







下图显示了作为DPDK-APP的一部分运行的虚拟主机用户库如何使用virtio-device-model和virtio-pci设备与qemu和客户机进行交互:
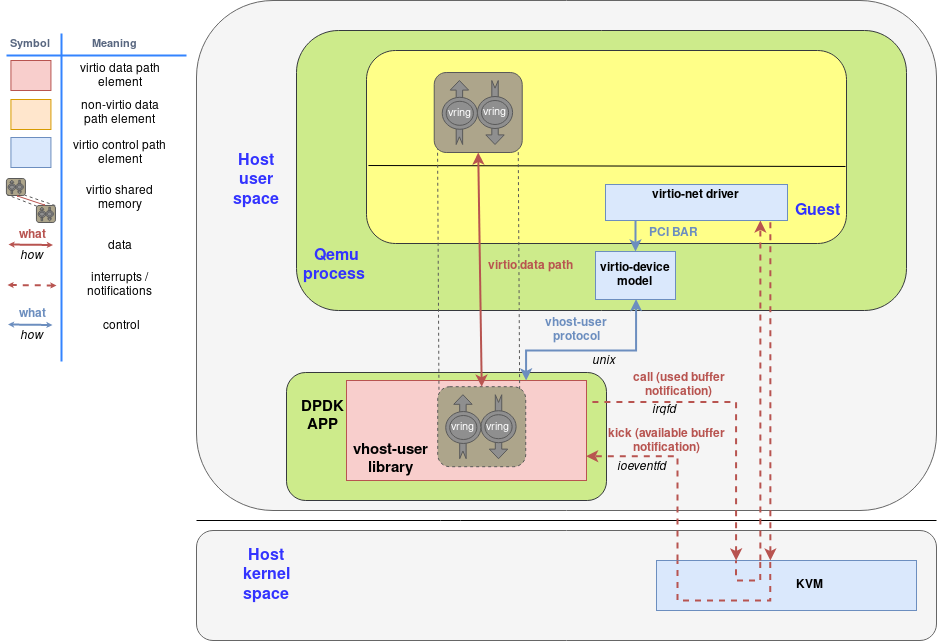
几个要点:
- virtio内存区域最初是由客户机分配的。
- 相应的virtio驱动程序通常通过virtio规范中定义的PCI BARs配置接口与virtio设备进行交互。
- virtio-device-model(位于QEMU内部)使用vhost-user协议配置vhost-user库,以及设置irqfd和ioeventfd文件描述符。
- 客户机分配的virtio内存区域由vhost用户库(即DPDK应用程序)映射(使用mmap 系统调用)。
- 结果是,DPDK应用程序可以直接在客户机内存中读取和写入数据包,并使用irqfd和ioeventfd机制直接对客户机发出通知。
rte_vhost_enqueue_burst通知虚拟机eventfd_write
static inline uint32_t __attribute__((always_inline))
virtio_dev_rx(struct virtio_net *dev, uint16_t queue_id,
struct rte_mbuf **pkts, uint32_t count)
{
struct vhost_virtqueue *vq;
struct vring_desc *desc;
struct rte_mbuf *buff;
/* The virtio_hdr is initialised to 0. */
struct virtio_net_hdr_mrg_rxbuf virtio_hdr = {
{0, 0, 0, 0, 0, 0}, 0};
uint64_t buff_addr = 0;
uint64_t buff_hdr_addr = 0;
uint32_t head[MAX_PKT_BURST];
uint32_t head_idx, packet_success = 0;
uint16_t avail_idx, res_cur_idx;
uint16_t res_base_idx, res_end_idx;
uint16_t free_entries;
uint8_t success = 0;
LOG_DEBUG(VHOST_DATA, "(%"PRIu64") virtio_dev_rx()\n", dev->device_fh);
if (unlikely(queue_id != VIRTIO_RXQ)) {
LOG_DEBUG(VHOST_DATA, "mq isn't supported in this version.\n");
return 0;
}
vq = dev->virtqueue[VIRTIO_RXQ];
count = (count > MAX_PKT_BURST) ? MAX_PKT_BURST : count;
/*
* As many data cores may want access to available buffers,
* they need to be reserved.
