







 本教程详细介绍了如何使用Hadoop MapReduce对学生信息进行排序。首先,创建一个包含学生信息的文本文件并上传到HDFS。然后,创建Maven项目,添加相关依赖,配置日志属性文件,定义学生实体类并实现序列化比较接口。接着,创建Mapper、Reducer类处理数据,最后通过Driver类启动作业,实现年龄降序排序。在拓展练习中,任务改为实现性别升序、年龄降序排序。
本教程详细介绍了如何使用Hadoop MapReduce对学生信息进行排序。首先,创建一个包含学生信息的文本文件并上传到HDFS。然后,创建Maven项目,添加相关依赖,配置日志属性文件,定义学生实体类并实现序列化比较接口。接着,创建Mapper、Reducer类处理数据,最后通过Driver类启动作业,实现年龄降序排序。在拓展练习中,任务改为实现性别升序、年龄降序排序。
一、实战概述
本教程介绍了通过Hadoop MapReduce实现学生信息排序任务的步骤。
- 首先,在Hadoop上创建一个sortstudent目录,并将包含学生信息的student.txt文件上传到HDFS的/sortstudent/input目录中。
- 接着,创建Maven项目SortStudent,添加hadoop和junit依赖,配置日志属性文件。
- 在net.hw.mr包下创建Student类实现序列化比较接口,设置性别升序、年龄降序的比较规则。
- 随后,创建StudentMapper和StudentReducer类进行数据处理和排序。
- 在StudentDriver类中设置作业配置并运行。
在拓展练习中,我们将修改Student类的比较规则以实现性别升序、年龄降序排序,最后重新运行StudentDriver查看结果。通过这个实践教程,我们深入浅出地了解了MapReduce的基本原理和应用,并领略了它在大数据处理中的强大魅力。
