







本来想模仿做一个联系人的快速索引,在敲代码做测试的过程中,想对读取文件获取的联系人进行排序,结果发现有许多排序上的问题。
于是,转移注意力到排序的方法上来,发现确实是有很多需要考虑的东西。
下面就把我在调试这个排序方法的过程给展示一下,说明一下排序中要考虑的方方面面。
1,参考网上部分人提供的方式,是默认的字符顺序来排序
这也是最容易想到的方法,就是一个按字符串的升序排列:
我将名字存放在一个list中:
List<String> listName;在添加了联系人名之后,来进行排序:
Collections.sort(listName, new SortComparator());
/**
* 按字符升序排序,最初的排序方法
* */
class SortComparator implements Comparator {
@Override
public int compare(Object t1, Object t2) {
String a=(String)t1;
String b=(String)t2;
int flag=a.compareTo(b);
if (flag==0){
return a.compareTo(b);
}else{
return flag;
}
}
};然而,这种排序,对于我们中国人来说,不太合适,我们的名字,当然是使用汉字啦。虽然近来也有用英文名的,毕竟还是少数嘛。而汉字按默认的字符顺序排序,拼音相近的姓氏,排序却相差很远。
为什么会这样呢?
我们来简单了解下字符集:
Java使用Unicode字符编码集,它不是按照拼音顺序,基本上是按照CJK编码顺序。
什么是CJK ?其实是Chinese, Japanese, Korean 的缩写啦,叫做 中日韩统一表意文字(CJK Unified Ideographs)。是采用字根分解与合成的方法,简单讲,就是按类似偏旁笔画的划分来排序,而不是按拼音排序的。
所以,我们需要做下一步的工作:
2,对于汉字,转拼音,按字母排序
这里使用的是一个库:pinyin4j-2.5.0.jar
pinyin4j的官方下载地址:http://sourceforge.net/projects/pinyin4j/files/,目前最新的版本就是2.5.0。
库的使用比较简单,就是根据汉字,获取拼音,例如这样:
String[] pinyinArray =PinyinHelper.toHanyuPinyinStringArray('解');为什么返回的是一个字符串数组?因为有多音字啊。
既然说到多音字,就需要选择恰当的读音了。这里采用的是一种比较简单的替换法,就是遇到多音字,转换为我们期望的一个同音的单音字。可以做成一个列表,遇到哪些,就更新进去,也还算方便。
还要考虑一种情况,就是拼音相同,字不同的,不能当成同样的字符来处理,否则会出现这样的排序:
许戈辉,徐静蕾,许晴。
是不是感觉很奇怪,同姓的居然没有挨在一块。所以,在比较到拼音相同时,要继续比较原来的汉字是否相同。对于这一步的汉字比较,我是直接使用默认的字符顺序比较的,就是区分开同音字就行了,没有继续考虑笔画顺序什么的。
3,要按中国人的习惯来,姓按拼音首字母分段,同一段内汉字优先
我们首先关注的是第一个字,也就是姓,按拼音的首字母分割。
对于汉字拼音与英文字母相同的情况,例如:白,B,如何排序?
按首字母分割后,在同一个段内(同一个首字母的情况下),汉字在前,英文字母在后。
4,不是第一个字符时,汉字在所有的字母之前
这一条和第3条很容易混淆,最大的区别就在于,第一个字符,作为姓氏,要按首字母来进行分段,而后面的字符不需要考虑这点。
举个例子,有3个联系人:白雪,Baby,崔健。则白雪和Baby这两个联系人要排在B这个段内,而崔健排中C段,所以Baby排中崔健之前。排序为:白雪,Baby,崔健。
又有3个联系人:杨白雪,杨Baby,杨崔健。由于姓是相同的,后面考虑名字时,先排汉字,后排英文字母,所以杨崔健排在杨Baby之前。排序为:杨白雪,杨崔健,杨Baby。
5,排序:汉字、字母、数字、其他
确定了汉字和字母之后,也考虑下其他字符的情况。这里我也没有进行很细致的区分,只是划分成4类:最常用的是汉字,然后外国人使用英文字母,还有就是考虑了数字也会有使用的情况,再剩下的就没有区分了,都当做是“其他”这一项。其排序的优先级,从前面的描述中已经体现了,就是:汉字>字母>数字>其他字符。
6,姓名前后的空格,要去掉
之所以特别提出来说明,是因为我们可能在输入联系人时,不小心就输入了空格。总之,我用我手机中的联系人进行测试时,就遇到了这个问题。由于空格不在26个字母的范围类,搞得那个联系人排到所有字母段之外去了,当时还奇怪了好一会呢。
当然知道了原因,解决起来也很简单,就是调用一次trim()就好了。
7,怎么来比较所有字符
知道了这么多,似乎还是没有想明白,到底怎么进行一个完整的排序。要知道,一个人的名字,可能有好几个字呢。特别是,汉字、英文字母、数字、其他字符混合排序的,虽然概率小,但是我们写程序的人,要都考虑进来呀。
还有拼音与英文字母,以及字符个数不定,到底要判断几次呢,想想就觉得好麻烦啊!
