







 本文展示了如何使用PyTorch实现VGG-16和VGG-19模型对CIFAR10数据集进行训练,通过详细配置和优化过程,模型达到了超过ReActNet-18的准确率,达到92.23%。
本文展示了如何使用PyTorch实现VGG-16和VGG-19模型对CIFAR10数据集进行训练,通过详细配置和优化过程,模型达到了超过ReActNet-18的准确率,达到92.23%。
PyTorch搭建VGGNet模型
CIFAR10数据集(准确率排行)
目前准确率超过了2021年提出的ReActNet-18模型VGG-16:
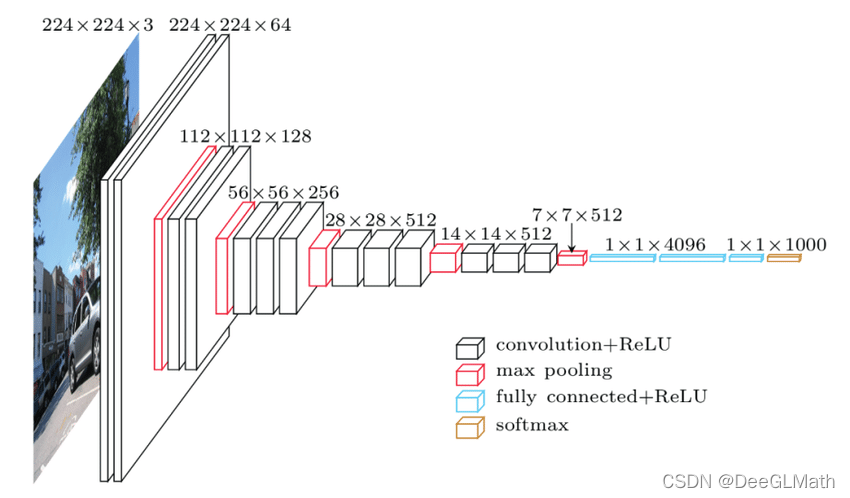
VGGNet(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(7): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(9): ReLU(inplace=True)
(10): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(12): ReLU(inplace=True)
(13): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(14): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(16): ReLU(inplace=True)
(17): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(19): ReLU(inplace=True)
(20): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(21): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(26): ReLU(inplace=True)
(27): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(28): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(29): ReLU(inplace=True)
(30): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(31): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(32): ReLU(inplace=True)
(33): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(34): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(35): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(36): ReLU(inplace=True)
(37): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(38): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(39): ReLU(inplace=True)
(40): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(41): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(42): ReLU(inplace=True)
(43): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(44): AvgPool2d(kernel_size=1, stride=1, padding=0)
)
(classifier): Linear(in_features=512, out_features=10, bias=True)
)
VGG-19:
VGGNet(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(7): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(9): ReLU(inplace=True)
(10): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(12): ReLU(inplace=True)
(13): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(14): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(16): ReLU(inplace=True)
(17): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(19): ReLU(inplace=True)
(20): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(21): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(22): ReLU(inplace=True)
(23): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(24): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(25): ReLU(inplace=True)
(26): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(27): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(28): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(29): ReLU(inplace=True)
(30): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(31): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(32): ReLU(inplace=True)
(33): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(34): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(35): ReLU(inplace=True)
(36): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(37): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(38): ReLU(inplace=True)
(39): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(40): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(41): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(42): ReLU(inplace=True)
(43): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(44): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(45): ReLU(inplace=True)
(46): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(47): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(48): ReLU(inplace=True)
(49): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(50): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(51): ReLU(inplace=True)
(52): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(53): AvgPool2d(kernel_size=1, stride=1, padding=0)
)
(classifier): Linear(in_features=512, out_features=10, bias=True)
)
# import packages
import torch
import torchvision
# Device configuration.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# Hyper-parameters
num_epochs = 80
batch_size = 100
learning_rate = 0.001
num_classes = 10
# Transform configuration and Data Augmentation.
transform_train = torchvision.transforms.Compose([torchvision.transforms.Pad(4),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.RandomCrop(32),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])
transform_test = torchvision.transforms.Compose([torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])
# Load downloaded dataset.
train_dataset = torchvision.datasets.CIFAR10('data/CIFAR/', download=False, train=True, transform=transform_train)
test_dataset = torchvision.datasets.CIFAR10('data/CIFAR/', download=False, train=False, transform=transform_test)
