






title: 动手学大模型应用开发之 RAG
authors: Ethan Lin
year: 2024-04-16
tags:
- 类型/笔记
- 日期/2024-04-16
- 传播/CSDN
学习笔记之动手学大模型应用开发之RAG
为保证最合适的体验,建议用 Obsidian 笔记软件打开该笔记之内容。
原书
所有的笔记来自 动手学大模型应用开发 。该笔记仅提供:一些提炼自原书的一些框架概念、一些个人思考。具体细节与实现需要看原书及其对应的程序。
章节笔记
第一章 大模型简介
常见的 LLM 模型
- 闭源 LLM
- GPT系列
- Cloude
- PaLM 系列
- 文言一心
- 星火系列
- 开源LLM
- LLaMA开源大模型
- 通义千问
- GLM系列
- Baichuan
关于 RAG
[!来源]
动手学大模型应用开发-C1-S2
#笔记/定义 #笔记/用途
[[大型语言模型]](LLM)虽然具有强大的能力,然而在某些情况下仍可能无法提供准确的答案。为了解决大型语言模型在生成文本时面临的一系列挑战,提高模型的性能和输出质量,[[检索增强生成]](RAG, Retrieval-Augmented Generation)架构整合了从庞大知识库中检索到的相关信息,并以此为基础,指导大型语言模型生成更为精准的答案,从而显著提升了回答的准确性与深度。
RAG 两大部分:
- 检索
- 生成
大模型根据检索部分的答案片段发挥其自身能力举一反三生成一个回答。这个回答最好能尽可能满足用户的需求。
关于 LangChain
[!来源]
动手学大模型应用开发-C1-S3
#笔记/定义 #笔记/用途
[[LangChain]] 框架是一个开源工具,充分利用了大型语言模型的强大能力,以便开发各种下游应用。它的目标是为各种大型语言模型应用提供通用接口,从而简化应用程序的开发流程。

#笔记/流程
流程图之LangChain
核心组件:
- 模型输入/输出(Model I/O):与语言模型交互的接口
- 数据连接(Data connection):与特定应用程序的数据进行交互的接口
- 链(Chains)将组件组合实现端到端应用。比如后续我们会将搭建
检索问答链来完成检索问答。 - 记忆(Memory):用于链的多次运行之间持久化应用程序状态;
- 代理(Agents)扩展模型的推理能力。用于复杂的应用的调用序列;
- 回调(Callbacks):扩展模型的推理能力。用于复杂的应用的调用序列;
开发 LLM 之流程
[!来源]
动手学大模型应用开发-C1-S4

