








 超级会员免费看
超级会员免费看

 本文详细介绍了如何使用Docker-Compose无密码验证部署ZooKeeper和Kafka,包括启动ZooKeeper、查看状态、启动Kafka及配置文件详解。同时,展示了如何使用Kafka命令操作生产与消费,以及SASL验证模式的设置。最后,通过Kafka-ui实现可视化管理和配置验证,解决了消费者监听Topic时的异常问题。
本文详细介绍了如何使用Docker-Compose无密码验证部署ZooKeeper和Kafka,包括启动ZooKeeper、查看状态、启动Kafka及配置文件详解。同时,展示了如何使用Kafka命令操作生产与消费,以及SASL验证模式的设置。最后,通过Kafka-ui实现可视化管理和配置验证,解决了消费者监听Topic时的异常问题。
使用 Docker-Compose 部署 Kafka + ZooKeeper
这里使用的镜像是
bitnami的,如果使用的是其他项目下的镜像,可能环境变量的参数名不一样,不能直接照抄了,需要看下对应镜像支持的环境变量参数名,后面的值是底层使用的,应该是一样的;
1. 无密码验证部署
1.1 启动 ZooKeeper
创建挂载 zookeeper 数据的文件夹:
mkdir -p zookeeper/{conf,data,logs}
再conf文件夹下创建一个自定义配置文件zoo.cfg:
# 服务器之间或客户端与服务器之间的单次心跳检测时间间隔,单位为毫秒
tickTime=2000
# 集群中leader服务器与follower服务器第一次连接最多次数
initLimit=10
# 集群中leader服务器与follower服务器第一次连接最多次数
syncLimit=5
# 客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求
clientPort=2181
# 存放数据文件
dataDir=/opt/bitnami/zookeeper/data
# 存放日志文件
dataLogDir=/opt/bitnami/zookeeper/logs
注:如果不配置dataLogDir,那么事务日志也会写在data目录中。这样会严重影响zookeeper的性能。因为在zookeeper吞吐量很高的时候,产生的事务日志和快照日志太多。
修改文件夹权限
chown -R 1001.1001 zookeeper
使用 docker-compose.yaml
version: "3"
services:
zookeeper:
image: docker.io/bitnami/zookeeper:3.9
container_name: zookeeper
hostname: zookeeper
privileged: true
restart: always
environment:
ALLOW_ANONYMOUS_LOGIN: yes
volumes:
- ./zookeeper/data:/opt/bitnami/zookeeper/data
- ./zookeeper/logs:/opt/bitnami/zookeeper/logs
- ./zookeeper/conf/zoo.cfg:/opt/bitnami/zookeeper/conf/zoo.cfg
ports:
- "12181:2181"
deploy:
resources:
limits:
cpus: '4'
memory: 4G
reservations:
cpus: '0.5'
memory: 200M
查看启动日志如下:
[root@localhost deploy]# docker logs -f --tail 20 zookeeper
2024-05-03 03:10:19,022 [myid:] - INFO [main:o.e.j.s.AbstractConnector@333] - Started ServerConnector@4b7dc788{HTTP/1.1, (http/1.1)}{0.0.0.0:8080}
2024-05-03 03:10:19,023 [myid:] - INFO [main:o.e.j.s.Server@415] - Started @1256ms
2024-05-03 03:10:19,023 [myid:] - INFO [main:o.a.z.s.a.JettyAdminServer@201] - Started AdminServer on address 0.0.0.0, port 8080 and command URL /commands
2024-05-03 03:10:19,030 [myid:] - INFO [main:o.a.z.s.ServerCnxnFactory@169] - Using org.apache.zookeeper.server.NIOServerCnxnFactory as server connection factory
2024-05-03 03:10:19,032 [myid:] - WARN [main:o.a.z.s.ServerCnxnFactory@309] - maxCnxns is not configured, using default value 0.
2024-05-03 03:10:19,034 [myid:] - INFO [main:o.a.z.s.NIOServerCnxnFactory@652] - Configuring NIO connection handler with 10s sessionless connection timeout, 1 selector thread(s), 8 worker threads, and 64 kB direct buffers.
2024-05-03 03:10:19,036 [myid:] - INFO [main:o.a.z.s.NIOServerCnxnFactory@660] - binding to port 0.0.0.0/0.0.0.0:2181
2024-05-03 03:10:19,057 [myid:] - INFO [main:o.a.z.s.w.WatchManagerFactory@42] - Using org.apache.zookeeper.server.watch.WatchManager as watch manager
2024-05-03 03:10:19,057 [myid:] - INFO [main:o.a.z.s.w.WatchManagerFactory@42] - Using org.apache.zookeeper.server.watch.WatchManager as watch manager
2024-05-03 03:10:19,059 [myid:] - INFO [main:o.a.z.s.ZKDatabase@134] - zookeeper.snapshotSizeFactor = 0.33
2024-05-03 03:10:19,059 [myid:] - INFO [main:o.a.z.s.ZKDatabase@154] - zookeeper.commitLogCount=500
2024-05-03 03:10:19,067 [myid:] - INFO [main:o.a.z.s.p.SnapStream@61] - zookeeper.snapshot.compression.method = CHECKED
2024-05-03 03:10:19,067 [myid:] - INFO [main:o.a.z.s.p.FileTxnSnapLog@480] - Snapshotting: 0x0 to /opt/bitnami/zookeeper/data/version-2/snapshot.0
2024-05-03 03:10:19,071 [myid:] - INFO [main:o.a.z.s.ZKDatabase@291] - Snapshot loaded in 13 ms, highest zxid is 0x0, digest is 1371985504
2024-05-03 03:10:19,073 [myid:] - INFO [main:o.a.z.s.p.FileTxnSnapLog@480] - Snapshotting: 0x0 to /opt/bitnami/zookeeper/data/version-2/snapshot.0
2024-05-03 03:10:19,088 [myid:] - INFO [main:o.a.z.s.ZooKeeperServer@589] - Snapshot taken in 15 ms
2024-05-03 03:10:19,105 [myid:] - INFO [ProcessThread(sid:0 cport:2181)::o.a.z.s.PrepRequestProcessor@138] - PrepRequestProcessor (sid:0) started, reconfigEnabled=false
2024-05-03 03:10:19,106 [myid:] - INFO [main:o.a.z.s.RequestThrottler@75] - zookeeper.request_throttler.shutdownTimeout = 10000 ms
2024-05-03 03:10:19,134 [myid:] - INFO [main:o.a.z.s.ContainerManager@83] - Using checkIntervalMs=60000 maxPerMinute=10000 maxNeverUsedIntervalMs=0
2024-05-03 03:10:19,136 [myid:] - INFO [main:o.a.z.a.ZKAuditProvider@42] - ZooKeeper audit is disabled.