# Data Loader.
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False)
# Define VGG-16 and VGG-19.
cfg = {
'VGG-16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'VGG-19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512,'M']
}
# VGG-16 and VGG-19
class VGGNet(torch.nn.Module):
def __init__(self, VGG_type, num_classes):
super(VGGNet, self).__init__()
self.features = self._make_layers(cfg[VGG_type])
self.classifier = torch.nn.Linear(512, num_classes)
def forward(self, x):
out = self.features(x)
out = out.view(out.size(0), -1)
out = self.classifier(out)
return out
def _make_layers(self, cfg):
layers = []
in_channels = 3
for x in cfg:
if x == 'M': # MaxPool2d
layers += [torch.nn.MaxPool2d(kernel_size=2, stride=2)]
else:
layers += [torch.nn.Conv2d(in_channels, x, kernel_size=3, padding=1),
torch.nn.BatchNorm2d(x),
torch.nn.ReLU(inplace=True)]
in_channels = x
layers += [torch.nn.AvgPool2d(kernel_size=1, stride=1)]
return torch.nn.Sequential(*layers) # The number of parameters is more than one.
# Make model.
net_name = 'VGG-16'
# net_name = 'VGG-19'
model = VGGNet(net_name, num_classes).to(device)
# Loss ans optimizer.
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# For updating learning rate.
def update_lr(optimizer, lr):
for param_group in optimizer.param_groups:
param_group['lr'] = lr
# Train the model
import gc
total_step = len(train_loader)
curr_lr = learning_rate
for epoch in range(num_epochs):
gc.collect()
torch.cuda.empty_cache()
for i, (images, labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
# Forward pass
outputs = model(images)
loss = criterion(outputs, labels)
# Backward and optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % 100 == 0:
print ('Epoch [{}/{}], Step [{}/{}], Loss {:.4f}'.format(epoch+1, num_epochs, i+1, total_step, loss.item()))
# Decay learning rate
if (epoch+1) % 20 == 0:
curr_lr /= 3
update_lr(optimizer, curr_lr)
Epoch [1/80], Step [100/500], Loss 1.8165
Epoch [1/80], Step [200/500], Loss 1.6665
Epoch [1/80], Step [300/500], Loss 1.5102
Epoch [1/80], Step [400/500], Loss 1.3168
Epoch [1/80], Step [500/500], Loss 1.3168
Epoch [2/80], Step [100/500], Loss 1.1777
Epoch [2/80], Step [200/500], Loss 1.0226
Epoch [2/80], Step [300/500], Loss 1.0651
Epoch [2/80], Step [400/500], Loss 0.9580
Epoch [2/80], Step [500/500], Loss 0.8674
Epoch [3/80], Step [100/500], Loss 0.8783
Epoch [3/80], Step [200/500], Loss 0.7673
Epoch [3/80], Step [300/500], Loss 0.9451
Epoch [3/80], Step [400/500], Loss 1.0446
Epoch [3/80], Step [500/500], Loss 0.7531
Epoch [4/80], Step [100/500], Loss 0.6678
Epoch [4/80], Step [200/500], Loss 0.9168
Epoch [4/80], Step [300/500], Loss 0.5116
Epoch [4/80], Step [400/500], Loss 0.7929
Epoch [4/80], Step [500/500], Loss 0.7686
Epoch [5/80], Step [100/500], Loss 0.6712
