







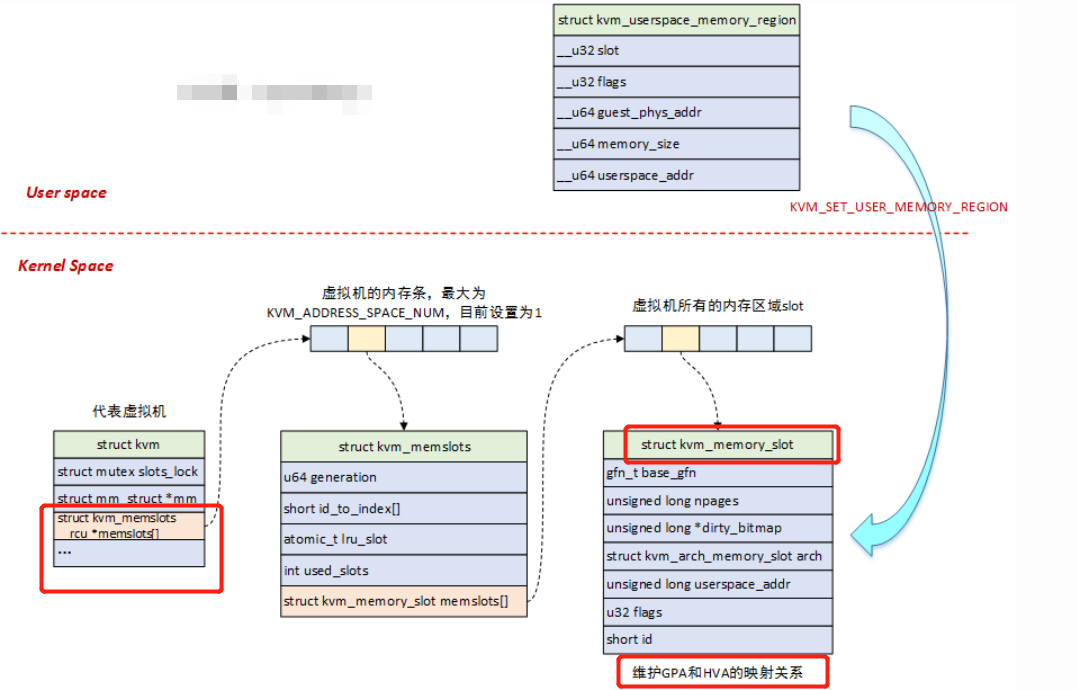
struct kvm_memory_slot
http://tinylab.org/kvm-intro-part1
https://www.cnblogs.com/LoyenWang/p/13943005.html
(免费订阅,永久学习)学习地址: Dpdk/网络协议栈/vpp/OvS/DDos/NFV/虚拟化/高性能专家-学习视频教程-腾讯课堂
更多DPDK相关学习资料有需要的可以自行报名学习,免费订阅,永久学习,或点击这里加qun免费
领取,关注我持续更新哦! !
- 虚拟机使用
slot来组织物理内存,每个slot对应一个struct kvm_memory_slot,一个虚拟机的所有slot构成了它的物理地址空间; - 用户态使用
struct kvm_userspace_memory_region来设置内存slot,在内核中使用struct kvm_memslots结构来将kvm_memory_slot组织起来; struct kvm_userspace_memory_region结构体中,包含了slot的ID号用于查找对应的slot,此外还包含了物理内存起始地址及大小,以及HVA地址,HVA地址是在用户进程地址空间中分配的,也就是Qemu进程地址空间中的一段区域;
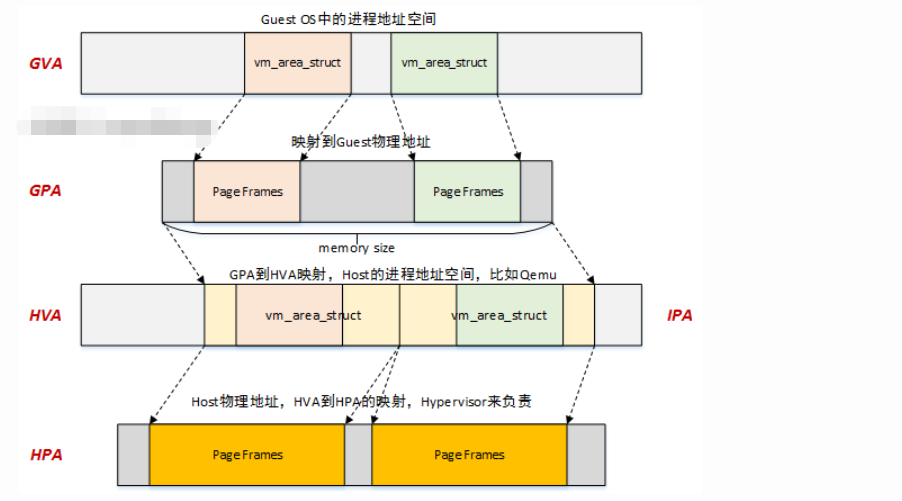
GPA->HVA
KVM-Qemu方案中,GPA->HVA的转换,是通过ioctl中的KVM_SET_USER_MEMORY_REGION命令来实现的,如下图:
HVA->HPA
光有了GPA->HVA,似乎还是跟Hypervisor没有太大关系,到底是怎么去访问物理内存的呢?貌似也没有看到去建立页表映射啊?