#笔记/流程
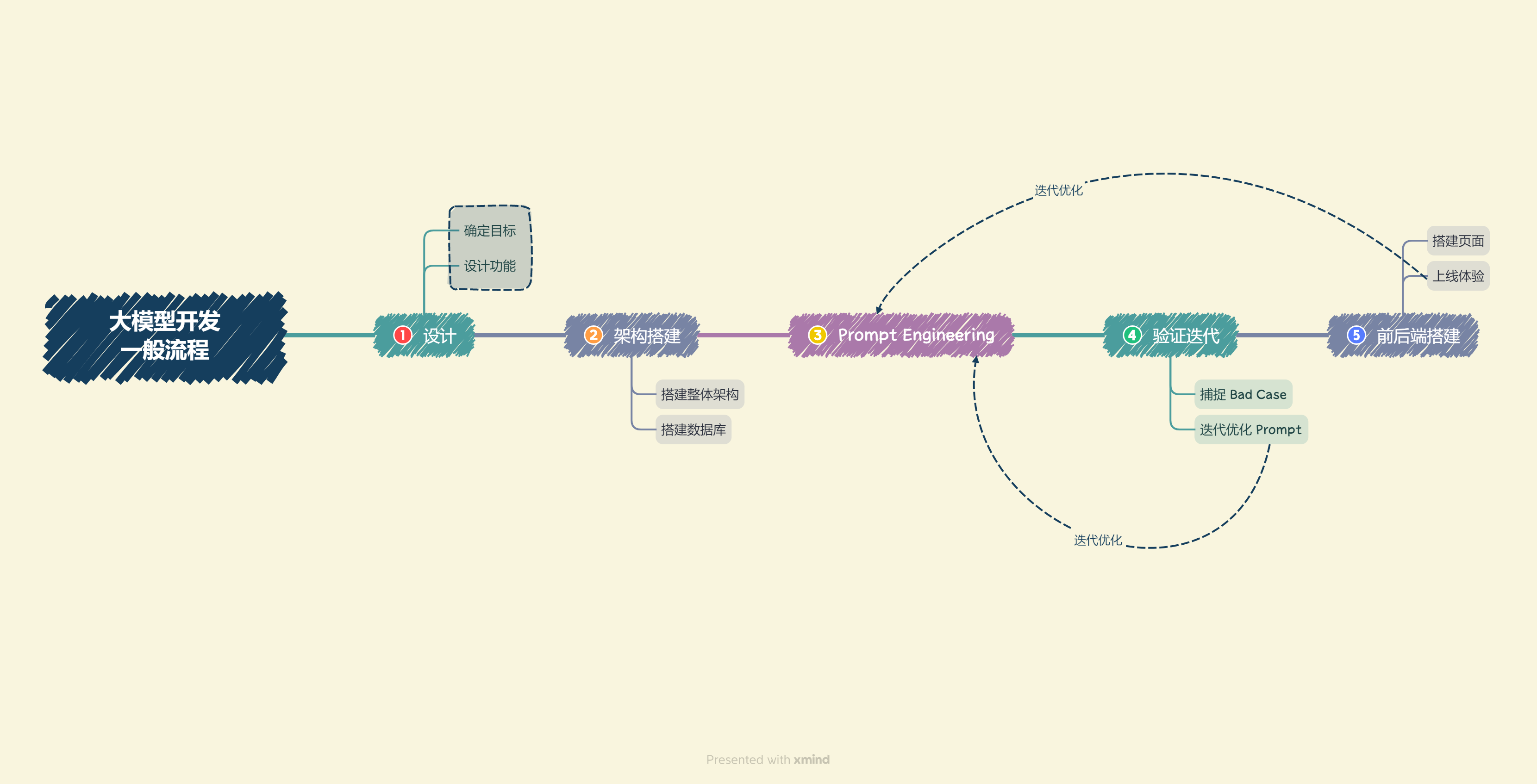
开发 LLM 之流程:
- 确定目标;
- 设计功能;
- 搭建整体架构;
- 搭建数据库;
- Prompt Engineering;
- 验证迭代;
- 前后端搭建;
- 体验优化;
#类型/举例 简要分析知识库助手项目开发流程
配置环境
按照章1节6一步一步动手做。
第二章 使用 LLM API 开发应用
提示 Prompt
#笔记/定义 #笔记/辨析
System Prompt 与 User Prompt 区别在于,前者相当于一种初始化配置,影响这个会话过程。后者相当于Prompt。
#笔记/举例
{
"system prompt": "你是一个幽默风趣的个人知识库助手,可以根据给定的知识库内容回答用户的提问,注意,你的回答风格应是幽默风趣的",
"user prompt": "我今天有什么事务?"
}
#笔记/定义 #笔记/用途
Temperature 参数控制模型生成之随机性发挥想象力。
∈
[
0
,
1
]
\in [0,1]
∈[0,1] 。越小越准确。
使用 LLM API
#笔记/操作
这里使用了智谱 GLM 。
提示工程
Prompt 设计原则
- 编写清晰、具体的指令;
- 分隔符表示输入的不同部分。类似于自然语句从逻辑上正确分段。
- 设计结构化的输出。类似于提供一个答复报告的模板。
- 要求模型检查是否满足条件。这个相当于时常对照检查。
- 提供少量示例。相当于提供一些样例供学习。
- 设定充足思考时间;
- 指定完成任务所需的步骤;
- 指导模型在下结论之前找出一个自己的解法;
假如把大模型类比做乙方。那么这些设计这些原则也适用于甲方与乙方的交互。
#笔记/思考
为了防止或者尽可能验证、纠正幻觉,是否可以采取 Agent 推理回答问题详尽反馈过程,让其它 AI 专家或者人类专家进行监测?此外还需要提供正确的数据库。
第三章 搭建知识库
词向量、向量数据库

词向量(Embeddings)是将文本信息编码成实数向量的技术。该技术在机器学习与 NLP 当中十分基础。
该技术的思路为构建映射。映射左侧的明文信息相似度对应于右侧的编码信息的相似度。如图所示:

优点:对于计算机而言,编码信息更适合检索。
向量数据库更适合大语言模型数据存储。优点是查询效率高于传统数据库。
主流的向量数据库
| 名称 | 编程语言 | 特点 | 优点 | 缺点 | 备注 |
|---|---|---|---|---|---|
| Chroma | - | 开源 | 轻量、适合初学者 | 暂时不支持 GPU | - |
| Weaviate | - | - | - | - | - |
| Qdrant | Rust | - | 效率高 | - | - |
数据处理过程
以 LangChain 为例处理数据过程如下:
-
选择源文档
-
读取数据
- 用 LangChain 的 PyMuPDFLoader 来读取知识库的 PDF 文件;
- 或者用 LangChain 的 UnstructuredMarkdownLoader 读取知识库的 markdown 文件;
-
清洗数据:
一般来说使用常规的清洗技术即可。 -
分割文档:
为了适配模型支持的上下文,需要分割文档。为了保持分割后的文档的连续性,可以考虑在分割不同的块(chunk)值键保留重叠部分