二、提出任务
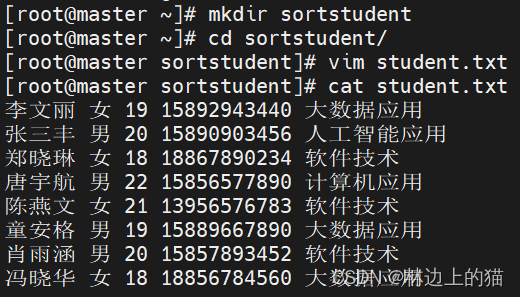
- 学生表,包含五个字段(姓名、性别、年龄、手机、专业),有8条记录。
| 姓名 | 性别 | 年龄 | 手机 | 专业 |
|---|---|---|---|---|
| 李文丽 | 女 | 19 | 15892943440 | 大数据应用 |
| 张三丰 | 男 | 20 | 15890903456 | 人工智能应用 |
| 郑晓琳 | 女 | 18 | 18867890234 | 软件技术 |
| 唐宇航 | 男 | 22 | 15856577890 | 计算机应用 |
| 陈燕文 | 女 | 21 | 13956576783 | 软件技术 |
| 童安格 | 男 | 19 | 15889667890 | 大数据应用 |
| 肖雨涵 | 男 | 20 | 15857893452 | 软件技术 |
| 冯晓华 | 女 | 18 | 18856784560 | 大数据应用 |
三、完成任务
(一)准备数据
- 启动hadoop服务

1、在虚拟机上创建文本文件
- 创建
sortstudent目录,在里面创建student.txt文件
2、上传文件到HDFS指定目录
-
创建
/sortstudent/input目录,执行命令:hdfs dfs -mkdir -p /sortstudent/input

-
将文本文件
student.txt,上传到HDFS的/sortstudent/input目录,执行命令:hdfs dfs -put student.txt /sortstudent/input

(二)实现步骤
1、创建Maven项目
-
Maven项目 -
SortStudent
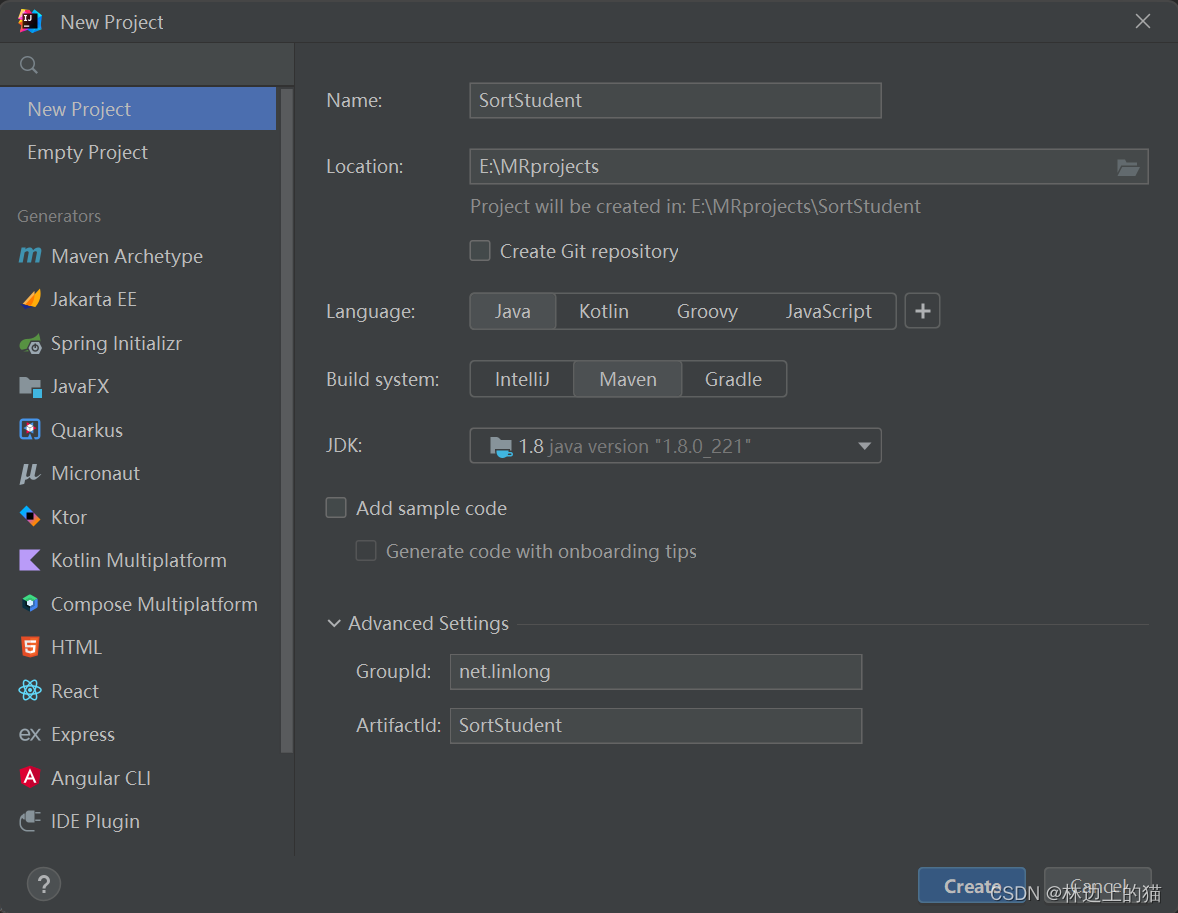
注意!!!