跟我走吧,带着问题出发!
之前内存管理相关文章中提到过,用户态程序中分配虚拟地址vma后,实际与物理内存的映射是在page fault时进行的。那么同样的道理,我们可以顺着这个思路去查找是否HVA->HPA的映射也是在异常处理的过程中创建的?答案是显然的。
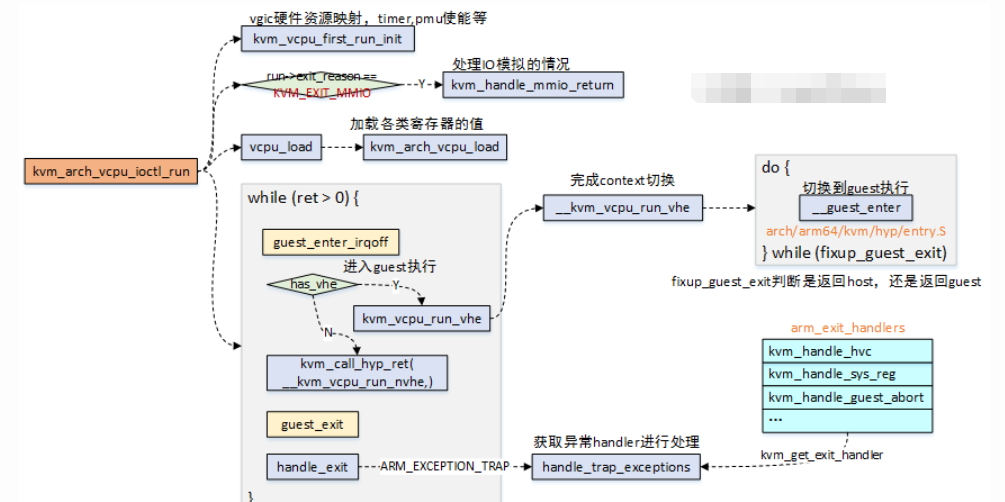
- 当用户态触发
kvm_arch_vcpu_ioctl_run时,会让Guest OS去跑在Hypervisor上,当Guest OS中出现异常退出到Host时,此时handle_exit将对退出的原因进行处理;
异常处理函数arm_exit_handlers如下,具体调用选择哪个处理函数,是根据ESR_EL2, Exception Syndrome Register(EL2)中的值来确定的。

static exit_handle_fn arm_exit_handlers[] = {
[0 ... ESR_ELx_EC_MAX] = kvm_handle_unknown_ec,
[ESR_ELx_EC_WFx] = kvm_handle_wfx,
[ESR_ELx_EC_CP15_32] = kvm_handle_cp15_32,
[ESR_ELx_EC_CP15_64] = kvm_handle_cp15_64,
[ESR_ELx_EC_CP14_MR] = kvm_handle_cp14_32,
[ESR_ELx_EC_CP14_LS] = kvm_handle_cp14_load_store,
[ESR_ELx_EC_CP14_64] = kvm_handle_cp14_64,
[ESR_ELx_EC_HVC32] = handle_hvc,
[ESR_ELx_EC_SMC32] = handle_smc,
[ESR_ELx_EC_HVC64] = handle_hvc,
[ESR_ELx_EC_SMC64] = handle_smc,
[ESR_ELx_EC_SYS64] = kvm_handle_sys_reg,
[ESR_ELx_EC_SVE] = handle_sve,
[ESR_ELx_EC_IABT_LOW] = kvm_handle_guest_abort,
[ESR_ELx_EC_DABT_LOW] = kvm_handle_guest_abort,
[ESR_ELx_EC_SOFTSTP_LOW]= kvm_handle_guest_debug,
[ESR_ELx_EC_WATCHPT_LOW]= kvm_handle_guest_debug,
[ESR_ELx_EC_BREAKPT_LOW]= kvm_handle_guest_debug,
[ESR_ELx_EC_BKPT32] = kvm_handle_guest_debug,
[ESR_ELx_EC_BRK64] = kvm_handle_guest_debug,
[ESR_ELx_EC_FP_ASIMD] = handle_no_fpsimd,
[ESR_ELx_EC_PAC] = kvm_handle_ptrauth,
};

这个函数表,发现ESR_ELx_EC_DABT_LOW和ESR_ELx_EC_IABT_LOW两个异常,这不就是指令异常和数据异常吗,我们大胆的猜测,HVA->HPA映射的建立就在kvm_handle_guest_abort函数中。
虚拟机内存初始化
https://abelsu7.top/2019/07/07/kvm-memory-virtualization/
qemu中用AddressSpace用来表示CPU/设备看到的内存,两个全局 Address_sapce: address_space_memory、 address_space_io,地址空间之间通过链表连接起来
kvm_vm_ioctl(s, KVM_SET_USER_MEMORY_REGION, &mem);来修改Guest的内存空间的
在kvm_init()函数中主要做如下几件事情:
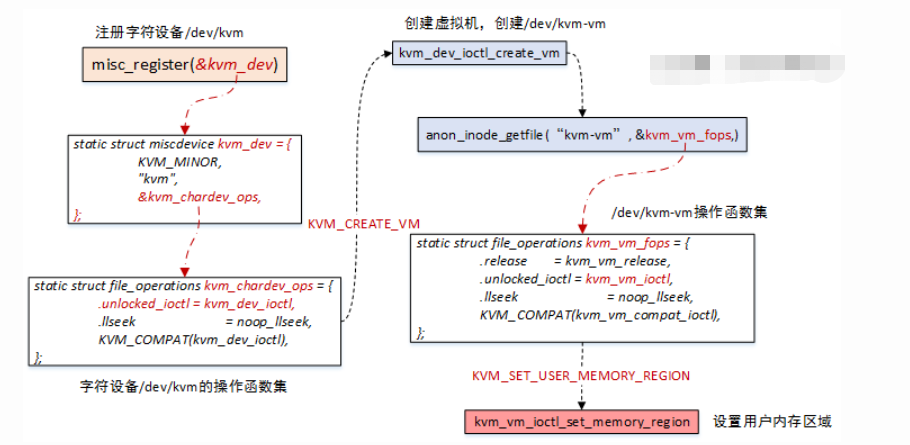
1、s->fd = qemu_open("/dev/kvm", O_RDWR),打开kvm控制的总设备文件/dev/kvm
2、s->vmfd = kvm_ioctl(s, KVM_CREATE_VM, 0),调用创建虚拟机的API,对应Linux kernel中的创建流程,请全文搜索kernel,关键词“KVM_CREATE_VM”
3、kvm_check_extension,检查各种extension,并设置对应的features
4、ret = kvm_arch_init(s),做一些体系结构相关的初始化,如msr、identity map、mmu pages number等等
5、kvm_irqchip_create,调用kvm_vm_ioctl(s, KVM_CREATE_IRQCHIP)在KVM中虚拟IRQ芯片,详细流程请全文搜索
6、memory_listener_register,该函数是初始化内存的主要函数,
