









尚硅谷-离线数仓-笔记
一、数仓建模理论
第一章 数仓概述
1.1 数仓概念
数据仓库是一个为数据分析而设计的企业级数据管理系统。数据仓库可集中、整合多个信息源的大量数据,借助数据仓库的分析能力,企业可从数据中获得宝贵的信息进而改进决策。同时,随着时间的推移,数据仓库中积累的大量历史数据对于数据科学家和业务分析师也是十分宝贵的。
数据仓库( Data Warehouse ),是为企业所有决策制定过程,提供所有系统数据支持的战略集合。
通过对数据仓库中数据的分析,可以帮助企业,改进业务流程、控制成本、提高产品质量等。
数据仓库,并不是数据的最终目的地,而是为数据最终的目的地做好准备。这些准备包括对数据的:清洗,转义,分类,重组,合并,拆分,统计等等。
1.2 数仓的主要功能
- 存储(可回溯)【会保留历史数据,区别于业务数据库】
- 管理【以合理的组织结构存储,使用效率高】
- 分析(可快速查询)【为企业决策、提高效益提供支持】
1.3 数仓核心架构
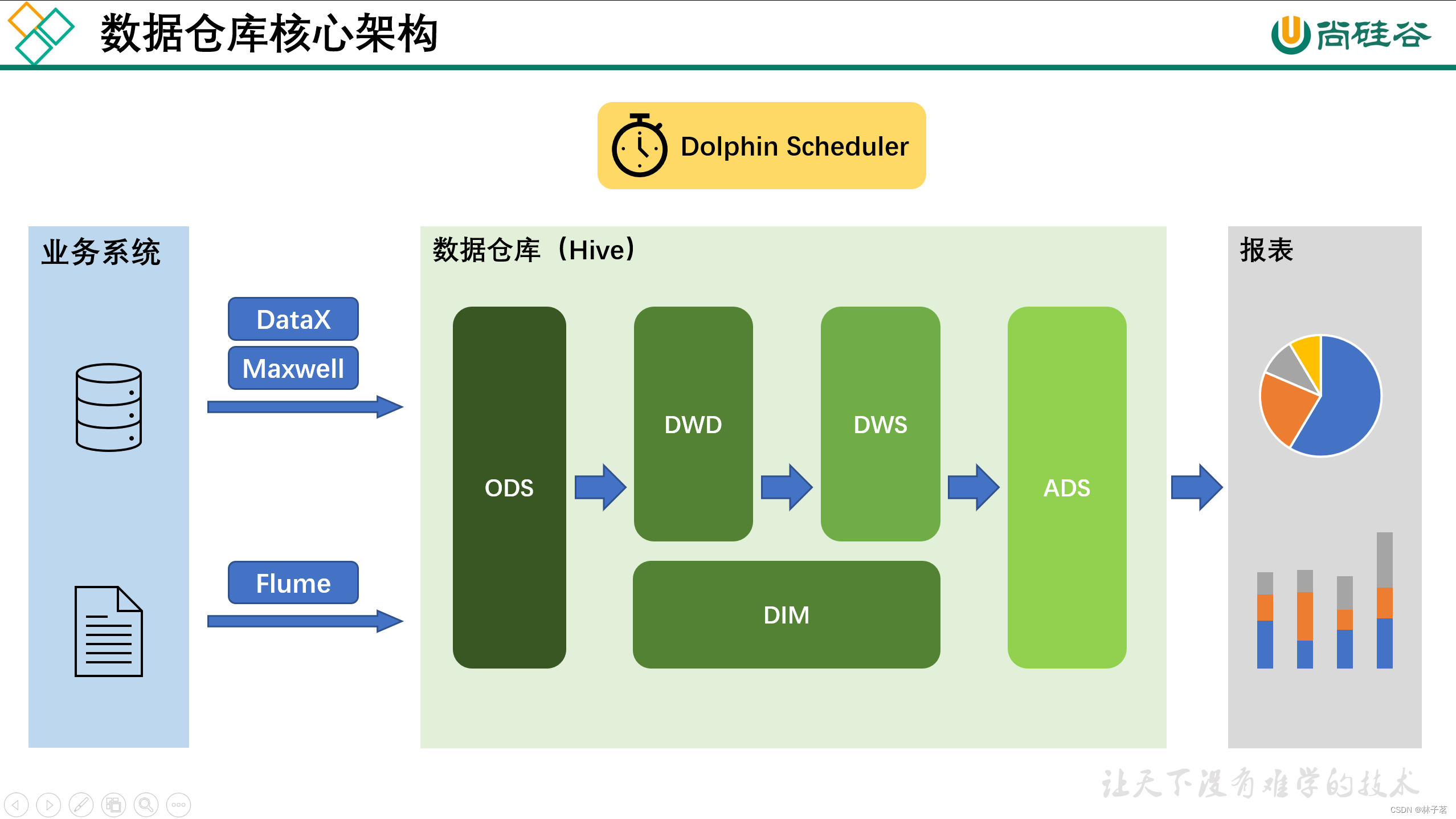
第二章 数仓建模
1.1 关系建模
用实体关系(Entity Relationship,ER)模型来描述企业业务,并用规范化的方式表示出来,在范式理论上符合3NF。
实体: 现实存在的物体。
关系: 两个实体之间的关系。例如1对1,1对N,N对N
1对1的实体对应关系可以通过外键来进行设置
1对N和N对N的实体对应关系可以通过中间表来进行设置
三范式
-
第一范式:属性不可切割
例如:
商品 –> 商品 数量 5台电脑 应改为 电脑 5 -
第二范式:不能存在部分函数依赖
错误:a, b 两列为联合主键,c 依赖于主键,d依赖于a
应改为:a, b, c 一张表,a, d 一张表
-
第三范式:不能存在传递函数依赖
有传递依赖:学号->系名->系主任
应改为:学号、系名一张表;系名、系主任一张表
1.3 对比
| ** ** | 关系建模 | 维度建模 |
|---|---|---|
| 侧重点 | 写的强一致性和消除冗余存储 | 业务查询的便捷 |
| 场景 | RDMS(Relational Database Management System)关系数据库管理系统 | 大数据分析 |
做笔记速度太慢,放弃了!
第五章
- 数仓分层的好处
- 复杂问题简单化
- 减少重复开发
- 脱敏,隔离原始数据
DWS层
DWS层建模
需求驱动
DWS层表命名规则
dws层命名规则: dws_数据域_统计粒度_业务过程_统计周期(1d/nd/td)
构建指标体系
构建指标体系的主要意义:为了指标定义标准化,避免指标歧义和重复定义
需求要根据指标体系来提,每一个需求落实到一个派生指标上。
-
原子指标
-
业务过程 -->提交订单
-
度量值 -->订单金额
-
聚合逻辑 -->sum求和
上面以 订单总额 为例
-
-
派生指标=原子指标 + 统计周期+业务限定+统计粒度 +数据来源
-
衍生指标:在一个或多个派生指标的基础上,通过各种逻辑运算复合而成的
拿到需求:1.提炼派生指标 --》2.派生指标去重 --》3.根据派生指标创建DWS层表
例子:
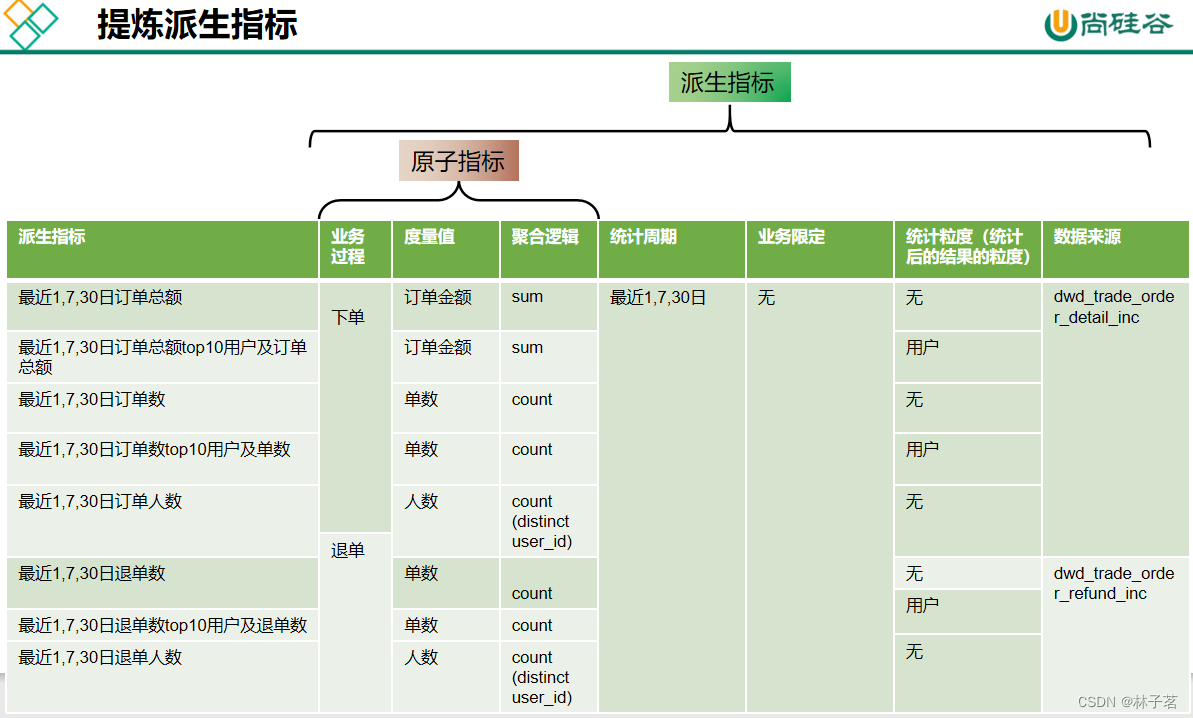

