






一. 分享的几个点
redis 内存
redis延时队列原理
canal的安装与使用
连接池
Redis 内存
redis.conf 配置最大内存
#最大内存设置,100M
maxmemory 104857600查看redis内存信息 (info Memory)
172.29.2.11:7002> info Memory
# Memory
used_memory:2598042
used_memory_human:2.48M
used_memory_rss:3002368
used_memory_rss_human:2.86M
maxmemory:104857600
maxmemory_human:100.00M
mem_fragmentation_ratio:1.16
....
几个重要指标
used_memory
自身运行所占用的内存(如元数据、lua)
实际缓存数据占用的内存(包含虚拟内存)
不包含内存碎片
used_memory_rss
操作系统角度占用内存,不包括虚拟内存,其它都包括。
mem_fragmentation_ratio
used_memory_rss / used_memory , 越大,used_memory_rss 越大,碎片化越严重。
越小,used_memory 越大,使用虚拟内存越多,速度越慢。
内存碎片
如何产生的一个实验:
首先我配置maxmemory为100M ,然后写程序一直set key value 到 内存爆满后(注意是不同的key),直到程序抛出OOM异常:

然后我查看了下此时内存信息
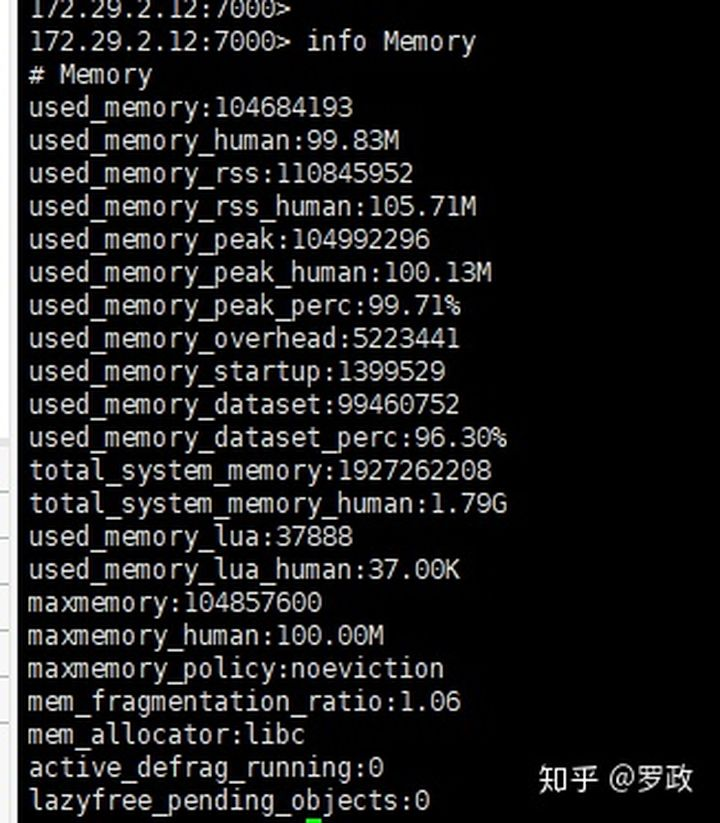
used_memory_rss和used_memory 都达到了100M,证明内存已经打满了。
但是我们的mem_fragmentation_ratio 还很正常,于是我执行了下flushdb,删除当前数据库所有key。
172.29.2.10:7000> flushdb
OK
172.29.2.10:7000> info Memory
# Memory
used_memory:2617096
used_memory_human:2.50M
used_memory_rss:112009216
used_memory_rss_human:106.82M
...
