`define NOP 5'b00000
`define HALT 5'b00001
`define LOAD 5'b00010
`define STORE 5'b00011
`define LDIH 5'b10000
`define ADD 5'b01000
`define ADDI 5'b01001
`define ADDC 5'b10001
`define SUB 5'b01011
`define SUBI 5'b10011
`define SUBC 5'b10111
`define CMP 5'b01100
// control
`define JUMP 5'b11000
`define JMPR 5'b11001
`define BZ 5'b11010
`define BNZ 5'b11011
`define BN 5'b11100
`define BNN 5'b11101
`define BC 5'b11110
`define BNC 5'b11111
// logic / shift
`define AND 5'b01101
`define OR 5'b01111
`define XOR 5'b01110
`define SLL 5'b00100
`define SRL 5'b00110
`define SLA 5'b00101
`define SRA 5'b00111
// general register
`define gr0 3'b000
`define gr1 3'b001
`define gr2 3'b010
`define gr3 3'b011
`define gr4 3'b100
`define gr5 3'b101
`define gr6 3'b110
`define gr7 3'b111
// FSM
`define idle 1'b0
`define exec 1'b1
/******* the whole module CPU is made of Instuction_Mem module, PCPU module and Data_Mem module ********/
module CPU(
input wire clk, clock, enable, reset, start,
input wire[3:0] select_y,
output [7:0] select_segment,
output [3:0] select_bit
);
wire[15:0] d_datain;
wire[15:0] i_datain;
wire[7:0] d_addr;
wire[7:0] i_addr;
wire[15:0] d_dataout;
wire d_we;
wire[15:0] y;
reg [20:0] count = 21'b0;
Instruction_Mem instruction(clock,reset,i_addr,i_datain);
PCPU pcpu(clock, enable, reset, start, d_datain, i_datain,
select_y, i_addr, d_addr, d_dataout, d_we, y);
Data_memory data(clock, reset, d_addr, d_dataout, d_we, d_datain);
Board_eval eval(clk, y, select_segment, select_bit);
endmodule
/************************ Instruction memeory module *****************************/
module Instruction_Mem (
input wire clock, reset,
input wire[7:0] i_addr,
output [15:0] i_datain
);
reg[15:0] i_data[255:0]; // 8 bits pc address to get instructions
reg[15:0] temp;
always@(negedge clock)
begin
if(!reset)
begin
i_data[0] <= {`LOAD, `gr1, 1'b0, `gr0, 4'b0000};
i_data[1] <= {`LOAD, `gr2, 1'b0, `gr0, 4'b0001};
i_data[2] <= {`ADD, `gr3, 1'b0, `gr1, 1'b0, `gr2};
i_data[3] <= {`SUB, `gr3, 1'b0, `gr1, 1'b0, `gr2};
i_data[4] <= {`CMP, `gr3, 1'b0, `gr2, 1'b0, `gr1};
