










目录
一、什么是统计信息
对象统计信息描述数据是如何在数据库中存储的。统计信息是优化器的代价计算的依据,可以帮助优化器较精确地估算成本,对执行计划的选择起着至关重要的作用。 达梦数据库的统计信息分三种类型:表统计信息、列统计信息、索引统计信息。通过直方图来表示。
二、统计信息如何生成
统计信息生成过程分以下三个步骤:
1. 确定采样的数据:根据数据对象,确定需要分析哪些数据。
1) 表:计算表的行数、所占的页数目、平均记录长度
2) 列:统计列数据的分布情况
3) 索引:统计索引列的数据分布情况
2. 确定采样率
根据数据对象的大小,通过内部算法,确定数据的采样率。采样率与数据量成反比。
3. 生成直方图
有两种类型的直方图:频率直方图和等高直方图。根据算法分析表的数据分布特征,确定直方图的类型。频率直方图的每个桶(保存统计信息的对象)的高度不同,等高直方图每个桶的高度相同。例如,对列生成统计信息,当列值分布比较均匀时,会采用等高直方图,否则,采用频率直方图。在执行查询时,如果数据对象存在统计信息,代价算法可以根据统计信息中的数据,比较精确地计算出操作所需花费的成本,以此来确定连接方式、对象访问路径、连接顺序,选择最优的执行计划。用户也可以通过修改 OPTIMIZER_DYNAMIC_SAMPLING 参数值在缺乏统计信息时进行动态统计信息收集。
三、如何更新和删除统计信息
3.1、manager客户端
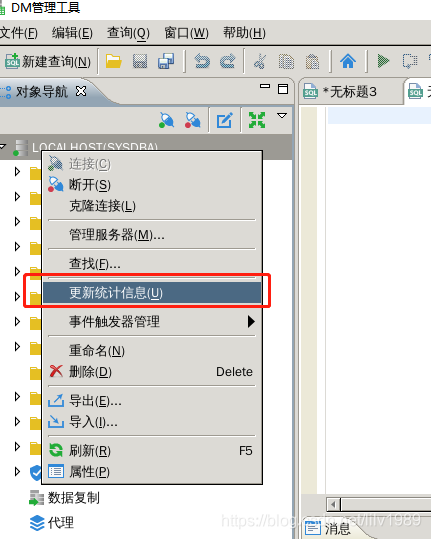
1、更新库的统计信息
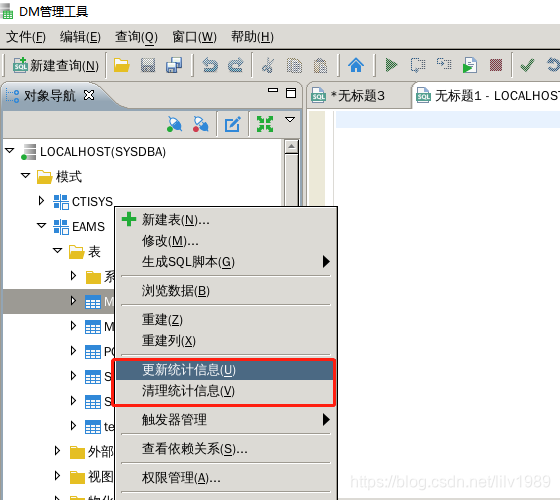
2、更新和清理表的统计信息
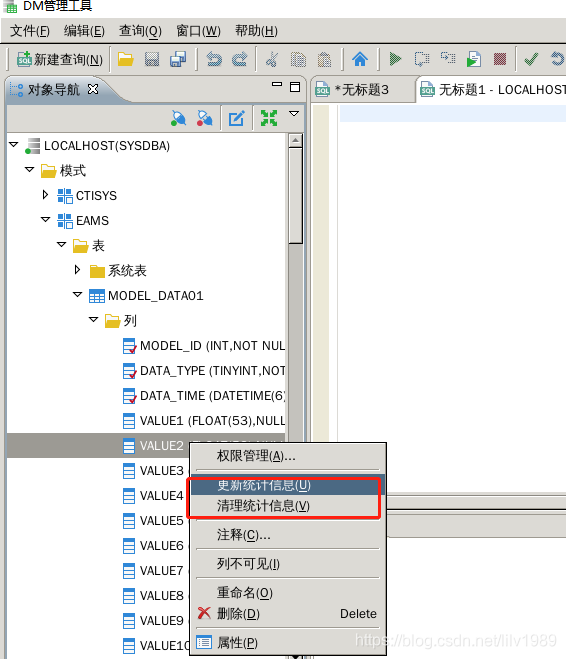
3、更新和清理列的统计信息
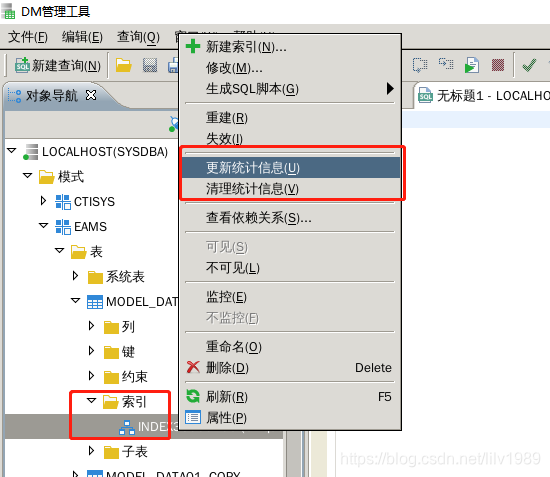
4、更新和清理索引的统计信息
3.2、系统函数
通过查询系统表可查看有哪些系统函数
SQL> SELECT ID,NAME FROM V$IFUN WHERE NAME LIKE 'SP%STAT%INIT' ORDER BY NAME;
行号 ID NAME
---------- ----------- ----------------------
1 708 SP_COL_CTL_STAT_INIT
2 394 SP_COL_STAT_DEINIT
3 387 SP_COL_STAT_INIT
4 384 SP_DB_STAT_DEINIT
5 383 SP_DB_STAT_INIT
6 709 SP_INDEX_CTL_STAT_INIT
7 392 SP_INDEX_STAT_DEINIT
8 381 SP_INDEX_STAT_INIT
9 1727 SP_INDEX_STAT_INIT
10 391 SP_SQL_STAT_INIT
11 1726 SP_SQL_STAT_INIT
行号 ID NAME
---------- ----------- ----------------------
12 398 SP_TAB_COL_STAT_DEINIT
13 389 SP_TAB_COL_STAT_INIT
14 707 SP_TAB_CTL_STAT_INIT
15 386 SP_TAB_INDEX_STAT_INIT
16 2102 SP_TAB_MSTAT_DEINIT
17 399 SP_TAB_STAT_DEINIT