JDK版本要与服务器上的JDK版本一致 -
单击【Create】按钮
2、添加相关依赖
- 在
pom.xml文件里添加hadoop和junit依赖
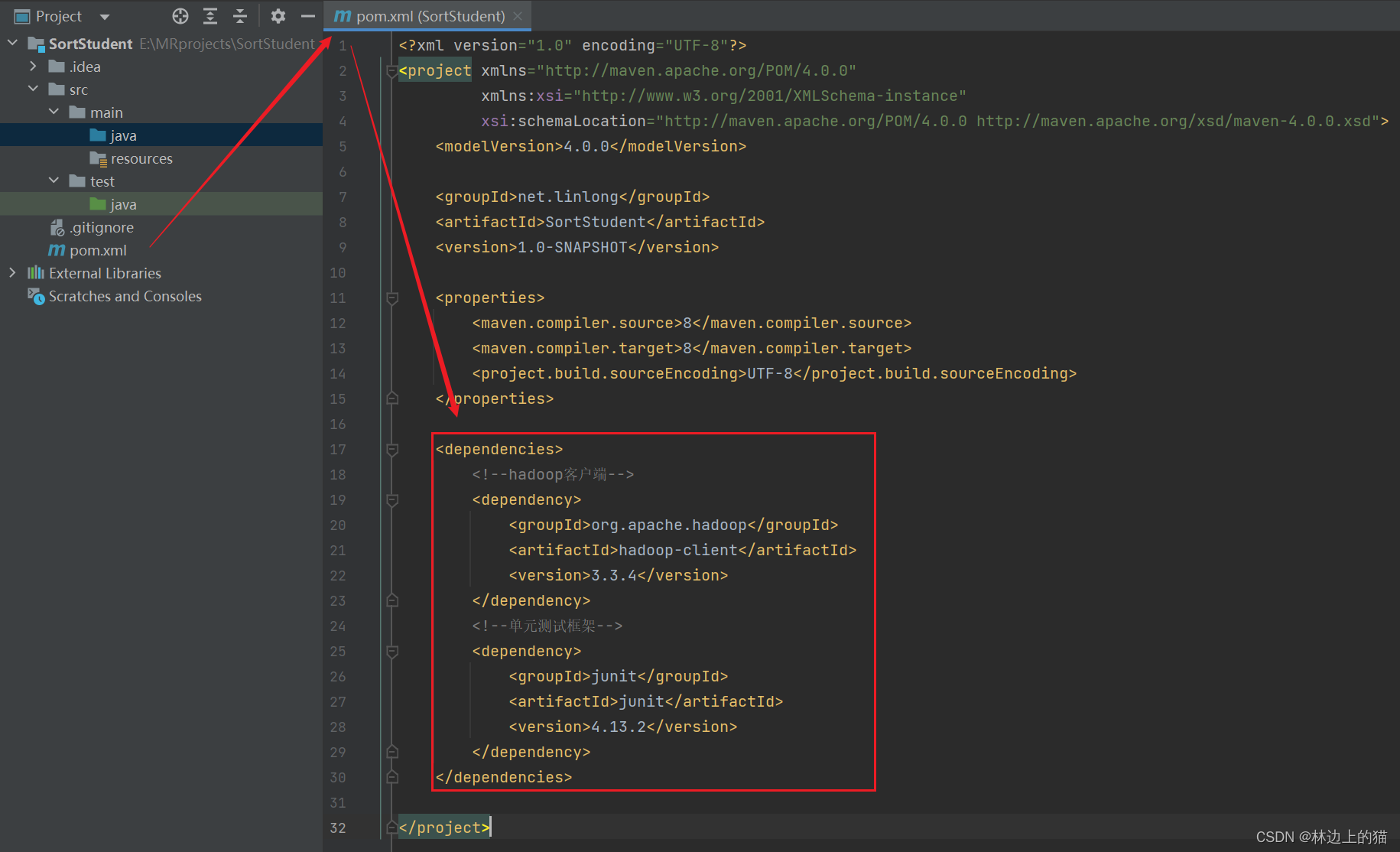
<dependencies>
<!--hadoop客户端-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.4</version>
</dependency>
<!--单元测试框架-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
</dependency>
