






Multimodal Large Language Models: A Survey
论文链接:https://arxiv.org/pdf/2311.13165
目录
3. PRACTICAL GUIDE FOR TECHNICAL POINTS
4. PRACTICAL GUIDE FOR ALGORITHMS
5. PRACTICAL GUIDE FOR VARIOUS TASKS
文章要点:
1. 多模态模型的核心定义与发展历程
- 定义:多模态指通过整合不同模态数据(如图像、文本、音频)表达复杂信息,应用于情感分析、机器翻译、生物医学等领域。
- 发展阶段:
- 单一模态研究:早期聚焦独立模态(如语音识别、图像统计模式)。
- 模态转换阶段(2000-2010):研究人机交互,计算机模拟人类行为,代表性项目包括:
- AMI项目(2001):记录和处理会议数据。
- CALO项目(2003):开发聊天机器人技术(Siri前身)。
- SSP项目(2008):提出社会信号处理网络。
- 多模态融合阶段:结合视觉、语言等模态的联合建模。
- 大规模预训练阶段:基于自监督学习的跨模态统一表示。
2. 技术要点与模型架构
- 关键技术:
- 知识表示:图像标记化分为基于区域、网格、补丁三种方法。
- 学习目标:多任务预训练结合图像-文本对比(ITC)、掩码语言建模(MLM)、掩码视觉建模(MVM)等目标,提升模型泛化能力。
- 信息融合:采用融合编码器(推理任务)或双编码器(检索任务)架构。
- 提示方法(Prompting):缩小预训练与下游任务差距,应用于视觉ChatGPT、CLIP等模型。
- 模型创新:
- KOSMOS-1:整合语言与感知能力,支持视觉对话、图像描述、零样本分类。
- PaLM-E:结合语言与视觉模型,在物体检测、代码生成等任务中实现零样本SOTA。
- BEiT:将掩码语言模型(MLM)扩展至视觉领域,实现图像自监督预训练。
3. 应用与扩展能力
- 任务场景:
- 推理与检索:融合编码器处理复杂推理,双编码器优化检索效率。
- 跨模态生成:如视觉ChatGPT通过注入视觉信息增强语言模型的图像理解与生成。
- 模态扩展:支持语言、图像,未来可扩展至视频、语音,避免重复训练新模型。
4. 挑战与未来方向
- 技术挑战:
- 视觉特征嵌入复杂度高,需平衡计算效率与表征能力。
- 多任务学习目标需避免冲突,优化组合策略。
- 未来方向:
- 开发更灵活的多模态统一架构。
- 探索小样本/零样本学习下的泛化能力。
- 推动生物医学等垂直领域的应用。
5. 总结
论文系统梳理了多模态大模型的技术演进,强调其通过跨模态融合与自监督学习实现通用性提升,同时指出需解决模态对齐、计算效率等核心问题,为未来研究提供理论框架与实践指南。
论文精读:
论文结构:
- INTRODUCTION
- RELATED CONCEPTS
- PRACTICAL GUIDE FOR TECHNICAL POINTS
- PRACTICAL GUIDE FOR ALGORITHMS
- PRACTICAL GUIDE FOR VARIOUS TASKS
- CHALLENGES
- CONCLUSION
1. INTRODUCTION
系统阐述了多模态大模型的核心概念、优势、应用潜力及研究现状,重点对比了传统纯文本大模型(如GPT-3、BERT)与多模态模型(如GPT-4)的差异,强调多模态模型在跨模态理解与任务泛化上的突破,并指出当前研究的不足。作者旨在通过本文填补现有综述对多模态模型发展历程、技术细节及实际应用分析的空白。