i_data[5] <= {`ADDC, `gr3, 1'b0, `gr1, 1'b0, `gr2};
i_data[6] <= {`SUBC, `gr3, 1'b0, `gr1, 1'b0, `gr2};
i_data[7] <= {`SLL, `gr2, 1'b0, `gr3, 1'b0, 3'b001};
i_data[8] <= {`SRL, `gr3, 1'b0, `gr1, 1'b0, 3'b001};
i_data[9] <= {`SLA, `gr4, 1'b0, `gr1, 1'b0, 3'b001};
i_data[10] <= {`SRA, `gr5, 1'b0, `gr1, 1'b0, 3'b001};
i_data[11] <= {`STORE, `gr3, 1'b0, `gr0, 4'b0010};
i_data[12] <= {`HALT, 11'b000_0000_0000};
end
else
begin
temp = i_data[i_addr[7:0]];
end
end
assign i_datain = temp;
endmodule
/**************************** PCPU module ***************************/
module PCPU(
input wire clock, enable, reset, start,
input wire [15:0] d_datain, // output from Data_Mem module
input wire [15:0] i_datain, // output from Instruction_Mem module
input wire [3:0] select_y, // for the board evaluation
output [7:0] i_addr,
output [7:0] d_addr,
output [15:0] d_dataout,
output d_we,
output [15:0] y
);
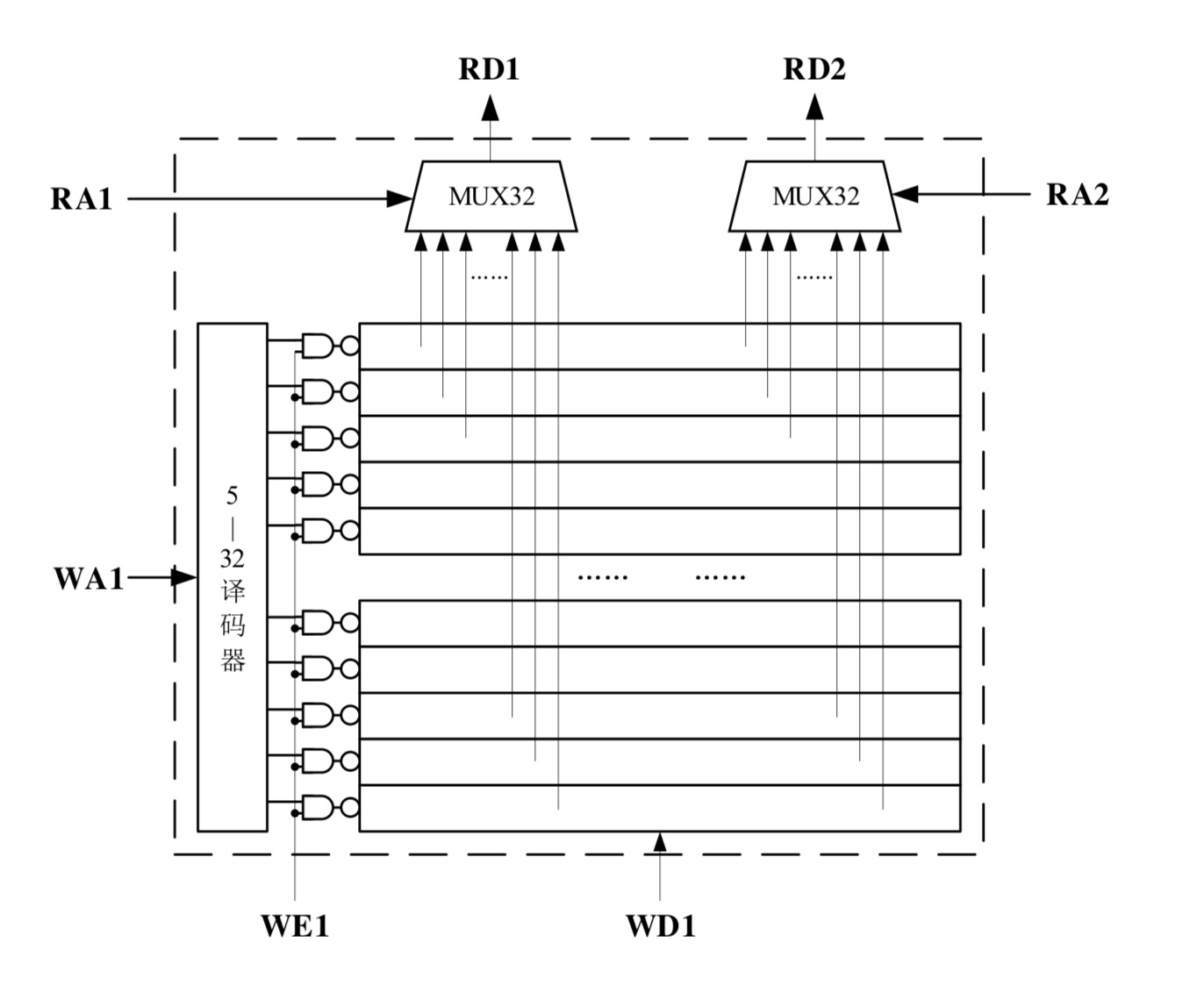
reg [15:0] gr [7:0];
reg nf, zf, cf;
reg state, next_state;
reg dw;
reg [7:0] pc;
reg[15:0] y_forboard;
reg [15:0] id_ir;
reg [15:0] wb_ir;
reg [15:0] ex_ir;
reg [15:0] mem_ir;
reg [15:0] smdr = 0;
reg [15:0] smdr1 = 0;
reg signed [15:0] reg_C1; //有符号
reg signed [15:0] reg_A;
reg signed [15:0] reg_B;
reg signed [15:0] reg_C;
reg signed [15:0] ALUo;
//************* CPU control *************//
always @(posedge clock)
begin
if (!reset)
state <= `idle;
else
state <= next_state;
end
always @(*)
begin
case (state)
`idle :
if ((enable == 1'b1)
&& (start == 1'b1))
next_state <= `exec;
else
next_state <= `idle;
`exec :
if ((enable == 1'b0)
|| (wb_ir[15:11] == `HALT))
next_state <= `idle;
else
next_state <= `exec;
endcase
end
assign i_addr = pc; // 准备下一条指令的地址
//************* IF *************//
always @(posedge clock or negedge reset)
begin
if (!reset)
begin
id_ir <= 16'b0;
pc <= 8'b0;
end
else if (state ==`exec)
// Stall happens in IF stage, always compare id_ir with i_datain to decide pc and id_ir
begin
// 当即将被执行的指令要用到之前load写入的值时, stall two stages , id and ex.
/*
