







正在看《Thinking in java》学习散列码相关的知识,在这总结一下吧。
先来看一个例子
class Student{
protected int id;//当前类的成员与继承该类的类能访问.
public Student(int id) {
this.id = id;
}
@Override
public String toString() {
return "Student #" + id;
}
}
class Score{
private static Random random = new Random(47);
private int score = random.nextInt(100);
@Override
public String toString() {
return String.valueOf(score);
}
}
public class HashCodeTest {
public static <T extends Student> void studScore(Class<T> type) throws Exception{
Constructor<T> stud = type.getConstructor(int.class);
//利用反射机制来实例化及使用Student类和任何从Student派生出来的类
Map<Student, Score> map = new HashMap<>();
for (int i = 0; i < 10; i++) {
map.put(stud.newInstance(i), new Score());
}
System.out.println("map" + map);
Student student = stud.newInstance(3);//使用id为3的Student作为键
System.out.println("寻找学生: " + student);
if (map.containsKey(student)) {
System.out.println(map.get(student));
}else {
System.out.println("此学生不存在");
}
}
public static void main(String[] args) throws Exception{
studScore(Student.class);
}
}
输出
map{Student #1=55, Student #4=61, Student #5=29, Student #3=61, Student #8=22, Student #7=0, Student #0=58, Student #2=93, Student #9=7, Student #6=68}
寻找学生: Student #3
此学生不存在但是结果它无法找到id为3的键。问题出在Student是自动继承自基类Object,这里是使用Object的hashCode()方法生成散列码,默认是使用对象的地址计算散列码。第一个Student(3)的实例和第二个的散列码是不同的。所以无法找到。
所以需要恰当的覆盖hashCode()方法。并且同时覆盖equals方法。因为HashMap使用equals()判断当前的键是否与表中存在的键相同
equals()满足下列条件:
1)自反性 对于任意x, x.equals(x)必定返回true。
2)对称性 对于任意x,y,x.equals(y)与y.equals(x)的返回值相同。
3)传递性 对于任意x,y,z,如果x.equals(y)与y.equals(z)返回值相同,那么x.equals(z)返回值也相同。
4)一致性 对于任意的x,y,无论x.equals(y)执行多少次,返回值要么是true,要么为false。
5)对于任意x != null, x.equals(null)返回false。
所以要使用自己的类作为HashMap的键,必须同时覆盖hashCode()和equals().
class Student2 extends Student{
public Student2(int id) {
super(id);
}
@Override
public int hashCode() {
return id;//返回id作为散列码
}
@Override
public boolean equals(Object obj) {
return obj instanceof Student2 && (id == ((Student2)obj).id);
//instanceof检查了此对象是否为null,然后基于每个对象中实际的id进行比较
}
}
public class HashCode2 {
public static void main(String[] args) throws Exception {
HashCodeTest.studScore(Student2.class);
}
}输出
map{Student #0=58, Student #1=55, Student #2=93, Student #3=61, Student #4=61, Student #5=29, Student #6=68, Student #7=0, Student #8=22, Student #9=7}
寻找学生: Student #3
61
为速度而散列
线性查询是最慢的查询方法
散列将键保存在某处,以便能够很快找到。存储一组元素最快的数据结构是数组,所以使用它来表示键的信息。
数组并不保存键本身,而是通过键对象生成一个数字,将其作为数组的下标,这个数字就是散列码。
冲突有外部链接处理,数组并不直接保存值,而是保存值得list。然后对list中的值使用equals()方法进行线性的查询。(这部分的查询会比较慢)
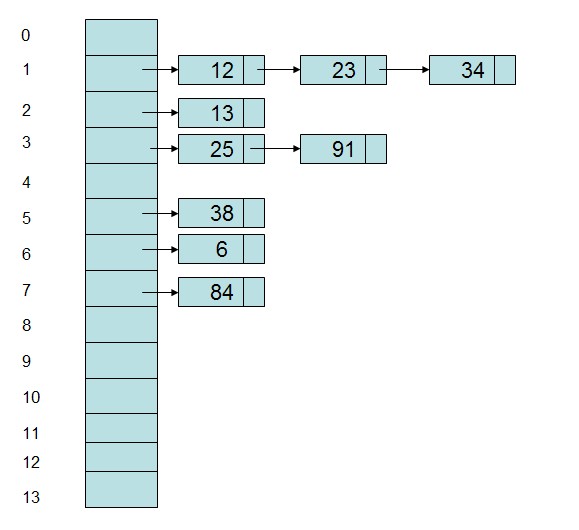
散列表的“槽位”(slot)通常被称为桶位(bucket),Java的散列函数使用2的整数次方(求余和除法是最慢的操作,使用2的整数次方长度的散列码,可以用掩码代替除法,可以减少get()中%操作的开销)。
覆盖hashCode()
无论何时,对同一个对象调用hashCode()都应该生成同样的值。且不能依赖易变的数据。
也不应该使hashCode()依赖于唯一性的对象信息。
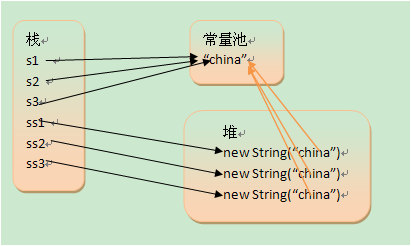
以String类为例,如果程序中有多个String对象,都包含相同的字符串序列,那么这些String对象都映射到同一块内存区域。
public class StringTest {
public static void main(String[] args) {
String str1 = new String("hello");
String str2 = new String("hello");
System.out.println(str1.hashCode());
System.out.println(str2.hashCode());
System.out.println(str1.equals(str2));
System.out.println(str1 == str2);
//双等号就是比较的栈里面的内容,原始数据类型和地址都是放在栈里面的。而equals则是根据地址拿到堆里面的内容进行比较。
}
}输出
99162322
99162322
true
false对String而言,hashCode()明显是基于String的内容的。根据对象的内容生成散列码,散列码不一定是独一无二,但是通过hashCod()和equals()必须能够完全确定对象的身份
来看看String的源码
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
//String类中的hashCode计算方法还是比较简单的,就是以31为权,每一位为字符的ASCII值进行运算.
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}














 475
475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









