









数据结构之哈希表
哈希表简介
哈希表又称为散列表(hash table),其主要的思路就是缩小问题规模,通过进行类似分组的方式使被处理的对象排列在不同的小组中,每个小组所要处理的问题规模又相对较小,从而达到提升效率的效果。一般在查询中应用较多。采用术语就是根据关键码值(key value)映射到表中的一个位置来访问记录,以加快查找的速度。这个将关键码值转换的映射函数叫做散列函数,存放记录的数组叫做散列表。
如下图所示就是一个常见的哈希表:
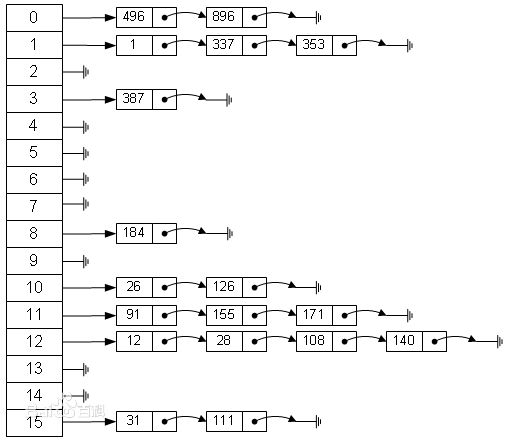
数组中的每个元素都指向了一个链表,这种允许多个关键码值散列到一个数组槽中的hash表叫做开链式哈希表。
通用hash表构建
通过上述的简单分析我们可以发现,hash表的出现就是为了解决单一的数组或单一的链表在查询或插入删除上都有各自的短板,而开链式hash表就是为了将两者的优势结合起来,这样就可以实现更高的查询和删除、添加的效率。但是该类hash表也有一定的隐患,那就是如果运气很不好,所有的关键值码全部都散列到了一个槽内,那么原本的hash表则又退化为了单链表,所以要尽量避免这种情况的出现,最关键的步骤就是设计好哈希函数,让所有的键值尽量的散列均匀。
今天介绍一种开链式的哈希表,要结合前几次的通用双端链的实现,其文件分布如下所示:
下一节将会介绍hash表的具体实现。
hash表实现
我们在hash.h文件中定义了hash表的控制信息,以及hash表的操作接口。内容如下所示:
//hash.h内容
#ifndef _HASH_H_
#define _HASH_H_
#include "dlist.h"
#define FALSE (0)
#define TRUE (1)
#define ZERO (0)
typedef unsigned char Boolean;
typedef int (*Hash_func)(const void *);
typedef struct Hash
{
int bucket_size; //桶的个数
int elem_size; //哈希表元素的个数
Dlist **table; //数据的存储区域
//hash相关函数
int (*hash_func)(const void *key);
//匹配函数
Boolean (*hash_match)(const void *value1, const void *value2);
//元素的销毁函数
void (*hash_free)(void *ptr);
}Hash;
//哈希表接口
Hash *init_hash(int b_size, Hash_func hash_func); //hash初始化
void destroy_hash(Hash **hash) ; //哈希表的销毁
Boolean hash_insert(Hash *hash, const void *value) ; //哈希表的插入
Boolean hash_remove(Hash *hash, const void *value) ; //哈希表的删除
Boolean hash_loop_up(Hash *hash, const void *value); //哈希表的查找
int get_element_count(Hash *hash) ; //得到哈希表内元素个数
void show_hashtable(Hash *hash) ; //显示哈希表内容
//哈希函数
int int_hash_func(const void *key);
#endif我们在hash.h文件中提出了hash表的插入和删除以及查找等关键的接口声明,在hash.c文件中将会对上述的接口进行定义:
//hash.c内容
#include <stdio.h>
#include <stdlib.h>
#include <strings.h>
#include "hash.h"
#include "tools.h"
//哈希表接口
Hash *init_hash(int b_size, Hash_func hash_func) //hash初始化
{
Hash *hash = (Hash *)Malloc(sizeof(Hash));
hash->bucket_size = b_size; //指定桶的个数
hash->elem_size = 0; //hash表初始元素个数为0
hash->hash_match = NULL;
hash->hash_free = NULL;
hash->hash_func = hash_func;
//先申请各个桶的地址,但不对桶初始化,知道该桶被使用的时候
//再临时进行初始化
hash->table = (Dlist **)malloc(sizeof(Dlist *) * b_size);
if(hash->table == NULL){
free(hash);
fprintf(stderr, "the memory is full!\n");
exit(1);
}
bzero(hash->table, sizeof(Dlist *) * b_size);
return hash;
}
void destroy_hash(Hash **hash) //哈希表的销毁
{
int i = 0;
int bucket_size = 0;
Hash *p_hash = NULL;
//销毁步骤:
//
//1.销毁每一个桶(双端链表);
//2.销毁table;
//3.销毁hash;
if(hash == NULL || *hash == NULL){
return ;
}
p_hash = *hash;
bucket_size = p_hash->bucket_size;
for(i = 0; i < bucket_size; ++i){
destroy_dlist(&(p_hash->table[i]));
}
free(p_hash->table);
