







1、验证性数据分析
探索性数据分析(EDA)与验证性数据分析(Confirmatory Data Analysis )有所不同:前者注重于对数据进行概括性的描述,不受数据模型和科研假设的限制,而后者只注重对数据模型和研究假设的验证。他认为统计分析不应该只重视模型和假设的验证,而应该充分发挥探索性数据分析的长处,在描述中发现新的理论假设和数据模型。
验证性数据分析(Confirmatory Data Analysis, CDA)是一种用于检验特定假设的统计方法,其目的是验证先前提出的假设是否正确。以下是一些常见的验证性数据分析方法:
-
因素分析:使用因素分析可以找出多个变量之间的潜在关系,并确定它们是否与预先设定的因素相关联。
-
结构方程模型:结构方程模型通过测量指标及其相互关系来评估理论模型与数据的拟合度,并确定模型中每个变量对结果的影响程度。
-
多元回归分析:多元回归分析通过考察自变量与因变量之间的关系,确定某个变量对另一个变量的影响程度,并建立预测模型。
-
相关分析:相关分析检查两种或多种变量之间的关系,以确定它们是否呈正相关、负相关或不相关。
-
方差分析:方差分析用于比较两个或多个样本之间的差异性,并确定哪个变量(或哪些变量)对差异最具影响力。
回归分析通常被认为是一种探索性数据分析方法,极大似然估计是一种统计推断方法,通常用于参数估计。它可用于验证性数据分析,也可以用于探索性数据分析
2、综合评价法
综合评价法的评价指标应该具有可测性
3、数据
所有数据具有保留价值 (×)
4、外部因素矩阵分析
赋予每个因素以权重时
- 数值由0.0(不重要)到1.0(非常重要)
- 权重反映该因素对于企业在产业中取得成功的影响的相对大小性
- 机会往往比威胁得到更高的权重,但当威胁因素特别严重时也可得到高权重
- 确定权重的方法:对成功的和不成功竞争者进行比较,以及通过集体讨论而达成共识
- 所有因素的权重总和必须等于1
无论EFE矩阵包含多少因素,总加权分数的范围都是从最低的1.0到最高的4.0,平均分为2.5。高于2.5则说明企业对外部影响因素能做出反应。EFE矩阵应包含10~20个关键因素,因素数不影响总加权分数的范围,因为权重总和永远等于1。
5、宏观经济两个指标
PPI和CPI是两个常用的宏观经济指标,分别代表生产者物价指数和消费者物价指数。它们是衡量物价水平和通胀水平的重要工具。
PPI(Producer Price Index),即生产者物价指数,是反映一定时期内生产领域(包括农、工、建等三次产业)产品价格总水平的指数。PPI是通过对生产者购买生产原料、能源和中间产品的价格进行监测和调查得出的。这些价格波动的变化可以反映生产成本的变化。PPI是一个领先指标,因为它可以提供有关生产成本的信息,因此可以预示最终产品的价格。
CPI(Consumer Price Index),即消费者物价指数,是反映一定时期内消费者购买商品和服务的价格总水平的指数。CPI通常被用作衡量通货膨胀水平的指标。它通过对一篮子消费品和服务的价格进行监测和调查得出,这些商品和服务被认为是消费者日常开支的代表。CPI是一个滞后指标,因为它反映的是消费者实际购买商品和服务时的价格水平。
PPI和CPI是衡量经济发展和通货膨胀水平的重要指标。当PPI上涨时,可能会导致最终产品价格上涨,这可能会导致通货膨胀;而CPI上涨则意味着消费者购买商品和服务的成本增加,这也可能导致通货膨胀。
百度安全验证![]() https://baijiahao.baidu.com/s?id=1763494910888999630&wfr=spider&for=pc
https://baijiahao.baidu.com/s?id=1763494910888999630&wfr=spider&for=pc
