







Scrapy简介
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
Scrapy 是基于twisted框架开发而来,twisted是一个流行的事件驱动的python网络框架。因此Scrapy使用了一种非阻塞(又名异步)的代码来实现并发。整体架构大致如下
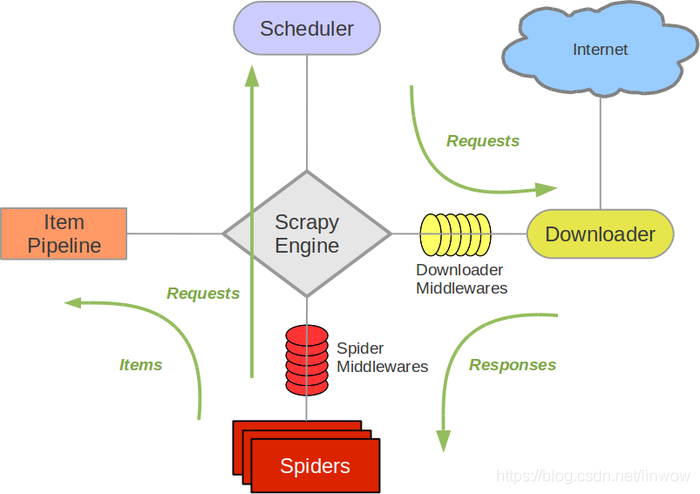
-
引擎(EGINE)
引擎负责控制系统所有组件之间的数据流,并在某些动作发生时触发事件。
-
调度器(SCHEDULER)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL的优先级队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 -
下载器(DOWLOADER)
用于下载网页内容, 并将网页内容返回给EGINE,下载器是建立在twisted这个高效的异步模型上的 -
爬虫(SPIDERS)
SPIDERS是开发人员自定义的类,用来解析responses,并且提取items,或者发送新的请求 -
项目管道(ITEM PIPLINES)
在items被提取后负责处理它们,主要包括清理、验证、持久化(比如存到数据库)等操作 -
下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间,主要用来处理从EGINE传到DOWLOADER的请求request,已经从DOWNLOADER传到EGINE的响应response,你可用该中间件做以下几件事
-
在将请求发送到下载程序之前处理请求(即在Scrapy将请求发送到网站之前)
-
在将它传递给spider之前改变收到的响应
-
发送新的请求,而不是将收到的响应传递给spider
-
在没有抓取网页的情况下将响应传递给蜘蛛
-
放弃一些请求
-
-
爬虫中间件(Spider Middlewares)
位于EGINE和SPIDERS之间,主要工作是处理SPIDERS的输入(即responses)和输出(即requests)
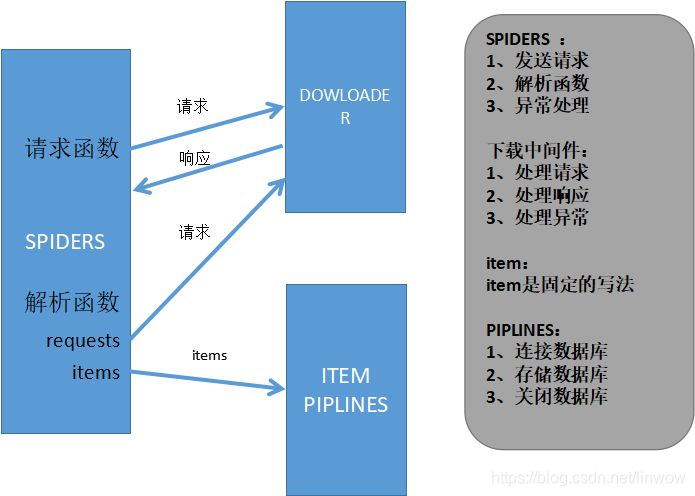
Scrapy的运作流程
代码写好,程序开始运行…
- 1 引擎:Hi!Spider, 你要处理哪一个网站?