可以看到 zookeeper 正常启动了,并且最后一行日志显示验证被禁用了,这是因为上面在启动的时候添加了环境变量: ALLOW_ANONYMOUS_LOGIN=yes 允许任何人连接;后面配置 Kafka 密码验证的时候,就不这么配置了;
1.2 查看 zookeeper 状态
进入容器:
docker exec -it zookeeper bash
I have no name!@zookeeper:/$ cd /opt/bitnami/zookeeper/bin
I have no name!@zookeeper:/opt/bitnami/zookeeper/bin$ ls
README.txt zkCli.sh zkServer-initialize.sh zkSnapShotToolkit.cmd zkSnapshotComparer.sh zkTxnLogToolkit.cmd
zkCleanup.sh zkEnv.cmd zkServer.cmd zkSnapShotToolkit.sh zkSnapshotRecursiveSummaryToolkit.cmd zkTxnLogToolkit.sh
zkCli.cmd zkEnv.sh zkServer.sh zkSnapshotComparer.cmd zkSnapshotRecursiveSummaryToolkit.sh
I have no name!@zookeeper:/opt/bitnami/zookeeper/bin$
查看 zookeeper 状态:
I have no name!@zookeeper:/opt/bitnami/zookeeper/bin$ zkServer.sh status
/opt/bitnami/java/bin/java
ZooKeeper JMX enabled by default
Using config: /opt/bitnami/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: standalone
I have no name!@zookeeper:/opt/bitnami/zookeeper/bin$
1.3 启动 Kafka
创建挂载目录:
mkdir -p kafka/data
chown -R 1001.1001 kafka
docker-compose.yaml
kafka:
image: docker.io/bitnami/kafka:3.4
container_name: kafka
hostname: kafka
privileged: true
restart: always
environment:
KAFKA_CFG_ZOOKEEPER_CONNECT: 'zookeeper:2181'
volumes:
- ./kafka/data:/opt/bitnami/kafka/data
ports:
- "9092:9092"
deploy:
resources:
limits:
cpus: '4'
memory: 4G
reservations:
cpus: '0.5'
memory: 200M
depends_on:
- zookeeper
启动 Kafka :docker-compose up -d kafka
[root@localhost kafka-with-zookeeper]# docker-compose up -d kafka
[+] Running 2/2
⠿ Container zookeeper Running 0.0s
⠿ Container kafka Started
查看 Kafka 日志:
[root@localhost ~]# docker logs -f --tail 20 kafka
[2024-05-03 04:12:03,381] INFO [ReplicaStateMachine controllerId=1001] Triggering online replica state changes (kafka.controller.ZkReplicaStateMachine)
[2024-05-03 04:12:03,391] INFO [ReplicaStateMachine controllerId=1001] Triggering offline replica state changes (kafka.controller.ZkReplicaStateMachine)
[2024-05-03 04:12:03,391] DEBUG [ReplicaStateMachine controllerId=1001] Started replica state machine with initial state -> Map() (kafka.controller.ZkReplicaStateMachine)
[2024-05-03 04:12:03,393] INFO [PartitionStateMachine controllerId=1001] Initializing partition state (kafka.controller.ZkPartitionStateMachine)
[2024-05-03 04:12:03,394] INFO [PartitionStateMachine controllerId=1001] Triggering online partition state changes (kafka.controller.ZkPartitionStateMachine)
[2024-05-03 04:12:03,396] INFO [RequestSendThread controllerId=1001] Controller 1001 connected to kafka:9092 (id: 1001 rack: null) for sending state change requests (kafka.controller.RequestSendThread)
[2024-05-03 04:12:03,399] DEBUG [PartitionStateMachine controllerId=1001] Started partition state machine with initial state -> Map() (kafka.controller.ZkPartitionStateMachine)
[2024-05-03 04:12:03,400] INFO [Controller id=1001] Ready to serve as the new controller with epoch 1 (kafka.controller.KafkaController)
[2024-05-03 04:12:03,411] INFO [Controller id=1001] Partitions undergoing preferred replica election: (kafka.controller.KafkaController)
[2024-05-03 04:12:03,412] INFO [Controller id=1001] Partitions that completed preferred replica election: (kafka.controller.KafkaController)
[2024-05-03 04:12:03,412] INFO [Controller id=1001] Skipping preferred replica election for partitions due to topic deletion: (kafka.controller.KafkaController)
[2024-05-03 04:12:03,413] INFO [Controller id=1001] Resuming preferred replica election for partitions: (kafka.controller.KafkaController)
[2024-05-03 04:12:03,416] INFO [Controller id=1001] Starting replica leader election (PREFERRED) for partitions triggered by ZkTriggered (kafka.controller.KafkaController)
[2024-05-03 04:12:03,431] INFO [Controller id=1001] Starting the controller scheduler (kafka.controller.KafkaController)
[2024-05-03 04:12:03,461] INFO [BrokerToControllerChannelManager broker=1001 name=forwarding]: Recorded new controller, from now on will use node kafka:9092 (id: 1001 rack: null) (kafka.server.BrokerToControllerRequestThread)
[2024-05-03 04:12:03,551] INFO [BrokerToControllerChannelManager broker=1001 name=alterPartition]: Recorded new controller, from now on will use node kafka:9092 (id: 1001 rack: null) (kafka.server.BrokerToControllerRequestThread)
[2024-05-03 04:12:08,434] INFO [Controller id=1001] Processing automatic preferred replica leader election (kafka.controller.KafkaController)
[2024-05-03 04:12:08,435] TRACE [Controller id=1001] Checking need to trigger auto leader balancing (kafka.controller.KafkaController)
[2024-05-03 04:17:08,439] INFO [Controller id=1001] Processing automatic preferred replica leader election (kafka.controller.KafkaController)
[2024-05-03 04:17:08,439] TRACE [Controller id=1001] Checking need to trigger auto leader balancing (kafka.controller.KafkaController)
可以看到 kafka 正常启动了。
1.4 Kafka 配置文件
进入 Kafka 容器,看下上面什么环境变量都没配置时,配置文件server.properties的内容:
I have no name!@kafka:/opt/bitnami/kafka/config$ cat server.properties
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# This configuration file is intended for use in ZK-based mode, where Apache ZooKeeper is required.
# See kafka.server.KafkaConfig for additional details and defaults
#
############################# Server Basics #############################
# The id of the broker. This must be set to a unique integer for each broker.
#broker.id=0
############################# Socket Server Settings #############################
# The address the socket server listens on. If not configured, the host name will be equal to the value of
# java.net.InetAddress.getCanonicalHostName(), with PLAINTEXT listener name, and port 9092.
# FORMAT:
# listeners = listener_name://host_name:port
# EXAMPLE:
# listeners = PLAINTEXT://your.host.name:9092
#listeners=PLAINTEXT://:9092
# Listener name, hostname and port the broker will advertise to clients.
# If not set, it uses the value for "listeners".
#advertised.listeners=PLAINTEXT://your.host.name:9092
# Maps listener names to security protocols, the default is for them to be the same. See the config documentation for more details
#listener.security.protocol.map=PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL
# The number of threads that the server uses for receiving requests from the network and sending responses to the network
num.network.threads=3
# The number of threads that the server uses for processing requests, which may include disk I/O
num.io.threads=8
# The send buffer (SO_SNDBUF) used by the socket server
socket.send.buffer.bytes=102400
# The receive buffer (SO_RCVBUF) used by the socket server
socket.receive.buffer.bytes=102400
# The maximum size of a request that the socket server will accept (protection against OOM)
socket.request.max.bytes=104857600
############################# Log Basics #############################
# A comma separated list of directories under which to store log files
log.dirs=/bitnami/kafka/data
# The default number of log partitions per topic. More partitions allow greater
# parallelism for consumption, but this will also result in more files across
# the brokers.
num.partitions=1
# The number of threads per data directory to be used for log recovery at startup and flushing at shutdown.
# This value is recommended to be increased for installations with data dirs located in RAID array.
num.recovery.threads.per.data.dir=1
############################# Internal Topic Settings #############################
# The replication factor for the group metadata internal topics "__consumer_offsets" and "__transaction_state"
# For anything other than development testing, a value greater than 1 is recommended to ensure availability such as 3.
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
############################# Log Flush Policy #############################
# Messages are immediately written to the filesystem but by default we only fsync() to sync
# the OS cache lazily. The following configurations control the flush of data to disk.
# There are a few important trade-offs here:
# 1. Durability: Unflushed data may be lost if you are not using replication.
# 2. Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush.
# 3. Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to excessive seeks.
# The settings below allow one to configure the flush policy to flush data after a period of time or
# every N messages (or both). This can be done globally and overridden on a per-topic basis.
# The number of messages to accept before forcing a flush of data to disk
#log.flush.interval.messages=10000
# The maximum amount of time a message can sit in a log before we force a flush
#log.flush.interval.ms=1000
############################# Log Retention Policy #############################
# The following configurations control the disposal of log segments. The policy can
# be set to delete segments after a period of time, or after a given size has accumulated.
# A segment will be deleted whenever *either* of these criteria are met. Deletion always happens
# from the end of the log.
# The minimum age of a log file to be eligible for deletion due to age
log.retention.hours=168
# A size-based retention policy for logs. Segments are pruned from the log unless the remaining
# segments drop below log.retention.bytes. Functions independently of log.retention.hours.
#log.retention.bytes=1073741824
# The maximum size of a log segment file. When this size is reached a new log segment will be created.
#log.segment.bytes=1073741824
# The interval at which log segments are checked to see if they can be deleted according
# to the retention policies
log.retention.check.interval.ms=300000
############################# Zookeeper #############################
# Zookeeper connection string (see zookeeper docs for details).
# This is a comma separated host:port pairs, each corresponding to a zk
# server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".
# You can also append an optional chroot string to the urls to specify the
# root directory for all kafka znodes.
zookeeper.connect=zookeeper:2181
# Timeout in ms for connecting to zookeeper
#zookeeper.connection.timeout.ms=18000
############################# Group Coordinator Settings #############################
# The following configuration specifies the time, in milliseconds, that the GroupCoordinator will delay the initial consumer rebalance.