Epoch [5/80], Step [200/500], Loss 0.6203
Epoch [5/80], Step [300/500], Loss 0.6114
Epoch [5/80], Step [400/500], Loss 0.6016
Epoch [5/80], Step [500/500], Loss 0.6058
Epoch [6/80], Step [100/500], Loss 0.5192
Epoch [6/80], Step [200/500], Loss 0.5720
Epoch [6/80], Step [300/500], Loss 0.4808
Epoch [6/80], Step [400/500], Loss 0.4696
Epoch [6/80], Step [500/500], Loss 0.7906
Epoch [7/80], Step [100/500], Loss 0.6197
Epoch [7/80], Step [200/500], Loss 0.6468
Epoch [7/80], Step [300/500], Loss 0.5682
Epoch [7/80], Step [400/500], Loss 0.5364
Epoch [7/80], Step [500/500], Loss 0.3679
Epoch [8/80], Step [100/500], Loss 0.3896
Epoch [8/80], Step [200/500], Loss 0.2853
Epoch [8/80], Step [300/500], Loss 0.3784
Epoch [8/80], Step [400/500], Loss 0.5404
Epoch [8/80], Step [500/500], Loss 0.4082
Epoch [9/80], Step [100/500], Loss 0.4143
Epoch [9/80], Step [200/500], Loss 0.4236
Epoch [9/80], Step [300/500], Loss 0.3737
Epoch [9/80], Step [400/500], Loss 0.3568
Epoch [9/80], Step [500/500], Loss 0.5423
Epoch [10/80], Step [100/500], Loss 0.2065
Epoch [10/80], Step [200/500], Loss 0.4200
Epoch [10/80], Step [300/500], Loss 0.2720
Epoch [10/80], Step [400/500], Loss 0.3715
Epoch [10/80], Step [500/500], Loss 0.2756
Epoch [11/80], Step [100/500], Loss 0.2904
Epoch [11/80], Step [200/500], Loss 0.2404
Epoch [11/80], Step [300/500], Loss 0.3287
Epoch [11/80], Step [400/500], Loss 0.5352
Epoch [11/80], Step [500/500], Loss 0.4666
Epoch [12/80], Step [100/500], Loss 0.2814
Epoch [12/80], Step [200/500], Loss 0.2372
Epoch [12/80], Step [300/500], Loss 0.3155
Epoch [12/80], Step [400/500], Loss 0.3158
Epoch [12/80], Step [500/500], Loss 0.3677
Epoch [13/80], Step [100/500], Loss 0.2848
Epoch [13/80], Step [200/500], Loss 0.4318
Epoch [13/80], Step [300/500], Loss 0.2843
Epoch [13/80], Step [400/500], Loss 0.2184
Epoch [13/80], Step [500/500], Loss 0.4082
Epoch [14/80], Step [100/500], Loss 0.2570
Epoch [14/80], Step [200/500], Loss 0.5338
Epoch [14/80], Step [300/500], Loss 0.4729
Epoch [14/80], Step [400/500], Loss 0.4461
Epoch [14/80], Step [500/500], Loss 0.3070
Epoch [15/80], Step [100/500], Loss 0.2682
Epoch [15/80], Step [200/500], Loss 0.2941
Epoch [15/80], Step [300/500], Loss 0.3328
Epoch [15/80], Step [400/500], Loss 0.2515
Epoch [15/80], Step [500/500], Loss 0.2797
Epoch [16/80], Step [100/500], Loss 0.3277
Epoch [16/80], Step [200/500], Loss 0.3148
Epoch [16/80], Step [300/500], Loss 0.4114
Epoch [16/80], Step [400/500], Loss 0.2806
Epoch [16/80], Step [500/500], Loss 0.2255
Epoch [17/80], Step [100/500], Loss 0.1877
Epoch [17/80], Step [200/500], Loss 0.2037
Epoch [17/80], Step [300/500], Loss 0.2120
Epoch [17/80], Step [400/500], Loss 0.2242
Epoch [17/80], Step [500/500], Loss 0.2882
Epoch [18/80], Step [100/500], Loss 0.2746
