







1.正则表达式的作用
案例演示
先给大家看一个例子,在以下文本中存储了一些职位信息:
Python3 高级开发工程师 上海互教教育科技有限公司上海-浦东新区2万/月02-18满员
测试开发工程师(C++/python) 上海墨鹍数码科技有限公司上海-浦东新区2.5万/每月02-18未满员
Python3 开发工程师 上海德拓信息技术股份有限公司上海-徐汇区1.3万/每月02-18剩余11人
测试开发工程师(Python) 赫里普(上海)信息科技有限公司上海-浦东新区1.1万/每月02-18剩余5人
Python高级开发工程师 上海行动教育科技股份有限公司上海-闵行区2.8万/月02-18剩余255人
python开发工程师 上海优似腾软件开发有限公司上海-浦东新区2.5万/每月02-18满员
将文本中的薪资数据提取出来,只要包含数字就可以。
代码实现
import re
content = '''
Python3 高级开发工程师 上海互教教育科技有限公司上海-浦东新区2万/月02-18满员
测试开发工程师(C++/python) 上海墨鹍数码科技有限公司上海-浦东新区2.5万/每月02-18未满员
Python3 开发工程师 上海德拓信息技术股份有限公司上海-徐汇区1.3万/每月02-18剩余11人
测试开发工程师(Python) 赫里普(上海)信息科技有限公司上海-浦东新区1.1万/每月02-18剩余5人
Python高级开发工程师 上海行动教育科技股份有限公司上海-闵行区2.8万/月02-18剩余255人
python开发工程师 上海优似腾软件开发有限公司上海-浦东新区2.5万/每月02-18满员
'''
for temp in re.findall(r'([\d.]+)万/每{0,1}月', content):
print(temp)
通过以上代码就可以轻松的将文本中的数字提取出来,在find_all方法中的字符串其实就是正则表达式。观察当前方法返回的数据我们发现是一个列表。
2.正则表达式在线验证工具
工具链接地址:https://regexr-cn.com
在这个工具中我们可以快速验证自己编写的正则表达式是否存在语法错误。