# The rebalance will be further delayed by the value of group.initial.rebalance.delay.ms as new members join the group, up to a maximum of max.poll.interval.ms.
# The default value for this is 3 seconds.
# We override this to 0 here as it makes for a better out-of-the-box experience for development and testing.
# However, in production environments the default value of 3 seconds is more suitable as this will help to avoid unnecessary, and potentially expensive, rebalances during application startup.
#group.initial.rebalance.delay.ms=0
sasl.enabled.mechanisms=PLAIN,SCRAM-SHA-256,SCRAM-SHA-512
这里配置文件的值都可以使用环境变量来指定;
服务基础配置:broker.id服务器节点ID,同一集群中必须唯一
可以看到,脚本中没有设置listeners和advertised.listeners的值,配置文件中这两项的配置是注释掉的,如果需要外部机器访问当前 Kafka 则需要配置这两项:
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093,EXTERNAL://:9094
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://kafka:9092,EXTERNAL://localhost:9094
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,EXTERNAL:PLAINTEXT,PLAINTEXT:PLAINTEXT
- KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER
这里配置了三个监听器连接方式:
- 第一组是明文端口9092,可以使用服务名kafka进行访问;
- 第二组是集群内部通信,9093端口;
- 第三组是外部机器明文访问,9094端口,在实际使用时,localhost 需要改为当前机器的IP;
如果为单节点 Kafka,允许外部机器访问,则只需要配置KAFKA_CFG_LISTENERS、KAFKA_CFG_ADVERTISED_LISTENERS就可以了。
1.4 使用命令操作 Kafak 生产、消费
进入 Kafka 容器:
docker exec -it kafka bash
cd /opt/bitnami/bin/
I have no name!@kafka:/opt/bitnami/kafka/bin$ ls
connect-distributed.sh kafka-console-producer.sh kafka-leader-election.sh kafka-run-class.sh kafka-verifiable-producer.sh
connect-mirror-maker.sh kafka-consumer-groups.sh kafka-log-dirs.sh kafka-server-start.sh trogdor.sh
connect-standalone.sh kafka-consumer-perf-test.sh kafka-metadata-quorum.sh kafka-server-stop.sh windows
kafka-acls.sh kafka-delegation-tokens.sh kafka-metadata-shell.sh kafka-storage.sh zookeeper-security-migration.sh
kafka-broker-api-versions.sh kafka-delete-records.sh kafka-mirror-maker.sh kafka-streams-application-reset.sh zookeeper-server-start.sh
kafka-cluster.sh kafka-dump-log.sh kafka-producer-perf-test.sh kafka-topics.sh zookeeper-server-stop.sh
kafka-configs.sh kafka-features.sh kafka-reassign-partitions.sh kafka-transactions.sh zookeeper-shell.sh
kafka-console-consumer.sh kafka-get-offsets.sh kafka-replica-verification.sh kafka-verifiable-consumer.sh
I have no name!@kafka:/opt/bitnami/kafka/bin$
这里看下脚本中的配置KAFKA_HEAP_OPTS:
I have no name!@kafka:/opt/bitnami/kafka/bin$ cat kafka-console-producer.sh
#!/bin/bash
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-Xmx512M"
fi
exec $(dirname $0)/kafka-run-class.sh kafka.tools.ConsoleProducer "$@"
I have no name!@kafka:/opt/bitnami/kafka/bin$
I have no name!@kafka:/opt/bitnami/kafka/bin$ cat kafka-console-consumer.sh
#!/bin/bash
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-Xmx512M"
fi
exec $(dirname $0)/kafka-run-class.sh kafka.tools.ConsoleConsumer "$@"
I have no name!@kafka:/opt/bitnami/kafka/bin$
可以看到生产者和消费者的参数配置仅配置了一个环境变量:KAFKA_HEAP_OPTS,并且内容仅为 -Xmx512M,记住这个玩意,等下密码验证时,需要对这个值进行扩展;
1.4.1 创建topic
创建名为 test,partitions(分区)为10,replication(副本)为1的topic
I have no name!@kafka:/opt/bitnami/kafka/bin$ kafka-topics.sh --create --bootstrap-server kafka:9092 --partitions 10 --replication-factor 1 --topic test
Created topic test.
I have no name!@kafka:/opt/bitnami/kafka/bin$
这里使用的是 kafka 来访问的,如果配置了 KAFKA_CFG_ADVERTISED_LISTENERS 也可以使用当前机器的Ip进行访问;
1.4.2 查看某个 topic
查看 Topic 分区情况,使用 describe
I have no name!@kafka:/opt/bitnami/kafka/bin$ kafka-topics.sh --describe --bootstrap-server kafka:9092 --topic test