指令中后第二、三个操作数均为寄存器时,需要判断LOAD的第一个操作数是否与这些指令的后两个寄存器有冲突
为一部分算数运算指令和逻辑运算指令
*/
if((i_datain[15:11] == `ADD
||i_datain[15:11] == `ADDC
||i_datain[15:11] == `SUB
||i_datain[15:11] == `SUBC
||i_datain[15:11] == `CMP
||i_datain[15:11] == `AND
||i_datain[15:11] == `OR
||i_datain[15:11] == `XOR)
&&( (id_ir[15:11] == `LOAD && (id_ir[10:8] == i_datain[6:4] || id_ir[10:8] == i_datain[2:0]))
||(ex_ir[15:11] == `LOAD && (ex_ir[10:8] == i_datain[6:4] || ex_ir[10:8] == i_datain[2:0]))
)
) // end if
begin
id_ir <= 16'bx;
pc <= pc; // hold pc
end
/*
指令中第二个操作数为寄存器变量并参与运算时,需要判断LOAD的第一个操作数是否与这些指令的第二个操作数的寄存器有冲突
为移位指令和STORE指令
*/
else if (( i_datain[15:11] == `SLL
||i_datain[15:11] == `SRL
||i_datain[15:11] == `SLA
||i_datain[15:11] == `SRA
||i_datain[15:11] == `STORE)
&&((id_ir[15:11] == `LOAD &&(id_ir[10:8] == i_datain[6:4]))
||(ex_ir[15:11] == `LOAD &&(ex_ir[10:8] == i_datain[6:4]))
)
)
begin
id_ir <= 16'bx;
pc <= pc; // hold pc
end
/*
跳转指令系列,id和ex阶段都需要stall,mem阶段跳转
*/
else if(id_ir[15:14] == 2'b11 || ex_ir[15:14] == 2'b11)
begin
id_ir <= 16'bx;
pc <= pc; // hold pc
end
/* mem阶段跳转 */
else
begin
// BZ & BNZ
if(((mem_ir[15:11] == `BZ)
&& (zf == 1'b1))
|| ((mem_ir[15:11] == `BNZ)
&& (zf == 1'b0)))
begin
id_ir <= 16'bx;
pc <= reg_C[7:0];
end
// BN & BNN
else if(((mem_ir[15:11] == `BN)
&& (nf == 1'b1))
|| ((mem_ir[15:11] == `BNN)
&& (nf == 1'b0)))
begin
id_ir <= 16'bx;
pc <= reg_C[7:0];
end
// BC & BNC
else if(((mem_ir[15:11] == `BC)
&& (cf == 1'b1))
|| ((mem_ir[15:11] == `BNC)
&& (cf == 1'b0)))
begin
id_ir <= 16'bx;
pc <= reg_C[7:0];
end
// JUMP
else if((mem_ir[15:11] == `JUMP)
|| (mem_ir[15:11] == `JMPR))
begin
id_ir <= 16'bx;
pc <= reg_C[7:0];
end
// 非跳转指令且没有检测到冲突
else
begin
id_ir <= i_datain;
pc <= pc + 1;
end
end // end else
end // else reset
end // end always
//************* ID *************//
always @(posedge clock or negedge reset)
begin
if (!reset)
begin
ex_ir <= 16'b0;
reg_A <= 16'b0;
reg_B <= 16'b0;
smdr <= 16'b0;
end
else if (state == `exec)
//Data forwarding happens in ID stage, always check id_ir to decide reg_A/B
begin
ex_ir <= id_ir;