free(p_hash);
p_hash = NULL;
}
Boolean hash_insert(Hash *hash, const void *value) //哈希表的插入
{
int bucket = 0;
if(hash == NULL || value == NULL
|| hash_loop_up(hash, value) == TRUE){
//如果hash表不存在或者元素已经插入到hash表中,则不进行插入操作
return FALSE;
}
//通过hash函数判断将元素插入到指定下标的桶中
bucket = hash->hash_func(value) % hash->bucket_size;
//采用头部插入方法
push_front(hash->table[bucket], (void *)value);
hash->elem_size++;
return TRUE;
}
Boolean hash_remove(Hash *hash, const void *value) //哈希表的删除
{
int bucket = 0; //被删除元素所在的桶的下标
Dlist_node *p_node = NULL;
if(hash == NULL || value == NULL || hash->elem_size <= ZERO){
return FALSE;
}
//找到元素所在的桶
bucket = hash->hash_func(value) % hash->bucket_size;
for(p_node = dlist_head(hash->table[bucket]);
p_node != NULL;
p_node = next_node(p_node)){
//先寻找,再删除
if(hash->hash_match != NULL){
if(hash->hash_match(p_node->data, value) == TRUE){
remove_dlist_node(hash->table[bucket], p_node, NULL);
hash->elem_size--;
return TRUE;
}
}else{
if(p_node->data == value){
remove_dlist_node(hash->table[bucket], p_node, NULL);
hash->elem_size--;
return TRUE;
}
}
}
return FALSE;
}
Boolean hash_loop_up(Hash *hash, const void *value) //哈希表的查找
{
//1.通过value和hash_func计算出在元素在哪个桶中;
//2.在指定的桶中查找元素是否存在,如果存在返回TRUE,
//不存在返回FALSE;
int bucket = 0;
Dlist_node *p_node = NULL;
if(hash == NULL || value == NULL){
return FALSE;
}
//step 1
bucket = hash->hash_func(value) % hash->bucket_size;
//如果这个桶不存在,则需要对桶进行初始化
if(hash->table[bucket] == NULL){
hash->table[bucket] = init_dlist();
return FALSE;
}
//查找操作
for(p_node = dlist_head(hash->table[bucket]);
p_node != NULL;
p_node = next_node(p_node)){
//如果用户设定了匹配方案,则按照该方案判断,否则比较两者的值
if(hash->hash_match != NULL){
if(hash->hash_match(p_node->data, value) == TRUE){
return TRUE;
}
}else{
if(p_node->data == value){
return TRUE;
}
}
}
return FALSE;
}
int get_element_count(Hash *hash) //得到哈希表内元素个数
{
if(hash == NULL){
return -1;
}
return hash->elem_size;
}
void show_hashtable(Hash *hash) //显示哈希表内容
{
int i = 0;
int bucket_size = 0;
if(hash == NULL || hash->elem_size == ZERO){
return ;
}
bucket_size = hash->bucket_size;
//从下标为0的桶到下标为bucket_size - 1的桶逐个打印
for(i = 0; i < bucket_size; ++i){
printf("bucket[%d]:", i);
print_dlist(hash->table[i], print_int);
}
}
int int_hash_func(const void *key)
{
return *(int *)key;
}因为hash表的每个槽中都记录了一个双端链表的接口,所以我们需要引入双端链表的声明和实现,即dlist.h和dlist.c文件,内容分别如下:
//dlist.h内容
//防止头文件的内容被重复包含
#ifndef _DLIST_H_
#define _DLIST_H_
#include <stdio.h>
#include <stdlib.h>
#include <strings.h>
#include "tools.h"
struct Dlist;
typedef struct Dlist Dlist; //双端链表控制信息
struct Dlist_node;
typedef struct Dlist_node Dlist_node; //双短链表节点信息