Topic: test TopicId: nAakv4u8SJO022gRe-ahVQ PartitionCount: 10 ReplicationFactor: 1 Configs:
Topic: test Partition: 0 Leader: 1001 Replicas: 1001 Isr: 1001
Topic: test Partition: 1 Leader: 1001 Replicas: 1001 Isr: 1001
Topic: test Partition: 2 Leader: 1001 Replicas: 1001 Isr: 1001
Topic: test Partition: 3 Leader: 1001 Replicas: 1001 Isr: 1001
Topic: test Partition: 4 Leader: 1001 Replicas: 1001 Isr: 1001
Topic: test Partition: 5 Leader: 1001 Replicas: 1001 Isr: 1001
Topic: test Partition: 6 Leader: 1001 Replicas: 1001 Isr: 1001
Topic: test Partition: 7 Leader: 1001 Replicas: 1001 Isr: 1001
Topic: test Partition: 8 Leader: 1001 Replicas: 1001 Isr: 1001
Topic: test Partition: 9 Leader: 1001 Replicas: 1001 Isr: 1001
I have no name!@kafka:/opt/bitnami/kafka/bin$
1.4.3 获取所有 topic
使用关键字 list
I have no name!@kafka:/opt/bitnami/kafka/bin$ kafka-topics.sh --list --bootstrap-server kafka:9092
test
I have no name!@kafka:/opt/bitnami/kafka/bin$
1.4.4 删除 topic
I have no name!@kafka:/opt/bitnami/kafka/bin$ kafka-topics.sh --delete --bootstrap-server kafka:9092 --topic test
I have no name!@kafka:/opt/bitnami/kafka/bin$
I have no name!@kafka:/opt/bitnami/kafka/bin$ kafka-topics.sh --list --bootstrap-server kafka:9092
I have no name!@kafka:/opt/bitnami/kafka/bin$
1.4.4 发送消息
首先创建一个 topic:
kafka-topics.sh --create --bootstrap-server kafka:9092 --partitions 10 --replication-factor 1 --topic test
发送两条消息
I have no name!@kafka:/opt/bitnami/kafka/bin$ kafka-console-producer.sh --broker-list kafka:9092 --topic test
>hello
>hello everyone
>
1.4.5 消费消息
再打开一个窗口,作为消费者连接 kafka
[root@localhost ~]# docker exec -it kafka bash
I have no name!@kafka:/$
I have no name!@kafka:/$ cd /opt/bitnami/kafka/bin/
I have no name!@kafka:/opt/bitnami/kafka/bin$
I have no name!@kafka:/opt/bitnami/kafka/bin$ kafka-console-consumer.sh --bootstrap-server kafka:9092 --topic test --from-beginning
hello
hello everyone
可以看到,已经正常消费了刚才生成的两条消息;
再次在生产者的窗口里生成消息,可以看到,消费者窗口,可以正常消费消息;
2. 有密码部署
这里使用SASL_PLAINTEXT模式,也就是明文密码,明文密码是直接配置在配置文件中,如果需要更安全的操作,可以使用jks证书的方式来配置 SASL_SSL密码验证。可参考:kafka-generate-ssl.sh
2.1 使用 SASL 验证模式
这里使用 无密码的 zookeeper,来搭配有密码的 Kafka;
首先创建一个配置文件secrets/kafka_server_jaas.conf,用来配置 Kafka 的账号和密码:
KafkaServer {
org.apache.kafka.common.security.plain.PlainLoginModule required
username="admin"
password="Abc123456"
user_admin="Abc123456"
user_producer="Abc123456"
user_consumer="Abc123456";
};
KafkaClient {
org.apache.kafka.common.security.plain.PlainLoginModule required
username="producer"
password="Abc123456";
};
该配置通过org.apache.org.apache.kafka.common.security.plain.PlainLoginModule指定采用PLAIN机制,定义了用户。
usemame和password指定该代理与集群其他代理初始化连接的用户名和密码- "
user_"为前缀后接用户名方式创建连接代理的用户名和密码,例如,user_producer=“Abc123456”是指用户名为producer,密码为Abc123456- username为admin的用户,和user为admin的用户,密码要保持一致,否则会认证失败
上述配置中,在KafkaServer里,创建了三个用户,分别为admin、producer和consumer(创建多少个用户,可根据业务需要配置,用户名和密码可自定义设置;
在KafkaClient里配置了一个用户,用户名和密码需要和服务端配置的账号密码保持一致,这里配置了producer这个用户。
修改配置文件权限:
chown -R 1001.1001 secrets
接着是 doker-compose 中的 kafka 配置调整为:
kafka:
image: docker.io/bitnami/kafka:3.4
container_name: kafka
hostname: kafka
privileged: true
restart: always
environment:
KAFKA_OPTS: '-Djava.security.auth.login.config=/opt/bitnami/kafka/secrets/kafka_server_jaas.conf'
KAFKA_BROKER_ID: 0
KAFKA_CFG_LISTENERS: SASL_PLAINTEXT://:9092
KAFKA_CFG_ADVERTISED_LISTENERS: SASL_PLAINTEXT://192.168.104.147:9092
KAFKA_CFG_SECURITY_INTER_BROKER_PROTOCOL: SASL_PLAINTEXT
