






最近学习了MDP,查看一些资料,本文翻译了维基百科http://en.wikipedia.org/wiki/Markov_decision_process。有许多地方翻译的不好,有翻译错的地方请多多谅解!欢迎给我留下意见,我会尽快更改!
定义
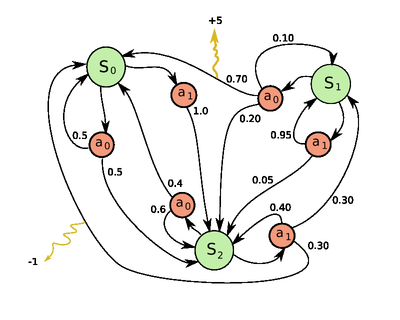
一个很简单的只有3个状态和2个动作的MDP例子。
一个马尔可夫决策过程是一个4 - 元组 ![]() ,其中
,其中
S是状态的有限集合,
A是动作的有限集合(或者,As是处于状态s下可用的一组动作的有限集合),
![]() 表示 t时刻的动作 a 将导致马尔可夫过程由状态 s 在t+1 时刻转变到状态 s' 的概率 。
表示 t时刻的动作 a 将导致马尔可夫过程由状态 s 在t+1 时刻转变到状态 s' 的概率 。
Ra(s,s') 表示以概率Pa(s,s')从状态 s 转变到状态 s' 后收到的即时奖励(或预计即时奖励)。
(马尔可夫决策过程理论实际上并不需要 S 或 A 这两个集合是有限的,但下面的基本算法假定它们是有限的。)
马尔可夫决策过程(MDPs)以安德烈马尔可夫的名字命名 ,针对一些决策的输出结果部分随机而又部分可控的情况,给决策者提供一个决策制定的数学建模框架。MDPs对通过动态规划和强化学习来求解的广泛的优化问题是非常有用的。MDPs至少早在20世纪50年代就被大家熟知(参见贝尔曼1957年)。大部分MDPs领域的研究产生于罗纳德.A.霍华德1960年出版的《动态规划与马尔可夫过程》。今天,它们被应用在各种领域,包括机器人技术,自动化控制,经济和制造业领域。
更确切地说,一个马尔可夫决策过程是一个离散时间随机控制的过程。在每一个时阶(each time step),此决策过程处于某种状态 s ,决策者可以选择在状态 s 下可用的任何动作 a。该过程在下一个时阶做出反应随机移动到一个新的状态 s',并给予决策者相应的奖励 Ra(s,s')。
此过程选择 s'作为其新状态的概率又受到所选择动作的影响。具体来说,此概率由状态转变函数Pa(s,s')来规定。因此,下一个状态 s' 取决于当前状态 s 和决策者的动作 a 。但是考虑到状态 s 和动作 a,不依赖以往所有的状态和动作是有条件的,换句话说,一个的MDP状态转换具有马尔可夫特性。
马尔可夫决策过程是一个马尔可夫链的扩展;区别是动作(允许选择)和奖励(给予激励)的加入。相反,如果忽视奖励,即使每一状态只有一个动作存在,那么马尔可夫决策过程即简化为一个马尔可夫链。
问题
MDPs的核心问题是为决策者找到一个这样的策略:找到到函数 π ,此函数指定决策者处于状态 s的时候将会选择的动作 π(s)。请注意,一旦一个马尔可夫决策过程以这种方式结合策略,这样可以为每个状态决定动作,由此产生的组合行为类似于马尔可夫链。
我们的目标是选择一个策略 π,它将最大限度地积累随机回报,通常预期折扣数目总和超会过一个假定的无限范围:
![]() (当我们选择 at = π(st ))
(当我们选择 at = π(st ))
其中 是折扣率,满足![]() 。它通常接近1。
。它通常接近1。
由于马尔可夫特性,作为上面假设的,特定问题的最优政策的确可以只写成 s 的功能。
解决方法
假设我们知道状态转移函数 P 和奖励函数 R ,而且我们希望计算最大化期望折扣奖励的策略。
标准的算法族(the standard family of algorithms)来计算此类最佳策略需要两个数组,它们分别被包含实际值的值 V 和包含动作的策略 π 索引。在算法的结束,π 将包含此解决方案,V(s)将包含在状态s 下(平均起来)采取上面所说的解决方案所获得的回报折扣总和。
该算法具有下述的两种步骤,针对所有状态按照某种次序重复执行它们,直到没有进一步的变化发生为止。它们是
