
http://market.itcgb.com/Contents/Intel/OR_AI_BJ/images/Brian_DeepLearning_LowNumericalPrecision.pdf
[2] NVIDIA官方混合精度训练文档
https://docs.nvidia.com/deeplearning/sdk/mixed-precision-training/index.html
[3] Apex官方使用文档
https://nvidia.github.io/apex/amp.html
[4] XLNet的实现改FP16
https://github.com/NVIDIA/apex/issues/394
[5] 专栏博客
https://zhuanlan.zhihu.com/p/79887894


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