a. 要点总结
- 多模态模型的核心价值
- 定义:整合图像、文本、音频等多模态数据,突破传统纯文本大模型(LLMs)的局限性。
- 优势:
- 支持跨模态任务(如视觉推理、多模态生成),在常识推理中性能优于单模态模型。
- 为通用人工智能(AGI)提供基础,增强与现实世界的交互能力。
- 代表模型:GPT-4(支持图文输入,接近人类表现)、多模态机器人技术等。
- 与传统LLM的对比
- 传统LLM局限:仅基于文本训练,缺乏视觉、听觉等模态的感知能力。
- 多模态LLM突破:通过跨模态数据融合,扩展至高价值领域(如文档智能、机器人控制)。
- 应用潜力
- 场景:人机交互、图像搜索、语音生成、多模态机器人等。
- 实验验证:跨模态迁移提升知识获取效率,模型在新任务中表现更优。
- 研究现状与不足
- 现有综述局限:
- 聚焦单一模态应用(如Summaira等人)或算法/数据集汇总(如Wang等人),缺乏对发展历程和实际应用的系统分析。
- 未深入探讨技术实现(如知识表示、提示方法)与垂直领域挑战。
- 研究难点:LLM能力向多模态迁移仍需突破(如视觉信号感知)。
- 现有综述局限:
- 本文的贡献
- 系统性框架:从多模态定义、历史发展、技术要点(知识表示、学习目标、模型架构)到应用挑战全面梳理。
- 资源整合:总结最新算法、常用数据库,为未来研究提供基准。
- 实践指导:探讨技术实现(如信息融合、提示方法)与领域应用(如生物医学),指明未来方向(如小样本学习)。
b. 核心结论
多模态大模型通过跨模态融合显著提升了AI的泛化能力,但其发展需解决模态对齐、计算效率等技术挑战,并需在垂直领域探索更落地的应用场景。本文为后续研究提供了理论框架与实用指南。
2. RELATED CONCEPTS
系统阐述了多模态学习的核心分类、定义及技术演进历程,通过划分四个发展阶段(单一模态→模态转换→模态融合→大规模多模态),结合代表性技术、模型与应用案例,揭示了多模态研究从基础计算到跨模态统一建模的进化路径,并强调其在提升AI感知与交互能力中的核心作用。
a. 多模态的核心分类与定义
- 模态类型:
- 同质模态:同类数据(如不同相机拍摄的图像)。
- 异质模态:跨类型数据(如图像与文本)。
- 多模态数据的内涵:
- 语义感知视角:整合视觉、听觉、触觉等多感官信息,形成对环境的统一理解。
- 数据视角:涵盖图像、文本、音频、时间序列等异构数据,甚至复杂结构(图、树、数据库)。
- 研究价值:
- 提供更全面的信息表征,推动情感分析、机器翻译、生物医学等领域的突破。
b. 多模态研究的四个发展阶段
- 单一模态阶段(1980-2000)
- 技术特点:依赖统计方法与基础计算能力。
- 关键成果:
- 人脸识别:特征脸方法(PCA)、统计模式分析。
- 语音识别:隐马尔可夫模型(HMM)提升准确性。
- 模态转换阶段(2000-2010)
- 目标:模拟人类行为,增强人机交互。
- 标志性项目:
- AMI项目(2001):会议多模态数据(音频、视频、文本)处理。
- CALO项目(2003):开发智能虚拟助手(Siri前身)。
- SSP项目(2008):分析非语言社交信号(表情、手势)。
- 模态融合阶段(2010-2020)
- 技术驱动力:深度学习与神经网络结合。
- 突破性技术:
- 多模态深度学习算法(Ngiam, 2011):联合学习图像、文本特征。
