







查找:根据给定的某个值,在查找表中确定一个其关键字等于给定值的记录或数据元素。
查找表:是由同一类型的数据元素(或记录)构成的集合。
对查找表经常进行的操作有:
1查询某个特定的数据元素是否在查找表中
2检索某个特定的数据元素的各种属性
3在查找表中插入一个数据元素
4从查找表中删去某个数据元素。
静态查找表:只做前2种查找操作的查找表。
动态查找表:包含4种操作的查找表。
哈希表:根据设定的哈希函数H(key)和处理冲突的方法将一组关键字映像到一个有限的连续的地址集上,并以关键字在地址集中的“像”作为记录在表中的存储位置,这种表便称为哈希表,这一映像过程称为哈希造表或散列,所得存储位置称哈希地址或散列地址。

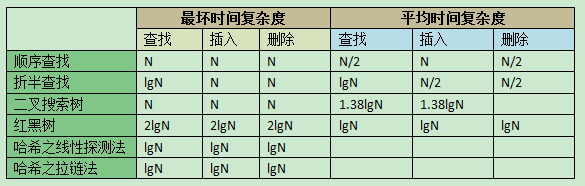
1顺序查找法
int seq_search(int a[], int n, int key)
{
int i;
for (i = 0; i < n; i++)
{
if (a[i] == key)
return i;
}
return -1;
}2折半查找法
查找表是必须有序表。
基本思想:
获取中间记录作为比较对象,若待查找值与中间记录的关键字相等,则查找成功;若待查找值小于中间记录关键字,则在中间记录的左半区继续查找,否则在右半区查找。不断重复,直到查找成功或失败。
/*递归版本*/
int binary_search(int a[], int low, int high, int key)
{
int mid = 0;
if (low > high)
{
return -1;
}
mid = (low+high)/2;
if (a[mid] == key)
{
return mid;
}
else if (a[mid] > key)
{
return binary_search(a, low, mid-1, key);
}
else if (a[mid] < key)
{
return binary_search(a, mid+1, high, key);
}
}
/*非递归版本*/
int binary_search(int a[], int n, int key)
{
int low = 0, high = n-1;
int mid = 0;
while (low <= high)
{
mid = (low+high)/2;
if (a[mid] == key)
{
return mid;
}
else if (a[mid] > key)
{
high = mid - 1;
}
else
{
low = mid + 1;
}
}
return -1;
}
3分块查找
分块查找又称索引顺序查找,它是顺序查找的一种改进方法。
思想:
将n个数据元素"按块有序"划分为m块(m ≤ n)。每一块中的结点不必有序,但块与块之间必须"按块有序";即第1块中任一元素的关键字都必须小于第2块中任一元素的关键字;而第2块中任一元素又都必须小于第3块中的任一元素,……。
操作步骤:
step1先选取各块中的最大关键字构成一个索引表;
step2查找分两个部分:先对索引表进行二分查找或顺序查找,以确定待查记录在哪一块中;
setp3在已确定的块中用顺序法进行查找。
#define IDX_NUM 3
struct index
{
int maxkey;
int start;
int end;
}index_table[IDX_NUM];
int block_search(int a[], int key)
{
int i = 0, j = 0;
/*确定key所在的分块*/
while (i < IDX_NUM && key > index_table[i].maxkey)
i++;
if (i >= IDX_NUM)
{
return -1;
}
/*在分块中顺序查找*/
for (j = index_table[i].start; j <= index_table[i].end; j++)
{
if (a[j] == key)
{
return j;
}
}
return -1;
}
4二叉排序树
B树即二叉排序树(Binary Sort Tree),简称BST,又称二叉查找树、二叉搜索树。
概念:
它或者是一棵空树;或者是具有下列性质的二叉树:
(1)若左子树不空,则左子树上所有结点的值均小于左子树所在树的根结点的值;
(2)若右子树不空,则右子树上所有结点的值均大于右子树所在树的根结点的值;
(3)左、右子树也分别为二叉排序树;
B树的查找:
时间复杂度与树的深度的有关。
步骤:
若根结点的关键字值等于查找的关键字,成功。否则:若小于根结点的关键字值,递归查左子树。
若大于根结点的关键字值,递归查右子树。
若子树为空,查找不成功。
B树的插入:
首先执行查找算法,找出被插结点的父亲结点。 判断被插结点是其父亲结点的左儿子还是右儿子。将被插结点作为叶子结点插入。若二叉树为空。则首先单独生成根结点。
注意:新插入的结点总是叶子结点,所以算法复杂度是O(h)。
B树的删除:
如果删除的结点没有孩子,则删除后算法结束;
如果删除的结点只有一个孩子,则删除后该孩子取代被删除结点的位置;
如果删除的结点有两个孩子,则选择该结点的后继结点(该结点右孩子为根的树中的左子树中的值最小的点)作为新的根,同时在该后继结点开始,执行前两种删除算法,删除算法结束。
5平衡二叉树
概念:
平衡二叉树或者是一棵空树,或者是具有下列性质的二叉树:
它的左子树和右子树都是平衡二叉树,且左子树和右子树的深度之差的绝对值不超过1.
转换:
如何使二叉排序树转变为平衡二叉树:
1单向右旋平衡处理
2单向左旋平衡处理
3双向旋转(先左后右)平衡处理
4双向旋转(先右后左)平衡处理
附:Linux主要的平衡二叉树数据结构就是红黑树。
6 B-树
B-树是一种平衡的多路查找树,常见于文件系统的应用。
一棵m阶的B-树,或为空树,或为满足下列特性的m叉树:
1.树中每个结点至多有m棵子树
2.若根结点不是叶子结点,则至少有两棵子树
3.除根之外的所有非终端结点至少有m/2棵子树
4.所有的叶子结点都出现在同一层次上,并且不带信息
7 B+树
B+树是应文件系统所需而出的一种B-树的变型树。一棵m阶的B+树和m阶的B-树的差异在于:
1.有n棵子树的结点中含有n个关键字
2.所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接
3.所有的非终端结点可以看成是索引部分,结点中仅含有其子树中的最大(或最小)关键字
8哈希表
关键字:哈希函数、装填因子、冲突、同义词;
关键字和和存储的地址建立一个对应的关系:Add = Hash(key);
解决冲突方法:
开放定址法 –探测方式:线性探测、二次探测。
分离链接法 –利用链表的方式。















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









