







之前做过数据平台,对于实时数据采集,使用了Flink。现在想想,在数据开发平台中,Flink的身影几乎无处不在,由于之前是边用边学,总体有点混乱,借此空隙,整理一下Flink的内容,算是一个知识积累,同时也分享给大家。
注意:由于框架不同版本改造会有些使用的不同,因此本次系列中使用基本框架是 Flink-1.19.x,Flink支持多种语言,这里的所有代码都是使用java,JDK版本使用的是19。
代码参考:https://github.com/forever1986/flink-study.git
1 Flink 做什么用
1.1 概念
下面截取官方网站的主页这段话描述,来看看Flink是做什么的。

从某个翻译软件可以上面描述可以被翻译为:
数据流上的状态计算
Apache Flink是一个框架和分布式处理引擎,用于无界和有界数据流的有状态计算。Flink被设计成可以在所有常见的集群环境中运行,以内存中的速度和任何规模执行计算。
上面的描述比较晦涩难懂,可以使用简单的话来说:Flink是一个专门处理数据流上数据计算的框架,支持大规模集群环境下运行,并且还能存储计算过程中的中间状态。这里需要对无界和有界数据流进行解释一下:
| \ | 无界流 | 有界流 |
|---|---|---|
| 定义 | 有数据流的开始,但是没有数据流的结束 | 有数据流的开始和结束 |
| 特点 | 数据无休止的,并不会停止 | 数据是有结束的,也就是数据是有一定数量 |
| 场景 | 流处理,数据必须马上处理,不能等待数据都带来之后再处理 | 批处理,可以等待数据到达之后,统一处理 |
1.2 特点
作为数据技术,那么之前类似Spark的框架已经有了,Flink为什么在已经有Spark等数据计算和处理框架的情况下出现呢?主要是它一些不同的特点,解决业务的痛点。以下结合官方给的特点,并简单解释其特点的作用,后续会一一讲到这些特点
1)准确性保证(Correctness guarantees):
- 提供准确一次:了解kafka消息中间件或者数据同步的都知道数据同步过程中可以分为最多一次(At most once)、至少一次(At least once)和精确一次(Exactly once),而这三种方式,在Flink都可以实现。特别是精确一次,保证业务的准确性。
- 事件时间处理:一条数据被计算或者处理,其实有2个时间非常重要,一个是处理时间,一个是事件时间。事件时间是数据产生的时间或者业务时间,而处理时间是计算框架处理这条数据的时间。Flink框架可以非常方便地选择符合你想要的时间,保证业务计算结果的准确性,而之前的框架可能要处理起来非常麻烦或者甚至不支持。
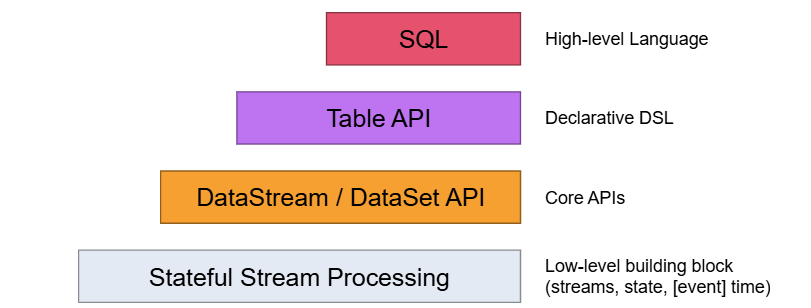
2)分层API(Layered APIs):
Flink提供了不同层级的API,支持从底层处理函数,到DataStream方式,再到中间Table API,以及最后SQL方式,也就是只需要你懂得其中的一种方式,你就可以使用Flink,非常方便。
3)着重操作处理(Operational focus):
- 灵活部署:提供多种部署方式和运行方式,你只需要关注你数据处理的操作,不需要关心在什么部署方式或者运行方式。使得用户能更加关注数据计算和操作。
- 高可用配置:提供很多灵活配置功能,让你的数据计算任务在部署或者运行时可以灵活配置,不需要在编码时就关注高可用问题。
- 保存点:提供可触发式的保存点,使得计算任务可以随时保存,下次任务可以从你保存点之后开始,而无需将数据重新计算一次。
4)可扩展性(Scalability):
- 水平扩展架构:Flink提供多并行度,并且自动分配集群中不同节点,使得计算能够水平扩展。
- 支持非常大的状态:刚才Flink定义中提到它是有状态的计算,所谓的有状态指的是计算过程中可能会需要存储中间计算状态,而Flink支持接入不同可持续化的存储,使得中间状态可以按需配置。
- 增量检查点:配置自动检查点,定时保存任务运行中间状态,避免任务意外中断需要重跑(这里的检查点和上面的保存点,区别在于保存点是主动保存,而检查点是被动定时触发的,并且检查点还支持增量保存,避免每次保存数据量过大)
5)高性能(Performance):
- 低延迟:使用事件驱动方式,使得Flink是触发式的,意味着已有数据就会触发计算,而非传统的定时查询,同时计算和状态都是在内存中完成,因此减低处理时间。从而最终保持数据传输过程中的低延迟。
