






介绍
本文介绍了执行计划的不同类型的操作,我们不会讨论应该使用或不使用哪个操作,因为本文只讨论操作的定义。如果您是一个执行计划的初学者,那么请阅读上一篇关于SQL执行计划基本概念篇。
现在,当我们知道了执行计划的类型以及如何获得执行计划的统计信息时,理解执行计划和统计信息的每一个单独输出的含义是非常重要的,这样我们才能更好地查询并提高性能。让我们来理解执行计划的操作。
下面是SQL执行计划中最常见的操作。

理解扫描和查找操作的区别。

索引和表访问
表扫描 / TABLE SCAN
表扫描操作只在表上没有任何索引且需要从表中获取所有数据时执行(不需要任何过滤器)。您可以通过以下步骤验证。
创建一个没有任何索引的表。编写任何选择语句并按Ctrl + L获得执行计划。您可以看到执行了一个表扫描操作。
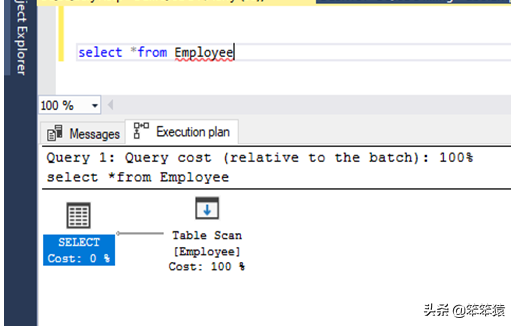
索引扫描 / INDEX SCAN
索引扫描操作仅在表具有非聚集索引的列并且需要获取该列的所有行时执行。您可以通过以下步骤验证。
创建一个非聚集索引表。写查询从表中选择column_name(创建了非聚集索引的列),按Ctrl + L获得执行计划。您可以看到索引扫描操作操作符将显示在执行计划中。
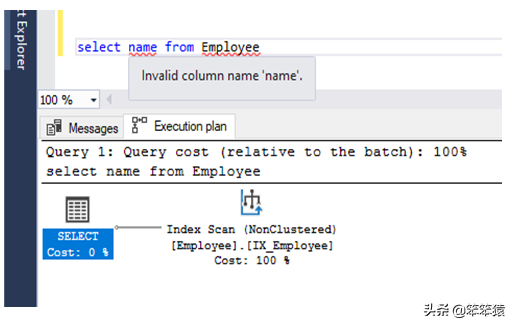
聚集索引扫描 / CLUSTERED INDEX SCAN
当写入查询以根据聚集索引读取表数据时,执行聚集索引扫描操作。让我们通过以下步骤来验证。
创建一个具有主键的表编写任何选择语句并按Ctrl+L您将能够在执行计划中看到聚集索引扫描操作符。
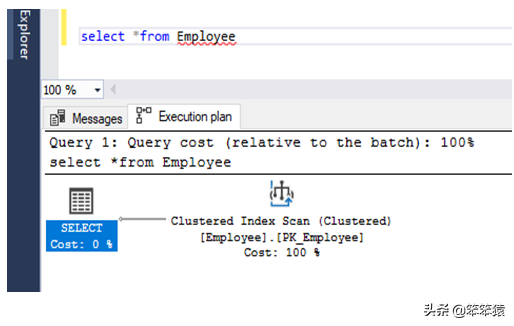
索引搜索 / INDEX SEEK
当编写查询来基于非聚集索引的列过滤记录时执行索引查找操作符,它不必读取所有表然后过滤。系统直接进入索引并根据筛选值找到所需的记录,我们做个练习。
创建一个非聚集索引表。写一个查询从列=' value '的表中选择列。(列应该与创建非聚集索引的列相同)在执行计划中的索引查找操作符中可以看到。