3.常见语法
普通字符匹配
可以在正则表达式中直接输入我们想要匹配的字符,如图所示:

当然直接查询汉字也是可以的。但是有些特殊字符不能直接匹配,这些特殊字符有专业术语:元字符。
元字符具有特殊含义,如下所示:
. * + ? \ [] ^ $ {} | ()
通配符 - .
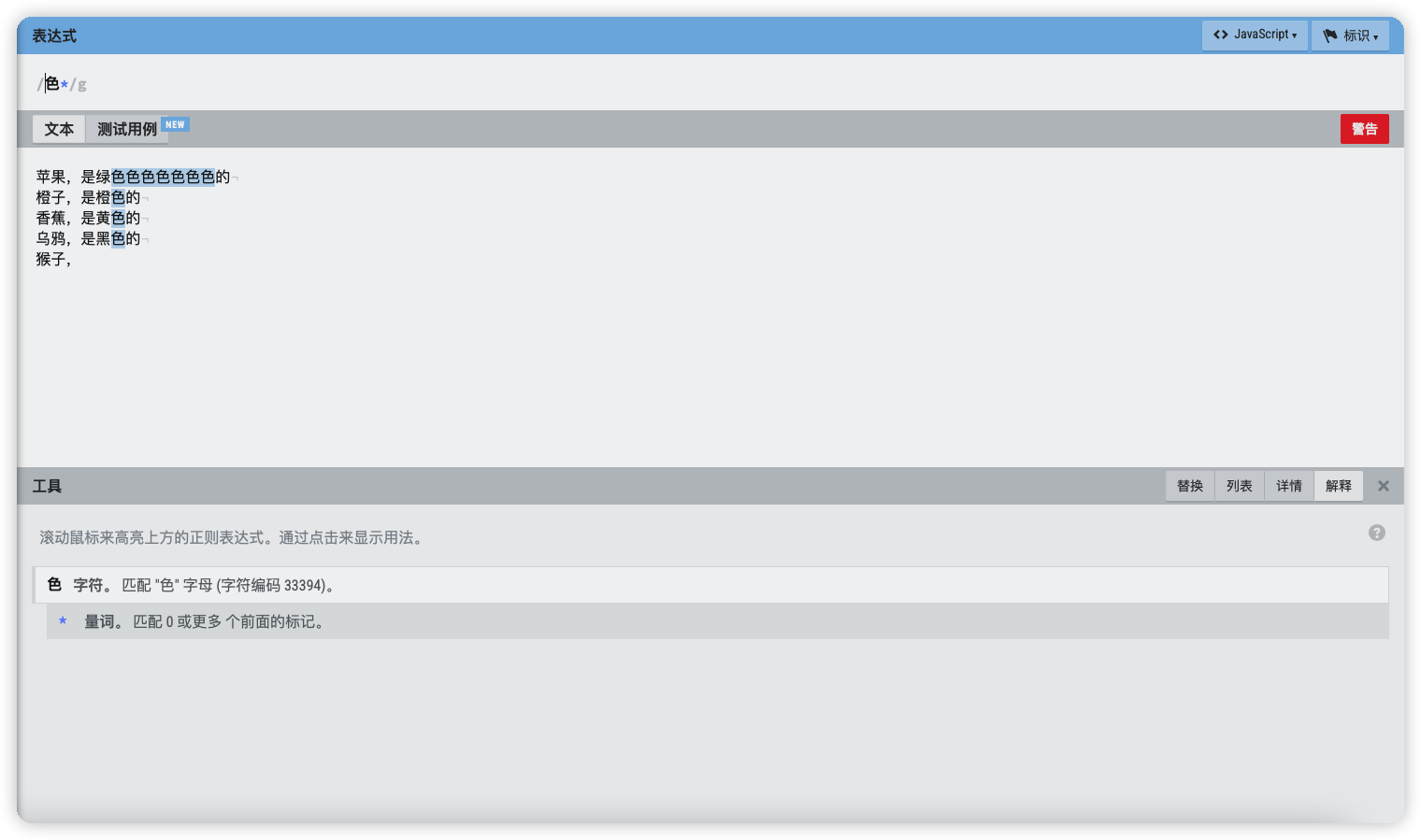
在以下文本中选出所有的颜色信息:
苹果是绿色的
橙子是橙色的
香蕉是黄色的
乌鸦是黑色的
在文本中找到以色结尾,并且包括前面一个字符的信息,那么正则表达式就可以写成:
.色
当前.代表任意字符,但是字符个数只有一个。色这个汉字代表以这个汉字结尾。

代码实现
import re
content = '''
苹果是绿色的
橙子是橙色的
香蕉是黄色的
乌鸦是黑色的
'''
for temp in re.findall(r'.色', content):
print(temp)
重复匹配任意次数 - *
*表示匹配子表达式任意次,包括0次。