- 深度玻尔兹曼机(DBM, 2012):建模跨模态依赖关系。
- 语义注意力机制(2016):图像自动描述生成(如视障辅助技术)。
- 大规模多模态阶段(2020至今)
- 技术特征:自监督学习、跨模态统一建模。
- 代表性模型:
- CLIP(2021):无监督图像-文本相似度预测。
- DALL-E 2(2022):基于扩散模型的文本到图像生成。
- KOSMOS-1(2023):整合语言与感知能力,支持视觉对话、零样本分类。
- PaLM-E(2023):语言与视觉模型结合,实现零样本SOTA性能。
c. 技术演进的核心趋势
- 从孤立到协同:早期单一模态分析 → 跨模态交互与融合 → 大规模统一建模。
- 从监督到自监督:依赖标注数据 → 利用无监督学习(如CLIP的图像-文本对)。
- 应用扩展:基础识别任务 → 复杂生成与推理(图像描述、代码生成、机器人控制)。
d. 当前研究的意义与挑战
- 意义:
- 推动通用人工智能(AGI)发展,增强机器对现实世界的理解与交互能力。
- 拓展高价值场景应用(如多模态机器人、自动化医疗诊断)。
- 挑战:
- 模态对齐的复杂性(如文本与视觉语义一致性)。
- 计算效率与模型规模的平衡。
e. 核心结论
多模态学习通过整合异构数据与跨模态技术,实现了AI从单一感知到综合智能的跨越。技术演进以模型规模扩大与自监督学习为核心,未来需进一步解决模态协同效率与落地应用难题,为通用人工智能奠定基础。
3. PRACTICAL GUIDE FOR TECHNICAL POINTS
a. 知识表示
- 文本处理
- 分词方法:Word2Vec(CBOW/Skip-gram)、字节对编码(BPE)
- 嵌入表示:生成可计算的分词向量(如BERT应用)
- 局限性:词汇量限制,需子词分词优化
- 图像处理
- 标记化方法:
- 基于region:预训练目标检测器提取特征
- 基于grid:CNN直接提取网格特征
- 基于patch:图像分块后线性投影(如ViT)
- 视觉特征重要性:METER实验表明视觉特征优化对结果影响远大于文本
- 标记化方法:
b. 学习目标选择
- 核心任务类型
- 图像-文本对比(ITC):对齐跨模态表示
- 掩码语言建模(MLM)与掩码视觉建模(MVM):联合推理语言与视觉线索
- 图像-文本匹配(TM):二分类判断模态匹配性
- 组合策略
- 多目标组合提升性能(如UNITER结合MLM+ITC)
- 目标数量需平衡:过多目标可能降低效果(METER实验验证)
c. 模型结构构建
- 架构类型
- 仅编码器型(如CLIP、ALBEF):
- 适用检索任务(图像-文本匹配)
- 不适合生成任务
- 编码器-解码器型(如T5、SimVLM):
- 自回归生成输出序列
- 擅长图像描述等生成任务
- 仅编码器型(如CLIP、ALBEF):
- 设计原则
- 任务导向选择架构(检索 vs 生成)
d. 信息融合
- 融合方法分类
- 融合编码器:
- 单流方法:直接拼接模态后自注意力(假设简单对齐)
- 双流方法:分别建模模态内/跨模态交互(交叉注意力)
- 适用场景:复杂推理任务(如VQA)
- 双编码器:
- 独立编码模态,浅层计算相似度(点积/注意力)
- 适用场景:高效检索任务
- 融合编码器:
- 创新方案
- 混合架构:VLMO的"三专家"模式(处理单模态/多模态数据)
e. 提示词使用
- 核心作用
- 缩小预训练与下游任务差距
- 降低微调成本,提升零样本/小样本性能
- 应用案例
