







文章目录
1. 什么是强化学习?
强化学习(Reinforcement learning,RL)讨论的问题是一个智能体(agent) 怎么在一个复杂不确定的 环境(environment) 里面去极大化它能获得的奖励。通过感知所处环境的 状态(state) 对 动作(action) 的 反应(reward), 来指导更好的动作,从而获得最大的 收益(return),这被称为在交互中学习,这样的学习方法就被称作强化学习。
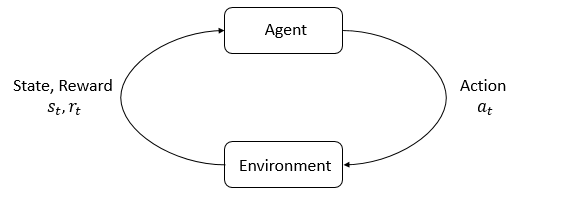
在强化学习过程中,智能体跟环境一直在交互。智能体在环境里面获取到状态 S t S_t St,智能体根据这个状态,结合自己的策略输出一个动作 A t A_t At。然后这个决策会放到环境之中去,环境会根据智能体采取的决策,根据状态模型输出下一个状态 S t + 1 S_{t+1} St+1 以及返回给智能体做当前的这个动作所得到的奖励值 R t + 1 R_{t+1} Rt+1,然后智能体可以继续选择下一个合适的动作,循环反复这个过程。最终的目的是为了尽可能多地从环境中获取奖励。
例如,我们走路摔倒了,大脑后面就会给一个负面的反馈,说明走势姿势不好,接着我们从摔倒状态爬起来并正常走路,那么大脑会给一个正面的反馈,此时我们就会知道并倾向于保持这个好的走路姿势。
强化学习是和监督学习、非监督学习并列的第三种基本的机器学习方法。
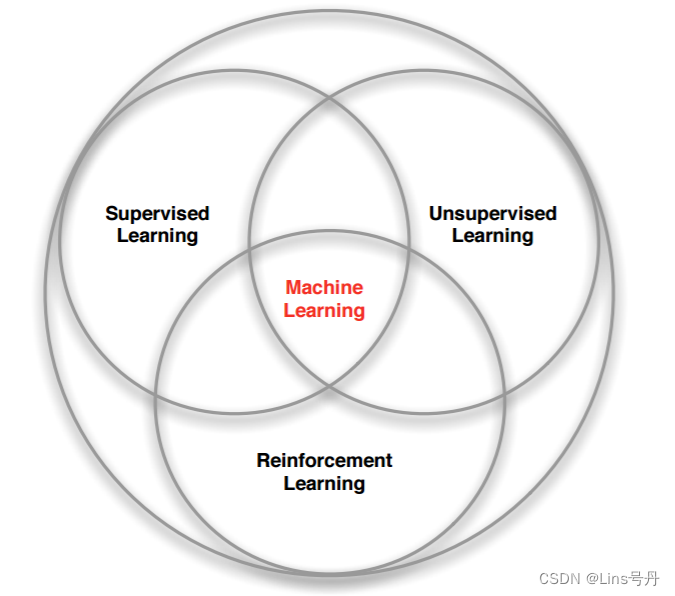
- 监督学习 是从外部监督者提供的带标注训练集中进行学习。 (任务驱动型)
- 非监督学习 是一个典型的寻找未标注数据中隐含结构的过程。 (数据驱动型)
- 强化学习 没有监督学习已经准备好的训练数据输出值,它只有奖励值,且这个奖励值不是事先给出的,而是延后给出的,而非监督学习既没有输出值也没有奖励值,只有数据特征。强化学习更偏重于智能体与环境的交互,它的每一步决策与时间顺序的前后关系紧密, 这带来了一个独有的挑战 ——“试错(exploration)”与“开发(exploitation)”之间的折中权衡,智能体必须开发已有的经验来获取收益,同时也要进行试探,使得未来可以获得更好的动作选择空间。 (从错误中学习)
强化学习主要有以下几个特点:
- 试错学习:强化学习一般没有直接的指导信息,Agent 要以不断与 Environment 进行交互,通过试错的方式来获得最佳策略(Policy);
- 延迟回报:强化学习的指导信息很少,而且往往是在事后(最后一个状态(State))才给出的。比如 围棋中只有到了最后才能知道胜负。
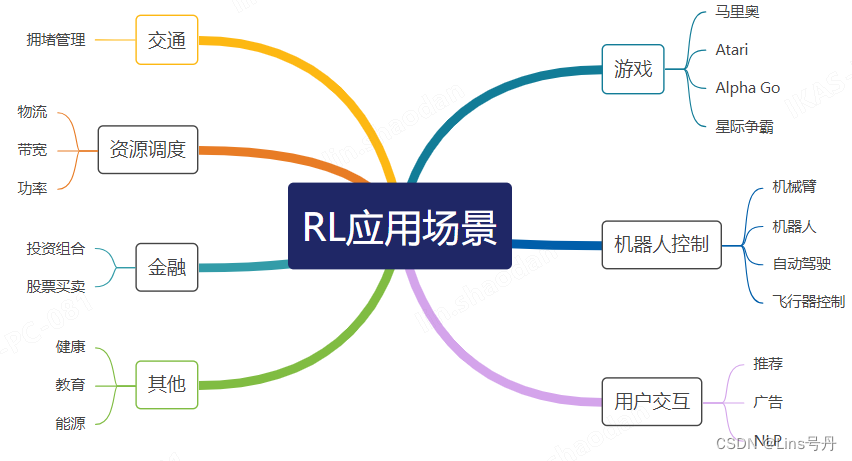
强化学习常见的应用场景有:
2. 强化学习的基本元素
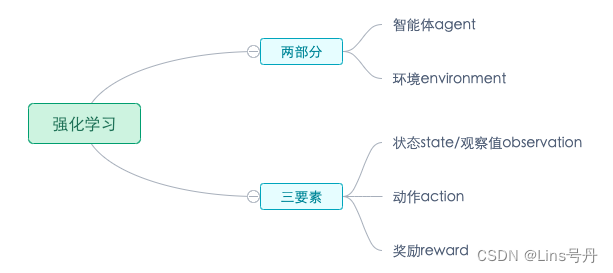
- 环境(Environment) 是一个外部系统,智能体处于这个系统中,能够感知到这个系统并且能够基于感知到的状态做出一定的行动。
- 智能体(Agent) 是一个嵌入到环境中的系统,能够通过采取行动来改变环境状态的对象,一般地说,在一个应用中谁采取动作谁就是 agent。
- 状态(State)/观察值(Observation):状态是对世界的完整描述,不会隐藏世界的信息。观测是对状态的部分描述,可能会遗漏一些信息。
- 动作(Action):不同的环境允许不同种类的动作,在给定的环境中,有效动作的集合经常被称为动作空间(action space),包括离散动作空间(discrete action spaces)和连续动作空间(continuous action spaces),例如,走迷宫机器人如果只有东南西北这 4 种移动方式,则其为离散动作空间;如果机器人向 360° 中的任意角度都可以移动,则为连续动作空间。
- 奖励(Reward):是由环境给的一个标量的反馈信号(scalar feedback signal),这个信号显示了智能体在某一步采 取了某个策略的表现如何。
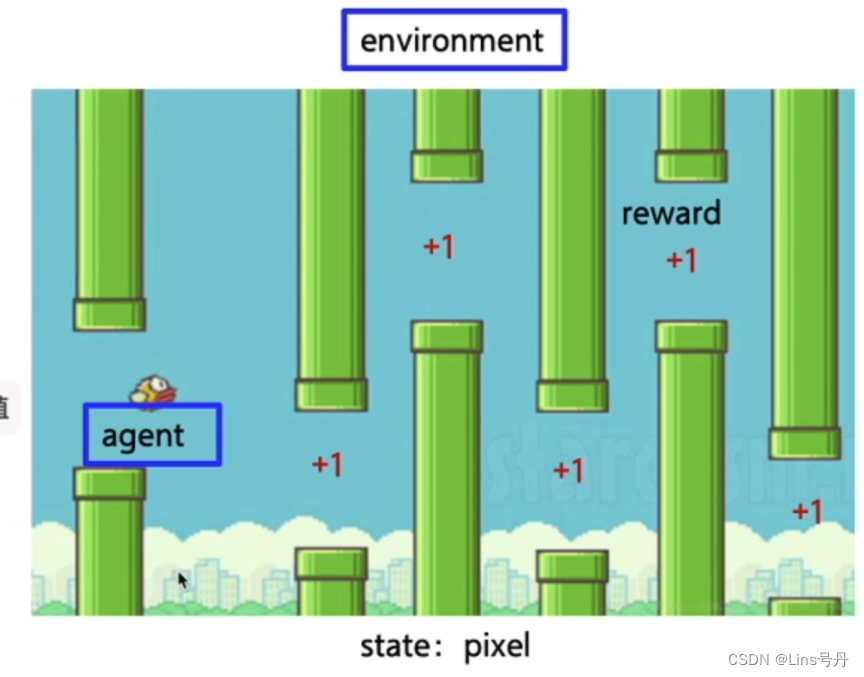
| 强化学习的基本元素 | 对应上图中的内容 |
|---|---|
| agent | 鸟 |
| environment | 鸟周围的环境,水管、天空(包括小鸟本身) |
| state | 拍个照(目前的像素) |
| action | 鸟向上向下动作 |
| reward | 距离(越远奖励越高) |
3. 相关衍生元素
3.1 策略(Policy)