在以下文本中匹配逗号后面的字符串内容,包含逗号本身:文本中的逗号为中文。
苹果,是绿色的
橙子,是橙色的
香蕉,是黄色的
乌鸦,是黑色的
猴子,
表达式语法:
,.*
效果如下:
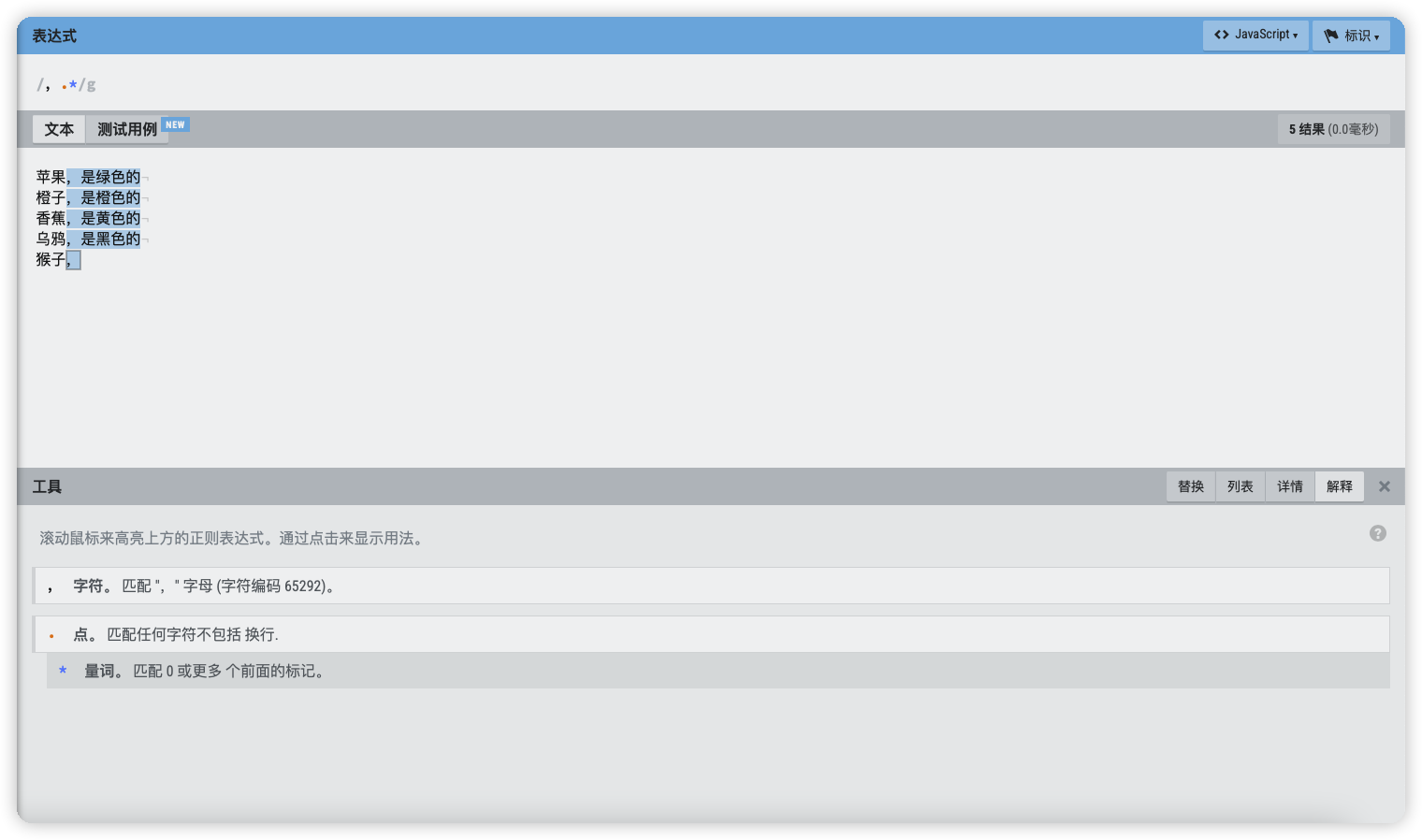
大家注意最后一行,猴子逗号后面没有其它字符了,但是*表示可以匹配0次, 所以表达式也是成立的。
代码实现
content = '''
苹果,是绿色的
橙子,是橙色的
香蕉,是黄色的
乌鸦,是黑色的
猴子,
'''
for temp in re.findall(r',.*', content):
print(temp)
.*在正则表达式中非常常见,表示匹配任意字符任意次数。当然,*前面不一定就是.,也可以是其他字符。
重复匹配一次或多次 - +
+表示匹配前面的子表达式一次或多次,不包括0次。
以之前的文本为例,匹配所有逗号的内容,包含逗号。但是如果逗号后没有内容则不匹配。
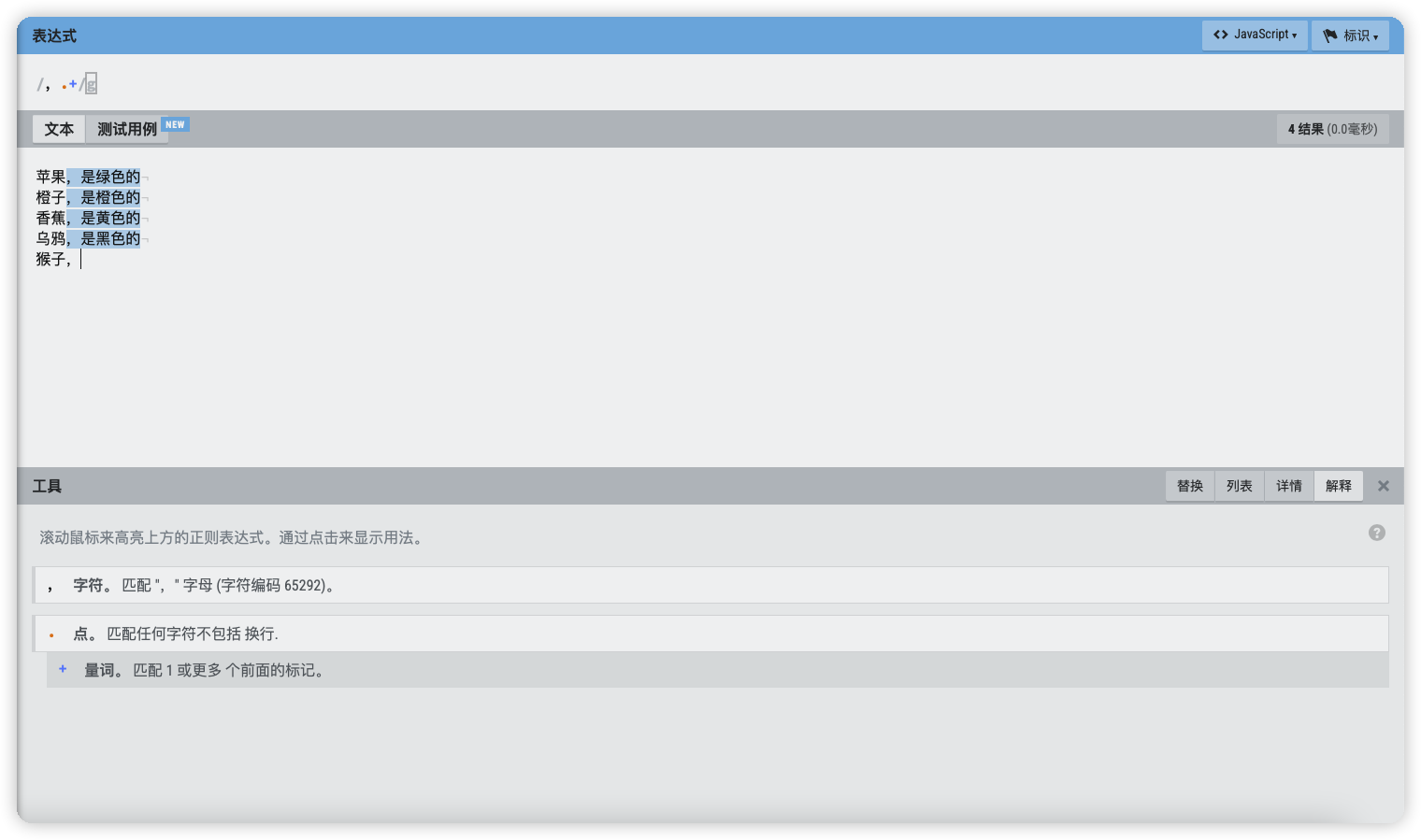
表达式语法:
,.+
匹配0次或者1次 - ?