- 2 Spider:老大要我处理xxxx.com。
- 3 引擎:你把第一个需要处理的URL给我吧。
- 4 Spider:给你,第一个URL是xxxxxxx.com。
- 5 引擎:Hi!调度器,我这有request请求你帮我排序入队一下。
- 6 调度器:好的,正在处理你等一下。
- 7 引擎:Hi!调度器,把你处理好的request请求给我。
- 8 调度器:给你,这是我处理好的request
- 9 引擎:Hi!下载器,你按照老大的下载中间件的设置帮我下载一下这个request请求
- 10 下载器:好的!给你,这是下载好的东西。(如果失败:sorry,这个request下载失败了。然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载)
- 11 引擎:Hi!Spider,这是下载好的东西,并且已经按照老大的下载中间件处理过了,你自己处理一下(注意!这儿responses默认是交给def parse()这个函数处理的)
- 12 Spider:(处理完毕数据之后对于需要跟进的URL),Hi!引擎,我这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的Item数据。
- 13 引擎:Hi !管道 我这儿有个item你帮我处理一下!调度器!这是需要跟进URL你帮我处理下。然后从第四步开始循环,直到获取完老大需要全部信息。
- 14 管道调度器:好的,现在就做!
注意!只有当调度器中不存在任何request了,整个程序才会停止,(也就是说,对于下载失败的URL,Scrapy也会重新下载。)
参考:https://www.runoob.com/w3cnote/scrapy-detail.html
安装
Windows平台
1、pip3 install wheel #安装后,便支持通过wheel文件安装软件,wheel文件官网:https://www.lfd.uci.edu/~gohlke/pythonlibs
3、pip3 install lxml
4、pip3 install pyopenssl
5、pip3 install pywin32
下载并安装pywin32:https://sourceforge.net/projects/pywin32/files/pywin32/
6、下载twisted的wheel文件:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
7、执行pip3 install 下载目录\Twisted-17.9.0-cp36-cp36m-win_amd64.whl
8、pip3 install scrapy
Linux平台
1、pip3 install scrapy
命令及创建项目
命令行工具
有两种命令:其中Project-only必须切到项目文件夹下才能执行,而Global的命令则不需要
Global commands:
startproject #创建项目
genspider #创建爬虫程序
runspider #运行一个独立的python文件,不必创建项目
shell #scrapy shell url地址 在交互式调试,如选择器规则正确与否
fetch #独立于程单纯地爬取一个页面,可以拿到请求头
Project-only commands:
crawl #运行爬虫,必须创建项目才行,确保配置文件中ROBOTSTXT_OBEY = False
list #列出项目中所包含的爬虫名
bench #scrapy bentch压力测试
用法:
#1、执行全局命令:请确保不在某个项目的目录下,排除受该项目配置的影响
scrapy startproject MyProject
cd MyProject
scrapy genspider baidu www.baidu.com
scrapy settings --get XXX #如果切换到项目目录下,看到的则是该项目的配置
scrapy runspider baidu.py
scrapy shell https://www.baidu.com
response
response.status
response.body
view(response)
scrapy view https://www.taobao.com #如果页面显示内容不全,不全的内容则是ajax请求实现的,以此快速定位问题
scrapy fetch --nolog --headers https://www.taobao.com
scrapy version #scrapy的版本
scrapy version -v #依赖库的版本
#2、执行项目命令:切到项目目录下
scrapy crawl baidu
scrapy check
scrapy list
scrapy parse http://quotes.toscrape.com/ --callback parse
scrapy bench
创建项目
创建一个新的Scrapy项目。进入自定义的项目目录中,运行下列命令:
scrapy startproject mySpider
其中, mySpider 为项目名称,可以看到将会创建一个 mySpider 文件夹,目录结构大致如下:
下面来简单介绍一下各个主要文件的作用:
mySpider/
scrapy.cfg
mySpider/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
tmall.py
myspider2.py
...