memory_listener_register调用了两次,分别注册了 kvm_memory_listener和kvm_io_listener,即通用的内存和MMIO是分开管理的。
以通用的内存注册为例,函数首先在全局的memory_listener链表中添加了kvm_memory_listener,之后调用listener_add_address_space分别将该listener添加到address_space_memory和address_space_io中, address_space_io是虚机的io地址空间(设备的io port就分布在这个地址空间里)
然后调用listener的region_add(即kvm_region_add()),该函数最终调用了kvm_set_user_memory_region(),其中调用kvm_vm_ioctl(s, KVM_SET_USER_MEMORY_REGION, &mem),该调用是最终将内存区域注册到kvm中的函数。

int main()
└─ static int configure_accelerator()
└─ int kvm_init() // 初始化 KVM
├─ int kvm_ioctl(KVM_CREATE_VM) // 创建 VM
├─ int kvm_arch_init() // 针对不同的架构进行初始化
└─ void memory_listener_register() // 注册 kvm_memory_listener
└─ static void listener_add_address_space() // 调用 region_add 回调
└─ static void kvm_region_add() // region_add 对应的回调实现
|
└─memory_region_get_ram_ptr
└─ static void kvm_set_phys_mem() // 根据传入的 section 填充 KVMSlot
└─ static int kvm_set_user_memory_region()
└─ int ioctl(KVM_SET_USER_MEMORY_REGION)


int kvm_init(void)
{
/* ... */
s->vmfd = kvm_ioctl(s, KVM_CREATE_VM, 0); // 创建 VM
/* ... */
ret = kvm_arch_init(s); // 针对不同的架构进行初始化
if (ret < 0) {
goto err;
}
/* ... */
memory_listener_register(&kvm_memory_listener, NULL); // 注册回调函数
/* ... */
}


static void kvm_region_add(MemoryListener *listener,
MemoryRegionSection *section)
{
KVMMemoryListener *kml = container_of(listener, KVMMemoryListener, listener);
memory_region_ref(section->mr);
kvm_set_phys_mem(kml, section, true);
}
这个函数看似复杂,主要是因为,需要判断变化的各种情况是否与之前的重合,是否是脏页等等情况。我们只看最开始的情况。
static void kvm_set_phys_mem(KVMMemoryListener *kml,
MemoryRegionSection *section, bool add)
{
KVMState *s = kvm_state;
KVMSlot *mem, old;
int err;
MemoryRegion *mr = section->mr;
bool writeable = !mr->readonly && !mr->rom_device;
hwaddr start_addr = section->offset_within_address_space;
ram_addr_t size = int128_get64(section->size);
void *ram = NULL;
unsigned delta;
/* kvm works in page size chunks, but the function may be called
with sub-page size and unaligned start address. Pad the start
address to next and truncate size to previous page boundary. */
delta = qemu_real_host_page_size - (start_addr & ~qemu_real_host_page_mask);
delta &= ~qemu_real_host_page_mask;
if (delta > size) {
return;
}