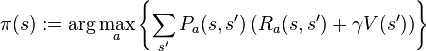
![]()
它们的顺序取决于该算法的变体;针对所有状态一个步骤也许就可以一次完成,或者一个状态接着一个状态,往往针对某些状态比其他一些要更多。只要没有状态是永久排除的此两个步骤之外的,那么该算法将最终找到正确的解答。
值得注意的变种
值迭代
在值迭代(贝尔曼1957年)中,也被称为逆向归纳法 ,π 数组是不被使用的,而是当需要时就计算π(s)的值。
代入 π(s) 的计算结果到 V(s) 得到下面的合并步骤:
 此更新的规则是针对所有状态 s 重申的,直到每个状态收敛到左边等于右边(Bellman方程)。
此更新的规则是针对所有状态 s 重申的,直到每个状态收敛到左边等于右边(Bellman方程)。
策略迭代
在政策迭代(霍华德1960年)中,第一步是进行一次,然后重复步骤二直到收敛。然后,第一步是重新执行一次等。
而不是重复步骤二的衔接,可能像一个线性方程组集合的规划和求解。
这种变体的优点是有一个明确的终止条件:针对所有状态当数组 π 在应用步骤1的过程中不会改变,则算法结束。
修改策略迭代
在修改后的策略迭代(van Nunen,1976; Puterman和Shin 1978),第一步是进行一次,然后第二步是反复多次。然后,第一步是重新执行一次等。
优先扫除
在这种变异中,所有步骤是优先适用于在某些方面重要的状态---无论是基于算法的(对 V 有大的变化或那些状态附近的π ),或基于使用的(这些状态附近初始化状态,或引起人或程序中算法兴趣的)。
扩展
部分可观测
主要文章: 部分可观察马尔可夫决策过程
假定当动作被采取时状态 s 是已知的;否则π(s)不能被计算。当这个假设是不正确的,此问题被称为部分可观测马尔可夫决策过程或POMDP的。
强化学习
如果概率或奖励不明,问题是一种强化学习 (Sutton和Barto,1998)。
为了对定义进一步函数有帮助,相当于首先采取动作对应 a ,然后继续优化(或根据目前策略一拥有的任何情况):
![]() 虽然这个功能也是未知的,在学习过程中经验是基于(s,a) 二元组的(连同其结果s'的 ),即“我是在状态s ,我尝试着做a , s'发生了”)。因此,人们有一个数组Q和使用经验直接更新它。这就是所谓的Q-学习 。
虽然这个功能也是未知的,在学习过程中经验是基于(s,a) 二元组的(连同其结果s'的 ),即“我是在状态s ,我尝试着做a , s'发生了”)。因此,人们有一个数组Q和使用经验直接更新它。这就是所谓的Q-学习 。
强化学习的力量在于它有能力解决没有计算转移概率的马尔可夫决策过程;请注意,在价值和策略迭代中转移概率必要的。此外,强化学习可以结合函数逼近,从而可以解决一个非常大数量的状态问题。强化学习也可以轻而易举地在蒙特卡洛系统模拟器上进行。
另类符号
MDPs的术语和符号并非完不变的。有两个主要来源:一个来源侧重于最大化问题,比如经济学背景的,使用条件的行动,奖励,价值,通常称折扣因子 β 或 γ,而另一个来源则侧重于最小化问题,比如工程学和航空领域,使用条件的控制,成本,成本代价,通常称折扣因子α。此外,转化概率符号各不相同。
| 在这篇文章 | 替代 | 意见 |
| 动作 a | 控制 u |
|
| 奖励 R | 开销 g | g 是 R 负值。 |
| 值 V | 成本代价 J | J 为 V 的负值。 |
| 策略 π | 策略 μ |
|
| 折扣因子 | 折扣因子 α |
|
| 转换概率 Pa(s,s') | 转换概率 pss'(a) |
|
此外,转换概率有时写成 Pr(s,a,s') ,Pr(s'|s,a) 或者 ps's(a) 。
参见
Bellman的经济学应用方程。















 752
752

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