- 高吞吐:Flink旨在运行任何规模的有状态流应用程序。应用程序可能被并行化为数千个任务,这些任务分布在集群中并发执行。因此,应用程序可以利用几乎无限量的cpu、主存、磁盘和网络IO。因此可以具备很高的吞吐量。
1.3 应用场景
Flink的应用场景由很多,这里就举几个常见的场景:
- 实时计算:比如一些电商场景下的实时计算,经常看到的比如最近5分钟、半小时、一小时、一天的订单量等等,都可以通过这种实时计算方式来实现,而Flink一个应用场景就是实时计算。
- 数据同步:在数据平台中,经常需要做数据同步,从A数据库同步到B数据库,Flink框架由于其设计上的扩展性,可以支持自己编写各种数据源,因此经常用于数据实时同步,并且已经发展出来一个叫Flink-CDC的项目,后面有兴趣的话,专门给它写一个系列。
- 实时监测/报警:在很多业务场景中,常常需要进行实时报警,比如工业中的设备报警、银行中异常行为报警等等,都可以使用Flink进行逻辑运算之后,发送报警信息。
1.4 Spark Streaming的比较
讲到Flink,就不得不提其竞品,而竞品中Spark Streaming是一个具有重量级的对手,因为其使用的广泛度很高。在讲与Spark Streaming比较之前,先回顾之前讲到Flink的概念时,提到的有界流和无界流,同时也提到批处理和流处理。只要了解这几个概念的区别,那么你就能够了解Flink和Spark Streaming的最重要区别:
| \ | Flink | Spark Streaming |
|---|---|---|
| 方式 | 流计算 | 微批处理 |
| 功能 | 支持灵活窗口、状态、以及多种API | 固定窗口、简单状态和较少语言支持 |
| 容错性 | 有检查点和保存点,保持很高的容错性 | 按批处理,可能需要将之前处理过的数据重新处理 |
2 快速入门
前面讲了这么多定义、概念,接下来就开始边实操边讲Flink。下面先使用一个快速入门示例,让大家能快速认识Flink。
代码lesson01:本示例通过3个任务,主要演示批处理和流处理、有界流和无界流的区别。代码参考来自Flink的examples中wordcount示例。
1)新建flink-study工程,该工程只作为一个父模块,关注一些依赖统一版本等功能,其pom引入如下:
<properties>
<maven.compiler.source>19</maven.compiler.source>
<maven.compiler.target>19</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.19.0</flink.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>
</dependencyManagement>
<!-- maven仓库 -->
<repositories>
<repository>
<id>central</id>
<url>https://maven.aliyun.com/repository/central</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
</repositories>
2.1 批处理
示例说明:通过按行读取文件,并将每一行的文字按照空格标点分割,并计算每个单词出现的频率
1)在flink-study下建立子模块lesson01,其pom引入如下:
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<!-- 注意这里的provider代表打包时不打入包中(因为该包在Flink服务器一般都会有),如果你要在IDE运行,需要设置“Add dependencies with "provided" scope to casspath”-->
<scope>provided</scope>
</dependency>
</dependencies>
2)新建WordCountBatchDemo类,代码如下:
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
public class WordCountBatchDemo{
public static void main(String[] args) throws Exception {