// ********************reg_A 赋值******************* //
/* 其他无冲突的情况 */
// reg_A <= r1: 要用到 r1 参与运算的指令,即除 "JUMP" 外的控制指令和一些运算指令,将寄存器r1中的值赋给reg_A
if ((id_ir[15:14] == 2'b11 && id_ir[15:11] != `JUMP)
|| (id_ir[15:11] == `LDIH)
|| (id_ir[15:11] == `ADDI)
|| (id_ir[15:11] == `SUBI))
reg_A <= gr[id_ir[10:8]];
else if (id_ir[15:11] == `LOAD)
reg_A <= gr[id_ir[6:4]];
// case for data forwarding, 当前指令第2个操作数用到之前指令第1个操作数的结果
else if(id_ir[6:4] == ex_ir[10:8])
reg_A <= ALUo;
else if(id_ir[6:4] == wb_ir[10:8])
reg_A <= reg_C1;
else if(id_ir[6:4] == mem_ir[10:8])
reg_A <= reg_C;
//reg_A <= r2: 如果运算中不用到 r1,要用到 r2, 则将 gr[r2]
else
reg_A <= gr[id_ir[6:4]];
//************************* reg_B赋值************************//
if (id_ir[15:11] == `STORE)
begin
reg_B <= {12'b0000_0000_0000, id_ir[3:0]}; //value3
smdr <= gr[id_ir[10:8]]; // r1
end
// case for data forwarding, 当前指令第3个操作数用到之前指令第1个操作数的结果
else if(id_ir[2:0] == ex_ir[10:8])
reg_B <= ALUo;
else if(id_ir[2:0] == wb_ir[10:8])
reg_B <= reg_C1;
else if(id_ir[2:0] == mem_ir[10:8])
reg_B <= reg_C;
/* 其他无冲突的情况 */
else if ((id_ir[15:11] == `ADD)
|| (id_ir[15:11] == `ADDC)
|| (id_ir[15:11] == `SUB)
|| (id_ir[15:11] == `SUBC)
|| (id_ir[15:11] == `CMP)
|| (id_ir[15:11] == `AND)
|| (id_ir[15:11] == `OR)
|| (id_ir[15:11] == `XOR))
reg_B <= gr[id_ir[2:0]];
end
end
//************* ALUo *************//
always @ (*)
begin
// {val2, val3}
if (ex_ir[15:11] == `JUMP)
ALUo <= {8'b0, ex_ir[7:0]};
// 跳转指令 r1 + {val2, val3}
else if (ex_ir[15:14] == 2'b11)
ALUo <= reg_A + {8'b0, ex_ir[7:0]};
//算数运算,逻辑运算,计算结果到ALUo, 并计算cf标志位
else
begin
case(ex_ir[15:11])
`LOAD: ALUo <= reg_A + {12'b0000_0000_0000, ex_ir[3:0]};
`STORE: ALUo <= reg_A + reg_B;
`LDIH: {cf, ALUo} <= reg_A + { ex_ir[7:0], 8'b0 };
`ADD: {cf, ALUo} <= reg_A + reg_B;
`ADDI:{cf, ALUo} <= reg_A + { 8'b0, ex_ir[7:0] };
`ADDC: {cf, ALUo} <= reg_A + reg_B + cf;
`SUB: {cf, ALUo} <= {{1'b0, reg_A} - reg_B};
`SUBI: {cf, ALUo} <= {1'b0, reg_A }- { 8'b0, ex_ir[7:0] };
`SUBC:{cf, ALUo} <= {{1'b0, reg_A} - reg_B - cf};
`CMP: {cf, ALUo} <= {{1'b0, reg_A} - reg_B};
