






一、费诺编码属于统计匹配编码,其编码步骤为::(1)将信源消息(符号)按其出现的概率由大到小依次排列;(2)将依次排列的信源符号按概率值分为两大组,使两个组的概率之和近于相同,并对各组分别赋予一个二进制码元“0”和“1”;(3)将每一大组的信源符号进一步再分成两组,使划分后的两个组的概率之和近于相同,并又分别赋予一个二进制符号“0”和“1”;(4)如此重复,直至每个组只剩下一个信源符号为止;(5)信源符号所对应的码字即为费诺码。费诺码考虑了信源的统计特性,使经常出现的信源符号能对应码长短的编码字。显然,费诺码仍然是一种相当好的编码方法。但是,这种编码方法不一定能使短码得到充分利用。尤其当信源符号较多,并有一些符号概率分布很接近时,分两大组的组合方法就很多。可能某种分配结果,会出现后面小组的“概率和”相差较远,因而使平均码长增加,所以费诺码不一定是最佳码。费诺码的编码方法实际上是构造码树的一种方法,所以费诺码是一种即时码。
| 编码输出 | 概率值 | 第一次分解 | 第二次分解 | 第三次分解 | 第四次分解 | ||||
| W1=0 | 0.40 | 0.40 | 0 |
|
|
| |||
| W1=10 | 0.30 | 0.60 | 1 | 0.30 | 0 |
|
| ||
| W1=111 | 0.15 |
|
| 0.30 | 1 | 0.15 | 1 |
| |
| W1=1101 | 0.10 |
|
|
|
| 0.15 | 0 | 0.10 | 1 |
| W1=1100 | 0.05 |
|
|
|
|
|
| 0.05 | 0 |
代码部分:
#include<bits/stdc++.h>
using namespace std;
int main(){
void Fenocode(double p[],int a ,int b,string c); // 函数声明
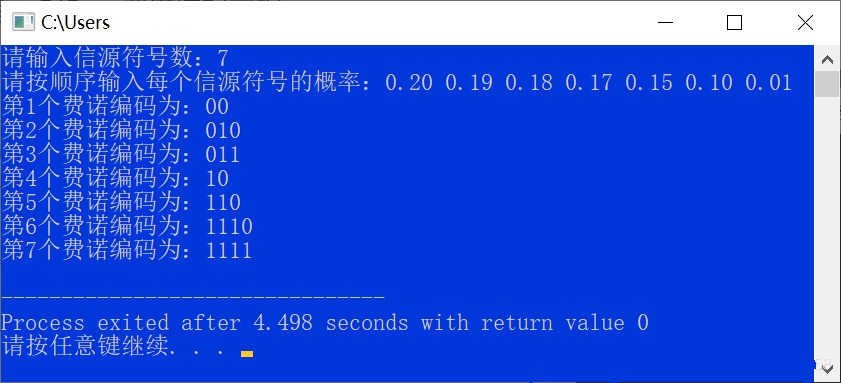
printf("请输入信源符号数:");
int count;
scanf("%d",&count);
double p[count];
printf("请按顺序输入每个信源符号的概率:"); // 按顺序输入 可从小到大 亦可从大到小
for(int i = 0 ; i<count ; i++){
scanf("%lf",&p[i]);
}
string feno = ""; // 费诺编码结果
Fenocode(p,0,count-1,feno);
return 0;
}
int cnt = 1; // 个数
void Fenocode(double p[],int begin ,int end,string fenocode){
double getSum(double p[],int a,int b); // 函数声明
// 边界条件
if(begin >= end){
// 输出结果
cout<<"第";
cout<<cnt;
cout<<"个费诺编码为:"+fenocode<<endl;
cnt++;
return;
}
// 找到分界值
double sum = getSum(p,begin,end);
int index = -1; // 初值设定
double minNum = sum; // 设定最小值
double tempSum = 0; // 前几个的和
for(int i = begin ; i <= end ; i++){
tempSum += p[i];
if(abs(sum-2*tempSum) < minNum){
index = i; // 记录当前最小的值
minNum = abs(sum-2*tempSum); // 更新最小值
}
}
// 递归左边部分
Fenocode(p,begin,index,fenocode+'0'); // 左边添加0
// 递归右边部分
Fenocode(p,index+1,end,fenocode+'1'); //右边添加1
}
double getSum(double p[] , int begin , int end){
double sum = 0;