mem_fragmentation_ratio:42.80
然后惊奇的发现: used_memory被释放了,但是used_memory_rss 还是雷打不动。mem_fragmentation_ratio内存碎片比达到了42.8之多,碎片化很严重。
如果此时不清理掉碎片, 会导致redis重新设置大key时没法存放,还有可能导致RDB和AOF重写 开子进程分页写数据失败。
内存碎片产生原因
redis内存分配两个特性
按页分配: 比如申请220字节,内存分配器(jemalloc) 会分配256字节,如果还要继续写入20字节,Redis则不会继续向系统申请内存空间,直接写。
当数据修改, 删除后,并不立即将页内存返回给操作系统,下次数据来了直接还可以用,从而 减少Redis向系统申请内存分配的次数。
碎片产生的原因就是页内部分数据回收了,这个页还是占着空间。
虚拟内存
首先我们在redis.conf配置文件配置虚拟内存:
# #开启虚拟内存
vm-enabled yes
# #交换出来的value保存的文件路径
vm-swap-file /usr/local/app/redis-cluster/7002/redis.swap
# #redis使用的最大内存上限
vm-max-memory 134857600
然后启动居然报错了:
*** FATAL CONFIG FILE ERROR ***
Reading the configuration file, at line 26
>>> 'vm-enabled yes'
Bad directive or wrong number of arguments
最后发现,据说redis2.6后面的版本已经把虚拟内存配置去掉了。~~~
而是直接交给操作系统的swap了。
Redis OOM 后的几个策略
redis oom ( >maxmemory )后会报错
OOM command not allowed when used memory > ‘maxmemory’
1
Ruby
如果在set值,redis程序不处理的话,就会抱申请不了内存的未知异常,从而崩溃主进程。
但是redis 进行了处理,判断内存满了,就会进行下面策略
noeviction: 不淘汰现有key,直接返回异常,不再接受set key了。
allkeys-lru: 优先删除掉最近最不经常使用的key,用以保存新数据。
volatile-lru: 删除 最近不常使用的 且 设置了过期时间的key 。
allkeys-random: 随机从all-keys中选择一些key进行删除。
volatile-random: 只从设置失效(expire set)的key中,选择一些key进行删除。
volatile-ttl: 只从设置失效(expire set)的key中,选出存活时间(TTL)最短的key进行删除,用以保存新数据。
volatile-lru 是线上首选
Redis OOM 大 key 的排查
如果直接靠杨水发,那我们永远不知道怎么排查问题。
127.0.0.1:7001> info Keyspace
# Keyspace
db0:keys=37801,expires=22759,avg_ttl=35832230364keys 总key数:37801
expires 带过期的key : 22759
avg_ttl 平均过期时间
在使用 bigkeys 查看下内存占用最多的key
[root@localhost redis-cluster]# redis-cli -p 7001 --bigkeys
# Scanning the entire keyspace to find biggest keys as well as
# average sizes per key type. You can use -i 0.1 to sleep 0.1 sec
# per 100 SCAN commands (not usually needed).
[00.00%] Biggest string found so far '127.1761.661.1021' with 3931 bytes
[00.03%] Biggest string found so far '127.661.651.971' with 4372 bytes
[00.03%] Biggest string found so far '127.311.2361.61' with 4428 bytes