`AND: {cf, ALUo} <= {1'b0, reg_A & reg_B};
`OR: {cf, ALUo} <= {1'b0, reg_A | reg_B};
`XOR: {cf, ALUo} <= {1'b0, reg_A ^ reg_B};
`SLL: {cf, ALUo} <= {reg_A[4'b1111 - ex_ir[3:0]], reg_A << ex_ir[3:0]};
`SRL: {cf, ALUo} <= {reg_A[ex_ir[3:0] - 4'b0001], reg_A >> ex_ir[3:0]};
`SLA: {cf, ALUo} <= {reg_A[ex_ir[3:0] - 4'b0001], reg_A <<< ex_ir[3:0]};
`SRA: {cf, ALUo} <= {reg_A[4'b1111 - ex_ir[3:0]], reg_A >>> ex_ir[3:0]};
default: begin
end
endcase
end
end
//************* EX *************//
always @(posedge clock or negedge reset)
begin
if (!reset)
begin
mem_ir <= 16'b0;
reg_C <= 16'b0;
dw <= 0;
nf <= 0;
zf <= 0;
smdr1 <= 16'b0;
end
else if (state == `exec)
begin
mem_ir <= ex_ir;
reg_C <= ALUo;
if (ex_ir[15:11] == `STORE)
begin
dw <= 1'b1;
smdr1 <= smdr;
end
// 设置标志位zf, nf, 算数和逻辑运算
else if(ex_ir[15:14] != 2'b11 && ex_ir[15:11] != `LOAD)
begin
zf <= (ALUo == 0)? 1:0;
nf <= (ALUo[15] == 1'b1)? 1:0;
dw <= 1'b0;
end
else
dw <= 1'b0;
end
end
// PCPU module 的输出
assign d_dataout = smdr1;
assign d_we = dw;
assign d_addr = reg_C[7:0];
//************* MEM *************//
always @(posedge clock or negedge reset)
begin
if (!reset)
begin
wb_ir <= 16'b0;
reg_C1 <= 16'b0;
end
else if (state == `exec)
begin
wb_ir <= mem_ir;
if (mem_ir[15:11] == `LOAD)
reg_C1 <= d_datain;
else if(mem_ir[15:14] != 2'b11)
reg_C1 <= reg_C;
end
end
//************* WB *************//
always @(posedge clock or negedge reset)
begin
if (!reset)
begin
gr[0] <= 16'b0;
gr[1] <= 16'b0;
gr[2] <= 16'b0;
gr[3] <= 16'b0;
gr[4] <= 16'b0;
gr[5] <= 16'b0;
gr[6] <= 16'b0;
gr[7] <= 16'b0;
end
else if (state == `exec)
begin
// 回写到 r1
if ((wb_ir[15:14] != 2'b11)
&&(wb_ir[15:11] != `STORE)
&&(wb_ir[15:11] != `CMP)
)
gr[wb_ir[10:8]] <= reg_C1;
end
end
// 板极验证
assign y = y_forboard; // 板极验证需要的输出
always @(select_y)
begin
case(select_y)
4'b0000: y_forboard <= {8'B0,pc};
4'b0001: y_forboard <= id_ir;
4'b0010: y_forboard <= reg_A;
4'b0011: y_forboard <= reg_B;
4'b0100: y_forboard <= smdr;
4'b0101: y_forboard <= ALUo;
4'b0110: y_forboard <= {15'b0, cf};
4'b0111: y_forboard <= {15'b0, nf};