策略是智能体用于决定下一步执行什么行动的规则。可以是确定性的关系,根据一个状态即可决定采取的下一步动作,用符号 μ \mu μ 表示,关系如下:
a t = μ ( s t ) a_t=\mu(s_t) at=μ(st)
智能体采取动作的策略也可以是随机的,即在一个状态下,下一步采取的动作满足一个随机的概率分布,此时概率大的动作被智能体选择的概率较高,用符号 π \pi π 表示:
a t ∼ π ( ⋅ ∣ s t ) a_t\ \sim \pi\left(\cdot \mid \mathrm{s}_{\mathrm{t}}\right) at ∼π(⋅∣st)
一般来说,如果策略过于确定,则容易被针对,即在与别人博弈的过程中难以取胜,因此在很多应用里面的策略函数是一个概率密度函数,让别人不一定能预测到下一步的动作。
3.2 状态转移(State Transition)
状态转移即智能体在采取某一个动作之后,环境的状态发生改变的过程。状态转移过程可以理解为一个概率模型,将状态 s s s 在智能体采取动作 a a a 后转到下一个状态 s ′ s' s′ 的概率设为 P s s ′ a P^a_{ss'} Pss′a,状态转移过程可以是确定的也可以是随机的,一般认为是随机的,它的这种随机性来源于环境。可以用状态密度函数来表示:
p ( s ′ ∣ s , a ) = P ( S ′ = s ′ ∣ S = s , A = a ) p(s'|s,a)=\mathbb{P}(S'=s'|S=s, A=a) p(s′∣s,a)=P(S′=s′∣S=s,A=a)
当前的环境状态 s s s 在智能体的行动 a a a 下,可能转变为不同的 s ′ s' s′,不同的转移后状态用概率函数进行表示,在环境中,这种变化通常是未知的,因此需要在不断的训练当中去探索。
策略动作的随机性,以及环境状态转移的随机性,是强化学习中的两种基本的随机因素。
3.3 回报(Return)
回报又称 cumulated future reward,一般表示为 U U U,定义为:
U t = R t + R t + 1 + R t + 2 + R t + 3 + . . . U_t=R_t+R_{t+1}+R_{t+2}+R_{t+3}+... Ut=Rt+Rt+1+Rt+2+Rt+3+...