KAFKA_CFG_SASL_ENABLED_MECHANISMS: PLAIN
KAFKA_CFG_SASL_MECHANISM_INTER_BROKER_PROTOCOL: PLAIN
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
# 平替默认配置文件里面的值
KAFKA_CFG_OFFSETS_TOPIC_REPLICATION_FACTOR: 3
KAFKA_CFG_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 3
KAFKA_CFG_TRANSACTION_STATE_LOG_MIN_ISR: 2
volumes:
- ./kafka/data:/opt/bitnami/kafka/data
- ./secrets:/opt/bitnami/kafka/secrets
ports:
- "9092:9092"
deploy:
resources:
limits:
cpus: '4'
memory: 4G
reservations:
cpus: '0.5'
memory: 200M
depends_on:
- zookeeper
启动成功日志结尾为:
[2024-05-03 07:26:17,096] TRACE [Controller id=0] Leader imbalance ratio for broker 1001 is 1.0 (kafka.controller.KafkaController)
[2024-05-03 07:26:17,102] INFO [Controller id=0] Starting replica leader election (PREFERRED) for partitions triggered by AutoTriggered (kafka.controller.KafkaController)
[2024-05-03 07:26:20,808] INFO [RequestSendThread controllerId=0] Controller 0 connected to 192.168.104.147:9092 (id: 0 rack: null) for sending state change requests (kafka.controller.RequestSendThread)
[2024-05-03 07:26:20,850] INFO [BrokerToControllerChannelManager broker=0 name=forwarding]: Recorded new controller, from now on will use node 192.168.104.147:9092 (id: 0 rack: null) (kafka.server.BrokerToControllerRequestThread)
[2024-05-03 07:26:20,859] INFO [Broker id=0] Add 60 partitions and deleted 0 partitions from metadata cache in response to UpdateMetadata request sent by controller 0 epoch 2 with correlation id 1 (state.change.logger)
[2024-05-03 07:26:20,927] INFO [BrokerToControllerChannelManager broker=0 name=alterPartition]: Recorded new controller, from now on will use node 192.168.104.147:9092 (id: 0 rack: null) (kafka.server.BrokerToControllerRequestThread)
可以看到,由于指定了环境变量:Broker ID 这里也确实生效了,由默认的ID 1001 改成了我们设置的 0;
2.2 客户端验证
进入容器,测试命令行操作 Kafka
使用原来操作 Topic 的命令:
使用命令:
kafka-console-producer.sh --bootstrap-server 127.0.0.1:9092 --topic test --producer.config /opt/bitnami/kafka/config/producer.properties
上面命令不好使,执行会住,查看日志可以看到一直循环打印下面的信息:
[2024-05-03 07:53:41,938] INFO [SocketServer listenerType=ZK_BROKER, nodeId=0] Failed authentication with /127.0.0.1 (channelId=127.0.0.1:9092-127.0.0.1:36094-17) (Unexpected Kafka request of type METADATA during SASL handshake.) (org.apache.kafka.common.network.Selector)
发现一直在报错,然后新加一个配置文件client.properties,内容如下:
security.protocol=SASL_PLAINTEXT
sasl.mechanism=PLAIN
sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="producer" password="Abc123456";
接着使用查看 Topic 的命令:
kafka-topics.sh --list --bootstrap-server kafka:9092 --command-config /opt/bitnami/kafka/secrets/client.properties
__consumer_offsets
test
test1
可以看到,可以正常看到 topic 列表;
查看某个 Topic 信息:
I have no name!@kafka:/opt/bitnami/kafka/config$ kafka-topics.sh --describe --bootstrap-server kafka:9092 --topic test --command-config /opt/bitnami/kafka/secrets/client.properties
Topic: test TopicId: _rY4JuTlQ-KRWdhbmIpklQ PartitionCount: 10 ReplicationFactor: 1 Configs:
Topic: test Partition: 0 Leader: none Replicas: 1001 Isr: 1001
Topic: test Partition: 1 Leader: none Replicas: 1001 Isr: 1001
Topic: test Partition: 2 Leader: none Replicas: 1001 Isr: 1001
Topic: test Partition: 3 Leader: none Replicas: 1001 Isr: 1001
Topic: test Partition: 4 Leader: none Replicas: 1001 Isr: 1001
Topic: test Partition: 5 Leader: none Replicas: 1001 Isr: 1001
Topic: test Partition: 6 Leader: none Replicas: 1001 Isr: 1001
Topic: test Partition: 7 Leader: none Replicas: 1001 Isr: 1001