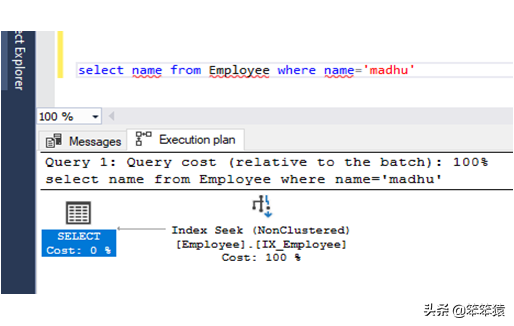
聚集索引搜索 / CLUSTERED INDEX SEEK
当需要获得过滤后的数据时,执行聚集索引查找操作。如果一个表有一个主键(聚集索引),并且我们编写一个查询来在聚集索引的帮助下过滤一些记录,那么聚集索引查找操作将会执行。
创建一个具有主键的表在主键列上写一个select语句,其中包含where子句,然后按Ctrl+L。聚集索引查找操作将执行,您将能够在执行计划中看到相同的情况。
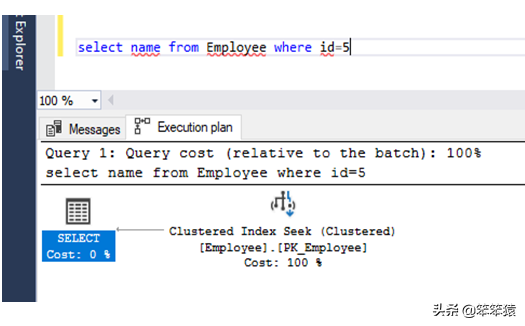
键查找(集群) / Key Lookup (Clustered)
当使用非聚集索引列过滤数据时,将执行此操作,但另外还需要其他列数据来满足此要求。注意,非聚集索引列应该是唯一的。在此操作中,系统首先根据非聚集索引列过滤记录,然后根据这些记录的主键/聚集索引使用键查找操作获取其他相关细节。当键查找百分比大于50%时,这是非常糟糕的。让我们通过一个例子来理解。
创建一个包含一些列的表Employee。在列上创建一个主键(例如ID)。在另一列上创建一个非聚集的唯一索引。现在写一个查询与where子句是使用非聚集索引列,选择任何列从表中非clusteredindexcolumn=Value'和按Ctrl+L您可以通过执行计划来验证这一点。
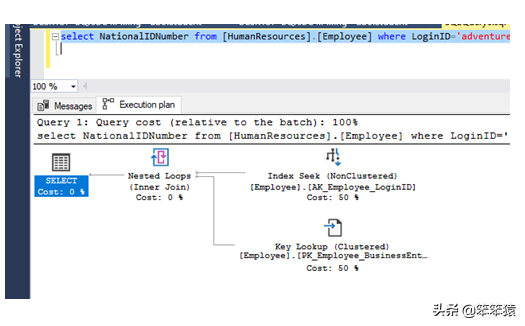
如果我解释这个执行计划,那么在这个查询中,第一个查询将在非聚集索引的基础上搜索主键,然后在聚集索引的基础上搜索其他列数据。
RID查找(堆)/ RID Lookup (Heap)
RID表示行标识符。当使用非聚集索引列过滤数据时,将执行此操作。注意,对于键查找操作,非聚集索引列也应该是唯一的。在此操作中,系统根据非聚集索引列过滤记录。当键查找百分比大于50%时,这是非常糟糕的。让我们通过一个例子来理解。
创建一个没有聚集索引的表。在任何唯一的列上创建非聚集索引。现在使用非聚集索引列编写带有where子句的搜索查询并按Ctrl+L。