*/
do {
res_base_idx = vq->last_used_idx_res;
avail_idx = *((volatile uint16_t *)&vq->avail->idx);
free_entries = (avail_idx - res_base_idx);
/*check that we have enough buffers*/
if (unlikely(count > free_entries))
count = free_entries;
if (count == 0)
return 0;
res_end_idx = res_base_idx + count;
/* vq->last_used_idx_res is atomically updated. */
/* TODO: Allow to disable cmpset if no concurrency in application. */
success = rte_atomic16_cmpset(&vq->last_used_idx_res,
res_base_idx, res_end_idx);
} while (unlikely(success == 0));
res_cur_idx = res_base_idx;
LOG_DEBUG(VHOST_DATA, "(%"PRIu64") Current Index %d| End Index %d\n",
dev->device_fh, res_cur_idx, res_end_idx);
/* Prefetch available ring to retrieve indexes. */
rte_prefetch0(&vq->avail->ring[res_cur_idx & (vq->size - 1)]);
/* Retrieve all of the head indexes first to avoid caching issues. */
for (head_idx = 0; head_idx < count; head_idx++)
head[head_idx] = vq->avail->ring[(res_cur_idx + head_idx) &
(vq->size - 1)];
/*Prefetch descriptor index. */
rte_prefetch0(&vq->desc[head[packet_success]]);
while (res_cur_idx != res_end_idx) {
uint32_t offset = 0, vb_offset = 0;
uint32_t pkt_len, len_to_cpy, data_len, total_copied = 0;
uint8_t hdr = 0, uncompleted_pkt = 0;
/* Get descriptor from available ring */
desc = &vq->desc[head[packet_success]];
buff = pkts[packet_success];
/* Convert from gpa to vva (guest physical addr -> vhost virtual addr) */
buff_addr = gpa_to_vva(dev, desc->addr);
/* Prefetch buffer address. */
rte_prefetch0((void *)(uintptr_t)buff_addr);
/* Copy virtio_hdr to packet and increment buffer address */
buff_hdr_addr = buff_addr;
/*
* If the descriptors are chained the header and data are
* placed in separate buffers.
*/
if ((desc->flags & VRING_DESC_F_NEXT) &&
(desc->len == vq->vhost_hlen)) {
desc = &vq->desc[desc->next];
/* Buffer address translation. */
buff_addr = gpa_to_vva(dev, desc->addr);
} else {
vb_offset += vq->vhost_hlen;
hdr = 1;
}
pkt_len = rte_pktmbuf_pkt_len(buff);
data_len = rte_pktmbuf_data_len(buff);
len_to_cpy = RTE_MIN(data_len,
hdr ? desc->len - vq->vhost_hlen : desc->len);
while (total_copied < pkt_len) {
/* Copy mbuf data to buffer */
rte_memcpy((void *)(uintptr_t)(buff_addr + vb_offset),
rte_pktmbuf_mtod_offset(buff, const void *, offset),
len_to_cpy);
PRINT_PACKET(dev, (uintptr_t)(buff_addr + vb_offset),
len_to_cpy, 0);
offset += len_to_cpy;
vb_offset += len_to_cpy;
total_copied += len_to_cpy;
/* The whole packet completes */
if (total_copied == pkt_len)
break;
/* The current segment completes */
if (offset == data_len) {
buff = buff->next;
offset = 0;
data_len = rte_pktmbuf_data_len(buff);
}
/* The current vring descriptor done */
if (vb_offset == desc->len) {
if (desc->flags & VRING_DESC_F_NEXT) {
desc = &vq->desc[desc->next];
buff_addr = gpa_to_vva(dev, desc->addr);
vb_offset = 0;
} else {
/* Room in vring buffer is not enough */
uncompleted_pkt = 1;
break;
}
}
len_to_cpy = RTE_MIN(data_len - offset, desc->len - vb_offset);
};
/* Update used ring with desc information */
vq->used->ring[res_cur_idx & (vq->size - 1)].id =
head[packet_success];
/* Drop the packet if it is uncompleted */
if (unlikely(uncompleted_pkt == 1))
vq->used->ring[res_cur_idx & (vq->size - 1)].len =
vq->vhost_hlen;
else
vq->used->ring[res_cur_idx & (vq->size - 1)].len =
pkt_len + vq->vhost_hlen;
res_cur_idx++;
packet_success++;
if (unlikely(uncompleted_pkt == 1))
continue;
rte_memcpy((void *)(uintptr_t)buff_hdr_addr,
(const void *)&virtio_hdr, vq->vhost_hlen);
PRINT_PACKET(dev, (uintptr_t)buff_hdr_addr, vq->vhost_hlen, 1);
if (res_cur_idx < res_end_idx) {
/* Prefetch descriptor index. */
rte_prefetch0(&vq->desc[head[packet_success]]);
}
}
rte_compiler_barrier();
/* Wait until it's our turn to add our buffer to the used ring. */
while (unlikely(vq->last_used_idx != res_base_idx))
rte_pause();
*(volatile uint16_t *)&vq->used->idx += count;
vq->last_used_idx = res_end_idx;
/* flush used->idx update before we read avail->flags. */
rte_mb();
/* Kick the guest if necessary. */
if (!(vq->avail->flags & VRING_AVAIL_F_NO_INTERRUPT))
eventfd_write((int)vq->callfd, 1);
return count;
}eth_vhost_install_intr(struct rte_eth_dev *dev)
for (i = 0; i < nb_rxq; i++) {
vq = dev->data->rx_queues[i];
if (!vq) {
VHOST_LOG(INFO, "rxq-%d not setup yet, skip!\n", i);
continue;
}
ret = rte_vhost_get_vhost_vring(vq->vid, (i << 1) + 1, &vring);
if (ret < 0) {
VHOST_LOG(INFO,
"Failed to get rxq-%d's vring, skip!\n", i);
continue;
}
if (vring.kickfd < 0) {
VHOST_LOG(INFO,
"rxq-%d's kickfd is invalid, skip!\n", i);
continue;
}
dev->intr_handle- 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 923
923

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