Topic: test Partition: 8 Leader: none Replicas: 1001 Isr: 1001
Topic: test Partition: 9 Leader: none Replicas: 1001 Isr: 1001
I have no name!@kafka:/opt/bitnami/kafka/config$
I have no name!@kafka:/opt/bitnami/kafka/config$ kafka-topics.sh --describe --bootstrap-server kafka:9092 --topic test1 --command-config /opt/bitnami/kafka/secrets/client.properties
Topic: test1 TopicId: pNlhOdhjQtaemjVB3jjM0g PartitionCount: 1 ReplicationFactor: 1 Configs:
Topic: test1 Partition: 0 Leader: 0 Replicas: 0 Isr: 0
I have no name!@kafka:/opt/bitnami/kafka/config$
现在问题来了,在生产者生成消息和消费消息时就噶了,生成消息也不报错,消费消息也不报错,但是消费者那不到消息,就很烦了。。。。。
既然命令行不行,那就换个其他的工具,本来还想省事呢,再加个 kafka-ui 瞅一眼;
3. 使用可视化工具 Kafka-ui
3.1 Kafka-ui 的基础使用
在上面 docker-compose 脚本中添加 Kafka-ui 的服务配置:
kafka-ui:
image: provectuslabs/kafka-ui
container_name: kafka-ui
hostname: kafka-ui
privileged: true
restart: always
environment:
- DYNAMIC_CONFIG_ENABLED=true
- AUTH_TYPE=LOGIN_FORM
- SPRING_SECURITY_USER_NAME=admin
- SPRING_SECURITY_USER_PASSWORD=admin123
#volumes:
# - ~/kui/config.yml:/etc/kafkaui/dynamic_config.yaml
ports:
- "8080:8080"
deploy:
resources:
limits:
cpus: '1'
memory: 2G
reservations:
cpus: '0.5'
配置上面的内容,启动 kafka-ui 服务后,可以看到正常启动的日志如下:
[root@localhost ~]# docker logs -f --tail 20 kafka-ui
Standard Commons Logging discovery in action with spring-jcl: please remove commons-logging.jar from classpath in order to avoid potential conflicts
_ _ ___ __ _ _ _ __ __ _
| | | |_ _| / _|___ _ _ /_\ _ __ __ _ __| |_ ___ | |/ /__ _ / _| |_____
| |_| || | | _/ _ | '_| / _ \| '_ / _` / _| ' \/ -_) | ' </ _` | _| / / _`|
\___/|___| |_| \___|_| /_/ \_| .__\__,_\__|_||_\___| |_|\_\__,_|_| |_\_\__,|
|_|
2024-05-04 02:37:44,032 WARN [main] c.p.k.u.u.DynamicConfigOperations: Dynamic config file /etc/kafkaui/dynamic_config.yaml doesnt exist or not readable
2024-05-04 02:37:44,098 INFO [main] c.p.k.u.KafkaUiApplication: Starting KafkaUiApplication using Java 17.0.6 with PID 1 (/kafka-ui-api.jar started by kafkaui in /)
2024-05-04 02:37:44,099 DEBUG [main] c.p.k.u.KafkaUiApplication: Running with Spring Boot v3.1.3, Spring v6.0.11
2024-05-04 02:37:44,100 INFO [main] c.p.k.u.KafkaUiApplication: No active profile set, falling back to 1 default profile: "default"
2024-05-04 02:37:59,321 INFO [main] c.p.k.u.c.a.BasicAuthSecurityConfig: Configuring LOGIN_FORM authentication.
2024-05-04 02:38:00,411 INFO [main] o.s.b.a.e.w.EndpointLinksResolver: Exposing 3 endpoint(s) beneath base path '/actuator'
2024-05-04 02:38:03,523 INFO [main] o.s.b.w.e.n.NettyWebServer: Netty started on port 8080
2024-05-04 02:38:03,615 INFO [main] c.p.k.u.KafkaUiApplication: Started KafkaUiApplication in 22.402 seconds (process running for 25.788)
这里并没有初始化配置连接 Kafka 的信息,仅仅在官方 Demo 上配置了个登录验证,登录页面如下:
这里登录的账号和密码就是上面脚本中配置的 admin和admin123;
官方支持的环境变量,可以参考这里:misc-configuration-properties
并且脚本里面注释了挂载的配置文件,这个配置文件等下我们来看看里面的内容到底是什么;
登录成功之后,会自动进入 Kafka-ui 的控制台页面:http://IP:8080/ui/clusters/create-new-cluster,来配置连接 Kafka 集群的信息;
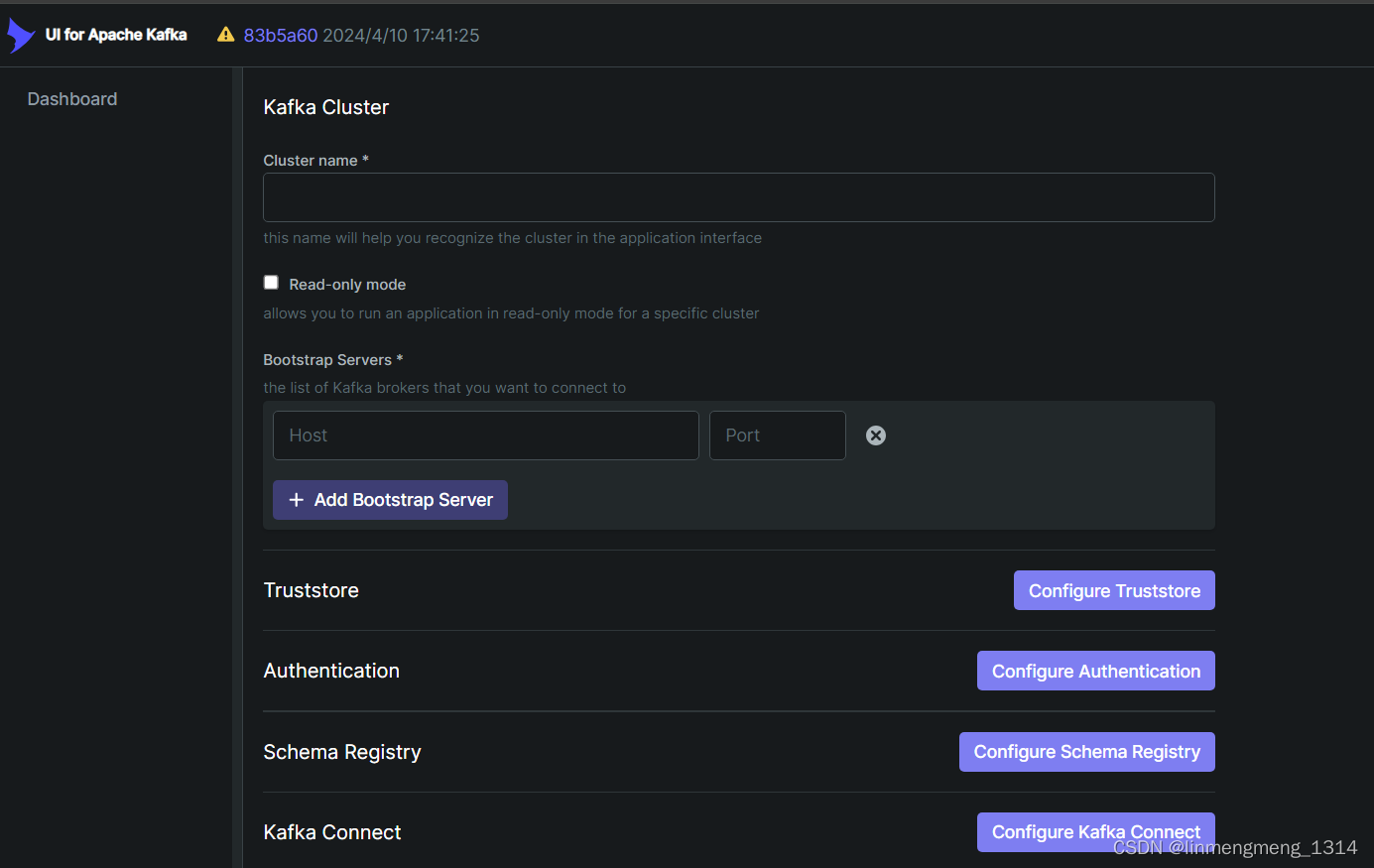
这里我们需要配置下必填项,如集群名称Cluster name,是否只读一般是不勾选的,我们可以使用这个来测试 Kafka 的发送消息,接着是 Bootstrap Servers 这里如果是kafka 集群,则可以配置多个;
如果没有配置 Kafka 的SASL验证,可以直接拉到最下面 使用 Validate 来测试是否能正常连接 Kafka;
由于我这里配置了 SASL验证,所以在 Authentication 这一项里面,配置Authentication Method为 SASL/PLAIN,Security Protocol 配置为:SASL_PLAINTEXT,接着勾选:Secured with auth?, 配置用户名和密码;
这里需要注意的是,用户名和密码,得是 Kafka 的 KafkaClient 里面配置的用户,不能是 KafkaServer里面的,否则在下面验证时报错:
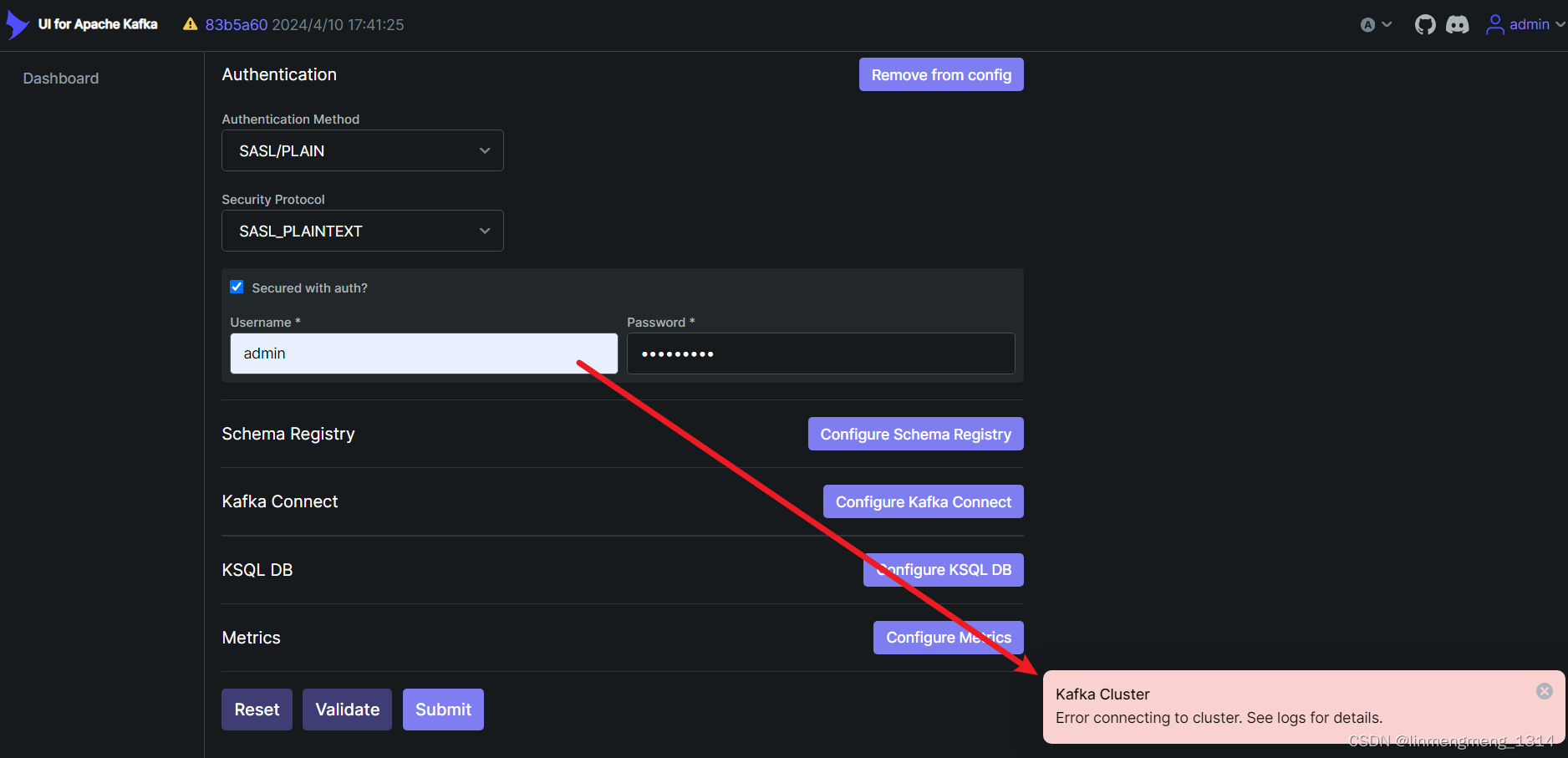