连接操作
连接用于从多个表中获取数据,如果一个查询有许多连接,那么连接将按顺序执行。
下面有三种类型的连接。
嵌套循环 / NESTED LOOPS
它是最基本的连接算法。当需要来自两个表的相关数据时,我们通常使用此连接。它有两个输入和一个输出。下图是一个执行嵌套循环联接的示例。对于外部(顶部)输入中的每一行,扫描内部(底部)输入并给出匹配行的输出。
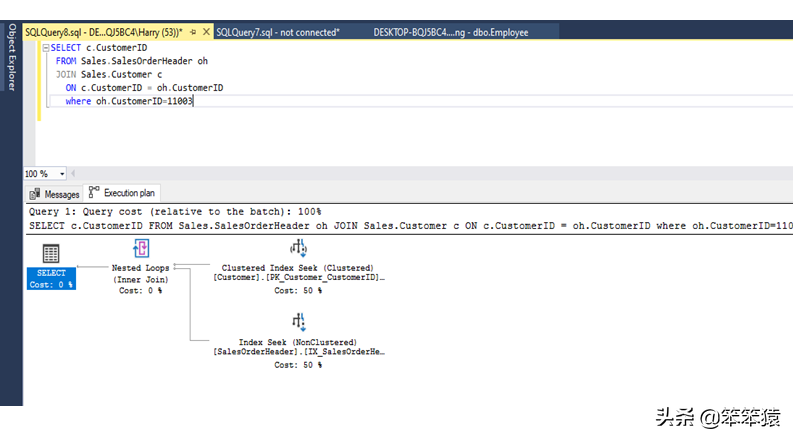
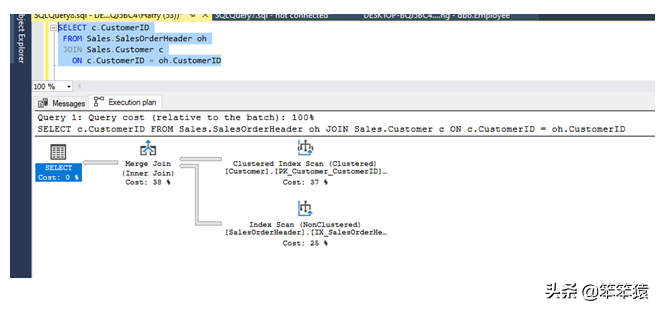
在上面的执行计划中,在CustomerID为11003的表Customer上执行一个聚集索引查找操作,对于提到的CustomerID,在内部表SalesOrderHeader上执行一个索引查找操作。
哈希匹配 / HASH MATCH
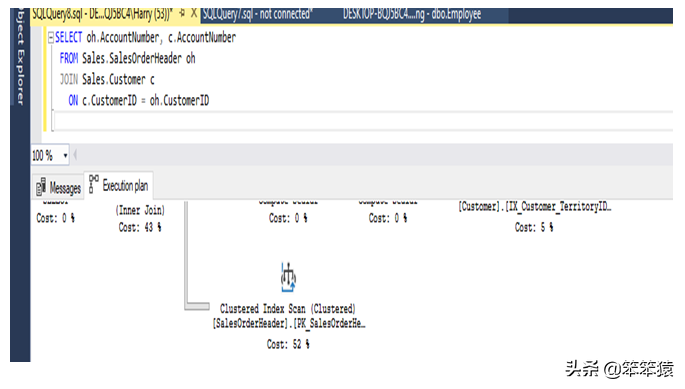
在执行哈希匹配操作时,它使用来自顶部输入的每一行构建哈希表,使用来自底部输入的每一行探测哈希表,并输出所有匹配的行。当我们想要从两个不同的表中获得匹配的数据时执行此操作:
合并连接 / MERGE JOIN
合并联接在匹配来自两个已排序输入表的行并利用它们的排序顺序时执行。简单地说,当两个表都有聚集索引并且我们在连接中使用它们来获取数据时,Sql优化器会选择合并操作符来执行查询。你可以看看下面的截图。
排序和分组
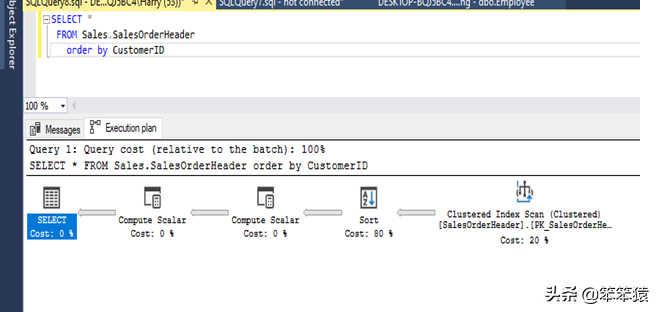
排序 / SORT
Sort操作符根据order by子句对数据进行排序。它需要大量的内存来实现中间结果。执行计划中的Sort操作符告诉我们查询优化器正在对数据进行排序。如果我运行一个带有order by子句的简单select语句,那么您将看到将执行一个排序操作,请看下面的截图。
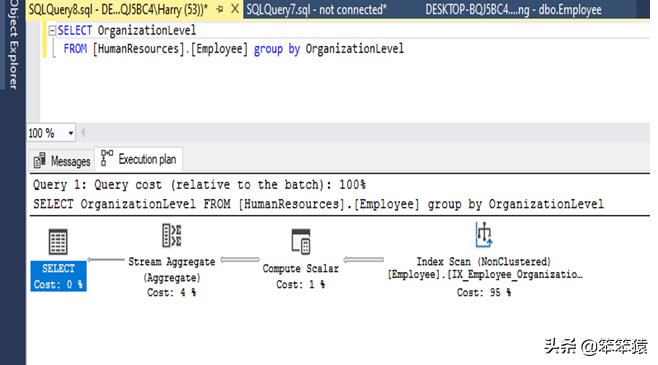
流聚集 / STREAM AGGREGATE
根据groupby子句聚合预先排序的集合,此操作符不需要缓冲中间结果,它是物理操作符来聚合数据。该操作符期望输入数据以排序的形式进行分组,如果输入是有序的,那么它就会以非常有效的方式工作。让我们看一个例子。
哈希聚合 / HASH MATCH (AGGREGATE)
哈希聚合运算符也是一个物理运算符,它通过创建哈希表来聚合数据。它的工作原理类似于散列连接来聚合数据,当输入数据行集不是排序格式时,这个操作符非常有效。它对结果进行分组,它根据一些内部选择的哈希函数在哈希表中组织组。

总结
我们已经了解了执行计划的操作,上述操作是执行计划中最常见的操作。希望这篇文章可以让您知道执行计划的基本操作,并且可以理解它。在下一篇文章中,我们将学习SQL查询执行计划的优化以及操作符,所以请继续关注。















 3998
3998











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