typedef unsigned char Boolean; //C语言中的布尔值
typedef void (*Print_func)(void *value);
//typedef void (*)(void *value) Print_func;
#if 1
//链表控制信息
struct Dlist{
struct Dlist_node *head; //指向双端链表的头节点
struct Dlist_node *tail; //指向双端链表的尾节点
int count; //双端链表中的元素个数
//释放链表节点数据域
void (*free)(void *ptr); //void (*)(void *ptr) free;
//匹配链表节点数据域
Boolean (*match)(void *val1, void *val2);
//拷贝链表节点数据域
void *(*copy_node)(void *src);
};
//链表节点信息
struct Dlist_node{
struct Dlist_node *prev; //前一个节点指针
struct Dlist_node *next; //后一个节点指针
void *data; //数据(指针)
};
#define ZERO (0)
#define TRUE (1)
#define FALSE (0)
#define ONLY_ONE (1)
#define dlist_head(list) ((list)->head)
#define dlist_tail(list) ((list)->tail)
#define next_node(node) ((node)->next)
#define prev_node(node) ((node)->prev)
#define node_data(node) ((node)->data)
#endif
//双端链表的接口(ADT)
Dlist *init_dlist(void) ; //链表的初始化
void destroy_dlist(Dlist **dlist) ; //链表的销毁
Boolean push_front(Dlist *dlist, void *value); //链表头部插入
Boolean push_back(Dlist *dlist, void *value) ; //链表尾部插入
Boolean pop_back(Dlist *dlist) ; //链表尾部删除
Boolean pop_front(Dlist *dlist) ; //链表头部删除
Boolean insert_prev_node(Dlist *dlist,
Dlist_node *node, void *value) ; //插入指定节点的前边
Boolean insert_next_node(Dlist *dlist,
Dlist_node *node, void *value) ; //插入指定节点的后边
Boolean remove_dlist_node(Dlist *dlist,
Dlist_node *node, void **value) ; //删除链表中的节点
void print_dlist(Dlist *dlist, Print_func print) ; //打印双端链表
Dlist_node *get_index_node(Dlist *dlist, int index) ; //得到下标为index的链表元素
Boolean get_front(Dlist *dlist, void **value) ; //得到链表头节点的数据域
Boolean get_tail(Dlist *dlist, void **value) ; //得到链表尾节点的数据域
int get_dlist_count(Dlist *dlist) ; //得到链表元素个数
//
void print_int(void *value); //打印整形值
#endif//dlist.c内容
#include "dlist.h"
void destroy_dlist(Dlist **dlist) //链表的销毁
{
Dlist_node *p_node = NULL;
if(dlist == NULL || *dlist == NULL){
return ;
}
p_node = (*dlist)->head;
while((*dlist)->head != NULL){
(*dlist)->head = p_node->next;
if((*dlist)->free != NULL){
(*dlist)->free(p_node->data);
}
free(p_node);
p_node = (*dlist)->head;
}
free(*dlist);
*dlist = NULL;
}
static Dlist_node *buy_node(void)
{
Dlist_node *result = (Dlist_node *)Malloc(sizeof(Dlist_node));
bzero(result, sizeof(Dlist_node));
return result;
}
Boolean push_front(Dlist *dlist, void *value) //链表头部插入
{
Dlist_node *node = NULL;
if(dlist == NULL || value == NULL){
return FALSE;
}
node = buy_node();
node->data = value;
if(dlist->count == ZERO){ //链表没有元素时
dlist->head = dlist->tail = node;
}else{
node->next = dlist->head;
dlist->head->prev = node;
dlist->head = node;
}