start_addr += delta;
size -= delta;
size &= qemu_real_host_page_mask;
if (!size || (start_addr & ~qemu_real_host_page_mask)) {
return;
}
if (!memory_region_is_ram(mr)) {
if (writeable || !kvm_readonly_mem_allowed) {
return;
} else if (!mr->romd_mode) {
/* If the memory device is not in romd_mode, then we actually want
* to remove the kvm memory slot so all accesses will trap. */
add = false;
}
}
ram = memory_region_get_ram_ptr(mr) + section->offset_within_region + delta;
...
if (!size) {
return;
}
if (!add) {
return;
}
mem = kvm_alloc_slot(kml);
mem->memory_size = size;
mem->start_addr = start_addr;
mem->ram = ram;
mem->flags = kvm_mem_flags(mr);
err = kvm_set_user_memory_region(kml, mem);
if (err) {
fprintf(stderr, "%s: error registering slot: %sn", __func__,
strerror(-err));
abort();
}
}
这个函数主要就是得到MemoryRegionSection在address_space中的位置,这个就是虚拟机的物理地址,函数中是start_addr,
然后通过memory_region_get_ram_ptr得到对应其对应的qemu的HVA地址,函数中是ram,当然还有大小的size以及这块内存的flags,这些参数组成了一个KVMSlot,之后传递给kvm_set_user_memory_region。
static int kvm_set_user_memory_region(KVMMemoryListener *kml, KVMSlot *slot)
{
KVMState *s = kvm_state;
struct kvm_userspace_memory_region mem;
mem.slot = slot->slot | (kml->as_id << 16);
mem.guest_phys_addr = slot->start_addr;
mem.userspace_addr = (unsigned long)slot->ram;
mem.flags = slot->flags;
if (slot->memory_size && mem.flags & KVM_MEM_READONLY) {
/* Set the slot size to 0 before setting the slot to the desired
* value. This is needed based on KVM commit 75d61fbc. */
mem.memory_size = 0;
kvm_vm_ioctl(s, KVM_SET_USER_MEMORY_REGION, &mem);
}
mem.memory_size = slot->memory_size;
return kvm_vm_ioctl(s, KVM_SET_USER_MEMORY_REGION, &mem);
}
通过层层抽象,我们终于完成了GPA->HVA的对应,并且传递到了KVM

KVM_SET_USER_MEMORY_REGION kvm_vm_ioctl_set_memory_region
kvm_vm_ioctl(s, KVM_SET_USER_MEMORY_REGION, &mem)
┝━kvm_vm_ioctl_set_memory_region()-->kvm_set_memory_region()-->__kvm_set_memory_region()
/*
* kvm ioctl vm指令的入口,传入的fd为KVM_CREATE_VM中返回的fd。
* 主要用于针对VM虚拟机进行控制,如:内存设置、创建VCPU等。
*/
static long kvm_vm_ioctl(struct file *filp,
unsigned int ioctl, unsigned long arg)
{
struct kvm *kvm = filp->private_data;
void __user *argp = (void __user *)arg;
int r;
if (kvm->mm != current->mm)
return -EIO;