[00.03%] Biggest string found so far '127.801.2211.111' with 4676 bytes
[00.08%] Biggest string found so far '127.2471.801.2511' with 4918 bytes
[00.41%] Biggest string found so far '127.121.501.901' with 4945 bytes
[00.63%] Biggest string found so far '127.291.1181.2461' with 4980 bytes
[00.90%] Biggest string found so far '127.441.1481.2311' with 4998 bytes
[14.36%] Biggest string found so far '127.1251.1911.1921' with 4999 bytes
-------- summary -------
Sampled 37801 keys in the keyspace!
Total key length in bytes is 631318 (avg len 16.70)
Biggest string found '127.1251.1911.1921' has 4999 bytes
37801 strings with 94531257 bytes (100.00% of keys, avg size 2500.76)
0 lists with 0 items (00.00% of keys, avg size 0.00)
0 sets with 0 members (00.00% of keys, avg size 0.00)
0 hashs with 0 fields (00.00% of keys, avg size 0.00)
0 zsets with 0 members (00.00% of keys, avg size 0.00)
0 streams with 0 entries (00.00% of keys, avg size 0.00)
Ruby
如果确认key 无用,就用程序批量删除,可以通过scan命令遍历删除。
还有rdbtools 工具,可以导出RDB文件的大key , 结果图
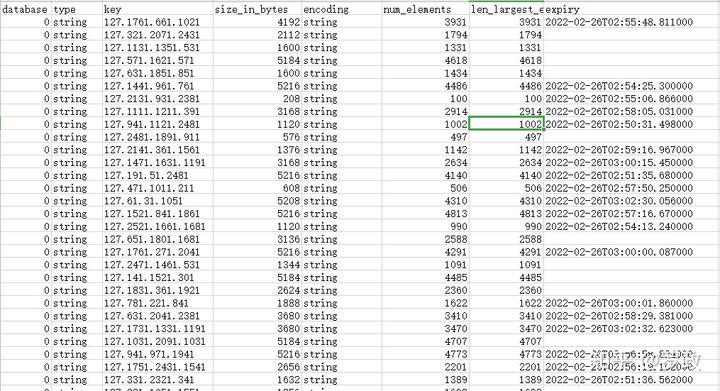
生成报表字段有:
database(key在redis的db)
type(key类型)
key(key值)
size_in_bytes(key的内存大小)
encoding(value的存储编码形式)
num_elements(key中的value的个数)
len_largest_element(key中的value的长度)
expiry (过期时间)
安装使用教程:https://zhuanlan.zhihu.com/p/342489203
Redis 内存优化案例
简单字符串优化
小于44
172.29.2.12:7000> set a 11111111222222333331212222233333333332333333
OK
172.29.2.12:7000> OBJECT encoding a
"embstr"
/// 大于44
172.29.2.12:7000> set a 111111112222223333312122222333333333323333333
OK
172.29.2.12:7000> OBJECT encoding a
"raw"Ruby
上面 设置a的value长度 <= 44 都是embstr编码。 大于44就是raw编码。
embstr编码 会比 raw 减少内存分配的次数。
因为redis是按页分配的,44以内加上额外的指针开销可能 就是一页内存, 大于44的话加上额外指针开销 可能大于一页内存了。
总结: 字符串值 尽量小于44
压缩链表的优化
看下redis默认压缩链表配置
172.29.2.12:7000> config get *ziplist*
1) "hash-max-ziplist-entries"
2) "512"
3) "hash-max-ziplist-value"
4) "64"
5) "list-max-ziplist-size"
6) "-2"
7) "zset-max-ziplist-entries"