以之前的文本为例,在文本中匹配每行逗号后面的1个字符,也包含逗号本身。
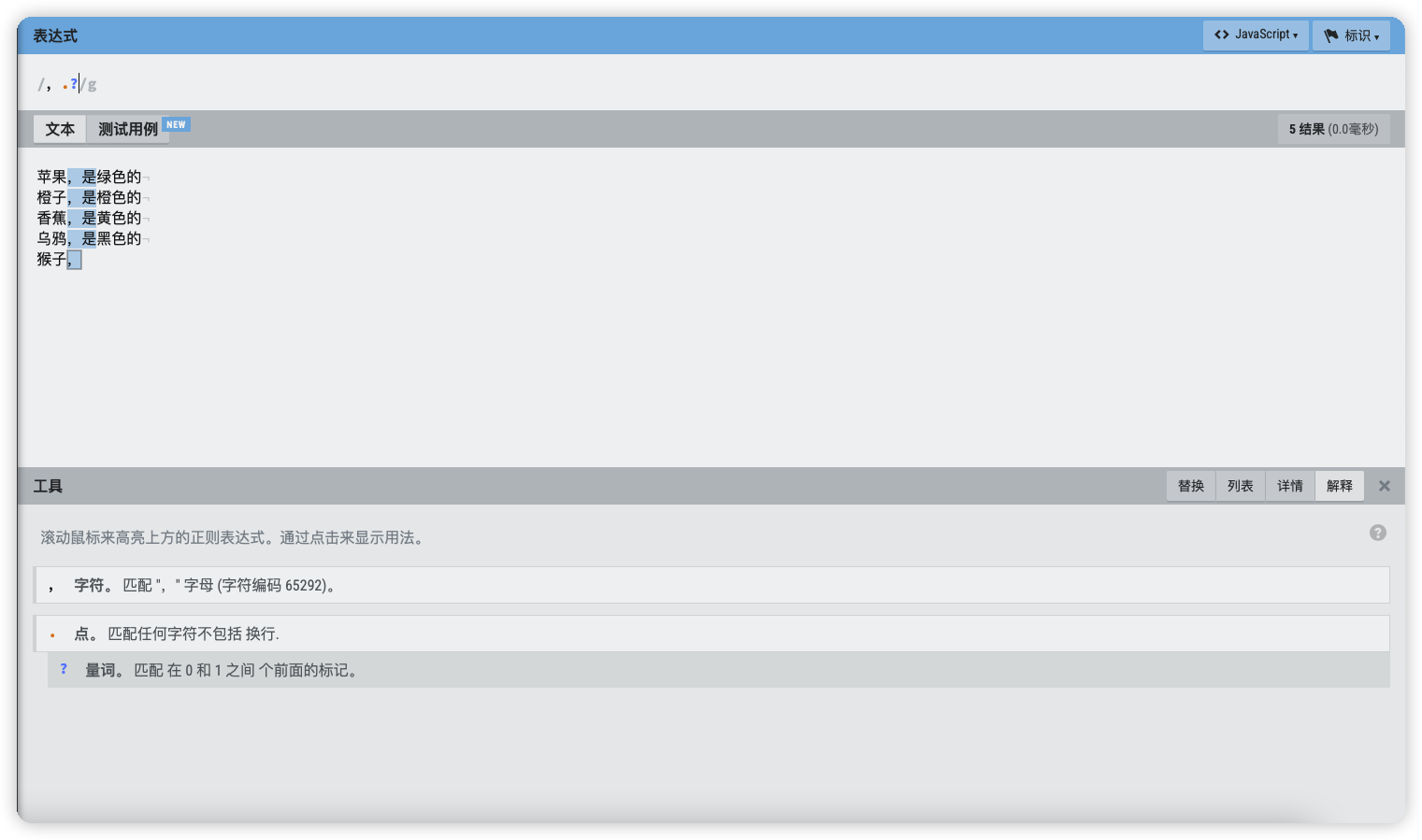
表达式语法:
,.?