Epoch [18/80], Step [200/500], Loss 0.1950
Epoch [18/80], Step [300/500], Loss 0.1089
Epoch [18/80], Step [400/500], Loss 0.2777
Epoch [18/80], Step [500/500], Loss 0.1905
Epoch [19/80], Step [100/500], Loss 0.1620
Epoch [19/80], Step [200/500], Loss 0.4182
Epoch [19/80], Step [300/500], Loss 0.1600
Epoch [19/80], Step [400/500], Loss 0.1532
Epoch [19/80], Step [500/500], Loss 0.2367
Epoch [20/80], Step [100/500], Loss 0.1545
Epoch [20/80], Step [200/500], Loss 0.1683
Epoch [20/80], Step [300/500], Loss 0.1332
Epoch [20/80], Step [400/500], Loss 0.2031
Epoch [20/80], Step [500/500], Loss 0.1870
Epoch [21/80], Step [100/500], Loss 0.1073
Epoch [21/80], Step [200/500], Loss 0.0871
Epoch [21/80], Step [300/500], Loss 0.1432
Epoch [21/80], Step [400/500], Loss 0.0362
Epoch [21/80], Step [500/500], Loss 0.0702
Epoch [22/80], Step [100/500], Loss 0.0989
Epoch [22/80], Step [200/500], Loss 0.0603
Epoch [22/80], Step [300/500], Loss 0.1718
Epoch [22/80], Step [400/500], Loss 0.1000
Epoch [22/80], Step [500/500], Loss 0.1331
Epoch [23/80], Step [100/500], Loss 0.0938
Epoch [23/80], Step [200/500], Loss 0.0310
Epoch [23/80], Step [300/500], Loss 0.0607
Epoch [23/80], Step [400/500], Loss 0.0487
Epoch [23/80], Step [500/500], Loss 0.0967
Epoch [24/80], Step [100/500], Loss 0.0583
Epoch [24/80], Step [200/500], Loss 0.2284
Epoch [24/80], Step [300/500], Loss 0.1072
Epoch [24/80], Step [400/500], Loss 0.0636
Epoch [24/80], Step [500/500], Loss 0.0373
Epoch [25/80], Step [100/500], Loss 0.0505
Epoch [25/80], Step [200/500], Loss 0.0499
Epoch [25/80], Step [300/500], Loss 0.0484
Epoch [25/80], Step [400/500], Loss 0.0741
Epoch [25/80], Step [500/500], Loss 0.0334
Epoch [26/80], Step [100/500], Loss 0.1052
Epoch [26/80], Step [200/500], Loss 0.0738
Epoch [26/80], Step [300/500], Loss 0.0862
Epoch [26/80], Step [400/500], Loss 0.1336
Epoch [26/80], Step [500/500], Loss 0.0827
Epoch [27/80], Step [100/500], Loss 0.0778
Epoch [27/80], Step [200/500], Loss 0.1204
Epoch [27/80], Step [300/500], Loss 0.0913
Epoch [27/80], Step [400/500], Loss 0.0406
Epoch [27/80], Step [500/500], Loss 0.1939
Epoch [28/80], Step [100/500], Loss 0.0312
Epoch [28/80], Step [200/500], Loss 0.0117
Epoch [28/80], Step [300/500], Loss 0.0375
Epoch [28/80], Step [400/500], Loss 0.0828
Epoch [28/80], Step [500/500], Loss 0.0752
Epoch [29/80], Step [100/500], Loss 0.0120
Epoch [29/80], Step [200/500], Loss 0.1047
Epoch [29/80], Step [300/500], Loss 0.1122
Epoch [29/80], Step [400/500], Loss 0.0986
Epoch [29/80], Step [500/500], Loss 0.0858
Epoch [30/80], Step [100/500], Loss 0.0258
Epoch [30/80], Step [200/500], Loss 0.0247
Epoch [30/80], Step [300/500], Loss 0.0478
Epoch [30/80], Step [400/500], Loss 0.0112
Epoch [30/80], Step [500/500], Loss 0.0597
Epoch [31/80], Step [100/500], Loss 0.0545