dlist->count++;
return TRUE;
}
Boolean push_back(Dlist *dlist, void *value) //链表尾部插入
{
Dlist_node *node = NULL;
if(dlist == NULL || value == NULL){
return FALSE;
}
node = buy_node();
node->data =value;
if(dlist->count == ZERO){
dlist->head = dlist->tail = node;
}else{
node->prev = dlist->tail;
dlist->tail->next = node;
dlist->tail = node;
}
dlist->count++;
return TRUE;
}
Boolean pop_back(Dlist *dlist) //链表尾部删除
{
Dlist_node *p_node = NULL;
if(dlist == NULL || dlist->count == ZERO){
return FALSE;
}
p_node = dlist->tail;
if(dlist->count == ONLY_ONE){
dlist->head = dlist->tail = NULL;
}else{
dlist->tail = p_node->prev;
dlist->tail->next = NULL;
}
if(dlist->free != NULL){
dlist->free(p_node->data);
}
free(p_node);
dlist->count--;
return TRUE;
}
Boolean pop_front(Dlist *dlist) //链表头部删除
{
Dlist_node *p_node = NULL;
if(dlist == NULL || dlist->count == ZERO){
return FALSE;
}
p_node = dlist->head;
if(dlist->count == ONLY_ONE){
dlist->head = dlist->tail = NULL;
}else{
dlist->head = p_node->next;
dlist->head->prev = NULL;
}
if(dlist->free != NULL){
dlist->free(p_node->data);
}
free(p_node);
dlist->count--;
return TRUE;
}
Dlist_node *get_index_node(Dlist *dlist, int index) //得到下标为index的链表节点
{
Dlist_node *node = NULL;
int move_count = 0;
if(dlist == NULL || dlist->count == ZERO
|| index < ZERO || index >= dlist->count){
return NULL;
}
node = dlist->head;
move_count = index;
//找到指定下标元素
while(move_count--){
node = node->next;
}
return node;
}
Boolean remove_dlist_node(Dlist *dlist,
Dlist_node *node, void **value) //删除指定节点
{
if(dlist == NULL || node == NULL){
return FALSE;
}
if(value != NULL){ //取得被删除节点数据域信息
*value = node->data;
}
if(node->next == NULL){ //node在尾部
pop_back(dlist);
}else if(node->prev == NULL){
pop_front(dlist);
}else{
node->prev->next = node->next;
node->next->prev = node->prev;
if(dlist->free != NULL){
dlist->free(node->data);
}
free(node); //Free(node)
dlist->count--;
/*
*
* #define Free(node) (node->prev->next = node->next;) \
* (node->next->prev = node->prev;) \
*
*
* */
}
return TRUE;
}
Boolean insert_next_node(Dlist *dlist,
Dlist_node *node, void *value) //插入到指定节点的后边
{
Dlist_node *p_node = NULL;
if(dlist == NULL || node == NULL || value){
return FALSE;
}
p_node = buy_node();
p_node->data = value;
p_node->prev = node;
p_node->next = node->next;
if(node->next == NULL){
dlist->tail = p_node;
}else{
node->next->prev = p_node;
}
node->next = p_node;
dlist->count++;
return TRUE;
}
Boolean insert_prev_node(Dlist *dlist,
Dlist_node *node, void *value) //插入到指定节点的前边
{
Dlist_node *p_node = NULL;
if(dlist == NULL || node == NULL || value == NULL){