导数思路
首日: 比每日复杂,必须是动态分区!
表名: dws_数据域_粒度_业务_周期
①分析dws表所需要的字段来源
哪些是要统计的指标: dwd
哪些是对指标补充的维度: dim
②编写sql
select
字段
from
(
select
粒度,dt,
-- 聚合的每个指标的含义和细微差别 例如 单数,单次等之类的
聚合函数(聚合指标)
from dwd_业务
where dt <= '2020-06-14'
group by 粒度,
-- dwd中事实发生的日期
dt
) t1
left join
(
select
xxx
from dim_维度
where dt='2020-06-14'
)t2
on xxx
每日: 处理当天产生的事实,静态分区即可!
dws (聚合)–> dws
从dws_细粒度中 进一步聚合得到 dws_粗粒度 的条件
/*
总结: 什么情况下可以从dws_细粒度中 进一步聚合得到 dws_粗粒度?
在当前的项目中: 退单可以。 退单的单位以商品为单位进行退单,业务的粒度和统计的粒度是一样的!
下单不可以。 下单的单位以订单为单位下单,业务的粒度和统计的粒度是不一样的!
*/
在下单过程中: 下单数和下单次数 是一回事。
在退单的过程中: 退单数和退单次数就不是一回事!
退单的基本单位是以商品为单位统计!
退单数:退单的商品,所存在的订单个数
退单次数,申请了几次退单操作。 退单操作以商品为单位进行退单的,退单次数,就是申请退单的次数!
Hive On Spark中合并小文件
<property>
<name>hive.merge.sparkfiles</name>
<value>true</value> <!--默认false-->
<description>Merge small files at the end of a Spark DAG Transformation</description>
</property>
<property>
<name>hive.merge.size.per.task</name>
<value>256000000</value> <!--默认256000000=256M-->
<description>Size of merged files at the end of the job</description>
</property>
DWS统计n天(n>1) 建表两种思路
/*1.若统计的天数较少,可在字段尾标标记*/
CREATE EXTERNAL TABLE dws_trade_user_order_nd
(
`user_id` STRING COMMENT '用户id',
`order_count_7d` BIGINT COMMENT '最近7日下单次数',
`order_num_7d` BIGINT COMMENT '最近7日下单商品件数',
`order_original_amount_7d` DECIMAL(16, 2) COMMENT '最近7日下单原始金额',
`activity_reduce_amount_7d` DECIMAL(16, 2) COMMENT '最近7日下单活动优惠金额',