6、常见统计指标
常用的统计指标有:总量指标、相对指标和平均指标。 各指标既有联系又有区别,具体如下: (1)总量指标反映出总体的大小和范围,是其他指标分析的基础。它反映总体规模、水平的综合指标,以统计单位以及标志值汇总而得。按计量单位的角度可分为:实物量指标、价值量指标、劳动量指标。 (2)相对指标反映各部分构成与相互关系,抽掉了整体规模。它是指两个有相互联系的现象间数值的比率,分为结构相对指标、比例相对数、比较相对指标、动态相对数、计划完成度相对指标。 (3)平均指标反映整体的一般水平和集中趋势,抽掉了差异性。它反映总体在一定时间、地点条件下的一般水平;反映了变量分布的集中趋势,说明整体的生产水平和经济效果,在大系统中作为该问题的总体代表值;用以分析现象间的依承关系;作为评价、决策的数量标准参考值。
总量指标是用来反映社会经济现象在一定条件下的总规模、总水平或工作总量的统计指标。总量指标用绝对数表示,也就是用一个绝对数来反映特定现象在一定时间上的总量状况,它是一种最基本的统计指标。
总量指标的计量单位有:自然单位、度量衡单位、复合单位。
自然单位:
自然单位制是高能物理和天体物理中常用的一种单位制。在此单位制下,普朗克常数,光速和玻尔兹曼常数被置为无量纲数1。所有的物理量都用一个基本单位(比如能量)来表述。质量和温度具有和能量相同的量纲,长度和时间则与能量有相反的量纲。
度量衡单位:
度量衡单位是指按照统一的度量衡制度的规定来计量事物数量的单位。
复合单位:
复合单位是物理量的单位,由两个或两个以上的基本物理单位组成。
按计量单位的角度可分为:实物量指标、价值量指标、劳动量指标。
实物指标主要特点是能直接反映产品的使用价值或现象的具体内容,因而能够具体地表明事物的规模和水平。通过实物指标的各项消耗定额,还可以进一步研究各生产部门之间的物质联系和比例关系。价值指标的最大特点在于它代表一定的社会必要劳动量,因此具有最广泛的综合性能和概括能力,用途非常广泛。价值指标首先用于反应经济活动总成果,并通过分类指标的计算,研究它们之间的比例关系。价值指标又经常被用于综合表明重量在不同时间的变动程度。
实物指标是以实物单位计算的总量指标。实物单位是根据事物的自然属性和特点采用实物计量的单位。分为:自然单位,如双、张等;度量衡单位,如吨、千米等;复合单位,如千瓦时等;双重单位,如千米/米等。
价值量指标是把使用价值不同的产品实物量采用既定的价格来进行计算,然后相加成为一个总价值,例如工业总产值等指标。indicator of output value 用货币单位计算和表示产品数量的指标,又称货币指标。
7、在正态总体中抽得的所有统计数都服从正态分布。(错)
8、抽样极限误差和抽样均值误差
“抽样平均误差”----- 样本数是有限的。
“抽样极限误差”----- 样本数是无限的。
平均误差指各个样点值的误差平均值,反映了误差水平大小。极限误差指最大和最小样点值的误差,反映了样本的离散度,即离平均值多远。
抽样平均误差是误差的平均值也就是把误差全部相加除以个数;
抽样极限误差是误差的两个极限之间的差距也就是最大值减去最小值;
两者之间的关系是都在一组调查数据信息中。
两个误差相比,差值较小。
9、矩估计法
矩估计法称数字特征法.求估计量的一种常用方法.以样本矩的某一函数代替总体矩的同一函数来构造估计量的方法称为矩估计法。因为样本可确定一个经验分布函数,由这个经验分布函数可确定样本的各阶矩.而样本又是从总体中随机抽取的,样本的分布及其各阶矩都在一定程度上反映了总体参数的特征,当样本容量n无限增大时,样本矩与相应的总体矩任意接近的概率趋于1,因而可用样本矩代替总体矩构造一个含有未知参数的方程或方程组,方程的解就给出总体参数的估计量.
