



 本文详细介绍了如何在IntelliJ IDEA中配置并利用Spark 3.1.3进行WordCount示例,包括Hadoop和Spark的安装过程,以及关键代码实现和Maven构建的整合。适合初学者理解Spark开发环境搭建。
本文详细介绍了如何在IntelliJ IDEA中配置并利用Spark 3.1.3进行WordCount示例,包括Hadoop和Spark的安装过程,以及关键代码实现和Maven构建的整合。适合初学者理解Spark开发环境搭建。
目录
大数据平台架构实战(一)hadoop搭建
大数据平台架构实战(二)IntelliJ IDEA搭建hadoop
大数据平台架构实战(三)Hive安装
大数据平台架构实战(四)Spark安装
相关的文章非常多,按照网上的步骤,总会出问题,现在更新一下最新版本的开发方法。
IntelliJ 配置
参考使用IntelliJ IDEA开发Spark应用程序_厦大数据库实验室博客
代码
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object WordCount {
def main(args: Array[String]) {
val inputFile = "/input"
val conf = new SparkConf().setAppName("WordCount").setMaster("local")
val sc = new SparkContext(conf)
val textFile = sc.textFile(inputFile)
val wordCount = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b)
wordCount.foreach(println)
}
}pom文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>spark-base</artifactId>
<version>1.0-SNAPSHOT</version>
<name>WordCount</name>
<packaging>jar</packaging>
<properties>
<cupid.sdk.version>3.3.8</cupid.sdk.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<scala.version>2.12.8</scala.version>
<scala.binary.version>2.12</scala.binary.version>
<PermGen>512m</PermGen>
<MaxPermGen>1024m</MaxPermGen>
<spark.version>3.1.3</spark.version>
<emr.version>2.0.0</emr.version>
<loghubb.client.version>0.6.13</loghubb.client.version>
</properties>
<repositories>
<repository>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.cloudera.sparkts</groupId>
<artifactId>sparkts</artifactId>
<version>0.4.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>ml.dmlc</groupId>
<artifactId>xgboost4j-spark</artifactId>
<version>0.81</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.codehaus.jackson</groupId>
<artifactId>jackson-core-asl</artifactId>
<version>1.9.13</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<minimizeJar>false</minimizeJar>
<shadedArtifactAttached>true</shadedArtifactAttached>
<artifactSet>
<includes>
<!-- Include here the dependencies you
want to be packed in your fat jar -->
<include>*:*</include>
</includes>
</artifactSet>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer">
<resource>reference.conf</resource>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<id>scala-compile-first</id>
<phase>process-resources</phase>
<goals>
<goal>compile</goal>
</goals>
</execution>
<!--
<execution>
<id>scala-test-compile-first</id>
<phase>process-test-resources</phase>
<goals>
<goal>testCompile</goal>
</goals>
</execution>
-->
<execution>
<id>attach-scaladocs</id>
<phase>verify</phase>
<goals>
<goal>doc-jar</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>打包jar
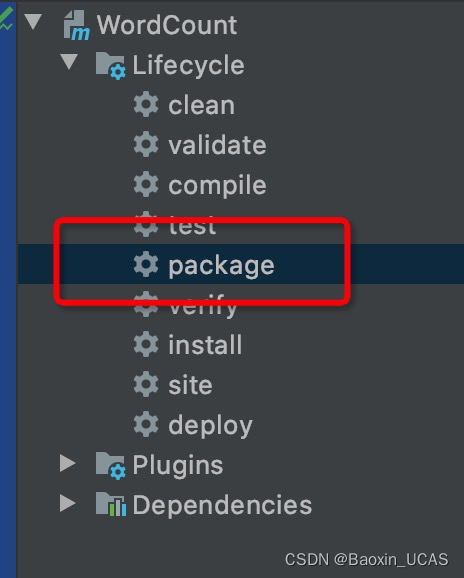
提交运行
spark-submit --class WordCount /Users/xxxx/Project/spark-base/target/spark-base-1.0-SNAPSHOT-shaded.jar 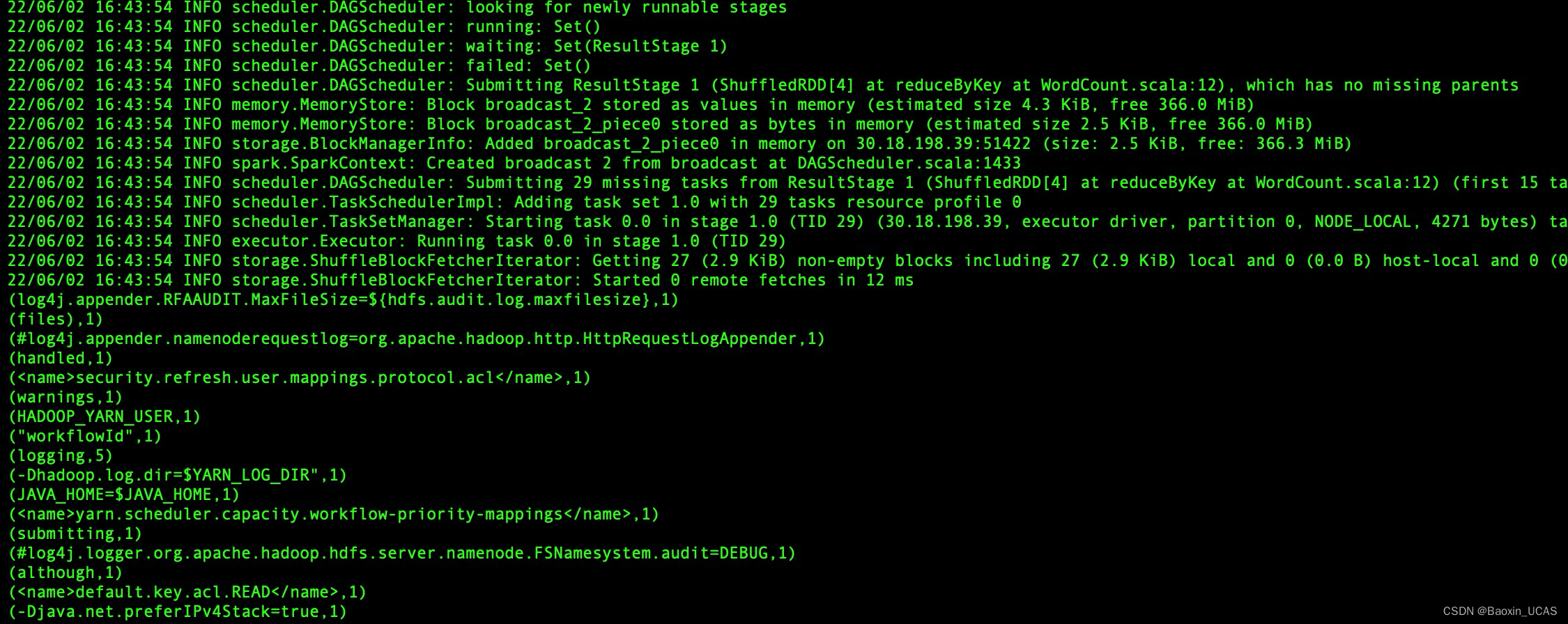

















 904
904

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