8) "128"
9) "zset-max-ziplist-value"
10) "64"
-entries 数据项的个数 在512 之内就是压缩链表 算法。
-value 每个数据超过64字节 就不是压缩链表算法。
压缩列表的原理就是按照一定的编码规则存储在一块连续内存里,很节约内存,但是修改代价大,容易引起内存重新分配。
举个例子
172.29.2.12:7000> hset ad aa dddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddsssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssssaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa22222222222222222222222222222222222222222222222222222222222222222eeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeee
172.29.2.12:7000> OBJECT encoding ad
"hashtable"
hashtable 的一个数据项超过了64 , 转为了hashtable编码,也就是普通的hashmap算法,查找效率高,但内存消耗高。
实际案例
一个dev-id(设备id)对应 一个用户id(uid),格式如下:
dev-id:2379889 , uid:67567
我们现在有三亿个这样的不同的设备id需要存储,都是通过设备id来查找,如何通过redis实现?
传统的方式, 使用string:
set 2379889 67567
## 取值
get 2379889
我们计算下这样的key 到3亿后需要花多少内存
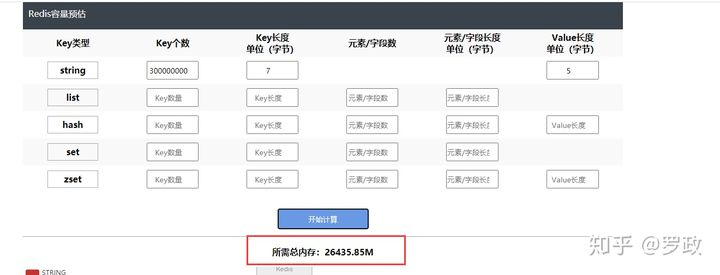
https://link.zhihu.com/?target=http%3A//www.redis.cn/redis_memory/
需要花26G内存 来存 这3亿条数据。
上面我们知道hash的ziplist 结构会压缩内存,于是我们可以想到以这种方式存储,我们以设备id的前4位作为hash的key ,于是这样存储:
>>hset 2379 889 67567
##hget时,把设备id分为2段: 2379 889
>>hget 2379 889由于是是前4位作为key,只留后3位不同,所以hash的个数最大就是999(0-999), 我们在改下配置
hash-max-ziplist-entries 1000
1
Plain Text
这样当我们hash里的个数没有超过1000时,就强制使用ziplist 。
测试后,内存使用量是5GB左右。注意一定要看编码是不是使用的ziplist。
那为什么是1000呢?因为前文已经提到过,如果数量太多会导致查询效率低下。于是取个良性的1000。
Redis的管道技术
适用场景: 批量的命令,命令之间不需要依赖结果。
redis 每执行一条命令,会经过 TCP 三次握手建立连接(没连接池),过程耗时比redis本身执行耗时多了,于是redis 提供了 可以将 一批命令打包到redis-server执行。耗时大大减少。
Redis实现延时队列
讲了,你自己也可以实现一个延时队列。
普通的想法
有一个 zset集合, 里面按时间搓来排序,然后 客户端 有个1s执行的定时器,来轮询 redis , 分页取出zset 。时间戳没到时间就 继续塞进去。
效率极差, 每秒执行一次,导致redis 就为你服务了。而且大部分时间都是没到时间的任务,空轮询。
java 的 Redisson 框架实现了一种延时队列
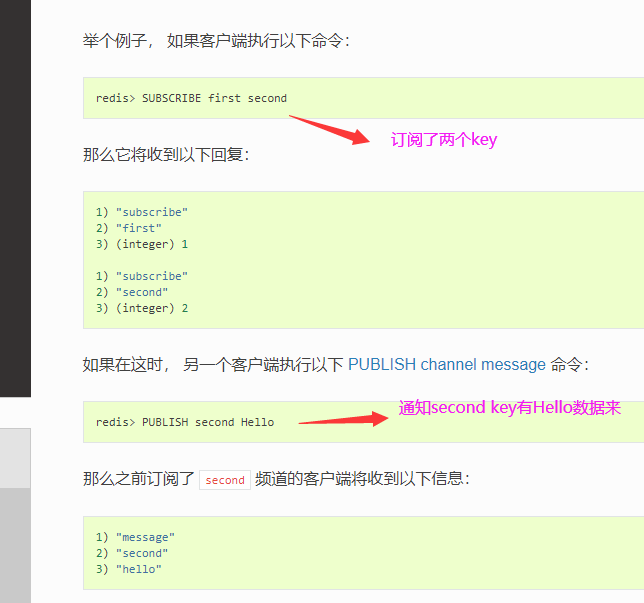
先讲几个命令的使用
SUBSCRIBE 订阅
zrangebyscore
zrangebyscore key min max [WITHSCORES] [LIMIT offset count]分页获取指定区间内(min - max),带有分数值(可选)的有序集成员的列表。1
2
Plain Text
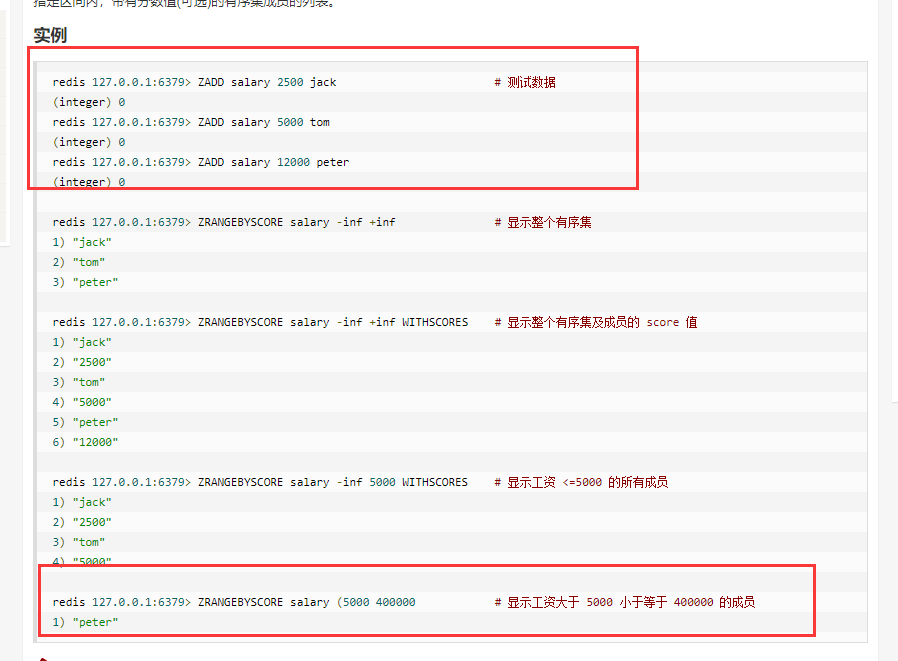
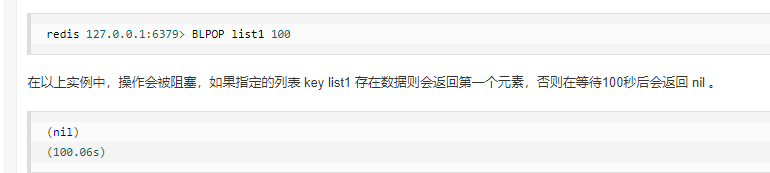
BLPOP
延时队列靠这几个命令来实现?