// 1. 创建执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 2. 读取数据
DataSource<String> text = env.readTextFile("lesson01/input/sentence.txt");
// 3. 计算
DataSet<Tuple2<String, Integer>> counts =
text.flatMap(new Tokenizer()) // 3.1 切分:按照空格或标点切分每一句中的词,并输出(词,数量)的元组
.groupBy(0) // 3.2 分组:这里的0代表二元组第一个元素,也就是按照词进行分组,分组只是分到不同并行度,并不会改变输出值
.sum(1); // 3.3 聚合:分组之后分别计算,这里的1代表二元组的第二个元素,也就是按照第二个元素进行累积
// 4. 输出
counts.print();
}
/**
* 自定义切分句子的分词器,遇到空格、标点符合都是切割,并输出的是一个Tuple2
*/
public static final class Tokenizer
implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
String[] tokens = value.toLowerCase().split("\\W+");
for (String token : tokens) {
if (token.length() > 0) {
out.collect(new Tuple2<>(token, 1));
}
}
}
}
}
3)与src目录平行的目录下,创建input目录,并创建sentence.txt文件,内容如下:
hello flink
hello,world
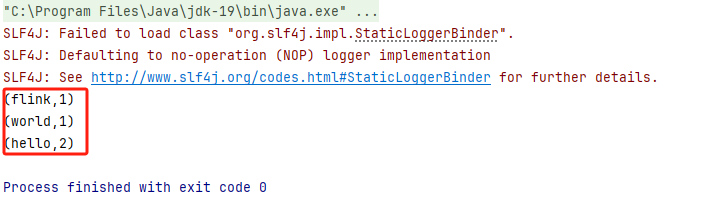
4)运行WordCountBatch类,得到控制台输出如下:(注意:请留意图片中画红色的输出,到时候对比流处理)
2.2 流处理
示例说明:本示例将2.1批处理改为流处理
1)在lesson01子模块下面,新建WordCountStreamDemo类
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class WordCountStreamDemo{
public static void main(String[] args) throws Exception {
// 1. 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 读取数据
DataStreamSource<String> text = env.readTextFile("lesson01/input/sentence.txt");
// 3. 计算
DataStream<Tuple2<String, Integer>> counts =
text.flatMap(new Tokenizer()) // 3.1 切分:按照空格或标点切分每一句中的词,并输出(词,数量)的元组
.keyBy(value -> value.f0) // 3.2 分组:这里的f0代表二元组第一个元素,也就是按照词进行分组,分组只是分到不同并行度,并不会改变输出值
.sum(1); // 3.3 聚合:分组之后分别计算,这里的1代表二元组的第二个元素,也就是按照第二个元素进行累积
// 4. 输出
counts.print();
// 执行
env.execute();
}
/**
* 自定义切分句子的分词器,遇到空格、标点符合都是切割,并输出的是一个Tuple2
*/
public static final class Tokenizer
implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
String[] tokens = value.toLowerCase().split("\\W+");
for (String token : tokens) {
if (!token.isEmpty()) {
out.collect(new Tuple2<>(token, 1));
}
}
}
}
}
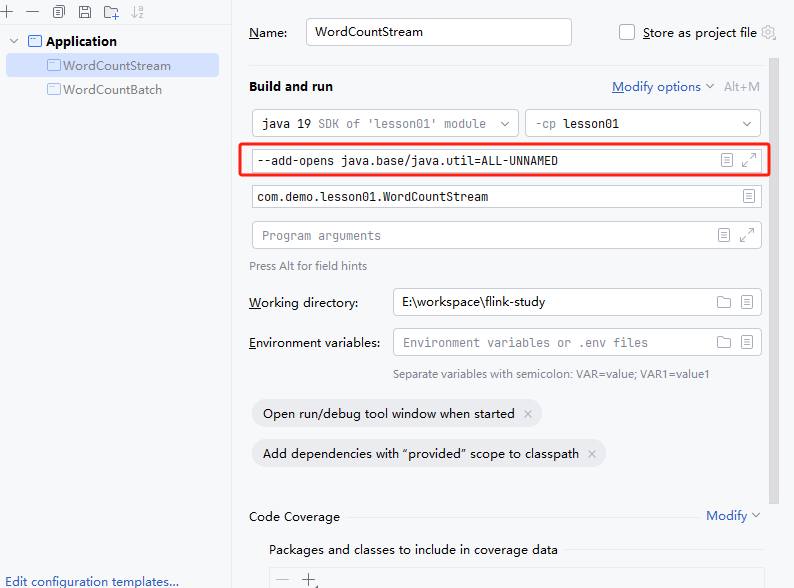