其中 R t R_t Rt 表示第 t t t 时刻的奖励 R e w o r d Reword Reword,agent 的目标就是让 R e t u r n Return Return 最大化。这里,我们不仅看当前做出动作后的奖励 R t R_t Rt,还需要看后续的各个时刻的奖励,例如下棋,我们不止看当前步是否能得利,还得看当前步对后续棋盘格局是否有影响,以使得后续也有持续高的回报。
未来的奖励不如现在等值的奖励那么好(比如一年后给 100 块不如现在就给),所以 R t + 1 R_{t+1} Rt+1 的权重应该小于 R t R_t Rt。因此,强化学习通常用 discounted return(折扣回报,又称 cumulative discounted future reward,累计贴现未来奖励),取 γ \gamma γ 为 discount rate(折扣率,有时也叫做奖励衰减因子), γ ∈ ( 0 , 1 ] \gamma\in (0,1] γ∈(0,1],如果 γ = 1 \gamma=1 γ=1,则说明后续的回报与当前的回报一视同仁,具体公式如下:
U t = R t + γ R t + 1 + γ 2 R t + 2 + γ 3 R t + 3 + . . . U_t=R_t+\gamma R_{t+1}+\gamma^2R_{t+2}+\gamma^3R_{t+3}+... Ut=Rt+γRt+1+γ2Rt+2+γ3Rt+3+...
3.4 价值函数(Value Function)
举例来说,在象棋游戏中,定义赢得游戏得1分,其他动作得0分,状态是棋盘上棋子的位置。仅从1分和0分这两个数值并不能知道智能体在游戏过程中到底下得怎么样,而通过价值函数则可以获得更多洞察。
价值函数使用对未来的收益期望进行预测,一方面不必等待未来的收益实际发生就可以获知当前状态的好坏,另一方面通过期望汇总了未来各种可能的收益情况。使用价值函数可以很方便地评价不同策略的好坏。
- v π v_{\pi} vπ 状态价值函数(State-value Function):用来度量给定策略 π \pi π 的情况下,当前状态 s t s_t st 的好坏程度:
v π ( s ) = E π [ G t ∣ S t = s ] v_{\pi}(s)=\mathbb{E}_{\pi}[G_t|S_t=s] vπ(s)=Eπ[Gt∣St=s]