18 390 SP_TAB_STAT_INIT以下是对重要的更新和清理统计信息系统函数的使用说明
以下是对重要的更新和清理统计信息系统函数的使用说明
1、收集数据库的统计信息,对库上所有模式下的所有用户表以及表上的所有索引生成统计信息
CALL SP_DB_STAT_INIT ();
2、清空库的统计信息
CALL SP_DB_STAT_DEINIT ();
3、对某张表或某个索引生成统计信息 CALL SP_TAB_STAT_INIT ('模式名', '表名或索引名');
对表 SYSOBECTS 生成统计信息 CALL SP_TAB_STAT_INIT ('SYS', 'SYSOBJECTS');
4、清空某张表的统计信息 CALL SP_TAB_STAT_DEINIT ('模式名', '表名');
清空表 SYSOBECTS 的统计信息 CALL SP_TAB_STAT_DEINIT ('SYS', 'SYSOBJECTS');
5、对某个表上所有的列生成统计信息 CALL SP_TAB_COL_STAT_INIT ('模式名', '表名');
对'SYSOBJECTS'表上所有的列生成统计信息 CALL SP_TAB_COL_STAT_INIT ('SYS', 'SYSOBJECTS');
6、清空某个表上所有的列的统计信息 CALL SP_TAB_COL_STAT_DEINIT ('模式名', '表名');
清空'SYSOBJECTS'表上所有的列统计信息 CALL SP_TAB_COL_STAT_DEINIT ('SYS', 'SYSOBJECTS');
7、对指定的列生成统计信息,不支持大字段列和虚拟列 CALL SP_COL_STAT_INIT ('模式名', '表名', '列名');
对表 SYSOBJECTS 的 ID 列生成统计信息 CALL SP_COL_STAT_INIT ('SYS', 'SYSOBJECTS', 'ID');
8、清空指定列的统计信息 CALL SP_COL_STAT_DEINIT ('模式名', '表名', '列名');
清空表 SYSOBJECTS 的 ID 列统计信息 CALL SP_COL_STAT_INIT ('SYS', 'SYSOBJECTS', 'ID');
9、对表上所有的索引生成统计信息 CALL SP_TAB_INDEX_STAT_INIT ('模式名', '表名');
对 SYSOBJECTS 表上所有的索引生成统计信息 CALL SP_TAB_INDEX_STAT_INIT ('SYS', 'SYSOBJECTS');
10、对指定的索引生成统计信息 CALL SP_INDEX_STAT_INIT ('模式名', '索引名');
对指定的索引 IND 生成统计信息 CALL SP_INDEX_STAT_INIT ('SYSDBA', 'IND');
11、清空指定的索引的统计信息 CALL SP_INDEX_STAT_DEINIT ('模式名', '索引名');
清空指定的索引 IND 的统计信息 CALL SP_INDEX_STAT_DEINIT ('SYSDBA', 'IND');
12、对某个 SQL 查询语句中涉及的所有表和过滤条件中的列(不包括大字段、ROWID)生成统计信息。可能返回的错误提示:1) 语法分析出错,sql 语句语法错误 2) 对象不支持统计信息,统计的表或者列不存在,或者不允许被统计 CALL SP_SQL_STAT_INIT ('SQL');
