







#include <iostream>
using namespace std;
void main()
{
int i=0;
int a=0;
int b=0;
a=(i++)+(i++)+(i++); // i++运算执行在 整个表达式 之后 。 就是先把三个i 加起来赋给a 然后再i++
cout<<" a = "<<a<<endl;
i=0;
b=(++i)+(++i)+(++i);//同理 ++i 执行 在先 执行每个表达式之前 联系运算符的优先级。
cout<<" b = "<<b<<endl;
}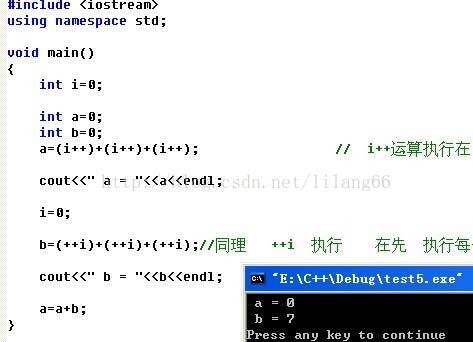
对应的汇编代码。 a= 0和b=7

翻译成C的伪码 应该是这样的:
m = i + 1; // i 的临时变量m
i = m;
n = i + 1; // i 的临时变量m
i = n;
h = i + i; // 表达式的临时返回值 h
o = i + 1; // i 的临时变量m
i = o;
h = h + i; // 结果为表达式的 返回值
s = h;
下面的例子: 堆栈数据结构实现
#include <iostream>
using namespace std;
#define STACK_INIT_SIZE 100
#define STACK_INCREATEMENT 10
typedef struct stack {
int *base;
int *top;
int size;
}sqStack;
int initStack( sqStack &s )
{
s.base = ( int * )malloc( STACK_INIT_SIZE * sizeof( int* ) );
if( !s.base ) exit( -1 );
s.top = s.base;
s.size = STACK_INIT_SIZE;
return 0;
}
int isStackEmpty( sqStack &s )
{
return s.top == s.base;
}
int push( sqStack &s, int &elem )
{
if( s.top - s.base >= s.size ){
s.base = ( int * )realloc( s.base, ( s.size + STACK_INCREATEMENT ) * sizeof( int * ) );
if( !s.base ) exit( -1 );
s.top = s.base + s.size;
s.size += STACK_INCREATEMENT;
}
*s.top++ = elem;
// *--s.top = elem;
return 1;
}
int pop( sqStack &s, int &elem )
{
if( isStackEmpty( s ) ){
return 0;
}
elem = *--s.top;
elem = *s.top++;
return 1;
}
int main(void)
{
sqStack s;
initStack( s );
int i = 0;
push( s, i );
i = 5;
pop( s, i );
cout<<" i = "<<i<<endl;
return 0;
}*s.top++ = elem;
// *---s.top = elem;
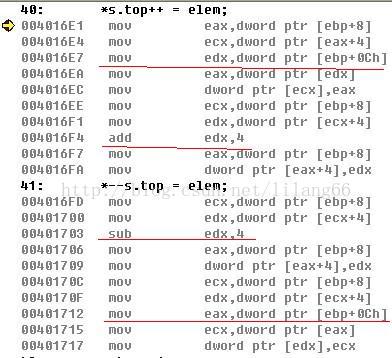
从汇编来看,很容易看那出来 赋值与改变指针值 哪个在先 哪个在后。而同理 在自加或自减运算符在作为右值的时候 同样有下图:

也很清晰的看到 区别。 自减或自加运算符在前,则运算在整个表达式之前,否则在整个表达式运算之后。 图为vc6 对应汇编















 4015
4015

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









