







打波广告勒,女朋友的淘宝店:https://item.taobao.com/item.htm?spm=a2oq0.12575281.0.0.25911deb2q0w5S&ft=t&id=591621534947
欢迎大家进店收藏关注观看哦,如需本文的资料及资源,也可以淘宝旺旺问我拿哦。
代码资源
Faster_r_cnn代码链接: https://pan.baidu.com/s/1eS8JcIY 密码: mqrh
论文作者源码下载:git clone –recursive https://github.com/rbgirshick/py-faster-rcnn.git
配置,编译与安装环境
1:在本机已经配置好了caffe环境以及各种依赖的安装,还要配置以下几个python包:cython,easydict和python-opencv,安装命令如下:
$ pip install cython
$ pip install easydict
$ sudo apt-get install python-opencv
2:Cython模块编译
$ cd $FRCN_ROOT/lib
$ make
3:caffe和pycaffe的编译
在编译之前,需要复制$FRCN_ROOT/caffe-fast-rcnn 的Makefile.config.example,然后重命名为Makefile.config。
需要注意的是里面有几个配置需要添加
打开USE_CUDNN=1,这个选项默认情况下是关闭的,需要打开让CUDA支持DNN
打开WITH_PYTHON_LAYER=1,默认关闭,需打开,因为FasterRCNN需要支持Python接口。
INCLUDE_DIRS := $(PYTHON_INCLUDE) /usr/local/include后面打上一个空格 然后添加/usr/include/hdf5/serial如果没有这一句可能会报一个找不到hdf5.h的错误
4:执行以下命令进行编译
make all -j4
make过程中出现找不到lhdf5_hl和lhdf5的错误,
解决方案:
在计算机中搜索libhdf5_serial.so.10.1.0,找到后右键点击打开项目位置
该目录下空白处右键点击在终端打开,打开新终端输入
sudo ln libhdf5_serial.so.10.1.0 libhdf5.so
sudo ln libhdf5_serial_hl.so.10.0.2 libhdf5_hl.so
最后在终端输入sudo ldconfig使链接生效
原终端中输入make clean清除第一次编译结果
再次输入make all -j4重新编译
终端输入
make test -j4
make runtest -j4
make pycaffe -j4
make distribute 生成发布安装包
运行demo
1:下载训练好的模型,下载好的模型在$FRCN_ROOT/data下面
$ cd $FRCN_ROOT
$ ./data/scripts/fetch_faster_rcnn_models.sh
faster_rcnn模型链接: https://pan.baidu.com/s/1miDWCEc 密码: xq4y
2:运行模型
$ cd $FRCN_ROOT
$ ./tools/demo.py
结果如下:

训练自己的数据集
1.工程目录介绍
- caffe-fast-rcnn:caffe框架目录
- data:用来存放pretrained模型以及读取文件的cache缓存,还有一些下载模型的脚本
- experiments:存放配置文件以及运行的log文件,另外这个目录下有scripts,里面存放end2end和all_opt两种训练方式的脚本
- lib: 用来存放一些python的接口文件,如darasets主要负责数据库的读取,config负责一些训练的配置选项
- models:里面存放了三个模型文件,小型网络ZF,中型网络VGG_CNN_M_1024以及大型网络VGG16,根据你的硬件条件来选择使用哪种网络,ZF和VGG_CNN_M_1024需要至少3G内存,VGG16需要更多的内存,但不会超过11G。
- outputs:这里存放的是训练后的输出目录,这是运行训练后才会出现的目录
- tools:里面存放的训练和测试python文件
2.创建数据集
仿照VOC2007数据集的格式来准备
具体参考我的这篇博客:http://blog.csdn.net/Lin_xiaoyi/article/details/78180705
生成好之后把所有的xml放到VOC2007下的Annotation中,可参考如下linux命令:
for xml in *.xml;do mv $xml Annotations/;done
1.将所有的训练图片都放入JPEGImages文件夹中,
生成ImageSet\Main里的四个txt文件,分别是:trainval.txt(训练和验证集总和)、train.txt(训练集)、val.txt(验证集)、test.txt(测试集),trainval集占整个数据集的70%,train集占trainval集的70%,val集占trainval集的30%,test集占整个数据集的30%。可参考以下代码进行数据集的划分:
%%
%该代码根据已生成的xml,制作VOC2007数据集中的trainval.txt;train.txt;test.txt和val.txt
%trainval占总数据集的70%,test占总数据集的30%;train占trainval的70%,val占trainval的30%;
%上面所占百分比可根据自己的数据集修改
%注意修改下面两个路径
xmlfilepath='/home/linbiyuan/py-faster-rcnn/data/VOCdevkit2007/VOC2007/Annotations';
txtsavepath='/home/linbiyuan/py-faster-rcnn/data/VOCdevkit2007/VOC2007/ImageSets/Main/';
xmlfile=dir(xmlfilepath);
numOfxml=length(xmlfile)-2;%减去.和.. 总的数据集大小
trainval=sort(randperm(numOfxml,floor(numOfxml*0.7)));%trainval为数据集的50%
test=sort(setdiff(1:numOfxml,trainval));%test为剩余50%
trainvalsize=length(trainval);%trainval的大小
train=sort(trainval(randperm(trainvalsize,floor(trainvalsize*0.7))));
val=sort(setdiff(trainval,train));
ftrainval=fopen([txtsavepath 'trainval.txt'],'w');
ftest=fopen([txtsavepath 'test.txt'],'w');
ftrain=fopen([txtsavepath 'train.txt'],'w');
fval=fopen([txtsavepath 'val.txt'],'w');
for i=1:numOfxml
if ismember(i,trainval)
fprintf(ftrainval,'%s\n',xmlfile(i+2).name(1:end-4));
if ismember(i,train)
fprintf(ftrain,'%s\n',xmlfile(i+2).name(1:end-4));
else
fprintf(fval,'%s\n',xmlfile(i+2).name(1:end-4));
end
else
fprintf(ftest,'%s\n',xmlfile(i+2).name(1:end-4));
end
end
fclose(ftrainval);
fclose(ftrain);
fclose(fval);
fclose(ftest);
至此,数据集的构建就完成啦,你可以新建一个文件夹,将上述三个文件夹放到里面去,也可将上述三个文件夹分贝替换VOC2007数据集中的Annotations、ImageSets和JPEGImages,这样可免去一些训练的修改。本文选择的是替换~
把数据集放到./data文件夹下
3.训练自己的数据集
1.修改prototxt配置文件
这些配置文件都在models下的pascal_voc下。里面有三种网络结构:ZF, VGG16, VGG_CNN_M_1024,本文选择的是VGG_CNN_M_1024。每个网络结构中都有三个文件夹,分别是faster_rcnn_end2end , faster_rcnn_alt_opt , fast_rcnn 。使用近似联合训练faster_rcnn_end2end ,比交替优化快1.5倍,但是准确率差不多,所以推荐使用这种方法。更改faster_rcnn_end2end文件夹的train.prototxt和test.prototxt,train中需要改的地方有三处,
第一处是input-data层,将原来的21改成:你的实际类别数+1(背景),我目标检测一共有46类,所以加上背景这一类,一共47类。
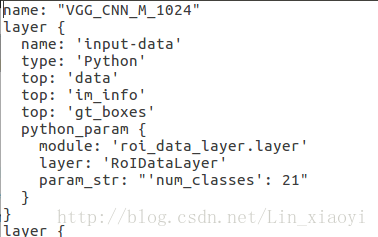
第二处是cls_score层,将原来的21改成:你的实际类别数+1(背景),我目标检测一共有46类,所以加上背景这一类,一共47类。
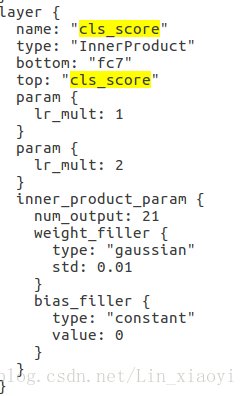
第三处是bbox_pred,这里需将原来的84改成(你的类别数+1)×4,即(46+1)×4=188