KafkaClient 里面配置的用户:producer 再次验证 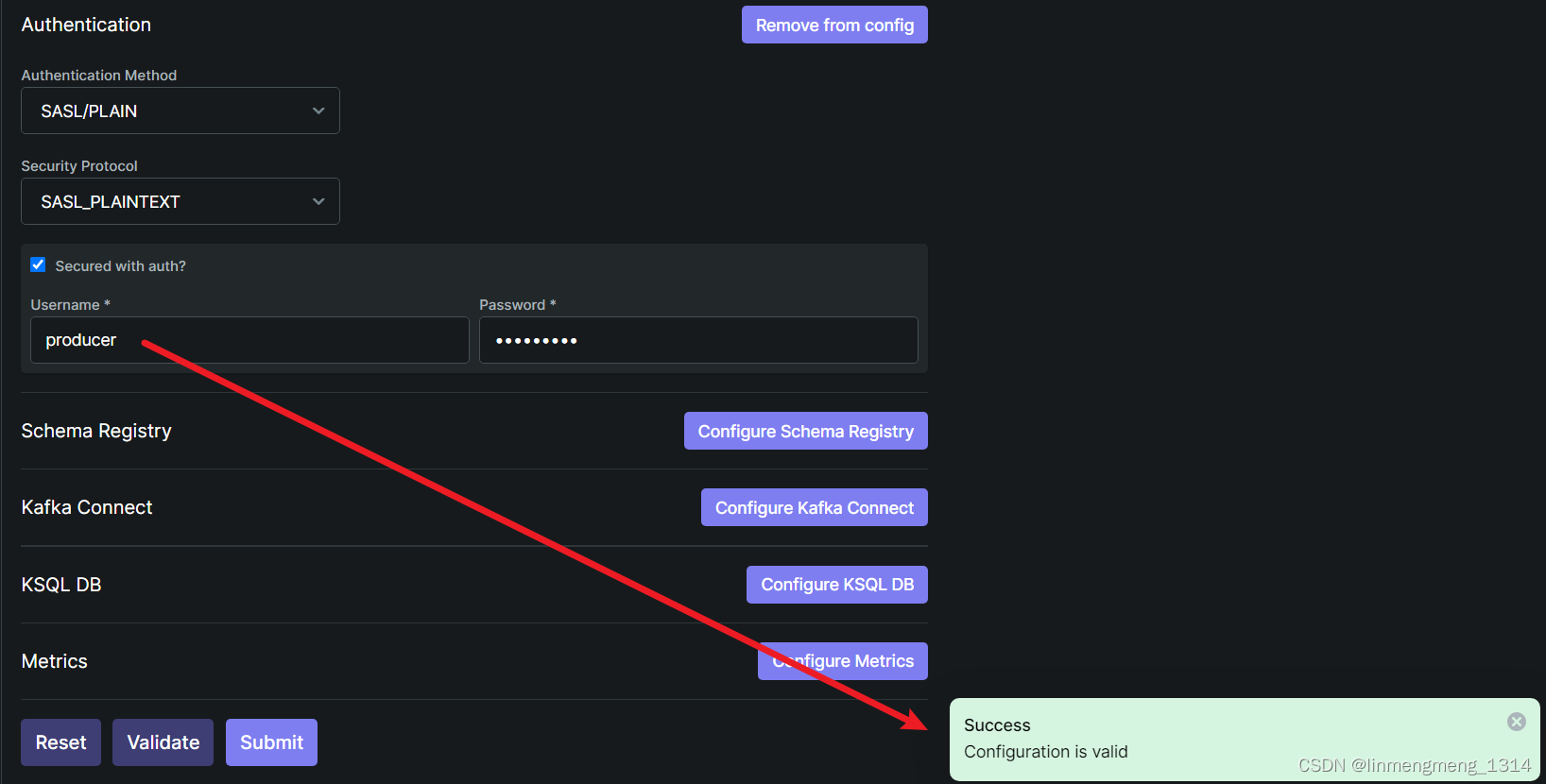
可以看到,连接成功了,也就是说这里的用户名和密码配置是作为 Kafka 的客户端来连接的。
点击 Submit 按钮,提交当前配置,自动进入 Kafka-UI 的控制台页面;
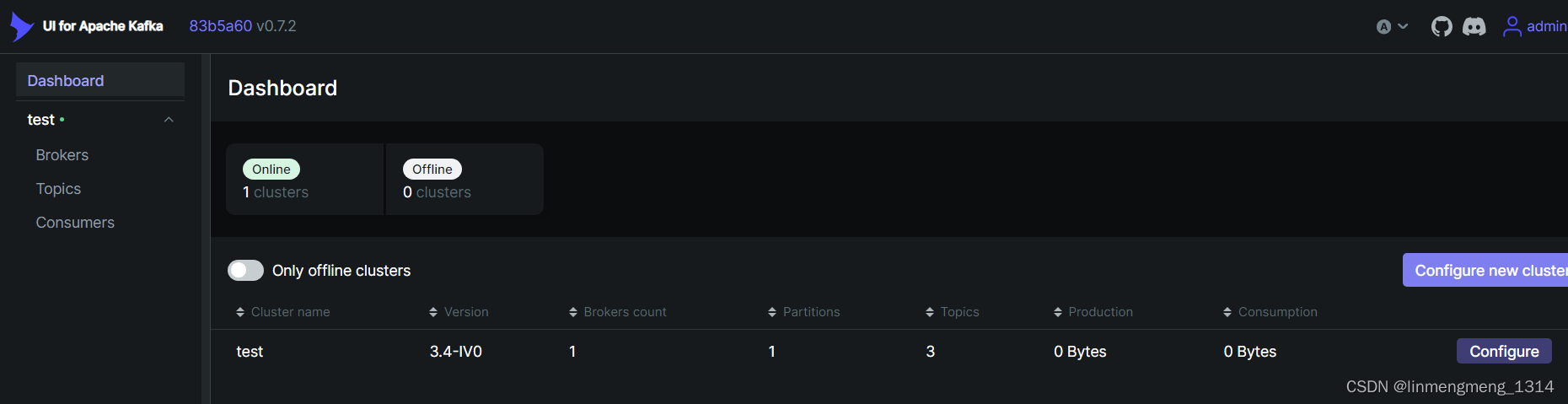
可以看到控制台面板下显示了我们的集群:test, 点击下面的 Brokes 、Topic 、Consumers 可以正常显示我们的集群信息:
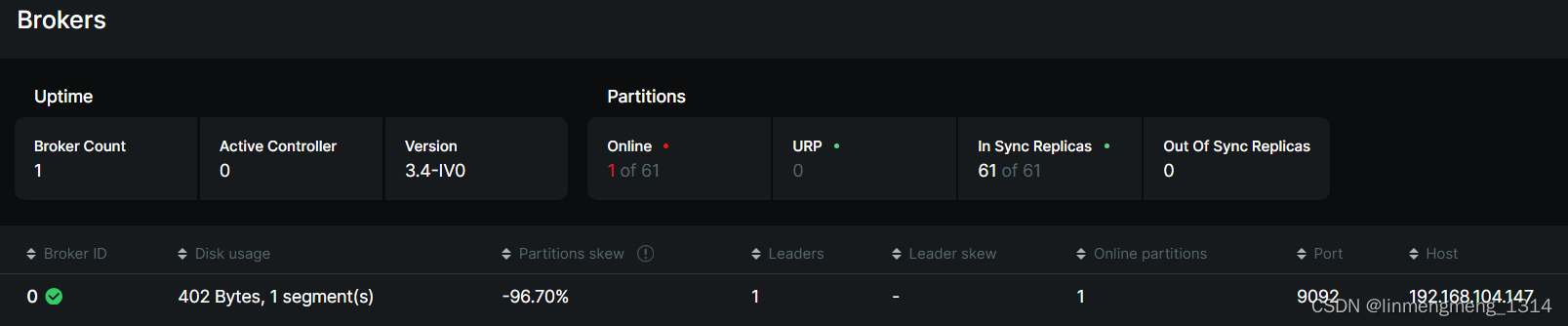
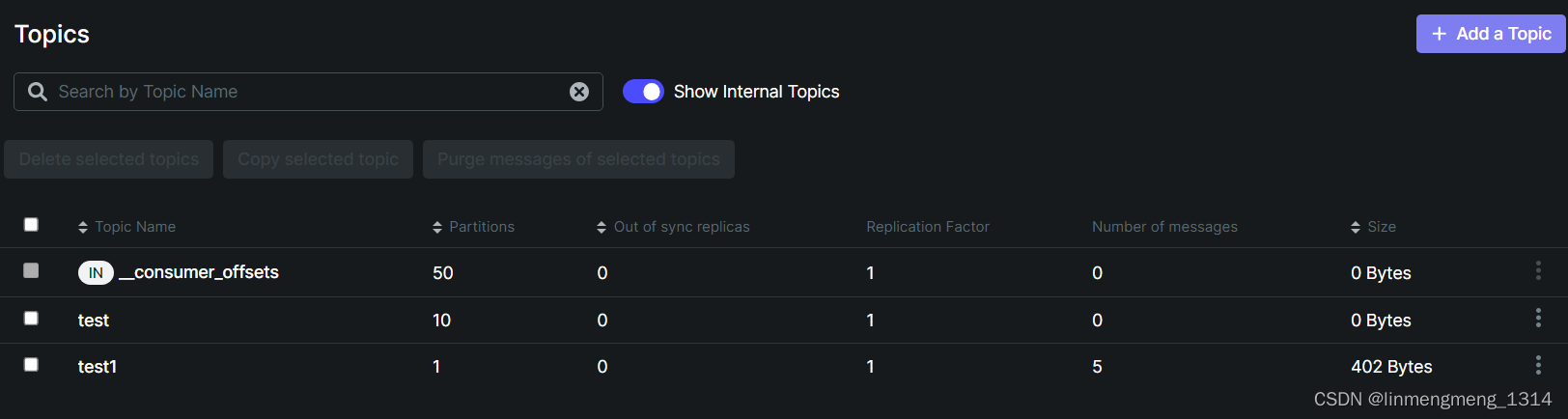

但凡在连接集群的时候哪里配置的不对的,在上面菜单中,就可能不会正常显示我们的 Kafka 集群信息;
3.2 Kafka-ui 的配置文件
上面我们的脚本里面注释了一个挂载目录文件/etc/kafkaui/dynamic_config.yaml,现在我们来看下这个文件的内容
[root@localhost ~]# docker exec -it kafka-ui sh
/ $
/ $ cd /etc/kafkaui/
/etc/kafkaui $ ls
dynamic_config.yaml
/etc/kafkaui $
/etc/kafkaui $ cat dynamic_config.yaml
auth:
type: LOGIN_FORM
kafka:
clusters:
- bootstrapServers: kafka:9092
name: test
properties:
security.protocol: SASL_PLAINTEXT
sasl.mechanism: PLAIN
sasl.jaas.config: org.apache.kafka.common.security.plain.PlainLoginModule required
username="producer" password="Abc123456";
readOnly: false
rbac:
roles: []
webclient: {}
/etc/kafkaui $
可以看到这个文件里面的内容,也就是上面配置的连接 Kafka 集群信息;
并且官方也说了这些配置是支持环境变量来配置的:
如:KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS 到配置文件里面就成了:
kafka:
clusters:
- bootstrapServers: xxx
但是我试了下直接把上面配置文件的内容转成如下的环境变量:
- KAFKA_CLUSTERS_0_NAME=local
- KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS=kafka:9092
- KAFKA_CLUSTERS_0_ZOOKEEPER=zookeeper:2181
- KAFKA_CLUSTERS_0_READONLY=false
- KAFKA_CLUSTERS_0_PROPERTIES_SECURITY_PROTOCOL=SASL_PLAINTEXT
- KAFKA_CLUSTERS_0_PROPERTIES_SASL_MECHANISM=PLAIN
- KAFKA_CLUSTERS_0_PROPERTIES_SASL_JAAS_CONFIG='org.apache.kafka.common.security.plain.PlainLoginModule required username="admin" password="Abc123456";'
但是启动的时候就报错了。然后还是注释掉,在启动 Kafka-ui 之后,在页面配置要连接的 Kafka 集群信息就好了。
如果在配置Kafka账号的时候提示验证失败,这玩意好像有点不稳定还是怎么着,多试几下 说不定就好了。
如果账号配置错误,在连接 kafka 的时候,会报错,比如我刚开始配置了 KafkaClient 的账号,然后就报错了,异常如下:
2024-05-04 02:28:06,338 ERROR [parallel-1] c.p.k.u.s.StatisticsService: Failed to collect cluster local info
java.lang.IllegalStateException: Error while creating AdminClient for Cluster local
at com.provectus.kafka.ui.service.AdminClientServiceImpl.lambda$createAdminClient$5(AdminClientServiceImpl.java:56)
at reactor.core.publisher.Mono.lambda$onErrorMap$28(Mono.java:3783)
at reactor.core.publisher.FluxOnErrorResume$ResumeSubscriber.onError(FluxOnErrorResume.java:94)
at reactor.core.publisher.Operators.error(Operators.java:198)
at reactor.core.publisher.FluxFlatMap.trySubscribeScalarMap(FluxFlatMap.java:135)
at reactor.core.publisher.MonoFlatMap.subscribeOrReturn(MonoFlatMap.java:53)
at reactor.core.publisher.Mono.subscribe(Mono.java:4480)
at reactor.core.publisher.FluxSwitchIfEmpty$SwitchIfEmptySubscriber.onComplete(FluxSwitchIfEmpty.java:82)
at reactor.core.publisher.Operators.complete(Operators.java:137)
at reactor.core.publisher.MonoEmpty.subscribe(MonoEmpty.java:46)
at reactor.core.publisher.Mono.subscribe(Mono.java:4495)
at reactor.core.publisher.FluxFlatMap$FlatMapMain.onNext(FluxFlatMap.java:427)
at reactor.core.publisher.FluxPublishOn$PublishOnSubscriber.runAsync(FluxPublishOn.java:440)
at reactor.core.publisher.FluxPublishOn$PublishOnSubscriber.run(FluxPublishOn.java:527)
at reactor.core.scheduler.WorkerTask.call(WorkerTask.java:84)
at reactor.core.scheduler.WorkerTask.call(WorkerTask.java:37)
at java.base/java.util.concurrent.FutureTask.run(FutureTask.java:264)
at java.base/java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:304)
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1136)
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:635)