文件说明
- scrapy.cfg:项目的主配置信息,用来部署scrapy时使用,爬虫相关的配置信息在settings.py文件中。
- mySpider/:项目的Python模块,将会从这里引用代码。
- mySpider/items.py: 设置数据存储模板,用于结构化数据,如:Django的Model。
- mySpider/pipelines.py: 数据处理行为,如:一般结构化的数据持久化。
- mySpider/settings.py: 项目的设置文件。强调:配置文件的选项必须大写否则视为无效,正确写法USER_AGENT=‘xxxx’
- mySpider/spiders:存储爬虫代码目录。
制作爬虫
在项目目录下输入命令,将在mySpider/spider目录下创建一个名为tmall的爬虫,并指定爬取域的范围:
scrapy genspider tmall "itcast.cn"
Spiders
Spiders是由一系列类(定义了一个网址或一组网址将被爬取)组成,具体包括如何执行爬取任务并且如何从页面中提取结构化的数据。
1、生成初始的Requests来爬取第一个URLS,并且标识一个回调函数
第一个请求定义在start_requests()方法内默认从start_urls列表中获得url地址来生成Request请求,默认的回调函数是parse方法。回调函数在下载完成返回response时自动触发
2、在回调函数中,解析response并且返回值
3、在回调函数中解析页面内容
4、最后,针对返回的Items对象将会被持久化到数据库
中间件
下载中间件的用途
1、在process——request内,自定义下载,不用scrapy的下载
2、对请求进行二次加工,比如
设置请求头
设置cookie
添加代理
scrapy自带的代理组件:
from scrapy.downloadermiddlewares.httpproxy import HttpProxyMiddleware
from urllib.request import getproxies
class DownMiddleware1(object):
def process_request(self, request, spider):
"""
请求需要被下载时,经过所有下载器中间件的process_request调用
:param request:
:param spider:
:return:
None,继续后续中间件去下载;
Response对象,停止process_request的执行,开始执行process_response
Request对象,停止中间件的执行,将Request重新调度器
raise IgnoreRequest异常,停止process_request的执行,开始执行process_exception
"""
pass
def process_response(self, request, response, spider):
"""
spider处理完成,返回时调用
:param response:
:param result:
:param spider:
:return:
Response 对象:转交给其他中间件process_response
Request 对象:停止中间件,request会被重新调度下载
raise IgnoreRequest 异常:调用Request.errback
"""
print('response1')
return response
def process_exception(self, request, exception, spider):
"""
当下载处理器(download handler)或 process_request() (下载中间件)抛出异常
:param response:
:param exception:
:param spider:
:return:
None:继续交给后续中间件处理异常;
Response对象:停止后续process_exception方法
Request对象:停止中间件,request将会被重新调用下载
"""
return None
settings.py 文件讲解
#==>第一部分:基本配置<===
#1、项目名称,默认的USER_AGENT由它来构成,也作为日志记录的日志名
BOT_NAME = 'Amazon'
#2、爬虫应用路径
SPIDER_MODULES = ['Amazon.spiders']
NEWSPIDER_MODULE = 'Amazon.spiders'
#3、客户端User-Agent请求头
#USER_AGENT = 'Amazon (+http://www.yourdomain.com)'
#4、是否遵循爬虫协议
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
#5、是否支持cookie,cookiejar进行操作cookie,默认开启
#COOKIES_ENABLED = False
#6、Telnet用于查看当前爬虫的信息,操作爬虫等...使用telnet ip port ,然后通过命令操作
#TELNETCONSOLE_ENABLED = False
#TELNETCONSOLE_HOST = '127.0.0.1'
#TELNETCONSOLE_PORT = [6023,]
#7、Scrapy发送HTTP请求默认使用的请求头
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
#===>第二部分:并发与延迟<===
#1、下载器总共最大处理的并发请求数,默认值16
#CONCURRENT_REQUESTS = 32
#2、每个域名能够被执行的最大并发请求数目,默认值8
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#3、能够被单个IP处理的并发请求数,默认值0,代表无限制,需要注意两点
#I、如果不为零,那CONCURRENT_REQUESTS_PER_DOMAIN将被忽略,即并发数的限制是按照每个IP来计算,而不是每个域名
#II、该设置也影响DOWNLOAD_DELAY,如果该值不为零,那么DOWNLOAD_DELAY下载延迟是限制每个IP而不是每个域
#CONCURRENT_REQUESTS_PER_IP = 16
#4、如果没有开启智能限速,这个值就代表一个规定死的值,代表对同一网址延迟请求的秒数
#DOWNLOAD_DELAY = 3
#===>第三部分:智能限速/自动节流:AutoThrottle extension<===
#一:介绍
from scrapy.contrib.throttle import AutoThrottle #http://scrapy.readthedocs.io/en/latest/topics/autothrottle.html#topics-autothrottle
设置目标:
1、比使用默认的下载延迟对站点更好
2、自动调整scrapy到最佳的爬取速度,所以用户无需自己调整下载延迟到最佳状态。用户只需要定义允许最大并发的请求,剩下的事情由该扩展组件自动完成
#二:如何实现?