最后一行也可以正常匹配,原因是?表示可以匹配1次或者0次。
匹配执行次数 - {}
{}表示指定字符匹配的次数。
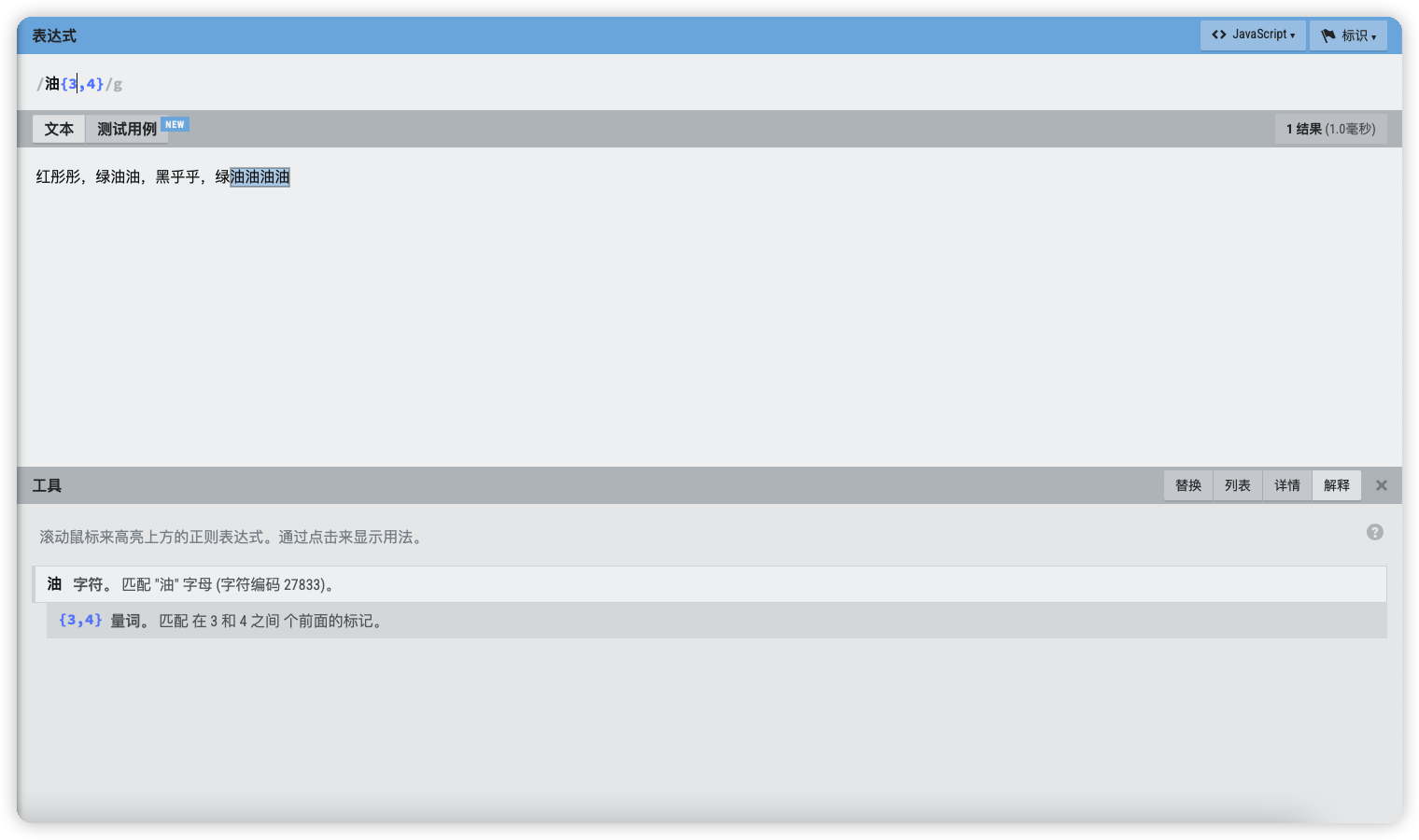
测试文本:
红彤彤,绿油油,黑乎乎,绿油油油油
- 表达式
油{3}就表示匹配连续的油字3次 - 表达式
油{3,4}就表示匹配连续的油字至少3次,至多4次
贪婪模式与非贪婪模式
将以下字符串中的所有html标签提取出来:
<html><head><title></ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











