






 本文介绍了唯一可译码的概念和Kraft不等式,提出了两种判断方法,包括基于异前缀码的判断和Sardinas-Patterson算法,并提供了C语言的程序代码示例来实现后者,用于检查码字集合是否构成唯一可译码。
本文介绍了唯一可译码的概念和Kraft不等式,提出了两种判断方法,包括基于异前缀码的判断和Sardinas-Patterson算法,并提供了C语言的程序代码示例来实现后者,用于检查码字集合是否构成唯一可译码。
本文为信息论李莉萍老师周一上午3-4节班级第一组成员作业。
小组成员信息:P02114016甘欣杭、P02114023叶吉耀、P02114036吴芳芳、P02114052王浩、P02114076韦懿原。
一、引言
信源编码的设计准则是,设计完成的编码必须是唯一可译码才能够被使用。
根据唯一可译码的定义:任意有限长的码元序列,只能被唯一地分割成一个个的码字,便被称为唯一可译码,希望在得到一组编码之后,能够判断所设计出来的是否是唯一可译码。唯一可译码存在性的判别,可以通过Kraft不等式给出唯一可译码存在的充分必要条件上,即:D进制码字集合,码集中每一Ci都是一个D进制符号串,设对应的码长分别是
,则存在唯一可译码的充要条件是
。显然,克劳夫特不等式只涉及唯可译码的存在问题而不涉及具体的码。它强调的是存在,但这并不是唯一可译码判断的充要条件。也就是说,唯一可译码一定满足克拉夫特不等式,但是反之,满足克拉夫特不等式的码不一定是唯一可译码。
二、算法的实现
目前,常用的判别唯一可译码的方法有两种:根据异前缀码来进行判断的方法,另一种是由A.A.Sardinas和G.W.Patterson于1957年提出的算法。
方法一:
根据异前缓码是唯一可译码来进行判断。其步骤如下:首先,观察是否为非奇异码。若是奇异码,肯定不是唯一可译码;其次,计算是否满足Kraft不等式。若不满足定不是唯一可译码;最后,将码画成一棵码树图,观察是否满足异前缓码的码树图的构造,若满足则是唯一可译码。这种方法的理论基础是异前缀码一定是唯一可译码,通过经典的Kraft不等式及码树图进行判别,但它的缺点也是显而易见的,若不是异前缀码时,则此方法无法判断是否是唯一可译码。
方法二:
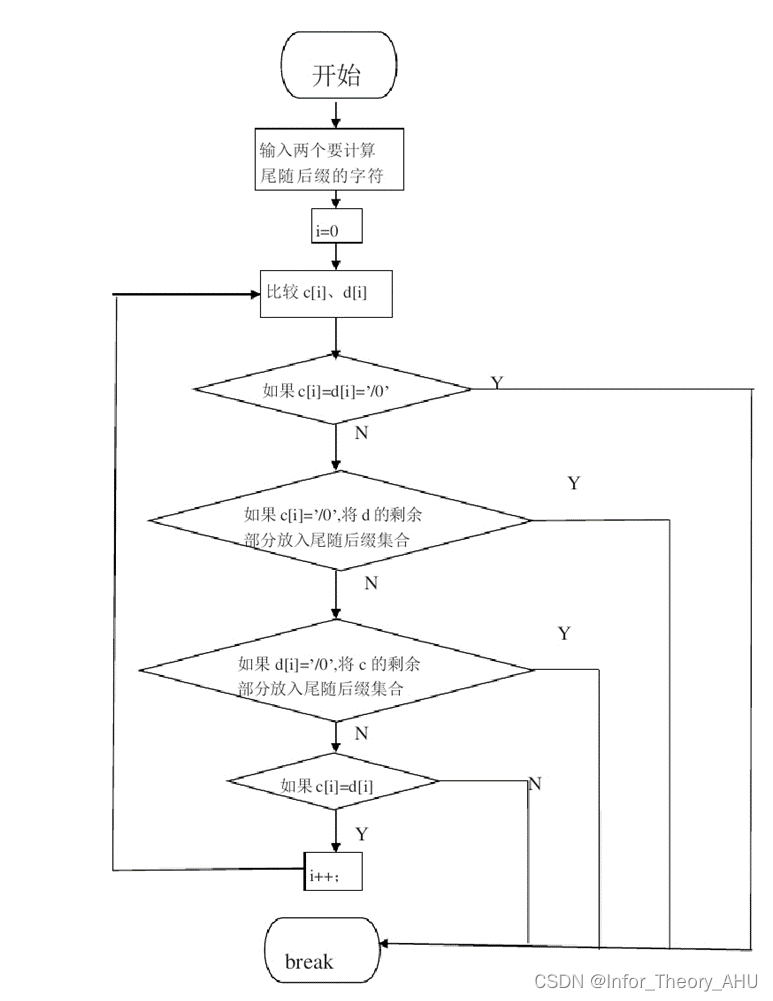
使用A.A.Sardinas和G.W.Patterson设计的判断法。其判断准则为:计算分组码C中所有可能的尾随后缀集合,观察
中有没有包含任一码字,若无则为唯一可译码:若有则一定不是唯一可译码。算法中的关键为尾随后缀集合F的构造。步骤如下:
(1)考查中所有的码字,若
是
的前缀,则将相应的后缀作为一个尾随后缀放入集合
中;
(2)考查和
两个集合,若
是
的前缀或
是
的前缀,则将相应的后缀作为尾随后缀码放入集合
中;
(3)即为码
的尾随后缀集合;
(4)若F中出现了中的元素,则算法终止,返回假(
不是唯一可译码);否则若
中没有出现新的元素,则返回真。
本文将详细介绍第二种方法。
三、流程框图
四、程序代码
#include<stdio.h>
#include<string.h >
char c[100][50];
char f[300][50];
int N, sum = 0; // N为输入码字的个数, sum为尼随后缀集合中码字的个数
int flag; //判断是否唯一可译标查位
void patterson(char c[],char d[]) //检测尾随后缀
{
int i, j, k;
for (i = 0;; i++)
{
if (c[i] == '\0' && d[i] == '\0') //字符一样跳出
break;
if (c[i] == '\0') //d比c长,将d的尾随后缀放入f中