4'b1000: y_forboard <= reg_C;
4'b1001: y_forboard <= reg_C1;
4'b1010: y_forboard <= gr[0];
4'b1011: y_forboard <= gr[1];
4'b1100: y_forboard <= gr[2];
4'b1101: y_forboard<= gr[3];
4'b1110: y_forboard <= gr[4];
4'b1111: y_forboard <= gr[5];
endcase
end
endmodule
/**************************** Data memory module ******************************/
module Data_memory (
input wire clock, reset,
input wire [7:0] d_addr,
input wire [15:0] d_dataout,
input wire d_we,
output [15:0] d_datain
);
reg[15:0] temp;
reg[15:0] d_data[255:0];
always@(negedge clock) begin
if(!reset) begin
d_data[0] <= 16'hFc00;
d_data[1] <= 16'h00AB;
end else if(d_we) begin
d_data[d_addr] <= d_dataout;
end else begin
temp = d_data[d_addr];
end
end
assign d_datain = temp;
endmodule
/**************************** Board evaluation module ******************************/
module Board_eval (
input wire clock,
input wire [15:0] y,
output reg [7:0] select_segment,
output reg [3:0] select_bit
);
parameter SEG_NUM0 = 8'b00000011,
SEG_NUM1 = 8'b10011111,
SEG_NUM2 = 8'b00100101,
SEG_NUM3 = 8'b00001101,
SEG_NUM4 = 8'b10011001,
SEG_NUM5 = 8'b01001001,
SEG_NUM6 = 8'b01000001,
SEG_NUM7 = 8'b00011111,
SEG_NUM8 = 8'b00000001,
SEG_NUM9 = 8'b00001001,
SEG_A = 8'b00010001,
SEG_B = 8'b11000001,
SEG_C = 8'b01100011,
SEG_D = 8'b10000101,
SEG_E = 8'b01100001,
SEG_F = 8'b01110001;
// 位选
parameter BIT_3 = 4'b0111,
BIT_2 = 4'b1011,
BIT_1 = 4'b1101,
BIT_0 = 4'b1110;
reg [20:0] count = 0;
always @ (posedge clock) begin
count <= count + 1'b1;
end
always @ (posedge clock) begin
case(count[19:18])
2'b00: begin
select_bit <= BIT_3;
case(y[15:12])
4'b0000: select_segment <= SEG_NUM0;
4'b0001: select_segment <= SEG_NUM1;
4'b0010: select_segment <= SEG_NUM2;
4'b0011: select_segment <= SEG_NUM3;
4'b0100: select_segment <= SEG_NUM4;
4'b0101: select_segment <= SEG_NUM5;
4'b0110: select_segment <= SEG_NUM6;
4'b0111: select_segment <= SEG_NUM7;
4'b1000: select_segment <= SEG_NUM8;
4'b1001: select_segment <= SEG_NUM9;
4'b1010: select_segment <= SEG_A;
4'b1011: select_segment <= SEG_B;
4'b1100: select_segment <= SEG_C;
