







看了《深入分析java web技术内幕》,感觉编码这部分写的挺有总结性的,自己总结了书上的内容,记录下一些知识点,希望能有更多朋友受益O(∩_∩)O
1.哪些操作中会存在编码?
1.1)I/O操作中存在的编码:在I/O中,字符与字节之间的相互转换 的操作中,通常用到InputStreamReader与OutputStreamWriter来 实现,要注意使用统一的编解码字符集,一般就不会出现乱码问 题
1.2)内存操作中存在的编码:
字符串—>字节:String对象.getBytes(String charset);
字节—>字符串:new String(byte[] b,String charset);
2.使用Charset类进行编码与解码:
Charset charset = Charset.forName(String charset);
编码:ByteBuffer byteBuffer = charset.encode(String s);
解码:CharBuffer charBuffer = charset.decode(ByteBuffer b);
ByteBuffer类提供一个缓冲区实现对字符与字节的软件换,无需编码与解码,实际值并没修改,仅仅类型做了转换,把16bit的 char变成两个8bit的byte
ByteBuffer byteBuffer = ByteBuffer.allocate(int bufferSize);
//初始化分配一个缓冲区
byteBuffer.putChar(Char char); //字符—>字节
byteBuffer.getChar(int index); //字节—>字符
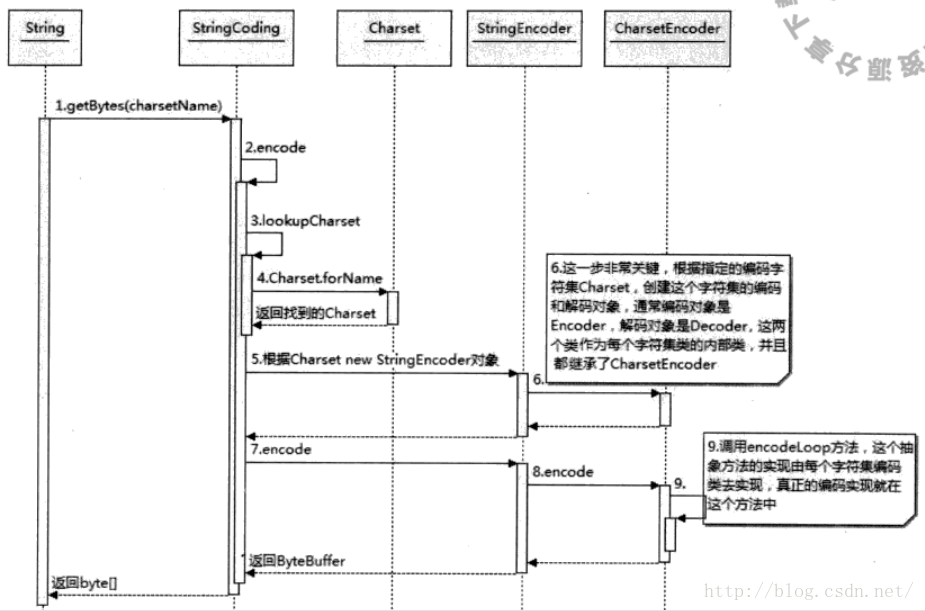
3.Java中如何编解码:
3.1)根据指定的字符集通过Charset.forName(String charset)创建 Charset类;
3.2)根据Charser类创建CharsetEncoder对象;
3.3)调用CharsetEncoder.encode(String s)进行编码
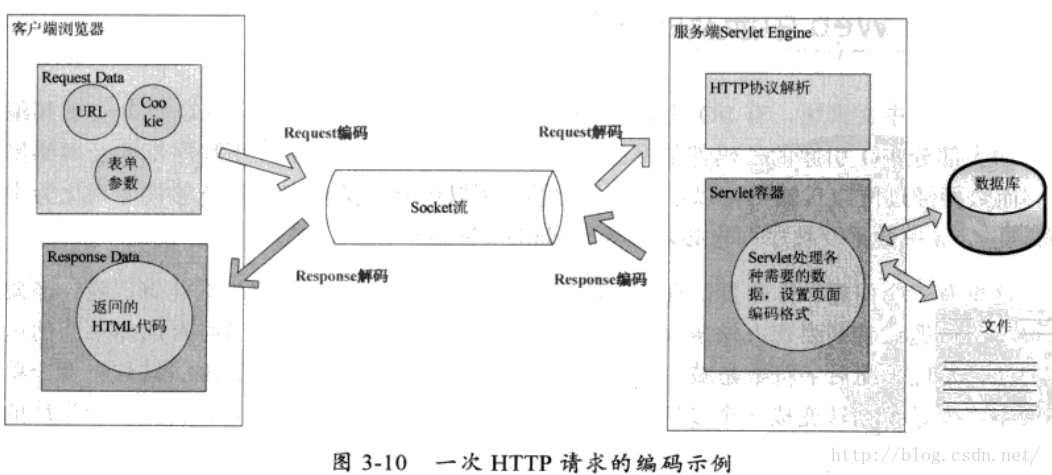
4.Java web中哪些地方可能存在编码转换:
4.1)发起HTTP请求时:URL、Cookie、请求参数
4.2)服务端响应时:读取的数据库数据、本地或网络中的文本文件
4.3)URL上的编解码:
在URL组成中,可能出现中文的部分有Path Info与Query String 这两部分,且浏览器对这两部分采取不同的编码,不同浏览器对 Path Info部分的编码也不一样;Query String部分的解码字符集是 通过HTTP的Header传到服务器端的,其字符集要么是通过 Header中的ContentType定义的charset,要么就是默认的 ISO-8859-1,要是有Header中定义的需要做一些相应的配置
在tomcat中,对URL中的URI部分进行解码的字符集是在connector的<Connector URIEncoding=”UTF-8” />中定义的,若没定义则使用ISO-8859-1解析,故有中文URL时最好把URIEncoding设为UTF-8;获取Query String部分是通过request.getParameter方法实现的,之后进行解码;对于Query String部分要使用ContentType中定义的编码就需要在connector的<Connector URIEncoding=”UTF-8” useBodyEncodingForURI=”true” />中的useBodyEncodingForURI设置为true,该设置仅仅是对Query String部分使用BodyEncoding编码,故在服务器端最好设置<Connector/>中的URIEncoding与useBodyEncodingForURI这两个参数
4.4)HTTP Header的编解码:
在tomcat中,对Header中的项进行解码是在调用 request.getHeader 方法时进行的,若请求的Header项没有解码 则调用MessageBytes 的toString方法,该方法从byte到char 的转换使用的默认编码是 ISO-8859-1,若设置的Header中有 非ASCII字符解码肯定会有乱 码,所以尽量不要在Header中 传递非ASCII字符,若必需传递,先用 org.apache.catalina.util.URLEncoding编码后添加到Header 中,届时再用对应的字符集解码即可
4.5)POST表单的编解码:
POST表单进行解码是在第一次调用request.getParameter方法 时发生的;当提交POST表单时,浏览器先根据ContentType 的Charset编码格式对表单内容进行编码,后提交到服务器端, 在服务器端也是用ContentType的Charset进行解码的,故表 单提交一般不会出现乱码,但一定要在第一次调用 request.getParameter之 前就设置 request.setCharacterEncoding(charset),否则也可能有乱 码,若 没设置则使用默认的ISO-8859-1编码;对于 multipart/form-data类型参数,同样使用Content-Type定义的字 符集编码,上传文件使用字节流方式传输到服务器的本地目 录,此过程不涉及字符编码,在将文件内容添加到parameters 时才发生编码,如果用这个不能编码则采用默认的 ISO-8859-1编码
4.6)HTTP BODY的编解码:
服务端响应客户端的请求返回资源这一过程,要先编码再浏览 器解码,可通过response.setCharacterEncoding设置,该设置会 覆盖request.setCharacterEncoding的值,并通过Content-Type 返回浏览 器,浏览器接收时用Content-Type进行解码;若 Header中的Content-Type没有设置,则根据HTML中的<meta http-equiv=”Context-Type” content=”text/html; charset=UTF-8” />中的charser进行解码,HTML中的再无设置则使用默认的编 码来解码
4.7)对于数据库编码问题,可以通过设置JDBC的URL来指定
如: url=”jdbc:mysql://localhost:3306/DB?useUnicode=true&characte rEn coding=UTF-8”
4.8)JS中的编码问题:
外部引入js文件:
<script src=” ” charset=”UTF-8”></script>
引入一个包含中文的js文件,如果script标签上没有设 置 charset,则浏览器以当前页面默认的字符集解析该js文件;若 外部js文件与当前页面的编码格式一致,则可以不用设置 charset;若不设置charset且js文件编码格式与当前页面不一 致,则乱码
4.9)JS的URL编码:
escape(String s)函数:将ASCII字母、数字、标点符号之外的 其他字符转换成Unicode编码值,并在其编码值前加“%u”; 解码用unescape(String s)函数,可以防止信息丢失
(上述两个方法一般用encodeURL、encodeURLComponent代 替)
encodeURL(String s)函数:可以将整个URL中的字符(除特殊 字符外)进行UTF-8编码,在每个码值前加“%”;解码使用 decodeURL(String s)函数
encodeURLComponent()函数:除了对 ‘ ( ) * - . _ ~ 0-9 a-z A-Z 不编码外,其余都编码,通常用于将一个URL当做一个参数 放在另一个URL中;解码通过decodeURLComponent(String s) 函数
4.10)java与js编码问题:
Java端处理URL编解码有两个类,java.net.URLEncoder和 java.net.URLDecoder,分别对应前端js的 encodeURLComponent 与decodeURLComponent;在前端使 用encodeURLComponent编 码后,到服务端使用URLDecoder 解码可能会发生乱码,原因是 前端js的默认编码是UTF-8, 而后端对于中文的编码一般是GBK 或GB2312,用GBK去 解码UTF-8的编码,必定发生乱码;解决方法:用 encodeURLComponent去编码2次,即 encodeURLComponent(encodeURLComponent(String s)),这样 在使用request.getParameter用GBK解码后取得的就是UTF-8 编码的字符串,若在java端要使用该字符串,再用UTF-8解 码就可以;若是这个结果直接通过js输出到前端,则该UTF-8 字符串输出可以正常显示
4.11)其他需要编码的地方:
除了URL和参数编码的问题外,XML、Velocity、JSP等也可 能存在编码
XML:<?xml version=”1.0” encoding=”UTF-8”?>
Velocity:services.VelocityService.input.encoding=UTF-8
JSP:<% @page contentType=”text/html; charset=UTF-8”%>
PS:以上图片摘自《深入java web 技术内幕》















 3504
3504

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