switch (ioctl) {
// 创建VCPU
case KVM_CREATE_VCPU:
r = kvm_vm_ioctl_create_vcpu(kvm, arg);
break;
// 建立guest物理地址空间中的内存区域与qemu-kvm虚拟地址空间中的内存区域的映射
case KVM_SET_USER_MEMORY_REGION: {
// 存放内存区域信息的结构体,该内存区域从qemu-kvm进程的用户地址空间中分配
struct kvm_userspace_memory_region kvm_userspace_mem;
r = -EFAULT;
// 从用户态拷贝相应数据到内核态,入参argp指向用户态地址
if (copy_from_user(&kvm_userspace_mem, argp,
sizeof kvm_userspace_mem))
goto out;
// 进入实际处理流程
r = kvm_vm_ioctl_set_memory_region(kvm, &kvm_userspace_mem);
break;
}

数据结构部分已经罗列了大体的关系,那么在KVM_SET_USER_MEMORY_REGION时,围绕的操作就是slots的创建、删除,更新等操作,话不多说,来图了:
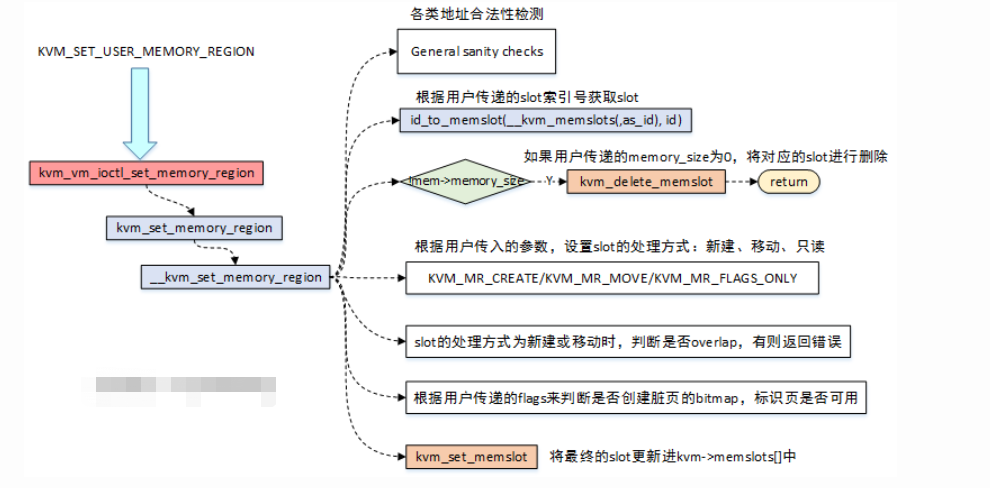
- 当用户要设置内存区域时,最终会调用到
__kvm_set_memory_region函数,在该函数中完成所有的逻辑处理; __kvm_set_memory_region函数,首先会对传入的struct kvm_userspace_memory_region的各个字段进行合法性检测判断,主要是包括了地址的对齐,范围的检测等;- 根据用户传递的
slot索引号,去查找虚拟机中对应的slot,查找的结果只有两种:1)找到一个现有的slot;2)找不到则新建一个slot; - 如果传入的参数中
memory_size为0,那么会将对应slot进行删除操作; - 根据用户传入的参数,设置
slot的处理方式:KVM_MR_CREATE,KVM_MR_MOVE,KVM_MEM_READONLY; - 根据用户传递的参数决定是否需要分配脏页的bitmap,标识页是否可用;
- 最终调用
kvm_set_memslot来设置和更新slot信息;

/*
* 建立guest物理地址空间中的内存区域与qemu-kvm虚拟地址空间中的内存区域的映射
* 相应信息由uerspace_memory_region参数传入,而其源头来自于用户态qemu-kvm。每次
* 调用设置一个内存区间。内存区域可以不连续(实际的物理内存区域也经常不连
* 续,因为有可能有保留内存)
*/
int __kvm_set_memory_region(struct kvm *kvm,
struct kvm_userspace_memory_region *mem)
{
int r;
gfn_t base_gfn;
unsigned long npages;
struct kvm_memory_slot *slot;
struct kvm_memory_slot old, new;
struct kvm_memslots *slots = NULL, *old_memslots;
enum kvm_mr_change change;
// 标记检查
r = check_memory_region_flags(mem);
if (r)
goto out;
r = -EINVAL;
/* General sanity checks */
// 合规检查,防止用户态恶意传参,导致安全漏洞
if (mem->memory_size & (PAGE_SIZE - 1))
goto out;
if (mem->guest_phys_addr & (PAGE_SIZE - 1))
goto out;
/* We can read the guest memory with __xxx_user() later on. */
if ((mem->slot < KVM_USER_MEM_SLOTS) &&
((mem->userspace_addr & (PAGE_SIZE - 1)) ||
!access_ok(VERIFY_WRITE,
(void __user *)(unsigned long)mem->userspace_addr,
mem->memory_size)))
goto out;
if (mem->slot >= KVM_MEM_SLOTS_NUM)
goto out;
if (mem->guest_phys_addr + mem->memory_size < mem->guest_phys_addr)
goto out;
// 将kvm_userspace_memory_region->slot转换为kvm_mem_slot结构,该结构从kvm->memslots获取
slot = id_to_memslot(kvm->memslots, mem->slot);