10、对两个总体均值之差进行估计时,两个样本不需要独立抽样
11、t分布中的t值
t值越大,表示样本平均数与总体平均数之间的差异越大,也意味着样本数据的可靠程度越低
作完全随机设计的两样本均数的t检验需要符合条件:方差是否齐性,是否符合正态分布。
T检验的样本含量较小(例如n < 30),总体标准差σ未知的正态分布。t检验是用t分布理论来推论差异发生的概率,从而比较两个平均数的差异是否显著。如样本量为10,一些学者声称甚至更小的样本也行),只要每组中变量呈正态分布,两组方差不会明显不同。
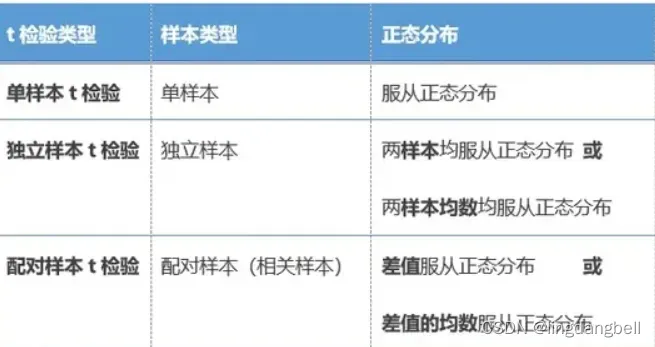
百度安全验证![]() https://baijiahao.baidu.com/s?id=1763660564878981734&wfr=spider&for=pc
https://baijiahao.baidu.com/s?id=1763660564878981734&wfr=spider&for=pc
作完全随机设计的两样本均数的t检验需要符合哪些条件-百度经验
统计中t值和p值的区别为:
1、t值,指的是T检验,主要用于样本含量较小(例如n<30),总体标准差σ未知的正态分布资料。T检验是用t分布理论来推论差异发生的概率,从而比较两个平均数的差异是否显著。
2、P值,就是当原假设为真时,所得到的样本观察结果或更极端结果出现的概率。如果P值很小,说明原假设情况的发生的概率很小,而如果出现了,根据小概率原理,我们就有理由拒绝原假设,P值越小,我们拒绝原假设的理由越充分。
p值代表的是不接受原假设的最小的显著性水平,可以与选定的显著性水平直接比较。例如取5%的显著性水平,如果P值大于5%,就接受原假设,否则不接受原假设。这样不用计算t值,不用查表。
3、P值能直接跟显著性水平比较;而t值想要跟显著性水平比较,就得换算成P值,或者将显著性水平换算成t值。在相同自由度下,查t表所得t统计量值越大,其尾端概率P越小,两者是此消彼长的关系,但不是直线型负相关。
12、云计算
在云计算中,根据其服务集合所提供的服务类型,整个云计算服务集合被划分成三个层次,即IaaS (Infrastructure as a Service, 基础设施即服务)层、PaaS (Platform as a Service, 平台即服务)层和SaaS(Software as a Service,软件即服务)层。这三个层次是可以分割的,即某一层次可以单独完成一项用户的请求而不需要其他层次为其提供必要的服务和支持。IaaS层位于云计算三层服务的最底端,提供基本的计算和存储能力;PaaS层通常也称为“云计算操作系统”,它提供给终端用户基于网络的应用开发环境,包括应用编程接口和运行平台等,并且支持应用从创建到运行整个生命周期所需的各种软硬件资源和工具;SaaS层提供最常见的云计算服务,如邮件服务等。
13、机器学习
机器学习强调三个关键词:算法、经验、性能
机器学习通常包括三个基本要素:模型、特征和算法。
-
模型:模型是机器学习的基础,它是用来预测未知数据的函数或系统。在机器学习中,通常使用数学模型来对数据进行建模。
-
特征:特征是模型的输入,也称为特征向量。特征可以是原始数据的子集,也可以是对原始数据进行预处理后的数据。
-
算法:算法是机器学习的核心,它决定了模型的学习能力。常见的机器学习算法有线性回归、逻辑回归、决策树、支持向量机、朴素贝叶斯分类器、神经网络等。
14、方差分析
用于两个及两个以上样本均数差别的显著性检验。 由于各种因素的影响,研究所得的数据呈现波动状。造成波动的原因可分成两类,一是不可控的随机因素,另一是研究中施加的对结果形成影响的可控因素。
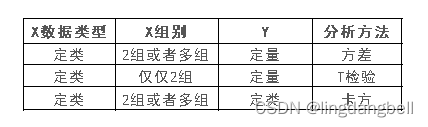
其实核心的区别在于:数据类型不一样。如果是定类和定类,此时应该使用卡方分析;如果是定类和定量,此时应该使用方差或者T检验。
方差和T检验的区别在于,对于T检验的X来讲,其只能为2个类别比如男和女。如果X为3个类别比如本科以下,本科,本科以上;此时只能使用方差分析。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