4'b1101: select_segment <= SEG_D;
4'b1110: select_segment <= SEG_E;
4'b1111: select_segment <= SEG_F;
endcase
end
2'b01: begin
select_bit <= BIT_2;
case(y[11:8])
4'b0000: select_segment <= SEG_NUM0;
4'b0001: select_segment <= SEG_NUM1;
4'b0010: select_segment <= SEG_NUM2;
4'b0011: select_segment <= SEG_NUM3;
4'b0100: select_segment <= SEG_NUM4;
4'b0101: select_segment <= SEG_NUM5;
4'b0110: select_segment <= SEG_NUM6;
4'b0111: select_segment <= SEG_NUM7;
4'b1000: select_segment <= SEG_NUM8;
4'b1001: select_segment <= SEG_NUM9;
4'b1010: select_segment <= SEG_A;
4'b1011: select_segment <= SEG_B;
4'b1100: select_segment <= SEG_C;
4'b1101: select_segment <= SEG_D;
4'b1110: select_segment <= SEG_E;
4'b1111: select_segment <= SEG_F;
endcase
end
2'b10: begin
select_bit <= BIT_1;
case(y[7:4])
4'b0000: select_segment <= SEG_NUM0;
4'b0001: select_segment <= SEG_NUM1;
4'b0010: select_segment <= SEG_NUM2;
4'b0011: select_segment <= SEG_NUM3;
4'b0100: select_segment <= SEG_NUM4;
4'b0101: select_segment <= SEG_NUM5;
4'b0110: select_segment <= SEG_NUM6;
4'b0111: select_segment <= SEG_NUM7;
4'b1000: select_segment <= SEG_NUM8;
4'b1001: select_segment <= SEG_NUM9;
4'b1010: select_segment <= SEG_A;
4'b1011: select_segment <= SEG_B;
4'b1100: select_segment <= SEG_C;
4'b1101: select_segment <= SEG_D;
4'b1110: select_segment <= SEG_E;
4'b1111: select_segment <= SEG_F;
endcase
end
2'b11: begin
select_bit <= BIT_0;
case(y[3:0])
4'b0000: select_segment <= SEG_NUM0;
4'b0001: select_segment <= SEG_NUM1;
4'b0010: select_segment <= SEG_NUM2;
4'b0011: select_segment <= SEG_NUM3;
4'b0100: select_segment <= SEG_NUM4;
4'b0101: select_segment <= SEG_NUM5;
4'b0110: select_segment <= SEG_NUM6;
4'b0111: select_segment <= SEG_NUM7;
4'b1000: select_segment <= SEG_NUM8;
4'b1001: select_segment <= SEG_NUM9;
4'b1010: select_segment <= SEG_A;
4'b1011: select_segment <= SEG_B;
4'b1100: select_segment <= SEG_C;
4'b1101: select_segment <= SEG_D;
4'b1110: select_segment <= SEG_E;
4'b1111: select_segment <= SEG_F;
endcase
end
endcase
end
endmodule