{
for (j = i; d[j] != '\0'; j++)f[sum][j - i] = d[j];
f[sum][j - i] = '\0';
for (k = 0; k < sum; k++)
{
if (strcmp(f[sum], f[k]) == 0) //查看当前生成的尾随后缀在f集合中是否存在
{
sum--; sum--; break;
}
}
sum++;
break;
}
if (d[i] == '\0') //c比d长,将c的wei'sui后缀放入f中
{
for (j = i; c[j] != '\0'; j++)f[sum][j - i] = c[j];
f[sum][j - i] = '\0';
for (k = 0; k < sum; k++)
{
if (strcmp(f[sum], f[k]) == 0) //查看当前生成的尾随后缀在f集合中是否存在
{
sum--; break;
}
}
sum++;
break;
}
if (c[i] != d[i])
break;
}
}
int main()
{
int i, j;
printf("请输入码字的个数(小于100):"); //输入码得个数
scanf_s("%d", &N,10);
while (N > 100)
{
printf("输入码字得个数过大,请输入小于100的数\n");
printf("请输入码字的个数(小于100):");
scanf_s("%d", &N,10);
}
flag = 0;
printf("请分别输入码字(每个码字长度小于50个字符):\n");
for (i = 0; i < N; i++)
{
scanf_s("%s", &c[i],51);
}
for(i=0;i<N-1;i++) //判断如果码本身是否重复
for (j = i + 1; j < N; j++)
{
if (strcmp(c[i], c[j]) == 0)
{
flag = 1; break;
}
}
if (flag == 1)
printf("这不是唯一可译码。\n");
else
{
for (i = 0; i < N ; i++) //根据原始编码生成的尾随后缀集合s[1]放入f中
{
for (j = i + 1; j < N; j++)
patterson(c[i], c[j]);
}
for (i = 0;; i++)
{
int s = 0;
for (j = 0; j < N; j++)
{
if (i == sum)
{
s = 1; break;
}
else patterson(f[i], c[j]);
}
if (s == 1)break;
}
for (i = 0; i < sum; i++) //判断p里面的字符串是否与s中的重复,重复则不是唯一的
{
for (j = 0; j < N; j++)
{
if (strcmp(f[i], c[j]) == 0)
{
flag = 1;
break;
}
}
}
if (flag == 1)
printf("这不是唯一可译码的。\n");
else
printf("这是唯一可译码。\n");
}
printf("尾随后缀集合为:");
for (i = 0; i <= sum; i++)
printf("\n%s", f[i]);
}
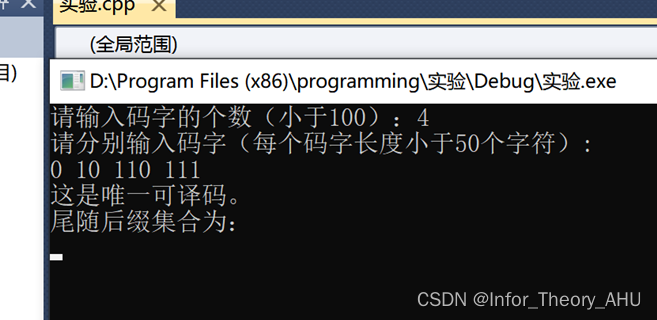
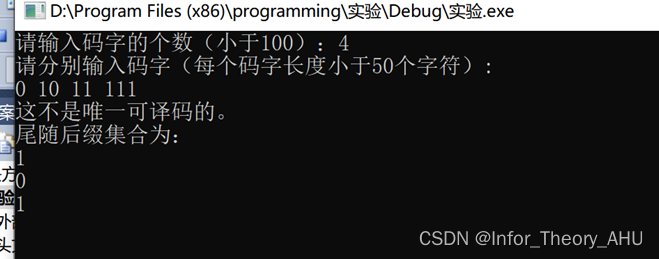
五、程序样例


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