`coupon_reduce_amount_7d` DECIMAL(16, 2) COMMENT '最近7日下单优惠券优惠金额',
`order_total_amount_7d` DECIMAL(16, 2) COMMENT '最近7日下单最终金额',
`order_count_30d` BIGINT COMMENT '最近30日下单次数',
`order_num_30d` BIGINT COMMENT '最近30日下单商品件数',
`order_original_amount_30d` DECIMAL(16, 2) COMMENT '最近30日下单原始金额',
`activity_reduce_amount_30d` DECIMAL(16, 2) COMMENT '最近30日下单活动优惠金额',
`coupon_reduce_amount_30d` DECIMAL(16, 2) COMMENT '最近30日下单优惠券优惠金额',
`order_total_amount_30d` DECIMAL(16, 2) COMMENT '最近30日下单最终金额'
) COMMENT '交易域用户粒度订单最近n日汇总事实表';
/*2.若统计天数太多,用一个专门的字段来标记统计天数比较好,不会造成表太宽*/
CREATE EXTERNAL TABLE dws_trade_user_order_nd
(
`user_id` STRING COMMENT '用户id',
`order_count` BIGINT COMMENT '最近n日下单次数',
`order_num` BIGINT COMMENT '最近n日下单商品件数',
`order_original_amount` DECIMAL(16, 2) COMMENT '最近n日下单原始金额',
`activity_reduce_amount` DECIMAL(16, 2) COMMENT '最近n日下单活动优惠金额',
`coupon_reduce_amount` DECIMAL(16, 2) COMMENT '最近n日下单优惠券优惠金额',
`order_total_amount` DECIMAL(16, 2) COMMENT '最近n日下单最终金额',
`recent_days_n` INT COMMENT '最近n日说明'
) COMMENT '交易域用户粒度订单最近n日汇总事实表';
ADS层
导数套路
insert overwrite table ads_user_change
-- 查出截止到今天导数之前的表中的数据
select * from ads_user_change
-- union all就是直接拼接 ,union拼接后去重(group by )
--union all
-- 保证幂等性
union
-- 今天要导入到表中的数据
select
'2020-06-15',20,40;
数据集复制3份
如何把一个数据集复制3份,且每一份分别添加1,7,30
-- 第一种: 笛卡尔积
select
dt, user_churn_count,
user_back_count,
recent_days
from (select dt,
user_churn_count,
user_back_count
from ads_user_change