当智能体从状态 s s s 开始,基于策略 π \pi π (随机)选择后续动作所产生的期望回报,代表了该状态 s s s 的价值,即告知当前的局势的好坏程度。
- q π q_{\pi} qπ 动作价值函数(Action-value Function):用来度量给定状态 s t s_t st 和策略 π \pi π 的情况下,采用动作 a t a_t at 的好坏程度:
q π ( s , a ) = E π [ G t ∣ S t = s , A t = a ] q_{\pi}(s,a)=\mathbb{E}_{\pi}[G_t|S_t=s,A_t=a] qπ(s,a)=Eπ[Gt∣St=s,At=a]
当已知智能体的策略函数 π \pi π,则在状态 s s s 下,对当前状态下可以采取的所有动作进行打分,就可以知道采取哪个动作好,哪个动作不好。当然,在不同的动作策略下,对动作的价值判断就不同,而好的动作策略是让博弈的赢面更大,因此最大化 q π q_{\pi} qπ 的 π \pi π 即是最优策略,相应的动作价值函数称为 q ∗ q^* q∗ 最优动作价值函数。
4. 算法分类
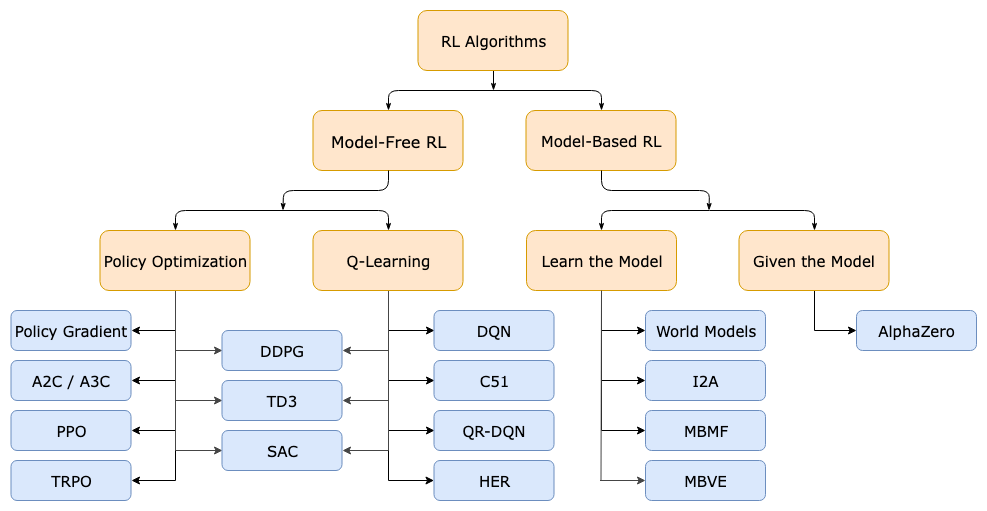
4.1 按环境是否已知划分
按照环境是否已知划分为:免模型学习(Model-Free) 和 有模型学习(Model-Based)。
- Model-free 就是不去学习和理解环境,环境给出什么信息就是什么信息,常见的方法有policy optimization和Q-learning。
- Model-Based 是去学习和理解环境,学会用一个模型来模拟环境,通过模拟的环境来得到反馈。Model-Based 相当于比Model-Free 多了模拟环境这个环节,通过模拟环境预判接下来会发生的所有情况,然后选择最佳的情况。
一般情况下,环境都是不可知的,即无法套用 Model-Based 算法。
4.2 按学习方式划分
按照学习方式划分为:在线策略(On-Policy) 和 离线策略(Off-Policy)。
- On-Policy 是指 agent 必须本人在场, 并且一定是本人边玩边学习。典型的算法为 Sarsa。
- Off-Policy 是指 agent 可以选择自己玩, 也可以选择看着别人玩, 通过看别人玩来学习别人的行为准则, 离线学习同样是从过往的经验中学习, 但是这些过往的经历没必要是自己的经历, 任何人的经历都能被学习,也没有必要是边玩边学习,玩和学习的时间可以不同步。典型的方法是 Q-learning,以及 Deep-Q-Network。