**
test.prototxt中没有input-data层,所以只需要按照train中修改cls_score层以及bbox_pred层即可
**
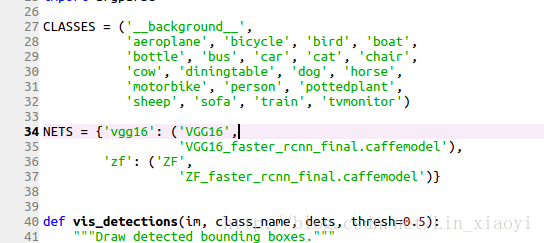
2.修改lib/datasets/pascal_voc.py,将类别改成自己的类别
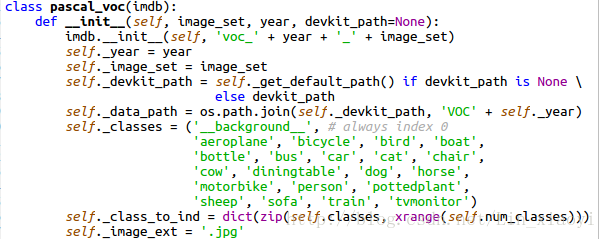
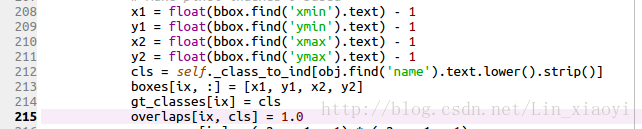
这里有一个注意点就是,这里的类别以及你之前的类别名称最好是全部小写,假如是大写的话,则会报keyError的错误,这时只需要在pascal_voc。py中第212行的lower去掉即可
dataset目录下主要有三个文件,分别是
- factory.py:这是一个工厂类,用类生成imdb类并且返回数据库供网络训练和测试使用
- imdb.py:是数据库读写类的基类,封装了许多db的操作
- pascl_voc.pyRoss用这个类来操作
3.修改py-faster-rcnn/lib/datasets/imdb.py
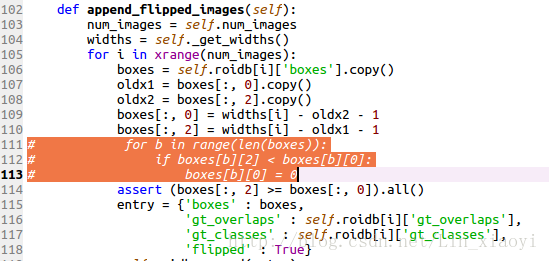
在使用自己的数据进行训练时,假如你的数据集中的图片没有统一整理过就会报assert(boxes[:,2]>=boxes[:,0].all()这个错误,故需在imdb.py中加入如下几行
4.开始训练
下载预训练的ImageNet的模型
$ cd py-fasyer-rcnn
$ ./data/scripts/fetch_imagenet_models.sh
下载的imagenet.model是在/data文件夹下
imagenet.model链接: https://pan.baidu.com/s/1bpJFguV 密码: 7u5v
$ cd py-faster-rcnn
$ ./experiments/scripts/faster_rcnn_end2end.sh 0 VGG_CNN_M_1024 pascal_voc
由于训练过程太长,可以将训练过程产生的输出定下输入到log文件中,这样可以方便查看。只需要在上述命令中加入定向输入的命令即可,如下:
$ ./experiments/scripts/faster_rcnn_end2end.sh 0 VGG_CNN_M_1024 pascal_voc >/home/xiaoyi/log/clothdirector.log 2>&1
! ! ! 训练前需要将cache中的cache中的pkl文件及VOCdevkit2007中annotations_cache的缓存删掉。
5.测试结果
训练完成之后,将output中的最终模型拷贝到data/faster_rcnn_models,修改tools下的demo.py,我是使用VGG_CNN_M_1024这个中型网络,不是默认的ZF,所以要改的地方挺多
1.修改class
2.增加你自己训练的模型

3.修改prototxt,如果你用的ZF,就不用改了

6.开始检测
执行 ./tools/demo.py –net myvgg1024
假如不想那么麻烦输入参数,可以在demo的parse_args()里修改默认参数
parser.add_argument(‘–net’, dest=’demo_net’, help=’Network to use [myvgg1024]’,
choices=NETS.keys(), default=’myvgg1024’)
这样只需要输入 ./tools/demo.py 就可以了
参考博客:
https://bealin.github.io/2016/10/23/Caffe学习系列——6使用Faster-RCNN进行目标检测/














 184
184











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