程序启动
客户端启动会 订阅一个key :redisson_delay_queue_channel
BLPOP dest_queue1 0 : 构建一个 无限阻塞 这个 key的list。
有延时任务 set 进来
计算出延时任务的时间戳。
zadd redisson_delay_queue_timeout 时间戳值
zrange key 0 0 取出最近一条要触发的数据,得到触发时间戳
然后 publish 程序启动时订阅的redisson_delay_queue_channel, 值为上面的时间戳 。
客户端执行,在进程内开启延时任务,延时时间为上面的时间。
进程延时任务执行
肯定是有到时间了的数据了, zrange 范围分页取出到了当前时间搓的数据。
将取出数据塞 rpush 到 dest_queue1 ,程序启动时阻塞的。
进程通过阻塞队列dest_queue1 收到数据消费。
将取完的数据从zset中移除
总结
不是通过轮询zset的,将延时任务执行放到进程里面实现,只有到时间才会取redis zset。防止空轮询。
Redisson的改进
线上发现直接用Redisson延时队列 有消息延时差不多十几分钟。
我不信! 于是我压测了单队列 Redisson情况:
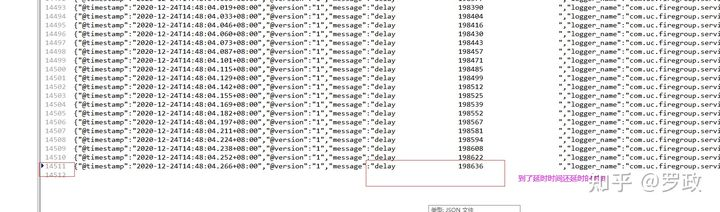
当我同时设置了14511条数据到redisson延时队列时,取出来的时间在本身的延时时间上还延时了198636多毫秒(3分钟),而且时间随着数据增加而增加。
这效率太差了。
于是我封装了下Redisson,改成了多队列,cluster模型,采用轮询的负载均衡模式。然后现在线上一直在用,没报延时的问题了,自己压测情况:
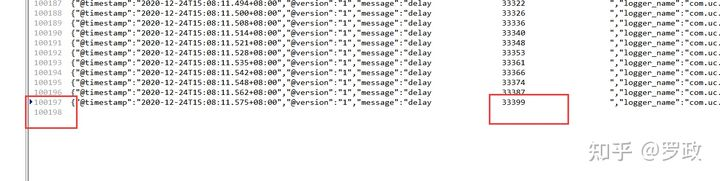
同时设置10万多条数据,真实延时时间最大33399毫秒(33秒)
canal使用
问题: 怎么保证数据库数据与redis数据同步?
canal就是为了解决 修改数据库数据后,自动同步到redis 的解决方案。 是阿里自己开发并使用的一套框架,稳定性不用说了。
简单原理
canal模拟mysql slave的交互协议,伪装自己为mysql slave,向mysql master发送dump协议
mysql master收到dump请求,开始推送binary log给slave(也就是canal)
canal解析binary log对象(原始为byte流)
线上使用就看这篇文章
Canal 详解 Mysql与Redis数据同步 解决方案
要保证数据库和redis强一致性是不可能的,肯定有少许时间的不一致。canal是阿里的一套组件,用来监听mysql master发送的类似binary log的数据,然后让消息费去消费。 Canal 简单原理canal模拟mysql slave的交互协…

https://zhuanlan.zhihu.com/p/346909055
Jedis连接池
maxTotal
控制连接池里面最多构建多少个Jedis实例
blockWhenExhausted
blockWhenExhausted为true时,上面拿不到jedis实例后,线程阻塞。 blockWhenExhausted为false时,上面拿不到jedis实例后,线程不阻塞,而是抛出异常。
maxIdle , minIdle
maxIdle实际上才是业务需要的最大连接数,maxTotal 是为了给出余量,所以 maxIdle 不要设置得过小,否则会有new jedis(新连接)开销。
例子:
maxTotal=5 , maxIdle=3 , 当maxTotal开满后,主动调用colse所有的连接,实际关闭tcp的只有2个,3个会保活一阵时间,时间到后也会断开tcp,也不是全部断开,断开的保持minIdle连接。
timeBetweenEvictionRunsMillis,minEvictableIdleTimeMillis
保活的时间配置,分以下两步:
timeBetweenEvictionRunsMillis: 空闲资源的检测周期(单位为毫秒)。
minEvictableIdleTimeMillis : 资源池中资源的最小空闲时间(单位为毫秒),达到此值后空闲资源将被移除。
三. 连接池配置建议
建议 maxTotal = maxIdle
这样就避免了连接池伸缩带来的性能干扰。如果您的业务存在突峰访问,建议设置这两个参数的值相等;如果并发量不大或者maxIdle设置过高,则会导致不必要的连接资源浪费。
怎么设置maxTotal的值
假如一个redis命令请求到执行需要花1ms,那么一个tcp的QPS就是1*1000。 如果你配置了maxTotal =50 , 也就是同时最大50个tcp连接,那么你服务的总QPS就是1000*50 = 50000。实际上线上服务都是集群的,所以还要乘以你的机器数。
但是 redis 也有最大的连接限制,所以不建议maxTotal很大
















 1148
1148











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