at java.base/java.lang.Thread.run(Thread.java:833)
Caused by: org.apache.kafka.common.KafkaException: Failed to create new KafkaAdminClient
at org.apache.kafka.clients.admin.KafkaAdminClient.createInternal(KafkaAdminClient.java:551)
at org.apache.kafka.clients.admin.KafkaAdminClient.createInternal(KafkaAdminClient.java:488)
at org.apache.kafka.clients.admin.Admin.create(Admin.java:134)
at org.apache.kafka.clients.admin.AdminClient.create(AdminClient.java:39)
at com.provectus.kafka.ui.service.AdminClientServiceImpl.lambda$createAdminClient$2(AdminClientServiceImpl.java:53)
at reactor.core.publisher.MonoSupplier.call(MonoSupplier.java:67)
at reactor.core.publisher.FluxFlatMap.trySubscribeScalarMap(FluxFlatMap.java:127)
... 16 common frames omitted
Caused by: java.lang.IllegalArgumentException: Login module control flag not specified in JAAS config
at org.apache.kafka.common.security.JaasConfig.parseAppConfigurationEntry(JaasConfig.java:110)
at org.apache.kafka.common.security.JaasConfig.<init>(JaasConfig.java:63)
at org.apache.kafka.common.security.JaasContext.load(JaasContext.java:93)
at org.apache.kafka.common.security.JaasContext.loadClientContext(JaasContext.java:87)
at org.apache.kafka.common.network.ChannelBuilders.create(ChannelBuilders.java:167)
at org.apache.kafka.common.network.ChannelBuilders.clientChannelBuilder(ChannelBuilders.java:81)
at org.apache.kafka.clients.ClientUtils.createChannelBuilder(ClientUtils.java:105)
at org.apache.kafka.clients.admin.KafkaAdminClient.createInternal(KafkaAdminClient.java:522)
... 22 common frames omitted
2024-05-04 02:28:06,339 DEBUG [parallel-1] c.p.k.u.s.ClustersStatisticsScheduler: Metrics updated for cluster: local
这里要配置成 KafkaServer 的 admin 账号;如果 KafkaServer 的 admin 账号也不好使,就再试KafkaClient 的账号。只要 Kafka 配置的没问题,这里连接应该也问题不大。
4. 问题记录
4.1 消费者监听Topic时异常:Replication factor: 3 larger than available brokers: 1.
[2024-06-05 09:51:42,266] INFO [Admin Manager on Broker 0]: Error processing create topic request CreatableTopic(name='__consumer_offsets', numPartitions=50, replicationFactor=3, assignments=[], configs=[CreateableTopicConfig(name='compression.type', value='producer'), CreateableTopicConfig(name='cleanup.policy', value='compact'), CreateableTopicConfig(name='segment.bytes', value='104857600')]) (kafka.server.ZkAdminManager)
org.apache.kafka.common.errors.InvalidReplicationFactorException: Replication factor: 3 larger than available brokers: 1.
这个异常是因为 Kafka 环境配置问题,错误信息中显示在尝试创建一个名为__consumer_offsets的主题,该主题的复制因子(replicationFactor)被设置为3,但是Kafka集群中当前可用的Broker数量只有1个。在Kafka中,复制因子表示一个分区的数据将被复制到多少个Broker上,以提供数据冗余和容错能力。
要解决这个问题,可以采取以下几种方式之一:
增加Broker的数量:确保你的Kafka集群中有至少3个活跃的Broker。这可以通过启动更多的Kafka实例并将其配置加入到集群中来实现。
减少复制因子:如果你暂时无法增加Broker的数量,可以考虑减少__consumer_offsets主题的复制因子,使其小于或等于当前集群中的Broker数量。例如,如果只有一个Broker,那么复制因子应该设为1。
检查Broker的健康状态:确保所有的Broker都处于正常运行状态,没有Broker因为故障而离线。可以使用Kafka的管理命令或者监控工具检查Broker的状态。
我的 Kafak 服务配置了环境变量:
# 平替默认配置文件里面的值 TOPIC_REPLICATION_FACTOR 为集群中节点个数
KAFKA_CFG_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
# 控制着与事务相关的日志主题的复制因子
KAFKA_CFG_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_CFG_TRANSACTION_STATE_LOG_MIN_ISR: 1
在报错的时候,这里KAFKA_CFG_OFFSETS_TOPIC_REPLICATION_FACTOR配置的是3,集群中只有一个节点,所以报错了,现在改成1;
在修改了上述设置后,你可能需要重新创建或更新__consumer_offsets主题, 这里直接删除 zookeeper 的数据,重新启动 zookeeper ,然后再重新创建 Kafka 服务。这时候生产者发送消息、消费者消费消息都可以正常工作了。

















 1105
1105

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









