









前言:
上篇我们介绍了scrapy的安装和基本的使用,本篇主要补充一个比较实用的操作,就是如何把从URL页面爬取到的数据保存到数据库中,以便于其他地方的使用,这里选择了比较简单的MongoDB作为存储数据的数据库。
一、设置信息:
在scrapy,一些基本的设置都是在settings.py中进行的,为了把爬虫爬取的数据写到数据库中的collection中,我们需要在settings.py中添加几个必要的设置信息。
1.存储使用的管道pipeline的信息:
将爬虫返回的Item数据存入数据库的操作,实际上是通过在pipelines.py脚本中自定义管道类来实现的,但是要让定义的管道正常工作就必须在设置信息中设置指向该管道的信息,打开pipelines.py脚本可以查找到跟pipeline相关的参数只有:
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
#ITEM_PIPELINES = {
# 'MyTest.pipelines.SomePipeline': 300,
#}这就是配置自定义Pipeline类的参数,假设我们在pipelines.py中定义的类名为MytestPipeline,则此时ITEM_PIPELINES的参数应该为:
ITEM_PIPELINES = {
'MyTest.pipelines.MytestPipeline':300,
}这里其实可以给ITEM_PIPELINES配置多个自定义的管道类,所以分配给每个类的整型值,确定了他们运行的顺序,item按数字从低到高的顺序,通过pipeline,通常将这些数字定义在0-1000范围内。
2.连接MongoDB的一些基本参数:
使用过MongoDB的应该清楚,想要连接MongoDB数据库有几个必要的参数需要被指定,包括:ip地址、端口号、db名称和Collection的名称,这些其实对应的几个参数分别是:
- MONGODB_SERVER:数据库所在服务器的ip地址
- MONGODB_PORT:数据库连接对应的端口号
- MONGODB_DB :数据库连接中创建的database名称
- MONGODB_COLLECTION:用于存放数据的文档collection的名称
一般本地测试时,ip通常设置为localhost,端口号由创建数据库时设定的一致,其他两项参数根据所要存入数据的数据库和文档名称对应。这里我使用MongoChef来管理MongoDB数据库,所以相关的参数都能在其中查询到,如下:
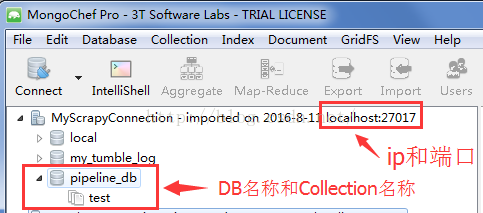
MONGODB_SERVER = "localhost" MONGODB_PORT = 27017 MONGODB_DB = "pipeline_db" MONGODB_COLLECTION = "test"ITEM_PIPELINES = {
'MyTest.pipelines.MytestPipeline':300,
}
MONGODB_SERVER = "localhost"
MONGODB_PORT = 27017
MONGODB_DB = "pipeline_db"
MONGODB_COLLECTION = "test"二、自定义Pipeline类:
- 首先,MytestPipeline类不继承自任何类,所以按照python定义类的规律,此类继承自object;
- 必须重写process_item(self, item, spider)这个方法;
# -*- coding: utf-8 -*-
from pymongo import MongoClient
from scrapy.conf import settings
class MytestPipeline(object):
def __init__(self):
connection = MongoClient(
settings[ 'MONGODB_SERVER' ],
settings[ 'MONGODB_PORT' ]
)
db = connection[settings[ 'MONGODB_DB' ]]
self.collection = db[settings[ 'MONGODB_COLLECTION' ]]参数:
- item (Item 对象) – 被爬取的item
- spider (Spider 对象) – 爬取该item的spider
# -*- coding: utf-8 -*-
from pymongo import MongoClient
from scrapy.conf import settings
from scrapy import log
class MytestPipeline(object):
def __init__(self):
connection = MongoClient(
settings[ 'MONGODB_SERVER' ],
settings[ 'MONGODB_PORT' ]
)
db = connection[settings[ 'MONGODB_DB' ]]
self.collection = db[settings[ 'MONGODB_COLLECTION' ]]
def process_item(self, item, spider):
valid=True
for data in item:
if not data:
valid=False
raise DropItem('Missing{0}!'.format(data))
if valid:
self.collection.insert(dict(item))
log.msg('question added to mongodb database!',
level=log.DEBUG,spider=spider)
return item















 1000
1000

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