// 内存区域起始位置在Guest物理地址空间中的页框号
base_gfn = mem->guest_phys_addr >> PAGE_SHIFT;
// 内存区域大小转换为page单位
npages = mem->memory_size >> PAGE_SHIFT;
r = -EINVAL;
if (npages > KVM_MEM_MAX_NR_PAGES)
goto out;
if (!npages)
mem->flags &= ~KVM_MEM_LOG_DIRTY_PAGES;
new = old = *slot;
new.id = mem->slot;
new.base_gfn = base_gfn;
new.npages = npages;
new.flags = mem->flags;
r = -EINVAL;
if (npages) {
// 判断是否需新创建内存区域
if (!old.npages)
change = KVM_MR_CREATE;
// 判断是否修改现有的内存区域
else { /* Modify an existing slot. */
// 修改的区域的HVA不同或者大小不同或者flag中的
// KVM_MEM_READONLY标记不同,直接退出。
if ((mem->userspace_addr != old.userspace_addr) ||
(npages != old.npages) ||
((new.flags ^ old.flags) & KVM_MEM_READONLY))
goto out;
/*
* 走到这,说明被修改的区域HVA和大小都是相同的
* 判断区域起始的GFN是否相同,如果是,则说明需
* 要在Guest物理地址空间中move这段区域,设置KVM_MR_MOVE标记
*/
if (base_gfn != old.base_gfn)
change = KVM_MR_MOVE;
// 如果仅仅是flag不同,则仅修改标记,设置KVM_MR_FLAGS_ONLY标记
else if (new.flags != old.flags)
change = KVM_MR_FLAGS_ONLY;
// 否则,啥也不干
else { /* Nothing to change. */
r = 0;
goto out;
}
}
} else if (old.npages) {/*如果新设置的区域大小为0,而老的区域大小不为0,则表示需要删除原有区域。*/
change = KVM_MR_DELETE;
} else /* Modify a non-existent slot: disallowed. */
goto out;
if ((change == KVM_MR_CREATE) || (change == KVM_MR_MOVE)) {
/* Check for overlaps */
r = -EEXIST;
// 检查现有区域中是否重叠的
kvm_for_each_memslot(slot, kvm->memslots) {
if ((slot->id >= KVM_USER_MEM_SLOTS) ||
(slot->id == mem->slot))
continue;
if (!((base_gfn + npages <= slot->base_gfn) ||
(base_gfn >= slot->base_gfn + slot->npages)))
goto out;
}
}
/* Free page dirty bitmap if unneeded */
if (!(new.flags & KVM_MEM_LOG_DIRTY_PAGES))
new.dirty_bitmap = NULL;
r = -ENOMEM;
// 如果需要创建新区域
if (change == KVM_MR_CREATE) {
new.userspace_addr = mem->userspace_addr;
// 设置新的内存区域架构相关部分
if (kvm_arch_create_memslot(&new, npages))
goto out_free;
}
/* Allocate page dirty bitmap if needed */
if ((new.flags & KVM_MEM_LOG_DIRTY_PAGES) && !new.dirty_bitmap) {
if (kvm_create_dirty_bitmap(&new) < 0)
goto out_free;
}
// 如果删除或move内存区域
if ((change == KVM_MR_DELETE) || (change == KVM_MR_MOVE)) {
r = -ENOMEM;
// 复制kvm->memslots的副本
slots = kmemdup(kvm->memslots, sizeof(struct kvm_memslots),
GFP_KERNEL);
if (!slots)
goto out_free;
slot = id_to_memslot(slots, mem->slot);