return FALSE;
}
p_node = buy_node();
p_node->data = value;
//进行插入操作
p_node->next = node;
p_node->prev = node->prev;
if(node->prev == NULL){ //node为第一个节点
dlist->head = p_node;
}else{ //node不是第一个节点
node->prev->next = p_node;
}
node->prev = p_node;
dlist->count++;
return TRUE;
}
void print_int(void *value)
{
printf("%d ", *(int *)value);
}
void print_dlist(Dlist *dlist, Print_func print) //打印链表信息
{
Dlist_node *p_node = NULL;
if(dlist == NULL || dlist->count == ZERO){
printf("\n");
return ;
}
for(p_node = dlist->head; p_node ; p_node = p_node->next){
print(p_node->data);
}
printf("\n");
}
#if 0
static void *Malloc(size_t size)
{
void *result = NULL;
result = malloc(size);
if(result == NULL){
fprintf(stderr, "the memory is full!\n");
exit(1);
}
return result;
}
#endif
Dlist *init_dlist(void) //双端链表的初始化
{
Dlist *dlist = NULL;
dlist = (Dlist *)Malloc(sizeof(Dlist));
bzero(dlist, sizeof(Dlist)); //对dlist进行初始化
return dlist;
}
Boolean get_front(Dlist *dlist, void **value)
{
if(dlist == NULL || dlist->count == ZERO){
return FALSE;
}
if(value != NULL){
*value = dlist->head->data;
}
return TRUE;
}
Boolean get_tail(Dlist *dlist, void **value)
{
if(dlist == NULL || dlist->count == ZERO){
return FALSE;
}
if(value != NULL){
*value = dlist->tail->data;
}
return TRUE;
}
int get_dlist_count(Dlist *dlist)
{
if(dlist == NULL){
return -1;
}
return dlist->count;
}双端链表的设计中需要借助tools里边的工具函数,tools模块也分为两个文件实现,tools.h文件和tools.c文件:
//tools.h内容
#ifndef _TOOLS_H_
#define _TOOLS_H_
// git svn
#include <stdio.h>
#include <stdlib.h>
void *Malloc(size_t size); //申请指定大小堆空间
#endif//tools.c内容
#include "tools.h"
void *Malloc(size_t size)
{
void *result = malloc(size);
if(result == NULL){
fprintf(stderr, "the memory is full!\n");
exit(1);
}
return result;
}在实现了hash的常见操作之后,我们在main.c中对相关接口进行了测试:
//main.c测试模块
#include <stdio.h>
#include <stdlib.h>
#include "tools.h"
#include "hash.h"
#define MAXSIZE (100)
int main(int argc, char **argv)
{
Hash *hash = NULL;
int *array = (int *)Malloc(sizeof(int) * MAXSIZE);
int i = 0;
for(i = 0; i < MAXSIZE; ++i){
array[i] = rand() % 1000;
}
hash = init_hash(10, int_hash_func); //整型hash表初始化
for(i = 0; i < MAXSIZE; ++i){
hash_insert(hash, &array[i]);
}
show_hashtable(hash);
destroy_hash(&hash); //hash表的销毁
return 0;
}
假设随机生成100个整型值散列到十个桶中,可以看到散列的结果如下所示:
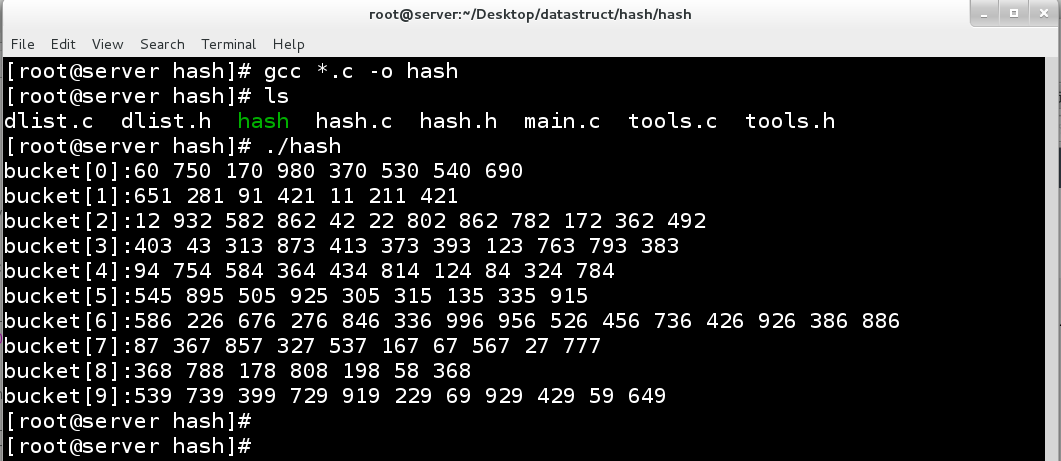
可以看到十个桶内都有元素进行分布,hash表完成
小结:
可以看到上述的十个桶中元素的分布是不同的,如果分布的越均匀,则让后期的查询效率越高,所以我们一定要设计好hash函数,让关键值能够均匀分布,这依赖于高级的算法,借助hash表我们还可以实现原子操作,在后面的章节中将会进行介绍。敬请期待!















 2375
2375

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









