









相关文章:
数据结构–图的概念
数据结构–图的连通
图搜索算法 - 深度优先搜索法(DFS)
图搜索算法 - 广度优先搜索法(BFS)
图搜索算法 - 拓扑排序
图搜索算法-最短路径算法-戴克斯特拉算法
图搜索算法-最短路径算法-贝尔曼-福特算法
图搜索算法-最小生成树问题-克鲁斯卡尔算法(kruskal)
图搜索算法-最小生成树问题-普里姆算法(prim)
图算法-网络流的最大流问题
循环图
观察循环图,脑子是非常迅速地找到了这个B-F-C-B循环,快得有些觉得理所当然,就好像1+1=2,但如果要告诉计算机怎样找出来循环,则显得困难了。你不能说看到B结点沿着箭头方向走,能回到开始的地方。因此需要算法,告诉计算机按照什么步骤去处理。
首先要解决图的表达问题,在2.7节中学习了两种方式表达图,分别是邻接矩阵和邻接列表。这里选择用邻接列表,用邻接列表表示循环图。
graph = {
'A':['J'],
'B':['A','F'],
'C':['B'],
'F':['C'],
'J':[]
}
这里为了简化定义字典的过程,引入【collections】标准库中【defaultdict】模块,它可以自定义字典的初始化值。具体是这样使用,先定义一个
【Graph】类,然后定义输入结点数据的方法add_edge()
from collections import defaultdict # 引入defaultdict
class Graph():
"""图类"""
def __init__(self):
self.graph = defaultdict(list) # 初始化图的邻接列表,自定义字典,默认值是列表
def add_edge(self,u,v):
if v:
self.graph[u].append(v) # 在u的关键字列表上添加v的值
else:
self.graph[u] = list() # 如果v没有值,添加一个空列表
若不用【defaultdict】也是可以的,但代码没有这么简洁,下面代码是等价的。
class Graph():
"""图类"""
def __init__(self):
self.graph = {} # 初始化图的邻接列表
def add_edge(self,u,v):
if v:
point = self.graph.get(u) # 尝试获取结点u
if point:
point.append(v) # 若存在直接添加u-v的边
else:
self.graph[u] = [v] # 若不存在,则先初始化u结点,然后再添加u-v的边
else:
self.graph[u] = list() # 如果v没有值,添加一个空列表
现在按上面的例子,测试输入数据是否能正确表示。
g = Graph()
g.add_edge('A', 'J')
g.add_edge('B', 'A')
g.add_edge('B', 'F')
g.add_edge('C', 'B')
g.add_edge('F', 'C')
g.add_edge('J', None)
print(g.graph)
# ------------结构-----------------
defaultdict(<class 'list'>, {'A': ['J'], 'B': ['A', 'F'], 'C': ['B'], 'F': ['C']})
注意:这是打印信息,不是说【graph】变量是这样,其实它是和字典使用方式一样。主要看内容是否正确就可以了。
然后选用深度优先搜索来检测循环,设置两个字典【visited】和【recur_stack】分别保存该结点是否已经访问和是否在递归栈中。然后设置一个规则,如果在遍历图的过程中,发现一个结点是已经访问过并且也在递归栈中,那么就能判定图中存在循环。模拟以上分析过程,首先初始化两个字典,然后从【A】结点出发,同时把【A】结点放进递归栈中得到表。
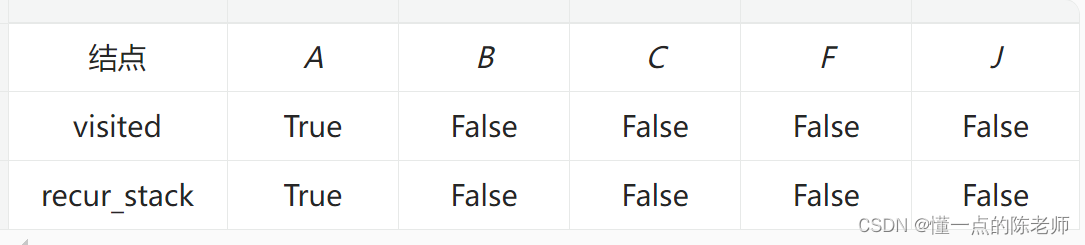
根据输入,找到【J】结点,那么这时候两个字典状态如表所示。
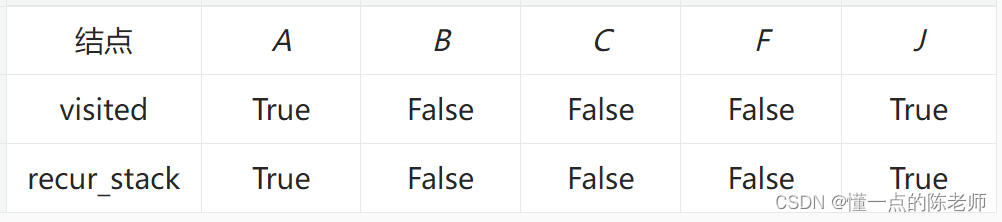
因为【J】结点没有连接的结点,因此搜索回到【A】结点,【J】结点也就退出递归栈。然后发现【A】结点也没有其他新结点,那么同样退出递归栈,接着访问【B】结点,如表所示。

