







前言
因为业务需要,我需要抓取欧盟商标查询网站的数据,经过分析发现,该网站通过混淆加密js写入cookie的方式进行反爬虫,js加密文件和cookie都有时限,通过破解js加密文件工作量太大,而且不一定成功。查了很多资料之后,我决定使用webmagic+selenium+PhantomJS 的方式进行数据抓取。
注:PhantomJS 是无界面浏览器,在测试阶段我采用的是Chrome浏览器作为调试。使用Chrome调试需要下载Chrome的驱动chrome驱动下载,请下载对应版本的驱动。
核心代码
首先我们项目要引入需要用到的jar包。
<!--java 爬虫框架 -->
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.3</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.seleniumhq.selenium/selenium-java -->
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>3.141.59</version>
</dependency>
java 测试demo
/**
* @author FeianLing
* @date 2019/9/4 chrome driver是谷歌浏览器驱动,用来适配selenium,有图形界面,调试更方便
*/
@Slf4j
public class EuropaDataCatch {
private static ChromeDriverService service;
/**
* @author FeianLing
* @date 2019/9/4
* @desc 获取chrome驱动
* @param
* @return org.openqa.selenium.WebDriver
*/
public static WebDriver getChromeDriver() throws IOException {
System.setProperty(
"webdriver.chrome.driver", "C:/Program Files (x86)/Google/Chrome/Application/chrome.exe");
// 创建一个 ChromeDriver 的接口,用于连接 Chrome(chromedriver.exe 的路径可以任意放置,只要在newFile()的时候写入你放的路径即可)
// C:\Users\feianling\Downloads\chromedriver.exe
service =
new ChromeDriverService.Builder()
.usingDriverExecutable(
new File(
"C:\\Users\\feianling\\Downloads\\chromedriver_win32 (2)\\chromedriver.exe"))
.usingAnyFreePort()
.build();
service.start();
// 创建一个 Chrome 的浏览器实例
return new RemoteWebDriver(service.getUrl(), DesiredCapabilities.chrome());
}
public static void main(String[] args) throws IOException, InterruptedException {
WebDriver driver = getChromeDriver();
driver.get("https://euipo.europa.eu/eSearch/");
driver.findElement(By.id("basicSearchBigInput")).sendKeys("HuaWei");
driver.findElement(By.id("basicSearchBigButton")).click();
}
}
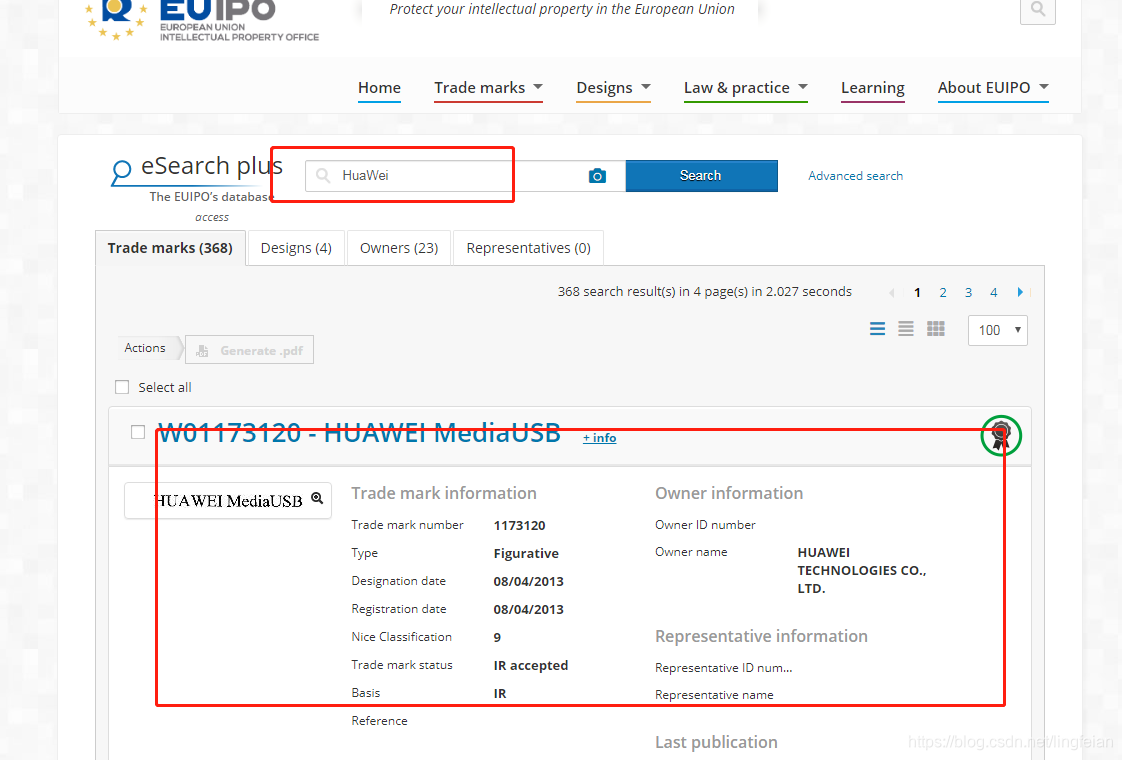
运行代码效果,可以成功打开网站并获取数据信息















 3552
3552











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