在经过一段时间的混乱后,我忽然想到一个方法,就是递归!
既然能比较好一个字符,就可以递归调用,来比较多个字符,直到某一个字符串结束。
一个汉字的拼音,与字母的比较,只在姓名中的第一个字符处使用。对于其他位置上的汉字与字母,使用更基础的判断(汉字>字母>数字>其他)就可以确定顺序了,根本还用不到拼音呢,只有在都是汉字时才用到。
8,名字中间的空格,不能去掉
这个问题,是在调试过程中发现的。是由于采用了递归,则判断名称中每一个字符时,就不能再使用trim了。所以trim只能最初确定名字时使用一次。
有了上面这么多考虑,基本上排序算法就梳理清楚了。
下面是实现:
/**
* 联系人排序,最终的排序方法
* */
private int compareCallNum=0;//判读是否是第一层的比较(递归调用中)
class SortComparator implements Comparator {
@Override
public int compare(Object lhs, Object rhs) {
compareCallNum = 0;
return compareString((String)lhs,(String)rhs);
}
}
//只比较一个字符,递归调用
public int compareString(String lhs, String rhs) {
compareCallNum++;
//判断第一个字符,汉字最前,其次字母,然后是数字,若有其他符号,放在最后
String nameA = lhs;//.trim();//注意,由于递归调用,所以此处不能再使用trim了
String nameB = rhs;//.trim();
//若存在长度为0的情况:
if((nameA.length()==0)&&(nameB.length()==0)){
return 0;
} else if(nameA.length()==0){
return -1;
} else if(nameB.length()==0){
return 1;
}
String firstStrA = nameA.substring(0,1);
String firstStrB = nameB.substring(0,1);
//先从类型上来区分:汉字>字母>数字>其他符号,若类型不同,立即出比较的结果
//但是汉字与字母,由于存在首字母的分段,所以先不区分开
int typeA = getFirstCharType(nameA);
int typeB = getFirstCharType(nameB);
if(typeA>typeB){
LogUtil.logWithMethod(new Exception(),"nameA="+nameA+" nameB="+nameB);
return -1;//返回负值,则往前排
} else if(typeA<typeB){
LogUtil.logWithMethod(new Exception(),"nameA="+nameA+" nameB="+nameB);
return 1;
}
//类型相同,需要进行进一步的比较
int compareResult ;
//不是字母与汉字
if(typeA<9 && typeB<9){
compareResult = firstStrA.compareTo(firstStrB);
if(compareResult!=0){
//若不同,立即出来比较结果
LogUtil.logWithMethod(new Exception(),"nameA="+nameA+" nameB="+nameB);
return compareResult;
} else {
//若相同,则递归调用
return compareString(nameA.substring(1),nameB.substring(1));
}
}
//是字母或汉字
//若是首字母,先用第一个字母或拼音进行比较
//否则,先判断字符类型
String firstPinyinA = PinYinStringHelper.getFirstPingYin(nameA).substring(0, 1);
String firstPinyinB = PinYinStringHelper.getFirstPingYin(nameB).substring(0, 1);
if(compareCallNum==1) {
compareResult = firstPinyinA.compareTo(firstPinyinB);
if (compareResult != 0) {