-
搭建向量数据库
搭建向量数据库
因为我选的是智谱模型的 API ,暂时没有被 LangChain 集成。这里直接用了原书对应的工程之封装好的代码。
关于向量检索有几种算法:
- 相似度检索
特点:根据内容的相关性检索内容。 - 最大边际相关性检索
特点:除了根据内容的相关性检索内容之外,还增加了一些探索式的检索方式以增加被检索的内容的多样性。
第四章 构建 RAG 应用
基于 LangChain 调用大模型
以原书对应的教程里封装的代码 zhipuai_llm.py 为例。该代码实现了 LangChain 框架调用智谱 AI 大模型。
构建 RAG 应用步骤:
- LangChain 对接 LLM;
构建检索问答链
部署知识库助手
这里采用了
Stramlit工具包。
#笔记/比较
| 名称 | 用途 | 优点 | 缺点 | 备注 |
|---|---|---|---|---|
| Stramlit | 构建机器学习数据科学用的 Web 应用程序 | 无需编写 HTML/CSS/JS ,直接用 Python 语言构建 | - | |
| Flask | - | - | - | 尚未了解,暂时无法比较 |
| Django | - | - | - | 尚未了解,暂时无法比较 |
速查 Streamlit 之模块
Streamlit 基本模块:
-
st.write():这是最基本的模块之一,用于在应用程序中呈现文本、图像、表格等内容。 -
st.title()、st.header()、st.subheader():这些模块用于添加标题、子标题和分组标题,以组织应用程序的布局。 -
st.text()、st.markdown():用于添加文本内容,支持 Markdown 语法。 -
st.image():用于添加图像到应用程序中。 -
st.dataframe():用于呈现 Pandas 数据框。 -
st.table():用于呈现简单的数据表格。 -
st.pyplot()、st.altair_chart()、st.plotly_chart():用于呈现 Matplotlib、Altair 或 Plotly 绘制的图表。 -
st.selectbox()、st.multiselect()、st.slider()、st.text_input():用于添加交互式小部件,允许用户在应用程序中进行选择、输入或滑动操作。 -
st.button()、st.checkbox()、st.radio():用于添加按钮、复选框和单选按钮,以触发特定的操作。
这些基础模块使得通过 Streamlit 能够轻松地构建交互式数据应用程序,并且在使用时可以根据需要进行组合和定制,更多内容请查看官方文档
第五章 系统评估与优化
评估大模型
评估大模型之思路:
- 系统开发初期,验证集体量小,首先要量化评估。常用的量化方式是进行评分;
- 通过多个维度进行量化评估。维度设计有:
- 知识查找的正确性;
- 回答一致性;
- 回答幻觉比例;
- 回答正确性;
- 逻辑性;
- 通顺性;
- 智能性;
- 各维度的评分权重尽可能一致;
对于不同的 Prompt 版本的不同的提问案例,可以进行排列组合,用人工评估实现。但是如果排列组合数量太大,需要考虑用自动评估。
自动评估
自动评估包括:
- 简单自动评估;
- 大模型自动评估;
- 综合型评估;
简单自动评估方法,有以下方法:
- 构造选择题 Prompt ,对比大模型的答案与标准答案打分;
- 计算答案相似度。例如采用 [[BLEU 算法]] 计算相似度。
大模型自动评估方法,主要通过构造 Prompt Engineering 让大模型充当一个评估者的角色,从而替代人工评估的评估员;同时大模型可以给出类似于人工评估的结果,因此可以采取人工评估中的多维度量化评估的方式,实现快速全面的评估。
#笔记/比较
| 评估方法 | 类型 | 优点 | 缺点 | 备注 |
|---|---|---|---|---|
| 人工评估 | 手动 | 准确度高、全面性强 | 人力成本高、时间成本高 | |
| 简单自动评估 | 自动 | 人力成本低、评估速度快 | 准确度不足、全面性不足 | |
| 大模型自动评估 | 自动 | 兼备上述二者优点 | 需要具备大模型开发经验 |
评估优化检索部分
优化检索的思路。列举一些导致需要优化的常见的问题对应的原因:
- 知识片段被割裂导致答案丢失;
这个主要涉及到知识库以及知识库系统的整个构建体系。因此有必要合理设计知识库。甚至考虑采用[[多智能体知识库系统]]; - Query 提问需要常上下文概括回答;
这个可以考虑使用足够长的上下文的 LLM,或者采用思维链或者[[思维-行动网络形式]]; - 关键词误导;
- 匹配关系不合理;
评估优化生成部分
优化生成部分。列举一些思路:
- 提升直观回答质量;
构建合适的 Prompt 模板; - 标明知识来源;
- 构造思维链;
最简单的方法之一就是拆分 Prompt 为两个步骤:第一步提供回答,第二步反思刚才的回答。 - 增加一层指令解析;
通过类似 Agent 的机制,拆分问题与回答返回的格式。 ^lg05pg
关于 ![[学习笔记之动手学大模型应用开发之RAG#^lg05pg]] 可以进一步学习 LangChain 的 Agent 部分。
探索笔记
- TODO
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}