for(int i = begin ; i <= end ; i++){
sum += p[i];
}
return sum;
}
先算出平均码字长度K=∑p(ai)*ki=2.1
可得编码效率为:H(X)/K*100%=95.6%。
二、哈夫曼编码介绍:哈夫曼编码为分组编码,完全依据各字符出现的概率来构造码字。基本原理是基于二叉树的编码思想,所有可能的输入符号在哈夫曼书上对应一个节点,节点的位置就是该符号的哈夫曼编码。为了构造出唯一可译码,这些节点都是哈夫曼书上的终极节点,不再延伸,不会出现前缀码。
哈夫曼编码步骤:
1、将信源消息符号按其出现的概率大小依次排列
2、取两个概率最小的字母分别配以 0 和 1 两码元, 并将这两个概率相加作为一个新字母的概率, 与未分配的二进 符号的字母重新排队。
3、对重排后的两个概率最小符号重复步骤(2)的过程。
4、不断继续上述过程,直到最后两个符号配以 0 和 1 为止
5、从最后一级开始,向前返回得到各个信源符号所对应的码元序列, 即相应的码字。
例子:
| 信源符号 | 概率P | 编码过程 | 编码 | |||
| A1 | 0.40 | 0.4 | 0.4 | 0.6(0 | 1.0 | 1 |
| A2 | 0.30 | 0.3 | 0.3(0 | 0.4(1 |
| 01 |
| A3 | 0.15 | 0.15(0 | 0.3(1 |
|
| 001 |
| A4 | 0.10(0 | 0.15(1 |
|
|
| 0000 |
| A5 | 0.05(1 |
|
|
|
| 0001
|
先算出平均码字长度K=∑p(ai)*ki=2.05%
可得编码效率为:H(X)/K*100%=97.9%。
三、香农编码:香农编码是一种构造最佳码长的编码方法。香农编码是是采用信源符号的累计概率分布函数来分配字码的。香农编码是根据香农第一定理直接得出的,指出了平均码长与信息之间的关系,同时也指出了可以通过编码使平均码长达到极限值。香农第一定理是将原始信源符号转化为新的码符号,使码符号尽量服从等概分布,从而每个码符号所携带的信息量达到最大,进而可以用尽量少的码符号传输信源信息。香农编码属于不等长编码,通常将经常出现的消息变成短码,不经常出现的消息编成长码,从而提高通信效率。
其编码方法如下:
(1) 将信源消息符号按其出现的概率大小依次排列为。
(2) 确定满足下列不等式的整数码长为:
Ki=⌈-logP(ai) ⌉(其中⌈ ⌉表示向上取整)
(3) 为了编成唯一可译码,计算第i个消息的累加概率。
(4) 将累加概率变换成二进制数。
(5) 取二进制数的小数点后位即为该消息符号的二进制码字。
例子:
| 信源消息符号 | 符号概率p() | 累加概率() |
| 码字长度 | 码字 |
|
| 0.40 | 0 | 1.32 | 2 | 00 |
|
| 0.30 | 0.40 | 1.73 | 2 | 01 |
|
| 0.15 | 0.70 | 2.73 | 3 | 101 |
|
| 0.10 | 0.85 | 3.32 | 4 | 1101 |
|
| 0.05 | 0.95 | 4.32 | 5 | 11110
|
算出平均码字长度K=∑p(ai)*ki=2.5
可得编码效率为:H(X)/K*100%=80.32%。
综上
1、若仅论编码效率而言,哈夫曼码>费诺码>香农码。
2、费诺码和哈夫曼编码的方法是不唯一的。
3、香农编码拓展性较好,有唯一的编码。依据编码定理编码,具有重要的理论意义。考虑了信源的统计特性,使经常出现的信源符号对应较短的码字,使平均码长缩短,实现了信源压缩。
费诺编码考虑了信源的统计特性,使概率较大的信源符号能对应码长较短的码字,提升了香农编码的效率。但是编码效率不一定最高,当信源符号较多时,有一些符号概率比较接近,使分组变多码长也随之增加,编码过程复杂,有时短码未必能得到充分利用。
哈夫曼编码是最佳的,它虽然有不同编码方式,但最终平均码长相等,不影响编码效率和数据的压缩性能。

















 992
992

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