对'SELECT * FROM SYSOBJECTS'语句涉及的所有表生成统计信息 CALL SP_SQL_STAT_INIT ('SELECT * FROM SYSOBJECTS');
13、对指定的列生成统计信息,不支持大字段列和虚拟列 CALL SP_COL_STAT_INIT('模式名','表名','列名')
对表 SYSOBJECTS 的 ID 列生成统计信息 CALL SP_COL_STAT_INIT ('SYS', 'SYSOBJECTS', 'ID');
14、清空指定的列的统计信息 CALL SP_COL_STAT_DEINIT('模式名','表名','列名')
清空表 SYSOBJECTS 的 ID 列统计信息 CALL SP_COL_STAT_DEINIT ('SYS', 'SYSOBJECTS', 'ID');
15、对某个表上所有的列,按照指定的采样率生成统计信息 CALL SP_STAT_ON_TABLE_COLS('模式名','表名','采样率')
对'SYSOBJECTS'表上所有的列生成统计信息,采样率 90 CALL SP_STAT_ON_TABLE_COLS('SYS','SYSOBJECTS',90);
16、删除一个表的多维统计信息 CALL SP_TAB_MSTAT_DEINIT('模式名','表名')
删除表 SYSDBA.L1 上所有的多维统计信息 CALL SP_TAB_MSTAT_DEINIT('SYSDBA','L1'); 3.3、系统包
通过manager客户端查看有dbms_stats有哪些具体实现
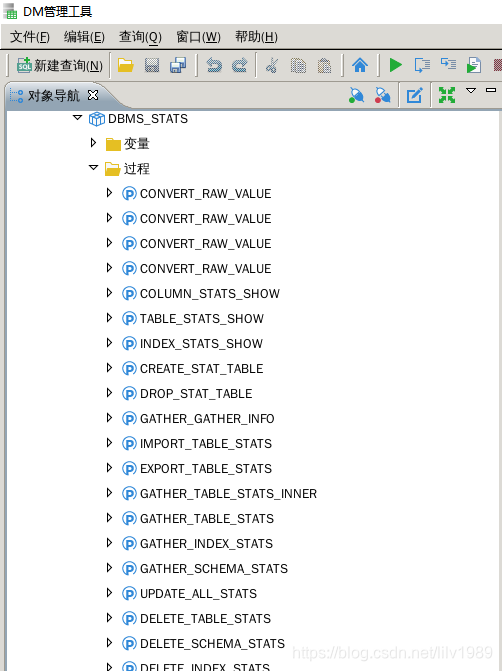
也可以通过 desc dbms_stats可以查看包体的内容,篇幅问题,没有列全
SQL> desc dbms_stats;
行号 NAME TYPE$ IO DEF RT_TYPE
---------- ----------------- ------------ --- --- -------
12 M_N FLOAT OUT
13 COLUMN_STATS_SHOW PROC
17 TABLE_STATS_SHOW PROC
20 INDEX_STATS_SHOW PROC
行号 NAME TYPE$ IO DEF RT_TYPE
---------- ------------------ ------------- ----- ----- -------
23 CREATE_STAT_TABLE PROC
28 DROP_STAT_TABLE PROC
73 GATHER_TABLE_STATS PROC
以下是包内重要的存储过程的使用说明,更详细的参数说明可参考DM8-System Package
1、更新已有的统计信息
DBMS_STATS.UPDATE_ALL_STATS();
2、收集模式下对象的统计信息,如果数据量较大,该过程可能较慢
DBMS_STATS.GATHER_SCHEMA_STATS(‘模式名’,100,TRUE,'FOR ALL COLUMNS SIZE AUTO');
3、根据设定参数,删除模式下对象的统计信息
DBMS_STATS.DELETE_SCHEMA_STATS('模式名');
4、根据模式名,表名获得该表的统计信息
DBMS_STATS.TABLE_STATS_SHOW('模式名','表名');
5、根据设定的参数,收集表、表中的列和表上的索引的统计信息。其中,对于表,只搜集表的总行数、总的页数、已经使用的页数等基本信息。