- CLIP:文本提示增强零样本分类
- Visual ChatGPT:提示管理器生成图像理解指令
f. 技术演进关键环节
- 视觉特征主导性:视觉优化对性能提升权重显著高于文本(METER结论)
- 目标组合平衡:UNITER多目标有效性 vs METER过度目标负面影响
- 架构-任务匹配:编码器型(检索) vs 编码器-解码器型(生成)
- 融合效率权衡:融合编码器(精度) vs 双编码器(速度)
- 提示工程价值:跨模态场景下零样本能力突破的关键
g. 总结
多模态大模型技术围绕跨模态对齐与任务适配展开,核心需解决:
- 异构数据的高效表示(文本分词 vs 图像分块)
- 多目标联合优化的平衡策略
- 架构设计与任务需求的精准匹配
- 推理效率与计算成本的动态平衡
- 预训练-微调间隙的提示词桥接
4. PRACTICAL GUIDE FOR ALGORITHMS
作者系统梳理了多模态算法领域的两大核心类别——基础模型与大规模多模态预训练模型,重点阐述其技术原理、创新点及在多模态任务中的应用。通过具体模型案例,揭示了多模态算法从基础框架到实际应用的发展脉络,并探讨了当前技术面临的挑战与未来方向。
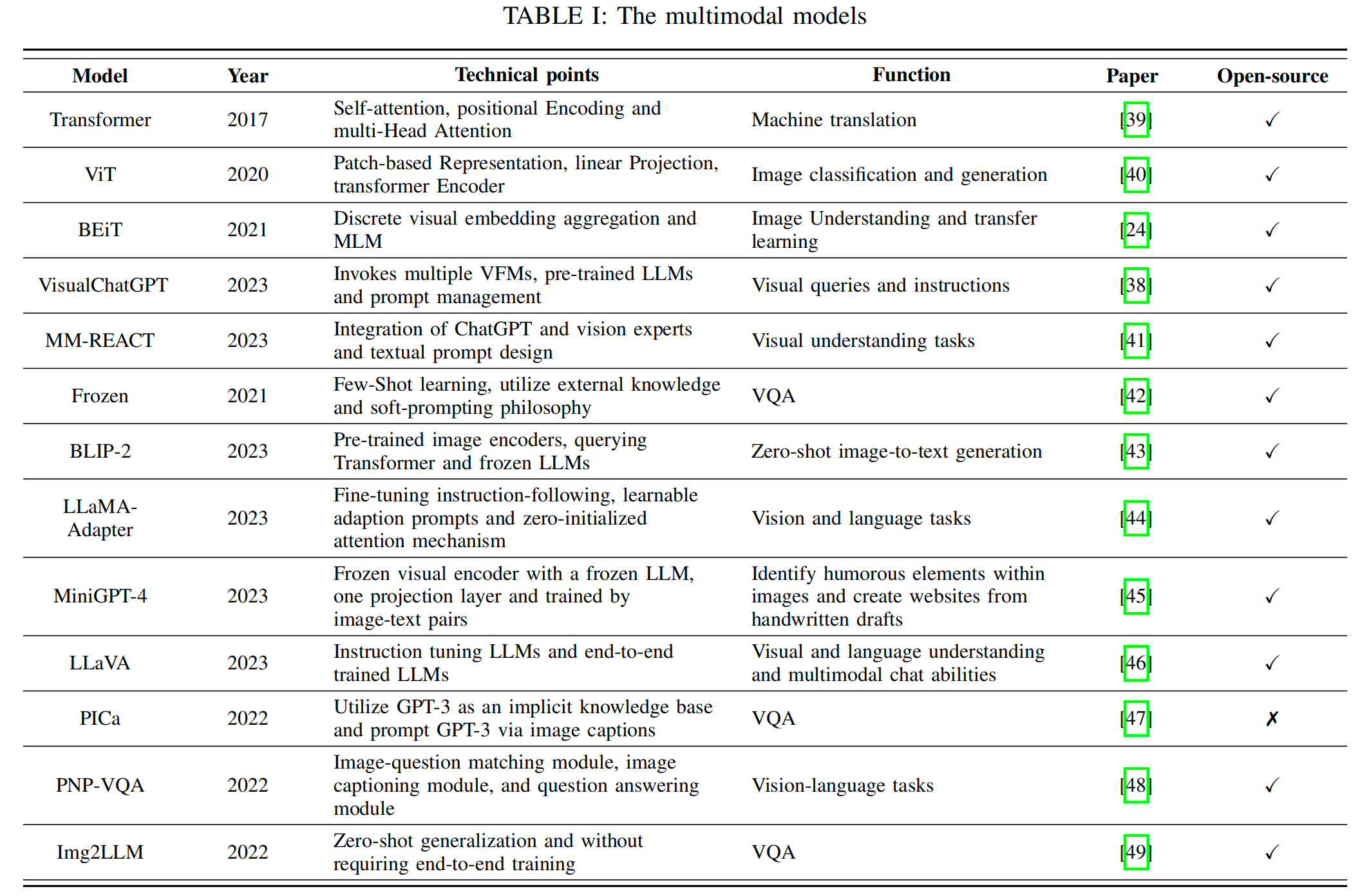
a. 基础模型
- Transformer
- 核心特性:自注意力机制、权重共享(与输入序列长度无关),支持跨模态参数迁移(如图像与文本权重共享)。
- 应用价值:奠定多模态模型基础,支持大规模自监督预训练与下游任务微调。
- ViT(视觉Transformer)
- 创新点:将图像分割为patch(如16块),通过线性映射适配Transformer输入,突破传统CNN限制。
- 意义:架起计算机视觉与自然语言处理的桥梁,实现高效图像特征提取。
- BEiT
- 核心贡献:将生成式预训练(如BERT的MLM)引入视觉领域,解决图像离散化表示与预训练融合问题。
- 方法:采用离散视觉嵌入聚合和ViT结构,结合掩码图像建模(MIM)实现自监督预训练。
b. 大规模多模态预训练模型
- 通用设计思路
- 模态融合:通过视觉编码器(如Qformer)、提示管理器等工具对齐多模态特征(如图像+文本)。
- 参数效率:冻结部分模块(如视觉编码器、LLM),仅微调关键组件(如适配器、线性层)。
- 迭代优化:多阶段训练(如BLIP-2的两阶段策略)、上下文学习(如Frozen的嵌入拼接)。
- 代表性模型
- 视觉版ChatGPT:整合视觉基础模型(VFMs),支持复杂跨模态交互(如多步骤图像问答)。
- BLIP-2:利用Qformer提取图像特征,通过对比学习与文本生成任务实现高效跨模态对齐。
- LLaMA-Adapter:插入可训练适配器,扩展至多模态场景,保留语言模型能力的同时适应视觉输入。
- MiniGPT-4/LLaVA:基于BLIP-2改进,通过两阶段微调(生成描述+高质量数据优化)提升多模态指令理解。
- 视觉问答(VQA)专项优化
- PICa:依赖图像描述模型,但面临视觉信息丢失问题。
- PNP-VQA:引入图像-问题匹配模块,筛选相关图像补丁生成描述,提升答案相关性。
- Img2LLM:通过(问题-答案)对传递视觉信息,解决模态与任务脱节问题。
c. 挑战与趋势
- 技术挑战
- 模态对齐:视觉与语言特征的空间差异(如Frozen的嵌入拼接需进一步优化)。
- 信息保留:图像转文本过程中的细节丢失(如PICa性能受限)。