在Scrapy中,下载延迟是通过计算建立TCP连接到接收到HTTP包头(header)之间的时间来测量的。
注意,由于Scrapy可能在忙着处理spider的回调函数或者无法下载,因此在合作的多任务环境下准确测量这些延迟是十分苦难的。 不过,这些延迟仍然是对Scrapy(甚至是服务器)繁忙程度的合理测量,而这扩展就是以此为前提进行编写的。
#三:限速算法
自动限速算法基于以下规则调整下载延迟
#1、spiders开始时的下载延迟是基于AUTOTHROTTLE_START_DELAY的值
#2、当收到一个response,对目标站点的下载延迟=收到响应的延迟时间/AUTOTHROTTLE_TARGET_CONCURRENCY
#3、下一次请求的下载延迟就被设置成:对目标站点下载延迟时间和过去的下载延迟时间的平均值
#4、没有达到200个response则不允许降低延迟
#5、下载延迟不能变的比DOWNLOAD_DELAY更低或者比AUTOTHROTTLE_MAX_DELAY更高
#四:配置使用
#开启True,默认False
AUTOTHROTTLE_ENABLED = True
#起始的延迟
AUTOTHROTTLE_START_DELAY = 5
#最小延迟
DOWNLOAD_DELAY = 3
#最大延迟
AUTOTHROTTLE_MAX_DELAY = 10
#每秒并发请求数的平均值,不能高于 CONCURRENT_REQUESTS_PER_DOMAIN或CONCURRENT_REQUESTS_PER_IP,调高了则吞吐量增大强奸目标站点,调低了则对目标站点更加”礼貌“
#每个特定的时间点,scrapy并发请求的数目都可能高于或低于该值,这是爬虫视图达到的建议值而不是硬限制
AUTOTHROTTLE_TARGET_CONCURRENCY = 16.0
#调试
AUTOTHROTTLE_DEBUG = True
CONCURRENT_REQUESTS_PER_DOMAIN = 16
CONCURRENT_REQUESTS_PER_IP = 16
#===>第四部分:爬取深度与爬取方式<===
#1、爬虫允许的最大深度,可以通过meta查看当前深度;0表示无深度
# DEPTH_LIMIT = 3
#2、爬取时,0表示深度优先Lifo(默认);1表示广度优先FiFo
# 后进先出,深度优先
# DEPTH_PRIORITY = 0
# SCHEDULER_DISK_QUEUE = 'scrapy.squeue.PickleLifoDiskQueue'
# SCHEDULER_MEMORY_QUEUE = 'scrapy.squeue.LifoMemoryQueue'
# 先进先出,广度优先
# DEPTH_PRIORITY = 1
# SCHEDULER_DISK_QUEUE = 'scrapy.squeue.PickleFifoDiskQueue'
# SCHEDULER_MEMORY_QUEUE = 'scrapy.squeue.FifoMemoryQueue'
#3、调度器队列
# SCHEDULER = 'scrapy.core.scheduler.Scheduler'
# from scrapy.core.scheduler import Scheduler
#4、访问URL去重
# DUPEFILTER_CLASS = 'step8_king.duplication.RepeatUrl'
#===>第五部分:中间件、Pipelines、扩展<===
#1、Enable or disable spider middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'Amazon.middlewares.AmazonSpiderMiddleware': 543,
#}
#2、Enable or disable downloader middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
# 'Amazon.middlewares.DownMiddleware1': 543,
}
#3、Enable or disable extensions
# See http://scrapy.readthedocs.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
#4、Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
# 'Amazon.pipelines.CustomPipeline': 200,
}
#===>第六部分:缓存<===
"""
1. 启用缓存
目的用于将已经发送的请求或相应缓存下来,以便以后使用
from scrapy.downloadermiddlewares.httpcache import HttpCacheMiddleware
from scrapy.extensions.httpcache import DummyPolicy
from scrapy.extensions.httpcache import FilesystemCacheStorage
"""
# 是否启用缓存策略
# HTTPCACHE_ENABLED = True
# 缓存策略:所有请求均缓存,下次在请求直接访问原来的缓存即可
# HTTPCACHE_POLICY = "scrapy.extensions.httpcache.DummyPolicy"
# 缓存策略:根据Http响应头:Cache-Control、Last-Modified 等进行缓存的策略
# HTTPCACHE_POLICY = "scrapy.extensions.httpcache.RFC2616Policy"
# 缓存超时时间
# HTTPCACHE_EXPIRATION_SECS = 0
# 缓存保存路径
# HTTPCACHE_DIR = 'httpcache'
# 缓存忽略的Http状态码
# HTTPCACHE_IGNORE_HTTP_CODES = []
# 缓存存储的插件
# HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
#===>第七部分:线程池<===
REACTOR_THREADPOOL_MAXSIZE = 10
#Default: 10
#scrapy基于twisted异步IO框架,downloader是多线程的,线程数是Twisted线程池的默认大小(The maximum limit for Twisted Reactor thread pool size.)
#关于twisted线程池:
http://twistedmatrix.com/documents/10.1.0/core/howto/threading.html
#线程池实现:twisted.python.threadpool.ThreadPool
twisted调整线程池大小:
from twisted.internet import reactor
reactor.suggestThreadPoolSize(30)
#scrapy相关源码:
D:\python3.6\Lib\site-packages\scrapy\crawler.py
#补充:
windows下查看进程内线程数的工具:
https://docs.microsoft.com/zh-cn/sysinternals/downloads/pslist
或
https://pan.baidu.com/s/1jJ0pMaM
命令为:
pslist |findstr python
linux下:top -p 进程id
#===>第八部分:其他默认配置参考<===
D:\python3.6\Lib\site-packages\scrapy\settings\default_settings.py
参考博客:https://www.cnblogs.com/linhaifeng/articles/7811861.html
实例
默认只能在CMD中执行爬虫,如果要在Pycharm中执行,必须要创建一个开始运行文件,并在文件中添加下面的代码。
#在项目目录下新建:run.py
from scrapy.cmdline import execute
# execute(['scrapy', 'crawl', 'tmall','--nolog']) // 不打印日志
execute(['scrapy', 'crawl', 'tmall'])
tamll.py
import scrapy
from .. import items
# from requests_html import HTML # 可以直接在框架中导入requests_html解析网页
# html = HTML(html='<a>fsfsdf</a>') # 对导入的HTML进行是实例化
class XiaopapaSpider(scrapy.Spider):
name = 'xiaopapa'
allowed_domains = ['list.tmall.com']
start_urls = 'https://list.tmall.com/search_product.htm?q=%C4%D0%D7%B0&totalPage=1&jumpto=1'
custom_settings = {
'DEFAULT_REQUEST_HEADERS':{
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36 LIEBO"
}
}
def start_requests(self):
yield scrapy.Request(url=self.start_urls,callback=self.totalPage_parse,dont_filter=True,errback=self.err_case) #errback会处理所有异常
def totalPage_parse(self, response):
totalPage = int(response.css('[name="totalPage"]::attr(value)').extract_first())
url = self.start_urls.replace('&totalPage=1&jumpto=1','&totalPage=%s&jumpto={}'%totalPage)
for i in range(1,totalPage+1):
next_url = url.format(i)
yield scrapy.Request(url=next_url,callback=self.parse_info,dont_filter=True,errback=self.err_case)
def parse_info(self,response):
product_selector_list = response.css('[class="product "]')
for product_selector in product_selector_list:
product_imgurl = product_selector.css('[class="productImg-wrap"] img::attr(src)').extract_first(product_selector.css('[class="productImg-wrap"] img::attr(data-ks-lazyload)').extract_first())
# print(product_imgurl)
product_title = product_selector.css('[class="productTitle"] a::attr(title)').extract_first(None)
print(product_title)
product_price = product_selector.css('[class="productPrice"] em::attr(title)').extract_first(None)
# print(product_price)
item = items.DemoItem()
item['product_imgurl'] = product_imgurl
item['product_title'] = product_title
item['product_price'] = product_price
yield item
def err_case(self,res):
print(res)
print("我是错误回调")
items.py
import scrapy
class DemoItem(scrapy.Item):
product_imgurl = scrapy.Field()
product_title = scrapy.Field()
product_price = scrapy.Field()
pipelines.py
import pymongo
class DemoPipeline(object):
def __init__(self,MONGO_INFO_DICT,MONGO_DB,MONGO_TABLE):
self.MONGO_INFO_DICT = MONGO_INFO_DICT
self.MONGO_DB = MONGO_DB