DBMS_STATS.GATHER_TABLE_STATS('模式名','表名',null,100,TRUE,'FOR ALL COLUMNS SIZE AUTO');
6、根据设定参数,删除与表相关对象的统计信息
DBMS_STATS.DELETE_TABLE_STATS('模式名','表名');
7、根据设定的参数,收集索引的统计信息。
DBMS_STATS.GATHER_INDEX_STATS('模式名','索引名');
8、根据设定参数,删除索引的统计信息
DBMS_STATS.DELETE_INDEX_STATS('模式名','索引名');
9、根据设定参数,删除列的统计信息
DBMS_STATS.DELETE_COLUMN_STATS('模式名','表名','列名');
10、根据模式名,表名和列名获得该列的统计信息。返回两个结果集:一个是列的统计信息,另一个是直方图的统计信息。
DBMS_STATS.COLUMN_STATS_SHOW('模式名','表名','列名');3.4、SQL
1、设置列、索引生成统计信息。
语法格式
STAT <统计信息采样率百分比> [SIZE <直方图桶数>] ON <统计对象> [GLOBAL]
<统计对象>::=
[<模式名>.] <表名> (<列名>{,<列名>}) |
INDEX [<模式名>.]<索引名>
参数
1. <统计信息采样率百分比> 指定统计信息采样率的百分比。必须为[0,100]范围内
整数;
2. <直方图桶数> 指定统计信息的直方图桶数,单列取值范围为0或[1~254]范围内
的整数,其中0表示不限制。不指定时系统根据数据的实际情况动态确定。多列的取值范围
是[1,2500];
3. <模式名> 指定收集统计信息的模式。缺省为当前会话的模式名;
4. <表名> 指定收集统计信息的表;
5. <列名> 指定收集统计信息的列。当前最大支持127列;
6. <索引名> 指定收集统计信息的索引;
7. GLOBAL 用于MPP环境下各节点数据收集后统一生成统计信息。
例 1 对 SYSOBJECTS 表上 ID 列生成统计信息,采样率的百分比为 30%。
STAT 30 ON SYS.SYSOBJECTS (ID);
例 2 对 PURCHASING 模式下的索引 S1 生成统计信息,采样率为 50%。
STAT 50 ON INDEX PURCHASING.S1;
例 3 对 SYSOBJECTS 表上 PID,NAME 列生成统计信息,采样率的百分比为 30%。
STAT 30 ON SYS.SYSOBJECTS (PID,NAME);
2、设置表生成统计信息。
语法格式
STAT ON [<模式名>.]<表名> [GLOBAL];
参数
1. <模式名> 指定生成统计信息的表的模式。缺省为当前会话的模式名;
2. <表名> 指定生成统计信息的表;
3. GLOBAL 用于MPP环境下各节点数据收集后统一生成统计信息。
例 1 为 SYSOBJECTS 表生成统计信息。 STAT ON SYS.SYSOBJECTS;
四、动态更新统计信息
为什么要动态更新统计信息呢,数据库经常会在计划缓存中生成了非最优的计划,达梦数据库的优化器是基于代价的优化器,精确的统计信息有助于CBO生成更优的计划,但是统计信息并不会实时更新。所以,统计信息的不准确,就导致CBO生成了非最优的计划。统计信息只有在我们手动更新的时候才会生成,所以当我们发现一些业务表的相关语句存在因为数据的变化而导致语句执行效率差异变大时,我们可以通过设定定时作业对表进行统计信息的收集。
4.1、自动收集统计信息