2).test
`timescale 1ns / 1ps
////////////////////////////////////////////////////////////////////////////////
// Company:
// Engineer:
//
// Create Date: 21:22:32 12/29/2014
// Design Name: CPU
// Module Name: C:/Users/liang/Desktop/embed/CPU/CPU/CPUTest.v
// Project Name: CPU
// Target Device:
// Tool versions:
// Description:
//
// Verilog Test Fixture created by ISE for module: CPU
//
// Dependencies:
//
// Revision:
// Revision 0.01 - File Created
// Additional Comments:
//
////////////////////////////////////////////////////////////////////////////////
module CPU_test;
// Inputs
reg clock;
reg enable;
reg reset;
reg [3:0] select_y;
reg start;
// Outputs
wire [15:0] y;
// Instantiate the Unit Under Test (UUT)
CPU cpu (
.clock(clock),
.enable(enable),
.reset(reset),
.start(start),
.select_y(select_y)
);
initial begin
// Initialize Inputs
clock = 0;
enable = 0;
reset = 0;
select_y = 0;
start = 0;
// Wait 100 ns for global reset to finish
#100;
forever begin
#5
clock <= ~clock;
end
// Add stimulus here
end
initial begin
// Wait 100 ns for global reset to finish
#100;
$display("pc: id_ir : ex_ir :reg_A: reg_B: reg_C: cf: nf: zf: regC1: gr1: gr2: gr3: gr4: gr5:");
$monitor("%h: %b: %b: %h: %h: %h: %h: %h: %h: %h: %h: %h: %h: %h: %h",
cpu.pcpu.pc, cpu.pcpu.id_ir, cpu.pcpu.ex_ir, cpu.pcpu.reg_A, cpu.pcpu.reg_B, cpu.pcpu.reg_C,
cpu.pcpu.cf, cpu.pcpu.nf, cpu.pcpu.zf, cpu.pcpu.reg_C1, cpu.pcpu.gr[1], cpu.pcpu.gr[2], cpu.pcpu.gr[3], cpu.pcpu.gr[4], cpu.pcpu.gr[5]);
enable <= 1; start <= 0; select_y <= 0;
#10 reset <= 0;
#10 reset <= 1;
#10 enable <= 1;
#10 start <=1;
#10 start <= 0;
end
endmodule











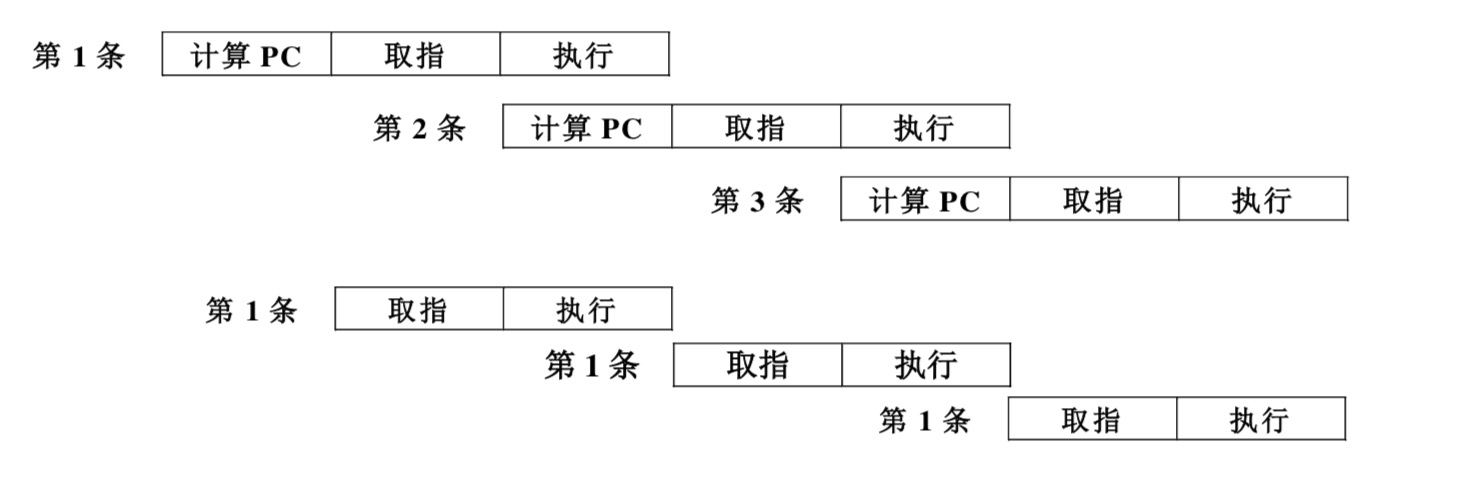
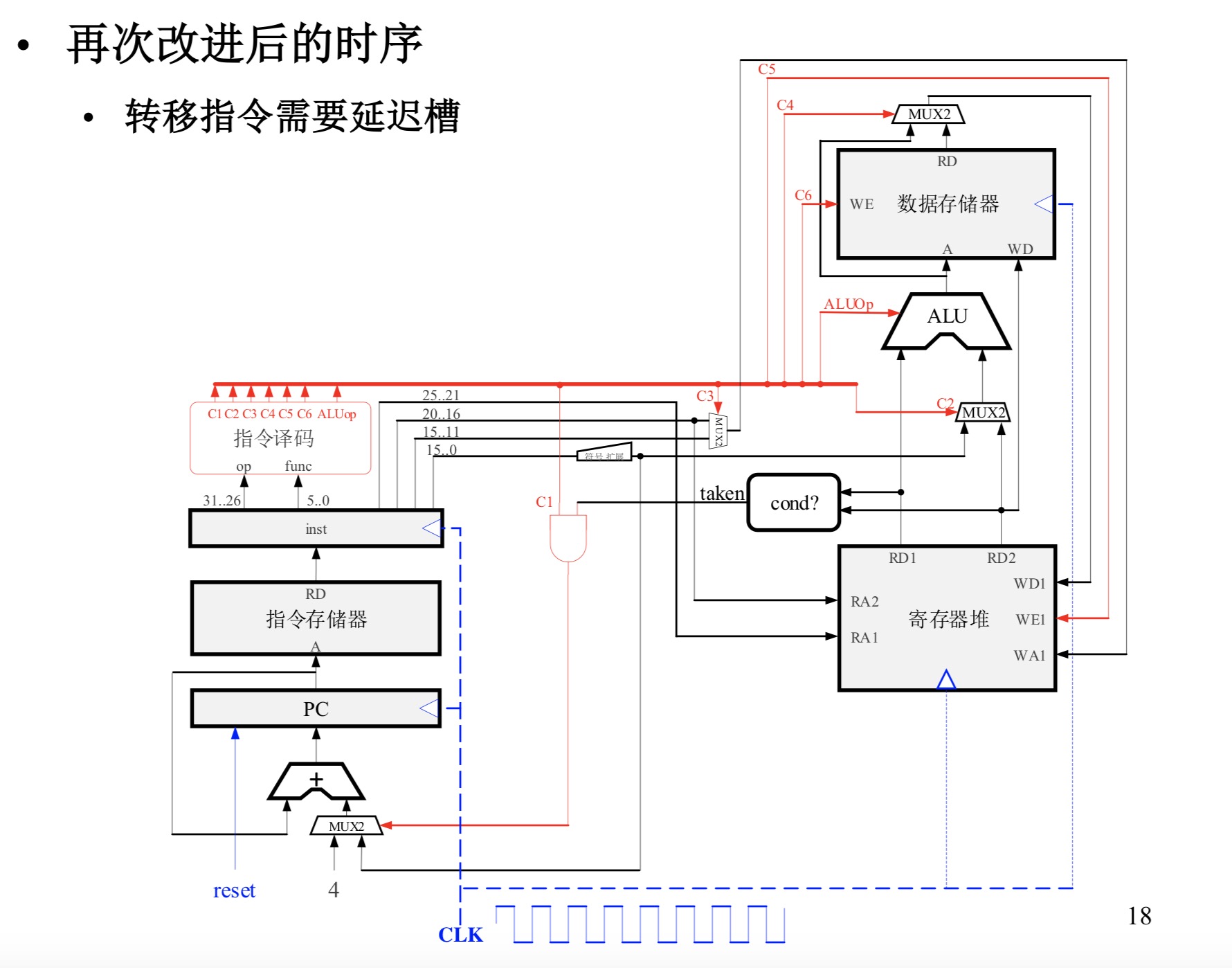
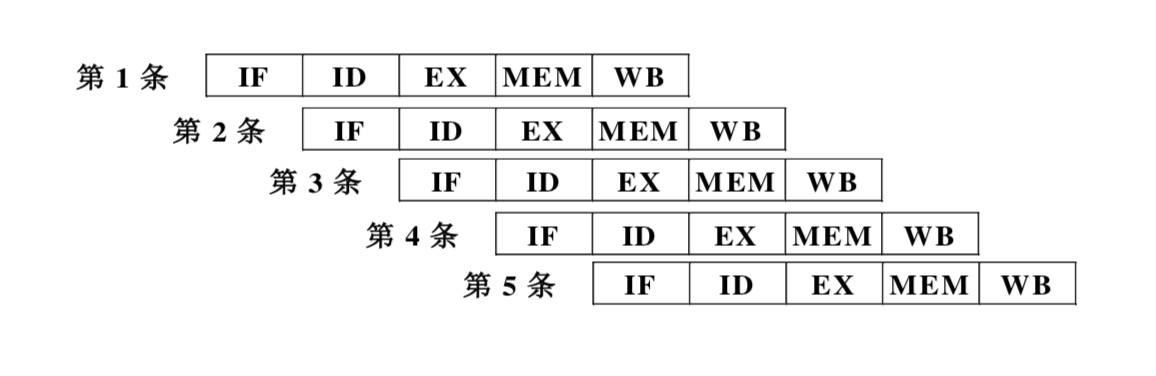
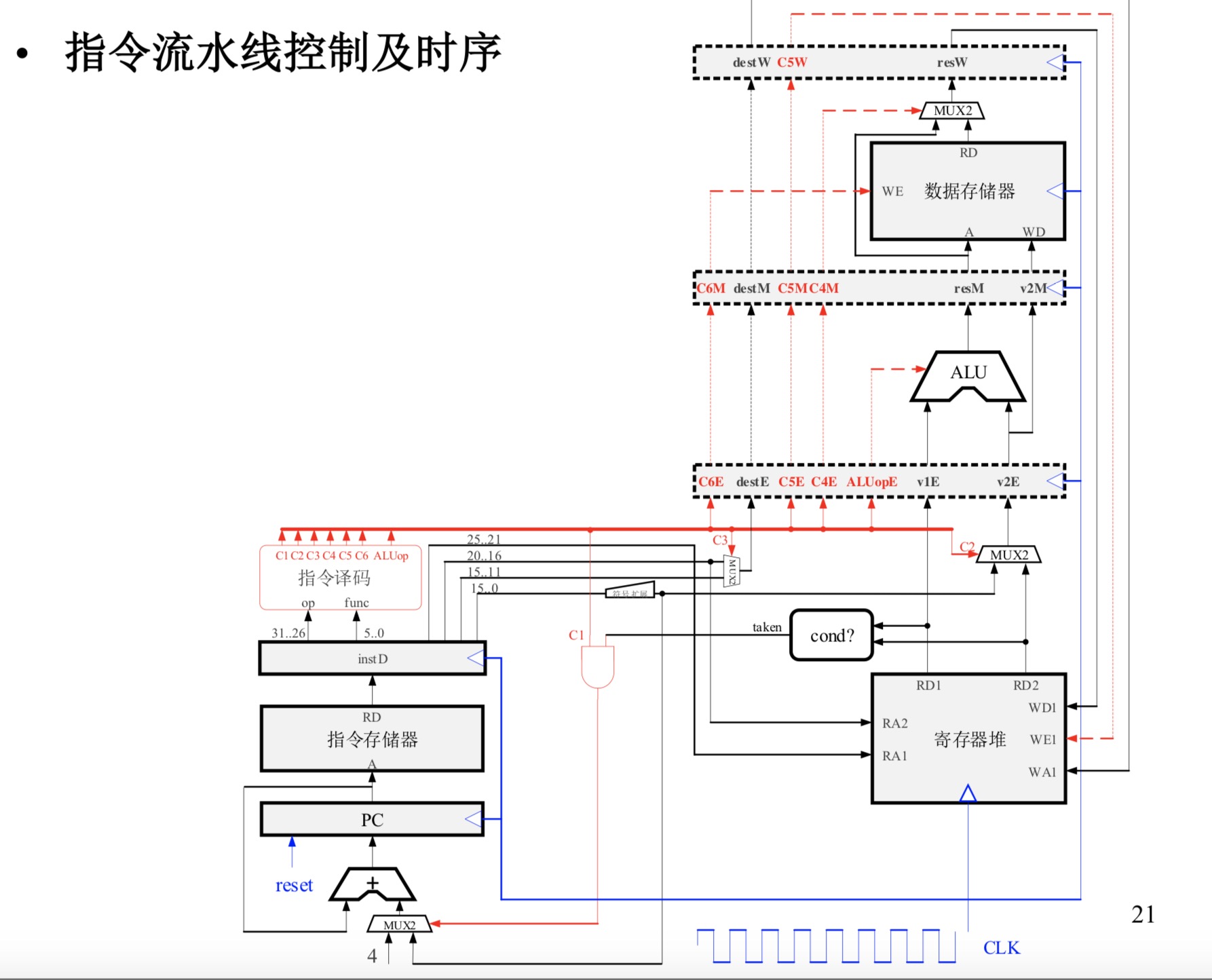
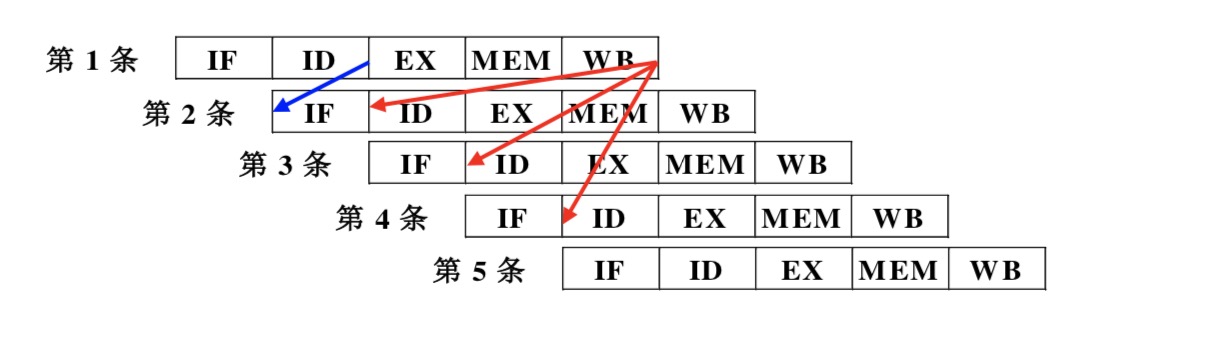
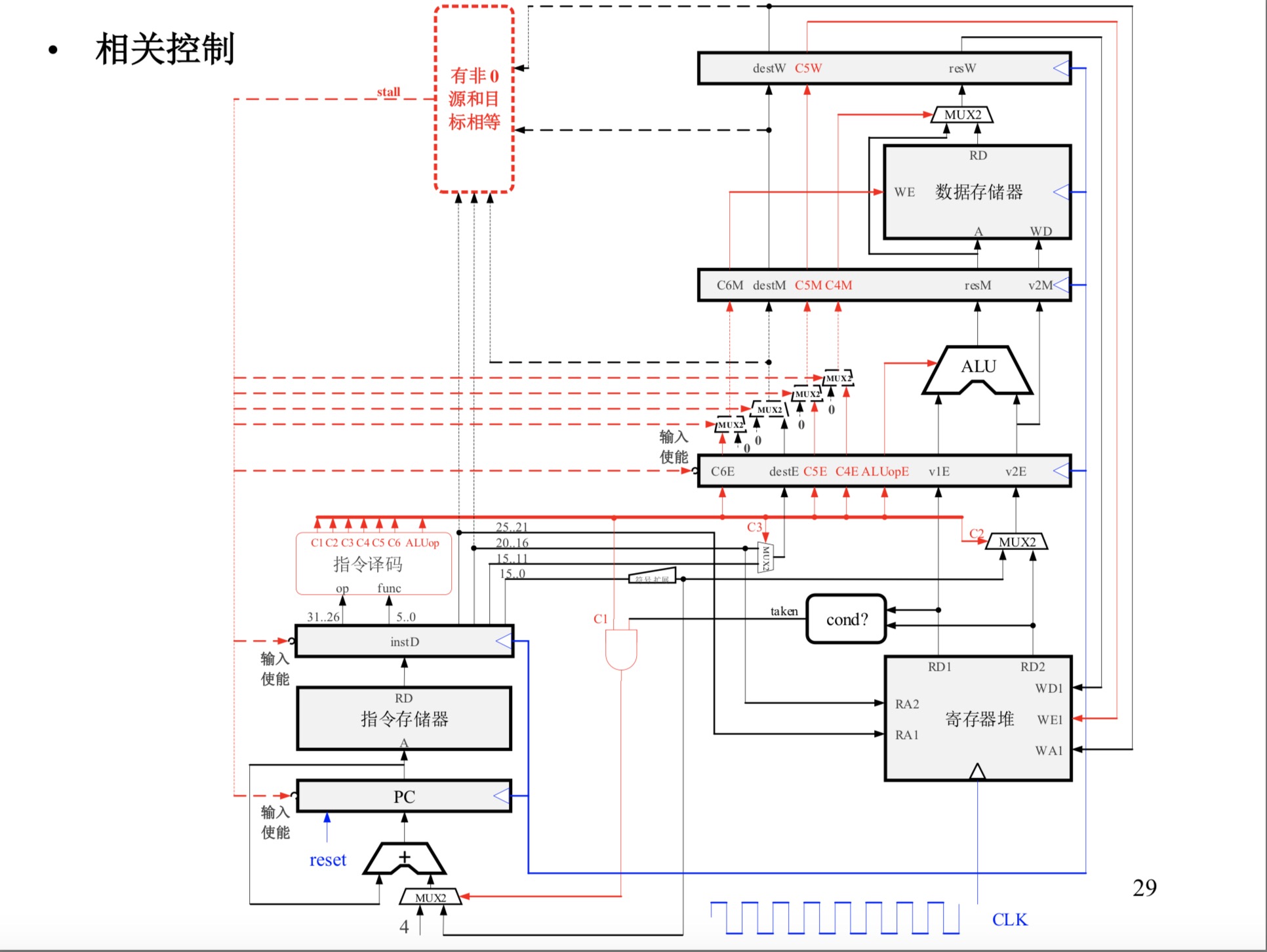
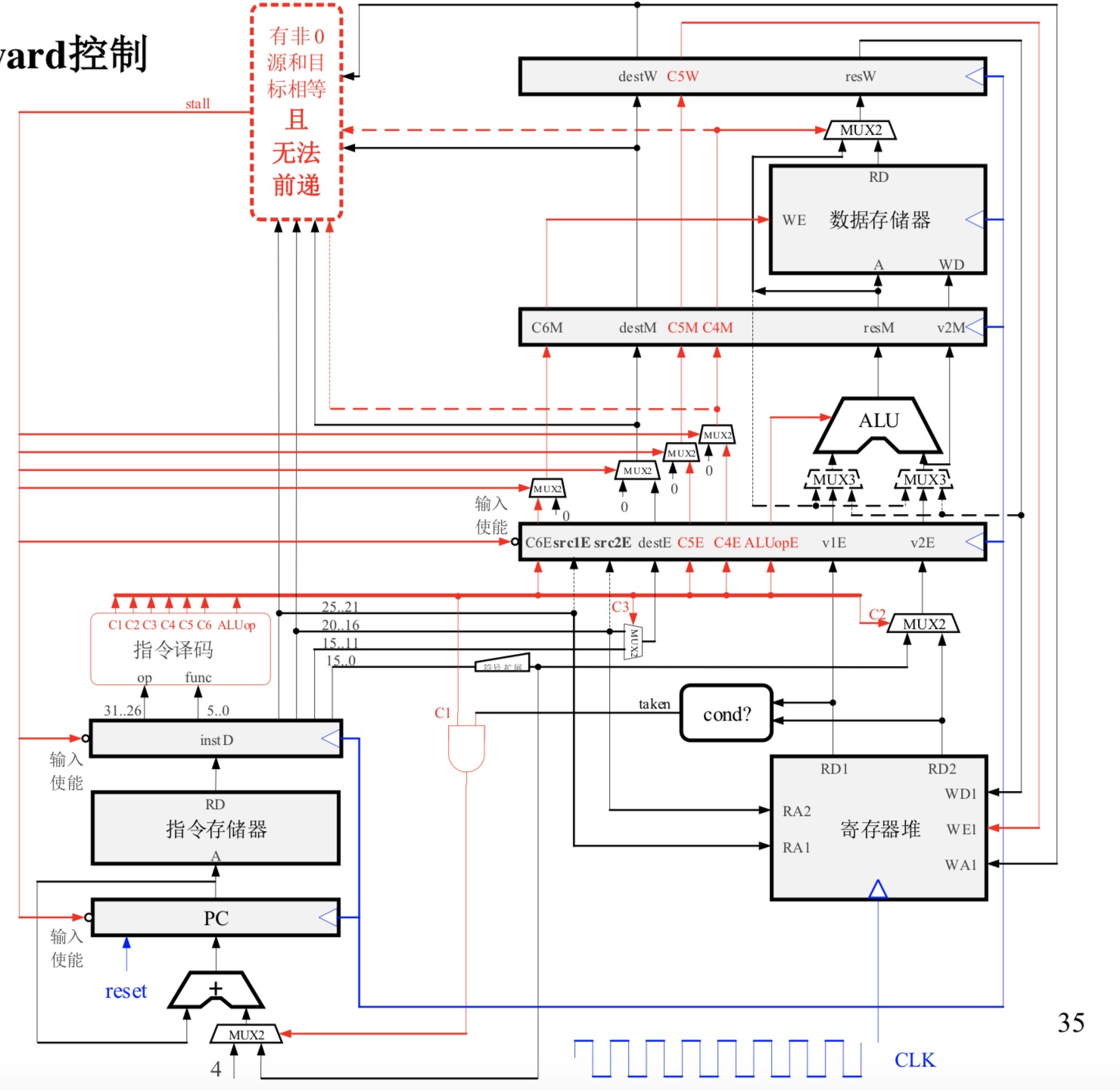
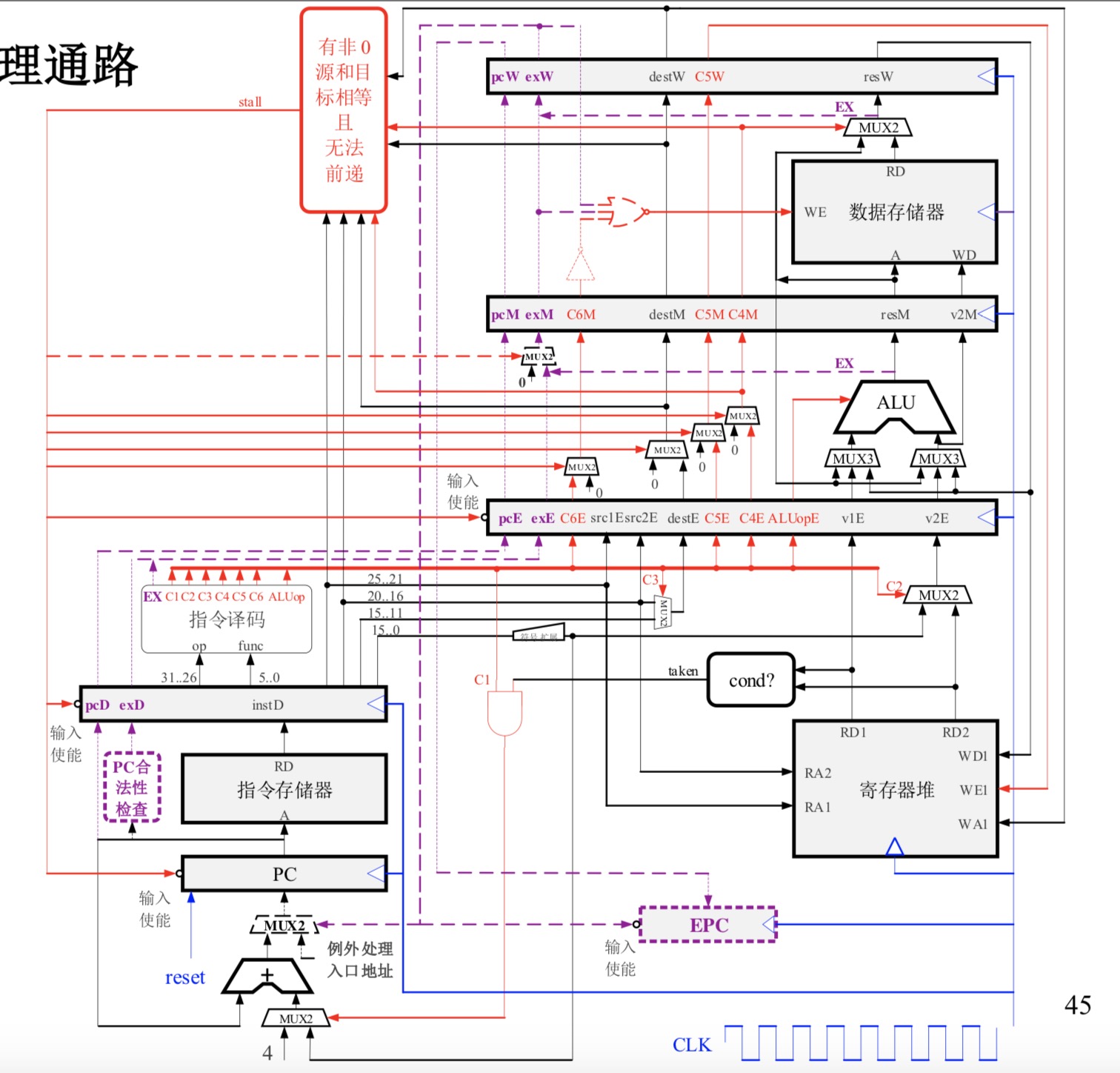















 3912
3912

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