self.MONGO_TABLE = MONGO_TABLE
@classmethod
def from_crawler(cls, crawler):
"""
Scrapy会先通过getattr判断我们是否自定义了from_crawler,有则调它来完
成实例化
"""
MONGO_INFO_DICT = crawler.settings.get('MONGO_INFO_DICT')
MONGO_DB = crawler.settings.get('MONGO_DB')
MONGO_TABLE = crawler.settings.get('MONGO_TABLE')
return cls(MONGO_INFO_DICT,MONGO_DB,MONGO_TABLE)
def open_spider(self,spider):
"""
爬虫刚启动时执行一次
"""
print('爬虫启动了')
self.client = pymongo.MongoClient(**self.MONGO_INFO_DICT)
self.table = self.client[self.MONGO_DB][self.MONGO_TABLE]
def close_spider(self,spider):
"""
爬虫关闭时执行一次
"""
print('爬虫结束了')
self.client.close()
def process_item(self, item, spider):
product_dict = dict(item)
self.table.insert(product_dict)
print("%s写入成功"%product_dict)
return item
settings.py
BOT_NAME = 'demo'
SPIDER_MODULES = ['demo.spiders']
NEWSPIDER_MODULE = 'demo.spiders'
MONGO_INFO_DICT = { # 配置数据库相关信息
'host':"127.0.0.1",
'port':27017,
'username':"root",
'password':'mongodb',
}
MONGO_DB = "tamllProduct"
MONGO_TABLE = "tmall"
ROBOTSTXT_OBEY = False # 这里要设置为False,不遵循robotstxt
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36"
}
DOWNLOADER_MIDDLEWARES = {
'demo.middlewares.DemoDownloaderMiddleware1': 300, # 300是权重,小的先执行
}
ITEM_PIPELINES = {
'demo.pipelines.DemoPipeline': 300,
'demo.pipelines.DemoPipeline_file': 400,
}
middlewares.py ,用来增加代理ip
from scrapy.exceptions import IgnoreRequest
from scrapy import signals
from scrapy.http import Response,Request
import requests
def get_proxy():
return requests.get("http://127.0.0.1:5010/get/").text
def delete_proxy(proxy):
requests.get("http://127.0.0.1:5010/delete/?proxy={}".format(proxy))
class DemoSpiderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the spider middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_spider_input(self, response, spider):
# Called for each response that goes through the spider
# middleware and into the spider.
# Should return None or raise an exception.
return None
def process_spider_output(self, response, result, spider):
# Called with the results returned from the Spider, after
# it has processed the response.
# Must return an iterable of Request, dict or Item objects.
for i in result:
yield i
def process_spider_exception(self, response, exception, spider):
# Called when a spider or process_spider_input() method
# (from other spider middleware) raises an exception.
# Should return either None or an iterable of Request, dict
# or Item objects.
pass
def process_start_requests(self, start_requests, spider):
# Called with the start requests of the spider, and works
# similarly to the process_spider_output() method, except
# that it doesn’t have a response associated.
# Must return only requests (not items).
for r in start_requests:
yield r
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)














 302
302











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