</dependencies>
注意要进行刷新!不然依赖无法使用
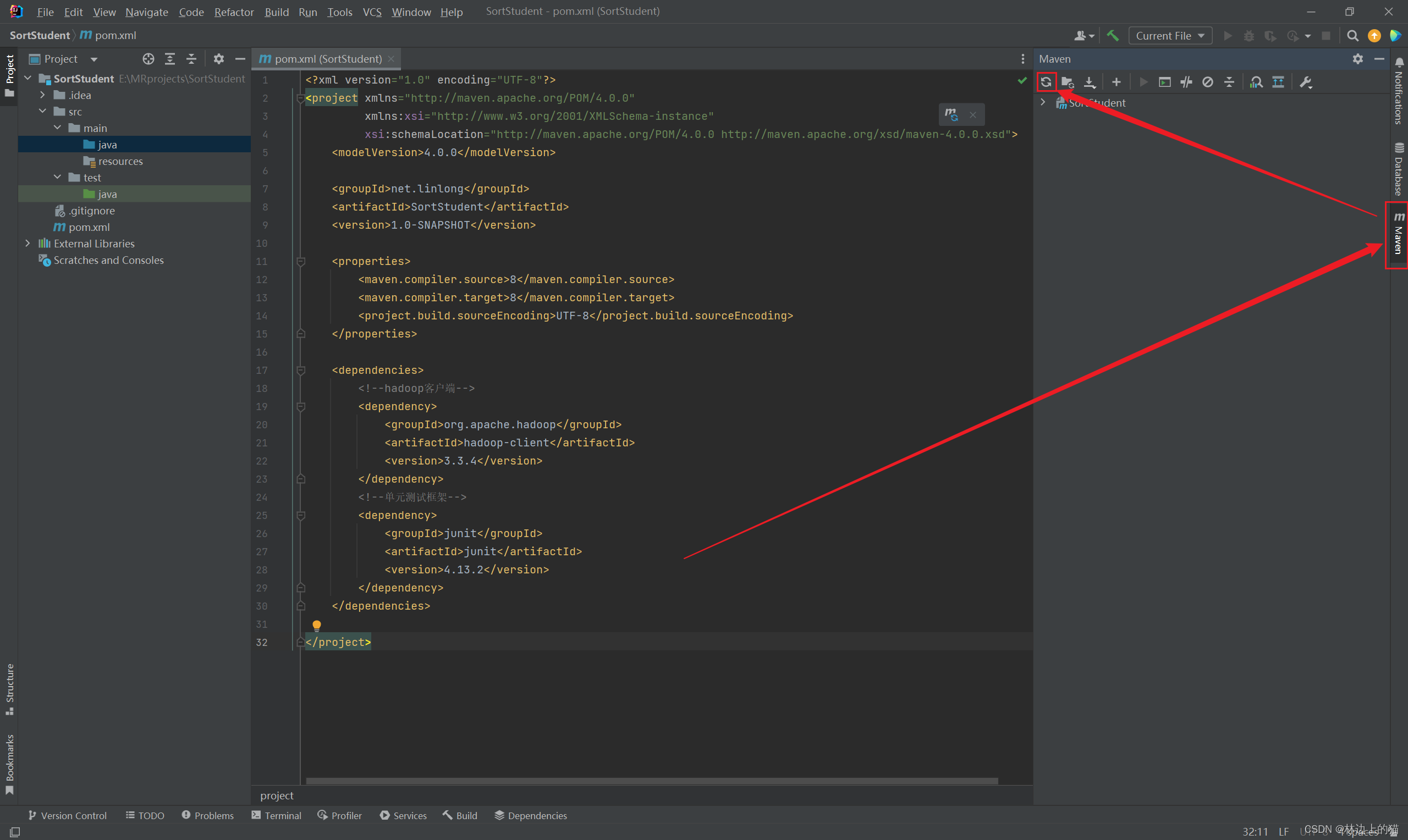
3、创建日志属性文件
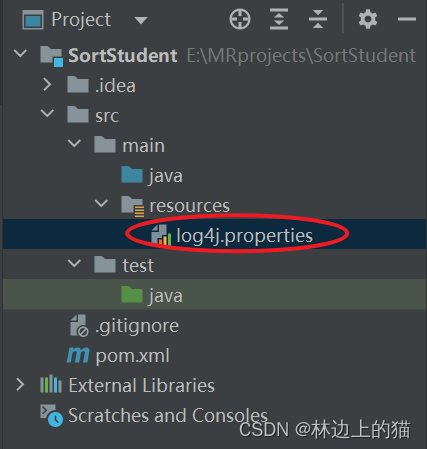
- 在
resources目录里创建log4j.properties文件
log4j.rootLogger=ERROR, stdout, logfile
log4j.appender.stdout=org.apache.log4 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