) t1
join
(select explode(`array`(1,7,30)) recent_days )
t2;
-- 第二种: lateral view(原理就是笛卡尔积)
select dt,
user_churn_count,
user_back_count,
recent_days
from ads_user_change
lateral view explode(`array`(1,7,30)) t2 as recent_days;
select 1 recent_days
union all
select 7 recent_days
union all
select 30 recent_days ;
7.2.1 ads_traffic_stats_by_channel
业务说明
/*名词解释
访客: 设备,主键mid_id
跳出率: 跳出会话数 / 会话总数 * 100
跳出会话: 如果一个会话仅仅有一次页面的访问,这种会话称为跳出的会话
*/
导数语句
/*导数套路,基本都按这种方法导,一定要掌握
*/
insert overwrite table ads_traffic_stats_by_channel
select * from ads_traffic_stats_by_channel
union
-- 如何把一个数据集复制为3份,再在后面拼上一列 recent_days
explain select
'2020-06-14' dt,
recent_days,
channel,
count(distinct mid_id) uv_count,
bigint(avg(during_time_1d) / 1000) avg_duration_sec,
bigint(avg(page_count_1d)) avg_page_count,
count(*) sv_count,
cast(sum(`if`(page_count_1d = 1,1,0)) / count(*) * 100 as decimal(16, 2)) bounce_rate
from dws_traffic_session_page_view_1d
-- 第二步
lateral view explode(`array`(1,7,30)) tmp as recent_days
-- 第一步: 取最近30天的数据集
-- Hive中自动开启 谓词下推(能先过滤的,一定是提前执行)的优化
-- 按照分区表过滤,属于 tablescan operator,和from一起执行
where dt>date_sub('2020-06-14',30)
-- 第三步:
and dt > date_sub('2020-06-14',recent_days)
group by channel,recent_days;
报表数据导出
-
建几张表:ADS层有几张表,当前库(gmall_report)下就建几张表
-
库中的表,字段如何去设计?
表中的数据是为了保存ADS层中的数据,因此ADS层表的字段有哪些,gmall_report库下表中的字段需要和它一一对应。
-
Mysql中的表和Hive的区别在于Mysql中的表通常都有主键,如何确定哪些字段作为主键?