DM 数据库支持统计信息的自动收集,当全表数据量变化超过设定阈值后可自动更新统计信息,方法如下
1、打开表数据量监控开关,参数值为 1 时监控所有表,2 时仅监控配置表
SP_SET_PARA_VALUE(1,'AUTO_STAT_OBJ',1);
2、设置 SYSDBA.TEST 表数据变化率超过 50% 时触发自动更新统计信息
DBMS_STATS.SET_TABLE_PREFS('SYSDBA','TEST','STALE_PERCENT',50);
3、配置自动收集统计信息触发时机,尽量在业务低峰期收集
SP_CREATE_AUTO_STAT_TRIGGER(1, 1, 1, 1,'01:00', '2021/6/10',120,1);
SP_CREATE_AUTO_STAT_TRIGGER(
TYPE INT, --间隔类型,默认为天
FREQ_INTERVAL INT, --间隔频率,默认 1
FREQ_SUB_INTERVAL INT, --间隔频率,与 FREQ_INTERVAL 配合使用
FREQ_MINUTE_INTERVAL INT, --间隔分钟,默认为 1440
STARTTIME VARCHAR(128), --开始时间,默认为 22:00
DURING_START_DATE VARCHAR(128), --重复执行的起始时间,默认 1900/1/1
MAX_RUN_DURATION INT, --允许的最长执行时间(秒),默认不限制
ENABLE INT --0 关闭,1 启用 --默认为 1
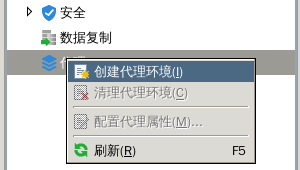
);4.2、manager客户端代理方式
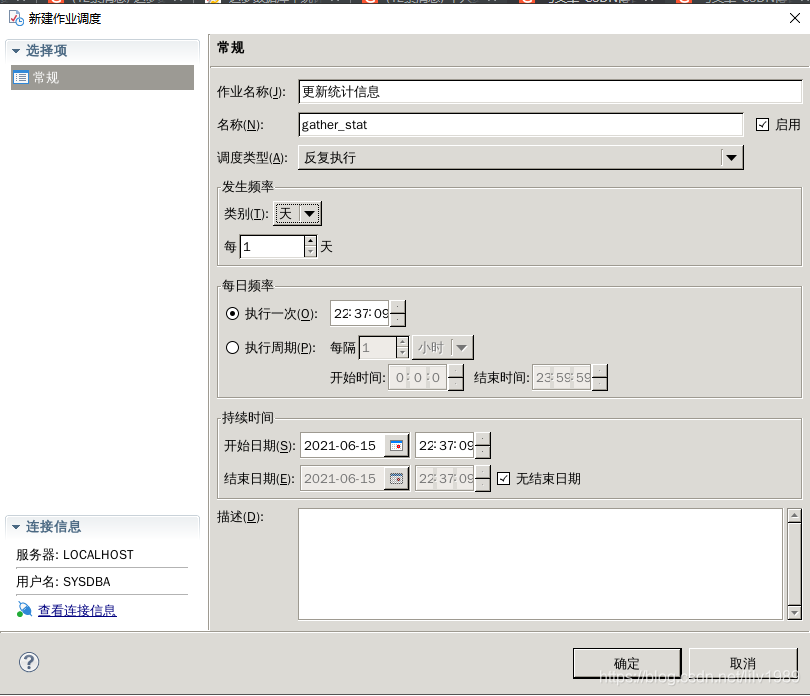
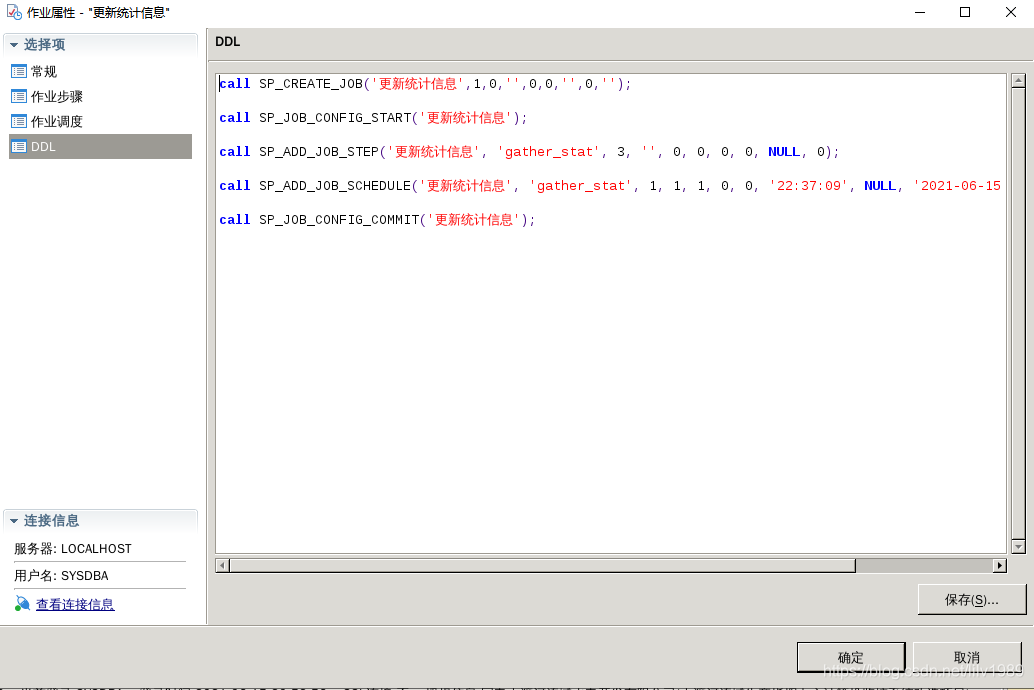
1、创建代理环境
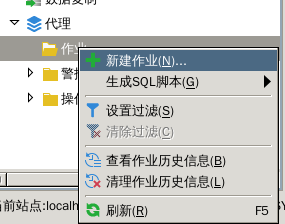
2、新建作业
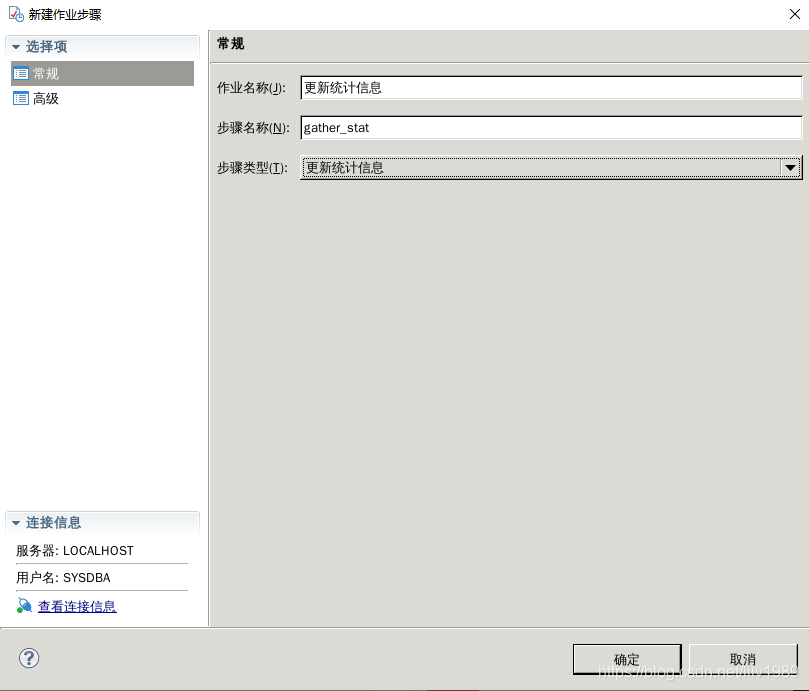
根据实际情况设置更新周期
五、统计信息的使用
5.1、数据库升级完需要更新统计信息
因为数据库bug或者需求更新,需要升级数据库,数据库的优化器可能在当前最新版本里做出了更新,这时候就需要更新统计信息,sql语句执行计划有最优选择
5.2、dts迁移工具迁移数据后需要更新统计信息
迁移完数据数据后,新增的模式数据并没有在当前库记录统计信息,因此需要更新统计信息
5.3、新建表或者新建表索引后需要更新统计信息
数据库在创建一张表并导入数据后或者新建一个索引后,系统并不会自动生成对应的统计信息,这样的结果就是会导致执行计划不正确,进而影响业务的性能
5.4、批量的DML操作后明显影响该表的执行效率
六、实例说明
统计信息可以简单理解为将索引的某一列进行统计分析,创建表时数据库会自己创建聚簇索引或非聚簇索引,列出其最大最小值,存在多少不同值,各个值存在多少个辅助信息。对于没有统计信息的列按照一定比例进行概率过滤。达梦数据库dm.ini配置文件有专用的两个参数:
SEL_RATE_EQU ,等值过滤选择率,默认0.025。
SEL_RATE_SINGLE,一般条件选择率,默认0.05。
创建一张用户表,插入十万条数据,如下:
SQL> create table person (id int,name varchar(128),age int) ;
操作已执行
已用时间: 7.071(毫秒). 执行号:75.