slot->flags |= KVM_MEMSLOT_INVALID;
// 安装新memslots,返回旧的memslots
old_memslots = install_new_memslots(kvm, slots, NULL);
/* slot was deleted or moved, clear iommu mapping */
// 原来的slot需要删除,所以需要unmap掉相应的内存区域
kvm_iommu_unmap_pages(kvm, &old);
/* From this point no new shadow pages pointing to a deleted,
* or moved, memslot will be created.
*
* validation of sp->gfn happens in:
* - gfn_to_hva (kvm_read_guest, gfn_to_pfn)
* - kvm_is_visible_gfn (mmu_check_roots)
*/
// flush影子页表中的条目
kvm_arch_flush_shadow_memslot(kvm, slot);
slots = old_memslots;
}
// 处理private memory slots,对其分配用户态地址,即HVA
r = kvm_arch_prepare_memory_region(kvm, &new, mem, change);
if (r)
goto out_slots;
r = -ENOMEM;
/*
* We can re-use the old_memslots from above, the only difference
* from the currently installed memslots is the invalid flag. This
* will get overwritten by update_memslots anyway.
*/
if (!slots) {
slots = kmemdup(kvm->memslots, sizeof(struct kvm_memslots),
GFP_KERNEL);
if (!slots)
goto out_free;
}
/*
* IOMMU mapping: New slots need to be mapped. Old slots need to be
* un-mapped and re-mapped if their base changes. Since base change
* unmapping is handled above with slot deletion, mapping alone is
* needed here. Anything else the iommu might care about for existing
* slots (size changes, userspace addr changes and read-only flag
* changes) is disallowed above, so any other attribute changes getting
* here can be skipped.
*/
if ((change == KVM_MR_CREATE) || (change == KVM_MR_MOVE)) {
r = kvm_iommu_map_pages(kvm, &new);
if (r)
goto out_slots;
}
/* actual memory is freed via old in kvm_free_physmem_slot below */
if (change == KVM_MR_DELETE) {
new.dirty_bitmap = NULL;
memset(&new.arch, 0, sizeof(new.arch));
}
//将new分配的memslot写入kvm->memslots[]数组中
old_memslots = install_new_memslots(kvm, slots, &new);
kvm_arch_commit_memory_region(kvm, mem, &old, change);
// 释放旧内存区域相应的物理内存(HPA)
kvm_free_physmem_slot(&old, &new);
kfree(old_memslots);
return 0;
out_slots:
kfree(slots);
out_free:
kvm_free_physmem_slot(&new, &old);
out:
return r;
}

kvm_handle_guest_abort
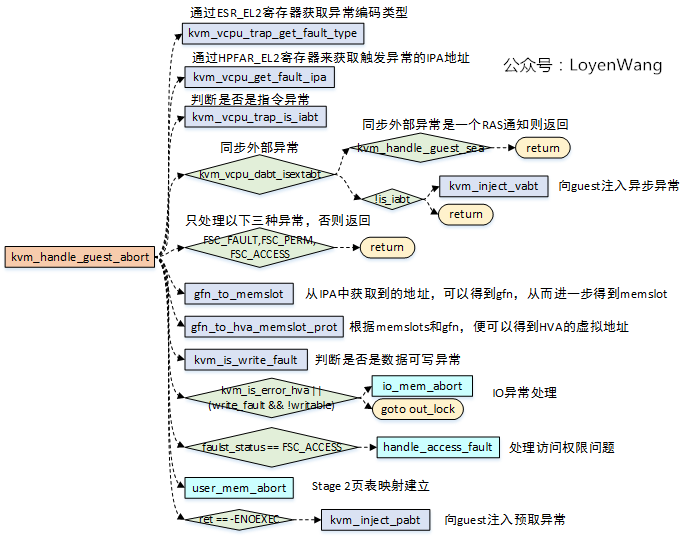
-