根据输入,找到【A】结点,但因为它已经访问过,并且也不在递归栈中,那么就继续下一个结点【F】,因为【F】结点没有访问过,所以要进一步访问它的值,同理把它变为已访问并且放到递归栈中,如表所示。

同理通过【F】结点,找到了未被访问的【C】结点,然后通过同样操作,进入【C】结点,这个时候【C】结点中发现了【B】结点,它已经被访问了并且还在递归栈中,如表所示。

这个时候可以递归返回结果,告诉大家已经找到了图中的循环。最后来看此算法的复杂度,这是基于深度优先搜索算法而设计的,因此时间复杂度也是一样。如果图中有N个结点,E条边,在搜索过程中,由于用邻接列表表示图,所以查找所有结点的邻接结点所需时间为O(E),访问结点的邻接点所花时间为O(N),总的时间复杂度为O(N+E)。空间复杂度主要看递归深度,因此它的复杂度为O(N)。
现在用代码来表现此算法,【GraphCycle】类继承【Graph】类包含导入数据的过程,is_cyclic()函数是算法主程序,检验每条路径是否存在循环。
class GraphCycle(Graph):
def is_cyclic_tool(self, v, visited, recur_statck):
visited[v] = True # 当前结点已访问
recur_statck[v] = True # 当前结点放进递归栈中
# 深度优先遍历每一个邻居结点,如果发现邻居是已经访问,
for neighbour in self.graph[v]:
if visited[neighbour] == False: # 如果结点没有访问,进入该结点
if self.is_cyclic_tool(neighbour, visited, recur_statck) == True:
return True # 该结点上发现循环
elif recur_statck[neighbour] == True:
return True # 该结点已访问,并且也在递归栈中,说明找到循环
recur_statck[v] = False # 该结点深度遍历完成,移出递归栈
return False
def is_cyclic(self):
# 如果有循环,回复True,否则回复False
visited = {} # 初始化参数是否已经访问
recur_statck = {} # 初始化参数是否在递归栈中
for key in self.graph.keys():
visited[key] = False # 值为未访问状态
recur_statck[key] = False # 不在递归栈中
for node in self.graph.keys(): # 遍历所有结点
if visited[node] == False: # 如果结点没有访问,进入该结点
if self.is_cyclic_tool(node, visited, recur_statck) == True:
return True # 如果发现有循环,则可以马上返回True
return False # 遍历结束后,没有找到循环,则返回False
用上面的循环图为例子来验证程序。
g = GraphCycle()
g.add_edge('A', 'J')
g.add_edge('B', 'A')
g.add_edge('B', 'F')
g.add_edge('C', 'B')
g.add_edge('F', 'C')
g.add_edge('J', None)
g.is_cyclic() # 输出 True
再尝试有向无环图,观察结果是否为【False】。
g = GraphCycle()
g.add_edge('A', 'J')
g.add_edge('B', 'A')
g.add_edge('B', 'F')
g.add_edge('C', 'B')
g.add_edge('F', None)
g.add_edge('J', None)
g.is_cyclic() # 输出 False
更多内容
想获取完整代码或更多相关图的算法内容,请查看我的书籍:《数据结构和算法基础Python语言实现》














 3455
3455











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