SQL> insert into person select level,'lilv'||level,level connect by level <=100000;
影响行数 100000
已用时间: 78.904(毫秒). 执行号:76.
SQL> commit;
操作已执行
已用时间: 1.652(毫秒). 执行号:77.
6.1、没有统计信息
SQL> DBMS_STATS.TABLE_STATS_SHOW('SYSDBA','PERSON');
行号 NUM_ROWS LEAF_BLOCKS LEAF_USED_BLOCKS
---------- -------------------- -------------------- --------------------
1 NULL NULL NULL
已用时间: 2.130(毫秒). 执行号:78.
SQL> DBMS_STATS.COLUMN_STATS_SHOW('SYSDBA','PERSON','NAME');
行号 NUM_DISTINCT LOW_VALUE HIGH_VALUE NUM_NULLS NUM_BUCKETS SAMPLE_SIZE HISTOGRAM
---------- -------------------- --------- ---------- -------------------- ----------- -------------------- ---------
1 NULL NULL NULL NULL NULL NULL NULL
已用时间: 0.940(毫秒). 执行号:80.
SQL> select * from sysstats;
未选定行
已用时间: 0.415(毫秒). 执行号:81.1、等值查询,#CSCN2涉及十万行数据,#SLCT2影响行数2500行,因为不存在统计信息,系统按100000 * 0.025直接给出2500的结果,执行时间15.199ms。
SQL> explain select * from person where name='lilv10000';
1 #NSET2: [12, 2500, 64]
2 #PRJT2: [12, 2500, 64]; exp_num(4), is_atom(FALSE)
3 #SLCT2: [12, 2500, 64]; PERSON.NAME = 'lilv10000'
4 #CSCN2: [12, 100000, 64]; INDEX33555466(PERSON)
已用时间: 1.740(毫秒). 执行号:0.
SQL>
SQL>
SQL> select * from person where name='lilv10000';
行号 ID NAME AGE
---------- ----------- --------- -----------
1 10000 lilv10000 10000
已用时间: 15.199(毫秒). 执行号:82.
2、一般条件查询,#CSCN2涉及十万行数据,#SLCT2影响行数5000行,因为不存在统计信息,系统按100000 * 0.05直接给出5000的结果,执行时间5.739ms。
已用时间: 5.739(毫秒). 执行号:85.
SQL> explain select * from person where age>50000;
1 #NSET2: [12, 5000, 64]
2 #PRJT2: [12, 5000, 64]; exp_num(4), is_atom(FALSE)
3 #SLCT2: [12, 5000, 64]; PERSON.AGE > 50000
4 #CSCN2: [12, 100000, 64]; INDEX33555466(PERSON)
已用时间: 1.045(毫秒). 执行号:0.
SQL> select * from person where age>50000;
行号 ID NAME AGE
---------- ----------- ---------- -----------
49996 99996 lilv99996 99996
49997 99997 lilv99997 99997
49998 99998 lilv99998 99998
49999 99999 lilv99999 99999
50000 100000 lilv100000 100000
50000 rows got
已用时间: 5.739(毫秒). 执行号:85.3、等值和一般条件组合查询,#CSCN2涉及十万行数据,#SLCT2影响行数125行,因为不存在统计信息,系统按100000 * 0.05*0.025直接给出125的结果,执行时间10.804ms。
SQL> explain select * from person where name='lilv10000' and age>50000;
1 #NSET2: [12, 125, 64]
2 #PRJT2: [12, 125, 64]; exp_num(4), is_atom(FALSE)
3 #SLCT2: [12, 125, 64]; (PERSON.NAME = 'lilv10000' AND PERSON.AGE > 50000)
4 #CSCN2: [12, 100000, 64]; INDEX33555466(PERSON)
已用时间: 1.154(毫秒). 执行号:0.
SQL>
SQL> select * from person where name='lilv10000' and age>50000;
未选定行
已用时间: 10.804(毫秒). 执行号:87.
以上看出这个默认值代价的估算是非常粗略的,尤其对于复杂的查询,如果没有统计信息CBO很有可能选择错误的执行计划,收集一下这个表的统计信息,再来对比一下执行计划。
6.2、统计信息采样率10%
下面我们来更新表的统计信息,更新10%的统计信息看下执行计划有何不同
SQL> DBMS_STATS.GATHER_TABLE_STATS('SYSDBA','PERSON',null,10,TRUE,'FOR ALL COLUMNS SIZE AUTO');
DMSQL 过程已成功完成
已用时间: 55.833(毫秒). 执行号:88.
SQL> DBMS_STATS.TABLE_STATS_SHOW('SYSDBA','PERSON');
行号 NUM_ROWS LEAF_BLOCKS LEAF_USED_BLOCKS
---------- -------------------- -------------------- --------------------
1 100000 528 520
已用时间: 0.277(毫秒). 执行号:89.