Epoch [31/80], Step [200/500], Loss 0.0378
Epoch [31/80], Step [300/500], Loss 0.0813
Epoch [31/80], Step [400/500], Loss 0.1018
Epoch [31/80], Step [500/500], Loss 0.0248
Epoch [32/80], Step [100/500], Loss 0.0679
Epoch [32/80], Step [200/500], Loss 0.0644
Epoch [32/80], Step [300/500], Loss 0.0325
Epoch [32/80], Step [400/500], Loss 0.0238
Epoch [32/80], Step [500/500], Loss 0.0830
Epoch [33/80], Step [100/500], Loss 0.0190
Epoch [33/80], Step [200/500], Loss 0.0180
Epoch [33/80], Step [300/500], Loss 0.0827
Epoch [33/80], Step [400/500], Loss 0.1390
Epoch [33/80], Step [500/500], Loss 0.0427
Epoch [34/80], Step [100/500], Loss 0.0126
Epoch [34/80], Step [200/500], Loss 0.0341
Epoch [34/80], Step [300/500], Loss 0.0201
Epoch [34/80], Step [400/500], Loss 0.0566
Epoch [34/80], Step [500/500], Loss 0.0629
Epoch [35/80], Step [100/500], Loss 0.0606
Epoch [35/80], Step [200/500], Loss 0.0093
Epoch [35/80], Step [300/500], Loss 0.0160
Epoch [35/80], Step [400/500], Loss 0.0595
Epoch [35/80], Step [500/500], Loss 0.0554
Epoch [36/80], Step [100/500], Loss 0.0575
Epoch [36/80], Step [200/500], Loss 0.0414
Epoch [36/80], Step [300/500], Loss 0.0429
Epoch [36/80], Step [400/500], Loss 0.0510
Epoch [36/80], Step [500/500], Loss 0.0522
Epoch [37/80], Step [100/500], Loss 0.0481
Epoch [37/80], Step [200/500], Loss 0.0698
Epoch [37/80], Step [300/500], Loss 0.0329
Epoch [37/80], Step [400/500], Loss 0.0207
Epoch [37/80], Step [500/500], Loss 0.0221
Epoch [38/80], Step [100/500], Loss 0.0317
Epoch [38/80], Step [200/500], Loss 0.1042
Epoch [38/80], Step [300/500], Loss 0.0206
Epoch [38/80], Step [400/500], Loss 0.0192
Epoch [38/80], Step [500/500], Loss 0.0287
Epoch [39/80], Step [100/500], Loss 0.0617
Epoch [39/80], Step [200/500], Loss 0.0201
Epoch [39/80], Step [300/500], Loss 0.0442
Epoch [39/80], Step [400/500], Loss 0.0038
Epoch [39/80], Step [500/500], Loss 0.1216
Epoch [40/80], Step [100/500], Loss 0.0266
Epoch [40/80], Step [200/500], Loss 0.0258
Epoch [40/80], Step [300/500], Loss 0.0866
Epoch [40/80], Step [400/500], Loss 0.1102
Epoch [40/80], Step [500/500], Loss 0.0285
Epoch [41/80], Step [100/500], Loss 0.0079
Epoch [41/80], Step [200/500], Loss 0.0075
Epoch [41/80], Step [300/500], Loss 0.0010
Epoch [41/80], Step [400/500], Loss 0.0063
Epoch [41/80], Step [500/500], Loss 0.0219
Epoch [42/80], Step [100/500], Loss 0.0046
Epoch [42/80], Step [200/500], Loss 0.0204
Epoch [42/80], Step [300/500], Loss 0.0379
Epoch [42/80], Step [400/500], Loss 0.1408
Epoch [42/80], Step [500/500], Loss 0.0523
Epoch [43/80], Step [100/500], Loss 0.0191
Epoch [43/80], Step [200/500], Loss 0.0007
Epoch [43/80], Step [300/500], Loss 0.0819
Epoch [43/80], Step [400/500], Loss 0.0032
Epoch [43/80], Step [500/500], Loss 0.0180
Epoch [44/80], Step [100/500], Loss 0.0439