2)注意如果你使用jdk9以上,会出现jdk新引入的模块化管理权限问题,可以在你的IDE上面运行配置如下:
报错异常:

在Add vm options中增加以下参数
3)运行WordCountStream类,得到控制台输出如下:(注意:请留意图片中画红色的输出,到时候对比批处理)
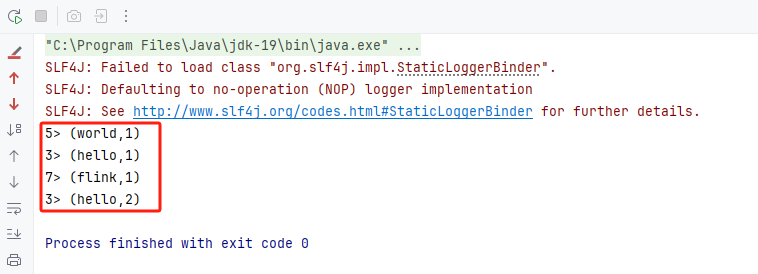
注意:这里可以看到输出有3个不同点:
1)输出前面多了一个“数字>”,这是并行度所在任务的id号
2)hello输出了2次,从1累积到2,这就可以看出流处理与批处理最大不同,流处理是来一条数据处理一条数据,而批处理是等所有数据到齐了,才统一处理。
3)如果你多运行几次,打印的顺序可能不同,但是最终计算结果是一样。这就说明Flink是一个多任务并行处理,前面还在持续读取数据, 后面就已经开始计算之前读取到的数据,每个步骤都是独立的。
2.3 无界流
示例说明:前面2.1和2.2无论是批处理还是流处理,都是读取文件,而文件是一个有界的流,也就是有结束的。下面演示一个无界流情况。使用netcat工具,作为一个输入端,Flink程序可以监听netcat的输入端口,这样就能得到一个无界流。
1)下载netcat工具,并启动,端口为9999

2)在lesson01子模块下面,新建WordCountStreamUnboundedDemo 类,唯一不同的就是读取数据方式:
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class WordCountStreamUnboundedDemo{
public static void main(String[] args) throws Exception {
// 1. 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 读取数据(这里与之前2.1示例不同,是通过监听端口获取数据,也就是一个无界流)
DataStreamSource<String> text = env.socketTextStream("127.0.0.1", 9999);
// 3. 计算
DataStream<Tuple2<String, Integer>> counts =
text.flatMap(new Tokenizer()) // 3.1 切分:按照空格或标点切分每一句中的词,并输出(词,数量)的元组
.keyBy(value -> value.f0) // 3.2 分组:这里的f0代表二元组第一个元素,也就是按照词进行分组,分组只是分到不同并行度,并不会改变输出值
.sum(1); // 3.3 聚合:分组之后分别计算,这里的1代表二元组的第二个元素,也就是按照第二个元素进行累积
// 4. 输出
counts.print();
// 执行
env.execute();
}
/**
* 自定义切分句子的分词器,遇到空格、标点符合都是切割,并输出的是一个Tuple2
*/
public static final class Tokenizer
implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
String[] tokens = value.toLowerCase().split("\\W+");
for (String token : tokens) {
if (!token.isEmpty()) {
out.collect(new Tuple2<>(token, 1));
}
}
}
}
}
3)运行WordCountStreamUnboundedDemo类,这时候可以看到控制台是没有任何输出的
4)在netcat控制台,输入以下数据:

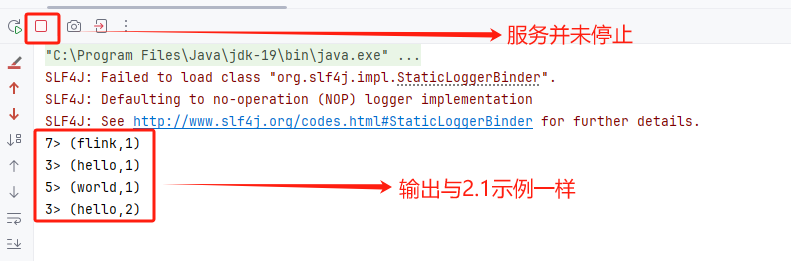
5)再看看控制台的输出,可以看到与2.1示例输出的结果一样,唯一不同的就是控制台的服务并未停止,也就说明还在监听来自netcat的输入:
结语:本章让大家从了解Flink的一些简单概念,到使用3个简单代码示例,最后通过代码的方式验证流处理和批处理,以及无界流和有界流的区别。这算是初步了解了Flink,虽然里面有很多代码可能看不懂,但是接下来的章节将会一一为你剖析




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