SQL> DBMS_STATS.COLUMN_STATS_SHOW('SYSDBA','PERSON','NAME');
行号 NUM_DISTINCT LOW_VALUE HIGH_VALUE NUM_NULLS NUM_BUCKETS SAMPLE_SIZE HISTOGRAM
---------- -------------------- ---------- ---------- -------------------- ----------- -------------------- ---------------
1 9375 lilv100000 lilv99993 0 300 9375 HEIGHT BALANCED
已用时间: 27.950(毫秒). 执行号:90.1、等值查询,#CSCN2涉及十万行数据,#SLCT2影响行数1行,因为存在采样率10%的统计信息,系统根据统计信息给出1的结果,单列估算准确,name列只存在一个为lilv10000的的行。执行时间9.858ms,执行效率有部分提高。
SQL> explain select * from person where name='lilv10000';
1 #NSET2: [12, 1, 64]
2 #PRJT2: [12, 1, 64]; exp_num(4), is_atom(FALSE)
3 #SLCT2: [12, 1, 64]; PERSON.NAME = 'lilv10000'
4 #CSCN2: [12, 100000, 64]; INDEX33555466(PERSON)
已用时间: 0.893(毫秒). 执行号:0.
SQL>
SQL> select * from person where name='lilv10000';
行号 ID NAME AGE
---------- ----------- --------- -----------
1 10000 lilv10000 10000
已用时间: 9.858(毫秒). 执行号:92.2、一般条件查询,#CSCN2涉及十万行数据,#SLCT2影响行数48379行,因为采样率只有10%,系统根据统计信息只给出48379的结果,执行时间4.121ms,执行效率也有部分提高。
SQL> explain select * from person where age>50000;
1 #NSET2: [12, 48379, 64]
2 #PRJT2: [12, 48379, 64]; exp_num(4), is_atom(FALSE)
3 #SLCT2: [12, 48379, 64]; PERSON.AGE > 50000
4 #CSCN2: [12, 100000, 64]; INDEX33555466(PERSON)
已用时间: 1.324(毫秒). 执行号:0.
SQL> select * from person where age>50000;
行号 ID NAME AGE
---------- ----------- ---------- -----------
49996 99996 lilv99996 99996
49997 99997 lilv99997 99997
49998 99998 lilv99998 99998
49999 99999 lilv99999 99999
50000 100000 lilv100000 100000
50000 rows got
已用时间: 4.121(毫秒). 执行号:95.3、等值和一般条件组合查询,#CSCN2涉及十万行数据,#SLCT2影响行数1行,因为存在采样率10%的统计信息,系统根据统计信息给出1的结果,多列混合估算准确,不存在满足条件的行,执行时间8.689ms,执行效率也有部分提高。
SQL> explain select * from person where name='lilv10000' and age>50000;
1 #NSET2: [12, 1, 64]
2 #PRJT2: [12, 1, 64]; exp_num(4), is_atom(FALSE)
3 #SLCT2: [12, 1, 64]; (PERSON.NAME = 'lilv10000' AND PERSON.AGE > 50000)
4 #CSCN2: [12, 100000, 64]; INDEX33555466(PERSON)
已用时间: 1.976(毫秒). 执行号:0.
SQL> select * from person where name='lilv10000' and age>50000;
未选定行
已用时间: 8.689(毫秒). 执行号:103.
6.3、统计信息采样率100%
更新采样率100%的统计信息后可以看到name列的统计信息中high_value和sample_size都要高于采样率10%的统计信息
SQL> DBMS_STATS.GATHER_TABLE_STATS('SYSDBA','PERSON',null,100,TRUE,'FOR ALL COLUMNS SIZE AUTO');
DMSQL 过程已成功完成
已用时间: 277.884(毫秒). 执行号:107.
SQL> DBMS_STATS.TABLE_STATS_SHOW('SYSDBA','PERSON');
行号 NUM_ROWS LEAF_BLOCKS LEAF_USED_BLOCKS
---------- -------------------- -------------------- --------------------
1 100000 528 520
已用时间: 0.873(毫秒). 执行号:108.
SQL> DBMS_STATS.COLUMN_STATS_SHOW('SYSDBA','PERSON','NAME');
行号 NUM_DISTINCT LOW_VALUE HIGH_VALUE NUM_NULLS NUM_BUCKETS SAMPLE_SIZE HISTOGRAM
---------- -------------------- --------- ---------- -------------------- ----------- -------------------- ---------------
1 100000 lilv1 lilv99999 0 300 100000 HEIGHT BALANCED
1、等值查询,#CSCN2涉及十万行数据,#SLCT2影响行数1行,执行计划跟采样率10%的统计信息情况一致,执行时间7.677ms,执行效率又有部分提高。
SQL> explain select * from person where name='lilv10000';
1 #NSET2: [12, 1, 64]
2 #PRJT2: [12, 1, 64]; exp_num(4), is_atom(FALSE)
3 #SLCT2: [12, 1, 64]; PERSON.NAME = 'lilv10000'
4 #CSCN2: [12, 100000, 64]; INDEX33555466(PERSON)
已用时间: 0.893(毫秒). 执行号:0.
SQL>
SQL> select * from person where name='lilv10000';
行号 ID NAME AGE
---------- ----------- --------- -----------
1 10000 lilv10000 10000
已用时间: 7.677(毫秒). 执行号:117.2、一般条件查询,#CSCN2涉及十万行数据,因为统计信息采样率100%,#SLCT2影响行数49999行,单列估算准确,执行时间3.055ms,执行效率也有部分提高。
SQL> explain select * from person where age>50000;
1 #NSET2: [12, 49999, 64]
2 #PRJT2: [12, 49999, 64]; exp_num(4), is_atom(FALSE)
3 #SLCT2: [12, 49999, 64]; PERSON.AGE > 50000
4 #CSCN2: [12, 100000, 64]; INDEX33555466(PERSON)
已用时间: 1.538(毫秒). 执行号:0.