Epoch [44/80], Step [200/500], Loss 0.0211
Epoch [44/80], Step [300/500], Loss 0.0159
Epoch [44/80], Step [400/500], Loss 0.0011
Epoch [44/80], Step [500/500], Loss 0.0375
Epoch [45/80], Step [100/500], Loss 0.0050
Epoch [45/80], Step [200/500], Loss 0.0172
Epoch [45/80], Step [300/500], Loss 0.0098
Epoch [45/80], Step [400/500], Loss 0.0011
Epoch [45/80], Step [500/500], Loss 0.0321
Epoch [46/80], Step [100/500], Loss 0.0027
Epoch [46/80], Step [200/500], Loss 0.0398
Epoch [46/80], Step [300/500], Loss 0.0342
Epoch [46/80], Step [400/500], Loss 0.0071
Epoch [46/80], Step [500/500], Loss 0.0035
Epoch [47/80], Step [100/500], Loss 0.0022
Epoch [47/80], Step [200/500], Loss 0.0043
Epoch [47/80], Step [300/500], Loss 0.0016
Epoch [47/80], Step [400/500], Loss 0.0018
Epoch [47/80], Step [500/500], Loss 0.0006
Epoch [48/80], Step [100/500], Loss 0.0059
Epoch [48/80], Step [200/500], Loss 0.0039
Epoch [48/80], Step [300/500], Loss 0.0089
Epoch [48/80], Step [400/500], Loss 0.0024
Epoch [48/80], Step [500/500], Loss 0.0020
Epoch [49/80], Step [100/500], Loss 0.0184
Epoch [49/80], Step [200/500], Loss 0.0482
Epoch [49/80], Step [300/500], Loss 0.0006
Epoch [49/80], Step [400/500], Loss 0.0047
Epoch [49/80], Step [500/500], Loss 0.0582
Epoch [50/80], Step [100/500], Loss 0.0124
Epoch [50/80], Step [200/500], Loss 0.0597
Epoch [50/80], Step [300/500], Loss 0.0611
Epoch [50/80], Step [400/500], Loss 0.0004
Epoch [50/80], Step [500/500], Loss 0.0258
Epoch [51/80], Step [100/500], Loss 0.0116
Epoch [51/80], Step [200/500], Loss 0.0196
Epoch [51/80], Step [300/500], Loss 0.0144
Epoch [51/80], Step [400/500], Loss 0.0024
Epoch [51/80], Step [500/500], Loss 0.0544
Epoch [52/80], Step [100/500], Loss 0.0176
Epoch [52/80], Step [200/500], Loss 0.0045
Epoch [52/80], Step [300/500], Loss 0.0133
Epoch [52/80], Step [400/500], Loss 0.0122
Epoch [52/80], Step [500/500], Loss 0.0020
Epoch [53/80], Step [100/500], Loss 0.0020
Epoch [53/80], Step [200/500], Loss 0.0229
Epoch [53/80], Step [300/500], Loss 0.0235
Epoch [53/80], Step [400/500], Loss 0.0006
Epoch [53/80], Step [500/500], Loss 0.0023
Epoch [54/80], Step [100/500], Loss 0.0094
Epoch [54/80], Step [200/500], Loss 0.0110
Epoch [54/80], Step [300/500], Loss 0.0076
Epoch [54/80], Step [400/500], Loss 0.0378
Epoch [54/80], Step [500/500], Loss 0.0020
Epoch [55/80], Step [100/500], Loss 0.0027
Epoch [55/80], Step [200/500], Loss 0.0086
Epoch [55/80], Step [300/500], Loss 0.0026
Epoch [55/80], Step [400/500], Loss 0.0024
Epoch [55/80], Step [500/500], Loss 0.0311
Epoch [56/80], Step [100/500], Loss 0.0030
Epoch [56/80], Step [200/500], Loss 0.0019
Epoch [56/80], Step [300/500], Loss 0.0005
Epoch [56/80], Step [400/500], Loss 0.0164
Epoch [56/80], Step [500/500], Loss 0.0080
Epoch [57/80], Step [100/500], Loss 0.0006