- 计算成本:大规模预训练对资源的依赖(如ViT依赖谷歌算力)。
- 发展方向
- 通用性扩展:支持视频、语音等多模态输入(如视觉版ChatGPT的潜力)。
- 轻量化设计:参数高效微调(如MiniGPT-4仅15M可调参数)。
- 自监督学习:探索更鲁棒的生成式预训练方法(如BEiT的MIM范式)。
多模态算法以基础模型为框架,通过大规模预训练模型实现跨模态任务落地,核心在于模态融合与参数效率优化。未来需突破信息对齐与计算瓶颈,向通用性、轻量化及自监督学习方向演进。
5. PRACTICAL GUIDE FOR VARIOUS TASKS
作者系统阐述了多模态技术在不同实际任务中的应用场景、技术方法及社会价值,涵盖图像描述、文本到图像生成、手语识别、情感识别、视频处理、数字人开发等核心领域。通过具体案例与数据集说明,揭示了多模态技术如何通过跨模态融合解决复杂问题,并推动人机交互、创意产业与无障碍服务的发展。
a. 核心多模态任务
- 图像描述
- 目标:将图像内容转化为简短文本描述,辅助视障用户理解视觉信息。
- 技术挑战:需检测图像中的对象、动作、特征及关系,应对开放式翻译的主观性。
- 应用价值:提供图像文字替代方案,增强无障碍服务(如盲人感知图像内容)。
- 文本到图像生成
- 代表性模型:DALL-E 2、Imagen,支持通过文本提示生成高质量图像或视频。
- 应用场景:照片编辑、数字艺术创作、创意产业创新(如文本直接转视觉内容)。
- 扩展方向:文本到视频生成技术崭露头角,拓展动态内容创作能力。
- 手语识别
- 技术核心:对齐视觉(视频帧)与音频(波形)的时序信息,识别手势对应口语。
- 数据集:RWTH PHOENIX Weather 2014T(德语手语视频+音频)。
- 难点:跨模态时间同步与手势-语音精准映射。
- 情感识别
- 多模态输入:视频、文本、音频、脑电波数据等,提升识别准确性。
- 应用案例:音乐情感识别(结合音频特征与歌词),采用后期融合策略整合预测结果。
- 数据集:DEAM(含2000+歌曲的音频特征与歌词)。
- 视频处理
- 技术迁移:图像-文本模型(如CLIP)扩展至视频-文本(VideoCLIP)、音频-文本(MusicLM)。
- 任务类型:视频问答、视频字幕生成、视听语音识别、声源分离、语音驱动3D面部动画等。
- 代表模型:阿里的mPLUG-2(视频任务)、谷歌的MusicLM(文本生成音乐)。
- 智能数字人
- 技术支撑:AIGC技术整合自然语言生成(交互内容)与计算机视觉(表情/动作合成)。
- 产品案例:NVIDIA Omniverse Avatar(通过照片/视频/音频快速创建3D数字人)。
- 核心能力:唇形同步、多模态感知与决策,推动高拟真人机交互。
b. 多模态数据的关键作用
- 数据集类型
- 涵盖图像、文本、视频、音频等多模态信息,支持多样化任务训练与验证。
- 示例:RWTH PHOENIX(手语)、DEAM(音乐情感)、COCO(图像描述)等。
- 研究价值
- 为模型有效性测试提供基准,推动跨模态对齐、特征融合等技术创新。
c. 技术挑战与发展方向
- 核心挑战
- 模态对齐:时序同步(如手语识别)、空间特征匹配(如视频-文本)。
- 信息损失:图像转文本的细节丢失、语音驱动动画的真实性限制。
- 计算复杂度:视频/音频多模态处理对算力的高需求。
- 未来趋势
- 动态内容生成:文本到视频、语音到3D动画等技术的深化应用。
- 通用性提升:统一多模态大模型(如mPLUG-2)向多任务适配扩展。