4.3 按学习目标划分
按照学习目标划分:基于价值(Value-Based)和基于策略(Policy-Based) 。
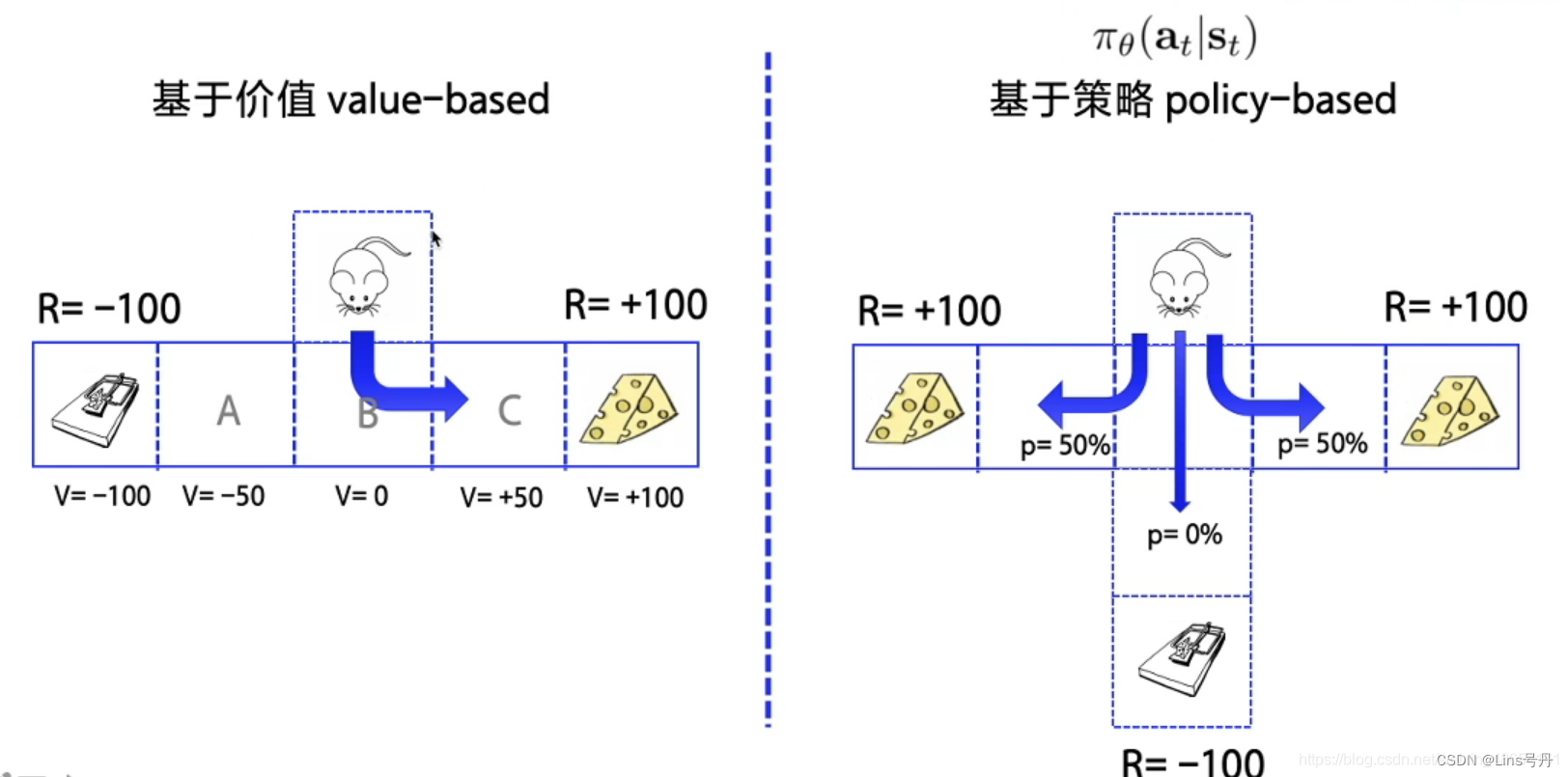
- 基于价值 Value-Based 的方法通过训练得到 Q 表或者是近似一个价值函数,并以此判断动作价值,制定相应的策略。该方法适用于非连续的动作。
- 这类方法具有较高的稳定性和更容易解释的理论;
- 不适用于高维(连续)问题等的复杂问题,当问题复杂时容易受到噪声干扰,收敛性较差,且对参数即为敏感;
- 常见的方法有 Q-learning、DQN和Sarsa。
- 基于策略 Policy-Based 的方法通过直接学习最优策略来指导决策,在处理连续动作空间,和高维状态空间时具有较强的适应性。
- 这类方法具有较高的适应性,且能够处理随机策略;
- 由于是直接优化策略,最终的策略方法可能具有较高方差,且一些策略方法需要大量的采样来准确估计,可能会导致训练时间较长;
- 常见的方法有 Policy gradients、REINFORCE。
- 更为厉害的方法是二者的结合:Actor-Critic,Actor根据概率做出动作,Critic 根据动作给出价值,以期每次都选取最优动作,从而加速学习过程,常见的有 A2C,A3C,DDPG等。
参考资料
- 张浩在路上:强化学习入门
- 强化学习介绍 / OpenAI Spinning Up
- Reinforcement Learning: An Introduction - Chapter 13: Policy Gradient Method
- Sutton R S. Policy Gradient Methods for Reinforcement Learning with Function Approximation[J]. Submitted to Advances in Neural Information Processing Systems, 1999, 12:1057-1063.
- 强化学习——策略梯度与Actor-Critic算法















 3741
3741











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