LogUtil.logWithMethod(new Exception(), "nameA=" + nameA + " nameB=" + nameB + " compareResult=" + compareResult);
return compareResult;
}
}
//若首字的第一个字母相同,或不是首字,判断原字符是汉字还是字母,汉字排在前面
typeA = getFirstCharType2(nameA);
typeB = getFirstCharType2(nameB);
if(typeA>typeB){
LogUtil.logWithMethod(new Exception(),"nameA="+nameA+" nameB="+nameB);
return -1;
} else if(typeA<typeB){
LogUtil.logWithMethod(new Exception(),"nameA="+nameA+" nameB="+nameB);
return 1;
}
//不是首字母,在字符类型之后判断,第一个字母或拼音进行比较
if(compareCallNum!=1) {
compareResult = firstPinyinA.compareTo(firstPinyinB);
if (compareResult != 0) {
LogUtil.logWithMethod(new Exception(), "nameA=" + nameA + " nameB=" + nameB + " compareResult=" + compareResult);
return compareResult;
}
}
if(isLetter(nameA)&&isLetter(nameB)) {
//若是同一个字母,还要比较下大小写
compareResult = firstStrA.compareTo(firstStrB);
if (compareResult != 0) {
LogUtil.logWithMethod(new Exception(),"nameA="+nameA+" nameB="+nameB+" compareResult="+compareResult);
return compareResult;
}
}
if(isHanzi(nameA)&&isHanzi(nameB)) {
//使用姓的拼音进行比较
compareResult = PinYinStringHelper.getFirstPingYin(nameA).compareTo(PinYinStringHelper.getFirstPingYin(nameB));
if (compareResult != 0) {
LogUtil.logWithMethod(new Exception(),"nameA="+nameA+" nameB="+nameB);
return compareResult;
}
//若姓的拼音相同,比较汉字是否相同
compareResult = firstStrA.compareTo(firstStrB);
if (compareResult != 0) {
LogUtil.logWithMethod(new Exception(),"nameA="+nameA+" nameB="+nameB);
return compareResult;
}
}
//若相同,则进行下一个字符的比较(递归调用)
return compareString(nameA.substring(1),nameB.substring(1));
}排序后的效果,上图:
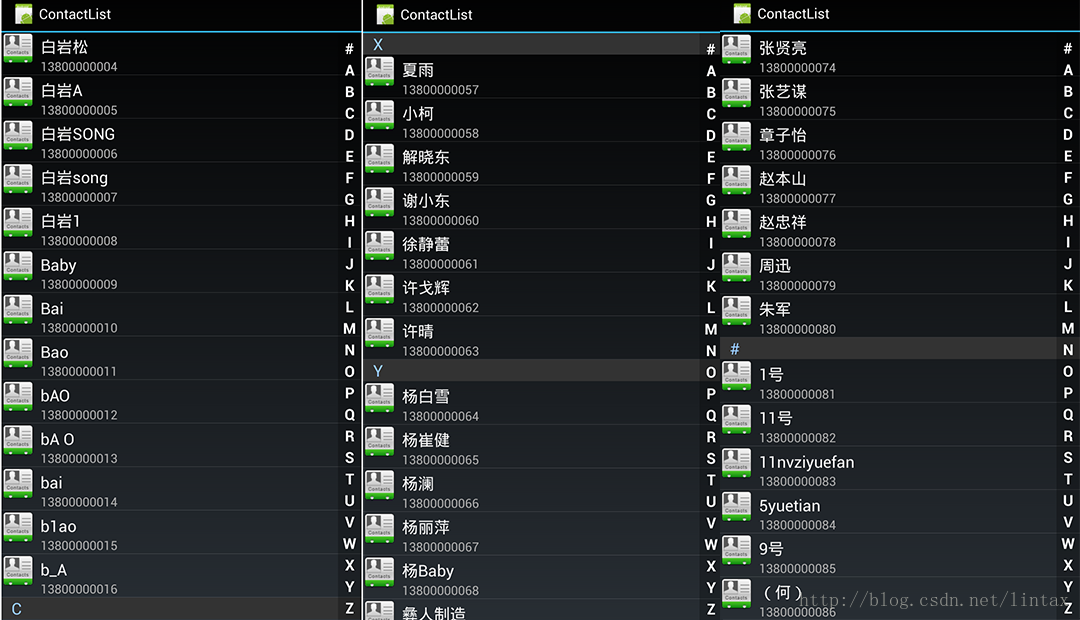
说明:
第一张图展示了汉字与字母、数字、特殊符号的顺序;
第二张图展示了同音汉字的排序,以及同姓时英文字母排序在后的情况;
第三张图展示了以数字与特殊字符开头的联系人排列位置(就是最后啦);
完整的工程,见如下地址:
https://github.com/lintax2017/ContactListDemo
参考:
http://blog.csdn.net/zpp119/article/details/7976139
http://www.javaapk.com/topics/demo/5894.html
http://www.2cto.com/kf/201311/258190.html

















 6246
6246

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