主键:最主要的功能是防止数据重复,为了保证数据的唯一性
在设计表的时候,粒度也是为了体现唯一性。
举例:表中的粒度是一个用户是一行,意味着每一行都是一个唯一的用户
所以,根据要导出表的粒度就可以确定Mysql中的主键!
举例说明:
ads_traffic_stats_by_channel的粒度:一天中一个渠道在一个统计周期(1,7,30)的各种指标是一行。
主键:dt, channel, recent_days
ads_user_action的粒度:一天中一个统计周期的各种指标是一行。
主键:dt, recent_days
工作流调度平台
Ozzie:CDH平台自带。重量级(安装麻烦,使用麻烦)
Azkaban:轻量级(安装简单,使用简单)。不方便的地方(需要自己去编写flow的文件,编写之后,再打包上传)
Airflow:优势:界面美观; 缺点:python编写,报错大部分后端程序员不懂python语言,看不懂堆栈信息
Dolphin Scheduler:国产软件,已经捐赠了Apache软件基金会,孵化成功,成为一个顶级项目。
优势:1.使用简单。2.文档、交流群都是中文,方便交流,社区活跃。3.份额逐渐提升,目前最主流。
Shell脚本错误定位
找到报错的最近一个OK的表,报错的位置在这张表的下一张表。
Dolphin Scheduler
- 安装前参数配错:到安装目录下的conf/ 目录里面修改配置,通常大部分配置都在common.properties 里。修改后要分发到所有机器,保持配置一致。
面试题
1. spark sql 比hive on spark 快的原因,为什么更快却不用?
2. 为什么要区分DIM层(维度表)和DWD层(事实表),为什么不把维度全部退化到事实表中?
答:1. 首先呢,维度建模,里面就是要把这种实体的信息给单独处理出来,做一个维表嘛。那他维表里面的数据,他有的可能会发生一些变化,隔一个事情可能会变了,你如果说是你不顾一切,然后把所有的东西为表的这些维度都放到事实表里面了,那你假设你今天这个围度变了,然后后天另外一个维度变了,大后天另外一个维度又变了,那你呢?事实表是不是得不停的去刷数据啊?所以说,一般这个把把为表里面的这些维度退化到事实表,一般退化的都是那些经常不怎么变的,或者说是比如一年变一次,这些种的还好啊,你比如说像一些这种什么品类品牌啊,事业部啊。
2.像这种的一般的话,像京东他们都是一年调整一次架构吧,调整那一次,然后等到三月份四月份的时候,可能会对整个组织架构做做一次调整调整,完了之后,然后你就重刷一次数据就行了,因为有一些这种维度会退化到里面,所以说这个维度退化,你不能退化的太多,然后一定要控制好他这个退化的度,对吧,你要什么都不管,窟窿都退化过去,那你还不如把。整个数仓的数仓的这些数据全部都放一张表里面得了,为什么不要放那么大的那种宽表啊,就是为了他这种数据发生变更的时候啊,他他不会去大面积的进行回溯对吧?你不回溯的话,那我只需要把为表的数据,我按照每天取全量,然后,那我后面的数据直接关联不就完事儿了,是吧。
3.他数仓吗,数仓,他是为了支持这样一个分析的一个事情,对吧?分析一般他们都是要从各个这种维度去看不同的维度去看这种一些指标,一些度量值的对吧?那你如果是这个,你全部统一到这个实施表里面,它这个它这个维度今天变明天变呢,那他怎么分析呀?对吧,他还要他还要不停的刷数对吧,你天天你今天刷一下,明天刷一下都用不成了,你还不如就直接把它放到这个为表里面,每天同步一个分区。用了他就关联一下就完事儿啊,整个的这个数仓的稳定性也比较好,你不用每天都去动它,你每次你刷数啊,都要都有用,这种成本儿在里面,对吧,有时间成本儿也有这种啊,那种错误的这个成本儿,然后你哪次没回没回好回错怎么办。
总结回答:
维表为什么要拆出来,主要有两个重要原因
1.防止过度冗余,占存储
2.维度是可能发生变化的,耦合在事实表里,一旦发生变化不容易修改
所以才将事实表放dwd,维表放dim,本质上dwd和dim其实都属于明细,只是dim是一类特殊的dwd















 888
888











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