- 人机交互升级:数字人拟真度与多模态交互流畅性优化。
多模态技术通过跨模态融合与多样化任务适配,在图像理解、内容生成、无障碍服务、人机交互等领域实现突破。其发展依赖高质量数据集支撑与算法创新,未来需进一步解决模态对齐、计算效率等挑战,推动更智能、普适的应用落地。
6. CHALLENGES
这一部分聚焦多模态应用性能提升的四大核心挑战——模态扩展、计算效率、持续学习与通用人工智能实现路径,系统剖析了当前技术瓶颈与创新方向。通过跨领域案例(如医疗、情感计算)与前沿模型(如BLIP-2、KOSMOS-1)说明,提出构建更鲁棒、高效、普适的多模态系统的关键策略,并揭示其与通用人工智能(AGI)发展的深度关联。
a. 模态扩展挑战
- 跨领域应用需求
- 情感计算:融合音频(语调/语速)、视觉(表情/肢体)、生理信号(ECG/EEG)实现情绪精准识别。
- 医学成像:整合CT(结构细节)、MRI(解剖功能)、PET(代谢标志物)提升诊断全面性。
- 核心价值
- 多模态数据互补增强分析准确性(如医疗影像多模态融合支持精准诊疗)。
- 拓展信息感知维度(如生理信号补充传统视听模态)。
b. 耗时问题优化
- 主要瓶颈
- 计算规模:大型模型依赖分布式集群训练,多租户场景资源调度复杂。
- 可靠性要求:需动态容错与多模型组合能力。
- 解决方向
- 动态资源调度:通过组调度实现跨数据中心模型动态分配,共享计算/权重。
- 架构创新:采用动态路由技术优化训练效率(如高速互联架构支持共享计算)。
c. 终⾝/持续学习机制
- 传统方法局限
- 孤立学习:模型缺乏记忆能力,无法积累知识持续优化。
- 技术突破路径
- 持续学习框架:构建具备经验积累能力的模型,支持自主渐进式改进。
- 应用场景:多模态大模型需适应动态环境(如机器人任务持续演化)。
d. 迈向通用人工智能(AGI)
- 核心障碍
- 灾难性遗忘:模型跨任务迁移时丢失原有能力(如语言模型转向机器人任务导致性能下降)。
- 解决方案
- 模型架构设计:
- 小规模网络重新训练(避免历史任务干扰)。
- 大规模语言网络作骨干(如BLIP-2、KOSMOS-1保留核心能力)。
- 模型架构设计:
- 长期挑战
- 多模态融合:跨模态特征对齐与协同学习。
- 服务化部署:模型即服务(MaaS)生态构建与动态适配。
多模态性能提升需突破模态局限、计算效率、学习范式与通用性瓶颈四大关卡,核心策略包括:
- 模态维度扩展(跨传感器数据融合)
- 动态资源调度(分布式计算优化)
- 持续学习框架(知识积累与迁移)
- AGI兼容架构(抗遗忘模型设计)
未来技术演进将推动多模态系统向更智能(自主决策)、更高效(低资源消耗)、更普适(跨任务泛化)方向发展,为AGI实现奠定基础。
7. CONCLUSION
多模态模型的发展为⼈⼯智能开辟了新的途径,使⼆进制机器能够理解并处理多种类型的数据。在不久的将来,多模态模型将带来更全⾯、更智能的系统。⾸先介绍了多 模态的概念,然后梳理了多模态算法的历史发展。之后,讨论了主要科技公司在开发多模态产品⽅⾯所做的努⼒,并对多模态模型的技术⽅⾯进⾏了分析。还汇总了⼀些常⽤的多模态数据集,这些数据集可为实验和评估提供宝贵的资源。最后,我们强调并讨论了多模态模型开发所⾯临的挑战,以供进⼀步研究。通过探讨这些⽅⾯,本⽂旨在更深⼊地理解多模态模型及其在各个领域的潜在特性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