kvm_vcpu_trap_get_fault_type用于获取ESR_EL2的数据异常和指令异常的fault status code,也就是ESR_EL2的ISS域;kvm_vcpu_get_fault_ipa用于获取触发异常的IPA地址;kvm_vcpu_trap_is_iabt用于获取异常类,也就是ESR_EL2的EC,并且判断是否为ESR_ELx_IABT_LOW,也就是指令异常类型;kvm_vcpu_dabt_isextabt用于判断是否为同步外部异常,同步外部异常的情况下,如果支持RAS,Host能处理该异常,不需要将异常注入给Guest;- 异常如果不是
FSC_FAULT,FSC_PERM,FSC_ACCESS三种类型的话,直接返回错误; gfn_to_memslot,gfn_to_hva_memslot_prot这两个函数,是根据IPA去获取到对应的memslot和HVA地址,这个地方就对应到了上文中第二章节中地址关系的建立了,由于建立了连接关系,便可以通过IPA去找到对应的HVA;- 如果注册了RAM,能获取到正确的HVA,如果是IO内存访问,那么HVA将会被设置成
KVM_HVA_ERR_BAD。kvm_is_error_hva或者(write_fault && !writable)代表两种错误:1)指令错误,向Guest注入指令异常;2)IO访问错误,IO访问又存在两种情况:2.1)Cache维护指令,则直接跳过该指令;2.2)正常的IO操作指令,调用io_mem_abort进行IO模拟操作; handle_access_fault用于处理访问权限问题,如果内存页无法访问,则对其权限进行更新;user_mem_abort,用于分配更多的内存,实际上就是完成Stage 2页表映射的建立,根据异常的IPA地址,已经对应的HVA,建立映射,细节的地方就不表了。
int kvm_handle_guest_abort(struct kvm_vcpu *vcpu, struct kvm_run *run)
{
unsigned long fault_status;
phys_addr_t fault_ipa;
struct kvm_memory_slot *memslot;
memslot = gfn_to_memslot(vcpu->kvm, gfn);
hva = gfn_to_hva_memslot_prot(memslot, gfn, &writable);
ret = user_mem_abort(vcpu, fault_ipa, memslot, hva, fault_status);
}
kvm_handle_guest_abort() -->
user_mem_abort()--> {
...
0. checks the vma->flags for the VM_PFNMAP.
1. Since VM_PFNMAP flag is not yet set so force_pte _is_ false;
2. gfn_to_pfn_prot() -->
__gfn_to_pfn_memslot() -->
fixup_user_fault() -->
handle_mm_fault()-->
__do_fault() -->
vma_mmio_fault() --> // vendor's mdev fault handler
remap_pfn_range()--> // Here sets the VM_PFNMAP
flag into vma->flags.
3. Now that force_pte is set to false in step-2),
will execute transparent_hugepage_adjust() func and
that lead to Oops [4].
}
内存初始化
memory_listener_register注册了listener,但是addressspace尚未初始化,本节就介绍下其初始化流程。从上节的configure_accelerator()函数往下走,会执行cpu_exec_init_all()函数, 该函数主要初始化了IO地址空间和系统地址空间。memory_map_init()函数初始化系统地址空间,有一个全局的MemoryRegion指针system_memory指向该区域的MemoryRegion结构
cpu_exec_init_all => memory_map_init 创建 system_memory("system") 和 system_io("io") 两个全局 MemoryRegion
=> address_space_init 初始化 address_space_memory("memory") 和 address_space_io("I/O") AddressSpace,并把 system_memory 和 system_io 作为 root
=> memory_region_transaction_commit
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1599
1599











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