SQL> select * from person where age>50000;
行号 ID NAME AGE
---------- ----------- ---------- -----------
49996 99996 lilv99996 99996
49997 99997 lilv99997 99997
49998 99998 lilv99998 99998
49999 99999 lilv99999 99999
50000 100000 lilv100000 100000
50000 rows got
已用时间: 3.055(毫秒). 执行号:119.3、等值和一般条件组合查询,#CSCN2涉及十万行数据,执行计划跟采样率10%的统计信息情况一致,执行时间8.379ms,执行效率相差不大。
SQL> explain select * from person where name='lilv10000' and age>50000;
1 #NSET2: [12, 1, 64]
2 #PRJT2: [12, 1, 64]; exp_num(4), is_atom(FALSE)
3 #SLCT2: [12, 1, 64]; (PERSON.NAME = 'lilv10000' AND PERSON.AGE > 50000)
4 #CSCN2: [12, 100000, 64]; INDEX33555466(PERSON)
已用时间: 2.043(毫秒). 执行号:0.
SQL> select * from person where name='lilv10000' and age>50000;
未选定行
已用时间: 8.379(毫秒). 执行号:143.
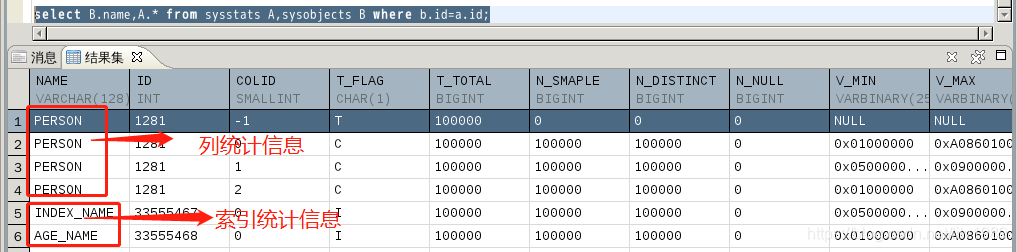
6.4、创建二级索引并更新统计信息
先创建索引并更新统计信息,如下:
SQL> create index index_name on person(name);
操作已执行
已用时间: 252.488(毫秒). 执行号:144.
SQL> create index age_name on person(age);
操作已执行
已用时间: 139.456(毫秒). 执行号:227.
SQL> DBMS_STATS.GATHER_TABLE_STATS('SYSDBA','PERSON',null,100,TRUE,'FOR ALL COLUMNS SIZE AUTO');
DMSQL 过程已成功完成
已用时间: 153.481(毫秒). 执行号:228.
1、等值查询,执行计划不再走聚集索引,变为刚创建的INDEX_NAME索引,执行时间0.378ms,执行效率提高巨大。
SQL> explain select * from person where name='lilv10000';
1 #NSET2: [0, 1, 64]
2 #PRJT2: [0, 1, 64]; exp_num(4), is_atom(FALSE)
3 #BLKUP2: [0, 1, 64]; INDEX_NAME(PERSON)
4 #SSEK2: [0, 1, 64]; scan_type(ASC), INDEX_NAME(PERSON), scan_range['lilv10000','lilv10000']
已用时间: 45.579(毫秒). 执行号:0.
SQL>
SQL> select * from person where name='lilv10000';
行号 ID NAME AGE
---------- ----------- --------- -----------
1 10000 lilv10000 10000
已用时间: 0.378(毫秒). 执行号:226.2、等值和一般条件组合查询,age列继续走聚集索引,name列走刚创建的INDEX_NAME索引,执行时间0.952ms,执行效率提高巨大。
SQL> explain select * from person where name='lilv10000' and age>50000;
1 #NSET2: [0, 1, 64]
2 #PRJT2: [0, 1, 64]; exp_num(4), is_atom(FALSE)
3 #SLCT2: [0, 1, 64]; PERSON.AGE > 50000
4 #BLKUP2: [0, 1, 64]; INDEX_NAME(PERSON)
5 #SSEK2: [0, 1, 64]; scan_type(ASC), INDEX_NAME(PERSON), scan_range['lilv10000','lilv10000']
已用时间: 1.348(毫秒). 执行号:0.
SQL> select * from person where name='lilv10000' and age>50000;
未选定行
已用时间: 0.952(毫秒). 执行号:233.
7、总结
1、统计信息的收集可以大概率的修正对过滤行数的估算;
2、统计信息对CBO选择正确的执行计划非常重要,对执行效率的影响非常大,在应用系统运行过程中,有时候用户可能会发现系统的响应速度越来越慢。这其中可能的原因之一就是随着数据规模的增长,SQL 语句的执行计划已经不是处于最优状态,需要对 SQL语句进行调整或者对统计信息进行更新;
3、统计信息收集的比列根据实际情况来设置,如果可行的话,就选择采用率为100 的方式收集。业务繁忙又必须更新统计信息的情况下,可先更新一部分来满足应用需求;
4、使用统计信息可以提升数据查询的效率,而定期地更新统计信息则有助于提高统计信息的有效性。象为了回收空间做清理一样,经常更新统计信息也是对更新频繁的表更有用。不过,即使是更新非常频繁的表,如果它的数据的统计分布并不经常改变,那么也不需要更新统计信 息。更新统计信息需要在业务低谷的时候去操作,在高峰操作可能导致业务瘫痪;

















 1623
1623

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









