







几个概念
block
一般设为128m,hdfs是按块存储的
packet
packet是第二大的单位,它是client端向datanode,或者 datanode之间传输数据的基本单位,默认是 64k
chunk
chunk是最小的单位,它是client向DataNode,或DataNode的PipLine之间进行数据校验的基本单位,默认512Byte,因为用作校验,故每个chunk需要带有4Byte的校验位。所以实际每个chunk写入packet的大小为516Byte。由此可见真实数据与校验值数据的比值约为128 : 1。(即64*1024 / 512)
写流程
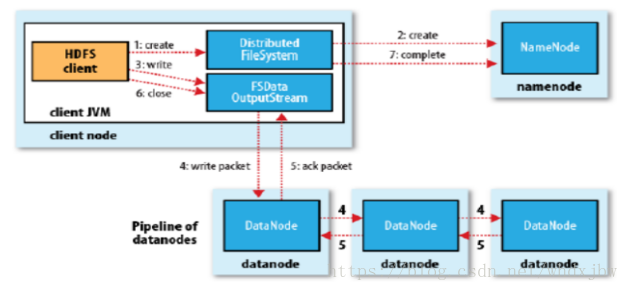
1 client向分布式文件系统发送写请求
2 请求发到了NN那里了,NN做检查,比如权限,路径,是否存在此文件等等。如果OK,就写 EditLog, 然后才写入内存。写完了之后,会返回一个输出流对象,并且返回一个datanode的列表。
3 client把文件按128m切分,然后用得到的输出流对象写数据,
4 client把数据分给第一个datanode,数据块是由packet组成的,完成一个packet传输之后,根据datanode列表,会依次往下发送packet包。
5 块写完之后,datanode往前汇报。
6 client关闭输出流
7 client告诉NN完成了上传任务。如果是强一致性,则是所有节点都有数据了,才通知。如果是最终一致性,则只要有一个datanode完成了就通知。
读流程

1 client发起一个读的请求
2 向NN获取数据的存放位置
3 client找到最近的主机,并且建立输入流
4 datanode向输入流来写入块的数据,如果有多个块,就读多个块,然后组合在一起
5 关闭流
数据校验
块由packet组成,packet由chunk组成,而chunk上由校验位。所以,块就能够做相应的校验了。
在写入的时候,client会把这个校验的一个值写在某文件中,当取出来时,再计算一下,如果和保存的不一致,就认为数据不对。文件保存在 .meta中
${dfs.datanode.data.dir}/
├── current
│ ├── BP-526805057-127.0.0.1-1411980876842
│ │ └── current
│ │ ├── VERSION
│ │ ├── finalized
│ │ │ ├── blk_1073741825
│ │ │ ├── blk_1073741825_1001.meta
│ │ │ ├── blk_1073741826
│ │ │ └── blk_1073741826_1002.meta
│ │ └── rbw
│ └── VERSION
└── in_use.lock
---------------------
参考了 https://blog.csdn.net/whdxjbw/article/details/81072207















 263
263











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