Epoch [57/80], Step [200/500], Loss 0.0020
Epoch [57/80], Step [300/500], Loss 0.0075
Epoch [57/80], Step [400/500], Loss 0.0286
Epoch [57/80], Step [500/500], Loss 0.0003
Epoch [58/80], Step [100/500], Loss 0.0020
Epoch [58/80], Step [200/500], Loss 0.0026
Epoch [58/80], Step [300/500], Loss 0.0077
Epoch [58/80], Step [400/500], Loss 0.0003
Epoch [58/80], Step [500/500], Loss 0.0125
Epoch [59/80], Step [100/500], Loss 0.0070
Epoch [59/80], Step [200/500], Loss 0.0048
Epoch [59/80], Step [300/500], Loss 0.0300
Epoch [59/80], Step [400/500], Loss 0.0070
Epoch [59/80], Step [500/500], Loss 0.0010
Epoch [60/80], Step [100/500], Loss 0.0028
Epoch [60/80], Step [200/500], Loss 0.0377
Epoch [60/80], Step [300/500], Loss 0.0034
Epoch [60/80], Step [400/500], Loss 0.0002
Epoch [60/80], Step [500/500], Loss 0.0078
Epoch [61/80], Step [100/500], Loss 0.0015
Epoch [61/80], Step [200/500], Loss 0.0069
Epoch [61/80], Step [300/500], Loss 0.0435
Epoch [61/80], Step [400/500], Loss 0.0008
Epoch [61/80], Step [500/500], Loss 0.0075
Epoch [62/80], Step [100/500], Loss 0.0014
Epoch [62/80], Step [200/500], Loss 0.0030
Epoch [62/80], Step [300/500], Loss 0.0036
Epoch [62/80], Step [400/500], Loss 0.0106
Epoch [62/80], Step [500/500], Loss 0.0042
Epoch [63/80], Step [100/500], Loss 0.0002
Epoch [63/80], Step [200/500], Loss 0.0004
Epoch [63/80], Step [300/500], Loss 0.0009
Epoch [63/80], Step [400/500], Loss 0.0068
Epoch [63/80], Step [500/500], Loss 0.0007
Epoch [64/80], Step [100/500], Loss 0.0073
Epoch [64/80], Step [200/500], Loss 0.0008
Epoch [64/80], Step [300/500], Loss 0.0130
Epoch [64/80], Step [400/500], Loss 0.0001
Epoch [64/80], Step [500/500], Loss 0.0010
Epoch [65/80], Step [100/500], Loss 0.0026
Epoch [65/80], Step [200/500], Loss 0.0036
Epoch [65/80], Step [300/500], Loss 0.0107
Epoch [65/80], Step [400/500], Loss 0.0000
Epoch [65/80], Step [500/500], Loss 0.0004
Epoch [66/80], Step [100/500], Loss 0.0015
Epoch [66/80], Step [200/500], Loss 0.0004
Epoch [66/80], Step [300/500], Loss 0.0089
Epoch [66/80], Step [400/500], Loss 0.0008
Epoch [66/80], Step [500/500], Loss 0.0016
Epoch [67/80], Step [100/500], Loss 0.0001
Epoch [67/80], Step [200/500], Loss 0.0004
Epoch [67/80], Step [300/500], Loss 0.0032
Epoch [67/80], Step [400/500], Loss 0.0002
Epoch [67/80], Step [500/500], Loss 0.0005
Epoch [68/80], Step [100/500], Loss 0.0002
Epoch [68/80], Step [200/500], Loss 0.0002
Epoch [68/80], Step [300/500], Loss 0.0004
Epoch [68/80], Step [400/500], Loss 0.0005
Epoch [68/80], Step [500/500], Loss 0.0004
Epoch [69/80], Step [100/500], Loss 0.0012
Epoch [69/80], Step [200/500], Loss 0.0006
Epoch [69/80], Step [300/500], Loss 0.0052
Epoch [69/80], Step [400/500], Loss 0.0007
Epoch [69/80], Step [500/500], Loss 0.0213
Epoch [70/80], Step [100/500], Loss 0.0001
Epoch [70/80], Step [200/500], Loss 0.0147
Epoch [70/80], Step [300/500], Loss 0.0792
Epoch [70/80], Step [400/500], Loss 0.0007
Epoch [70/80], Step [500/500], Loss 0.0016
Epoch [71/80], Step [100/500], Loss 0.0004
Epoch [71/80], Step [200/500], Loss 0.0027
Epoch [71/80], Step [300/500], Loss 0.0079
Epoch [71/80], Step [400/500], Loss 0.0060
Epoch [71/80], Step [500/500], Loss 0.0055
Epoch [72/80], Step [100/500], Loss 0.0003
Epoch [72/80], Step [200/500], Loss 0.0001
Epoch [72/80], Step [300/500], Loss 0.0085
Epoch [72/80], Step [400/500], Loss 0.0001
Epoch [72/80], Step [500/500], Loss 0.0000
Epoch [73/80], Step [100/500], Loss 0.0004
Epoch [73/80], Step [200/500], Loss 0.0001
Epoch [73/80], Step [300/500], Loss 0.0001
Epoch [73/80], Step [400/500], Loss 0.0006
Epoch [73/80], Step [500/500], Loss 0.0017
Epoch [74/80], Step [100/500], Loss 0.0002
Epoch [74/80], Step [200/500], Loss 0.0013
Epoch [74/80], Step [300/500], Loss 0.0001
Epoch [74/80], Step [400/500], Loss 0.0012
Epoch [74/80], Step [500/500], Loss 0.0003
Epoch [75/80], Step [100/500], Loss 0.0039
Epoch [75/80], Step [200/500], Loss 0.0001
Epoch [75/80], Step [300/500], Loss 0.0020
Epoch [75/80], Step [400/500], Loss 0.0001
Epoch [75/80], Step [500/500], Loss 0.0003
Epoch [76/80], Step [100/500], Loss 0.0051
Epoch [76/80], Step [200/500], Loss 0.0052
Epoch [76/80], Step [300/500], Loss 0.0005
Epoch [76/80], Step [400/500], Loss 0.0012
Epoch [76/80], Step [500/500], Loss 0.0035
Epoch [77/80], Step [100/500], Loss 0.0032
Epoch [77/80], Step [200/500], Loss 0.0003
Epoch [77/80], Step [300/500], Loss 0.0003
Epoch [77/80], Step [400/500], Loss 0.0015
Epoch [77/80], Step [500/500], Loss 0.0005
Epoch [78/80], Step [100/500], Loss 0.0003
Epoch [78/80], Step [200/500], Loss 0.0004
Epoch [78/80], Step [300/500], Loss 0.0809
Epoch [78/80], Step [400/500], Loss 0.0000
Epoch [78/80], Step [500/500], Loss 0.0001
Epoch [79/80], Step [100/500], Loss 0.0002
Epoch [79/80], Step [200/500], Loss 0.0014
Epoch [79/80], Step [300/500], Loss 0.0022
Epoch [79/80], Step [400/500], Loss 0.0001
Epoch [79/80], Step [500/500], Loss 0.0001
Epoch [80/80], Step [100/500], Loss 0.0002
Epoch [80/80], Step [200/500], Loss 0.0103
Epoch [80/80], Step [300/500], Loss 0.0001
Epoch [80/80], Step [400/500], Loss 0.0114
Epoch [80/80], Step [500/500], Loss 0.0324
# Test the mdoel.
model.eval()
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the model on the test images: {} %'.format(100 * correct / total))
Accuracy of the model on the test images: 92.23 %
# Accuracy of the model on the test images: 91.99 %
# Save the model checkpoint.
torch.save(model.state_dict(), 'VGG-16.ckpt')
# torch.save(model.state_dict(), 'VGG-19.ckpt')



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











