







数据:
#_measurement:rig
#tag:ip
#field:gpu_count gpu数量
#field:total_khs gpu总速度
#field:device_count 机器数量,纯粹为了统计机器数用
p = influxdb_client.Point("rig").tag("ip", myaddr).field("gpu_count", gpuCount).field("total_khs", total_khs).field("device_count", 1)
统计设备数量
找了好久也没看到基于flux统计机器数量(基于tag的count统计),转弯在上报数据里,专门加了一个字段device_count=1,表示机器数量
from(bucket: "fxos")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "rig")
|> filter(fn: (r) => r["_field"] == "device_count")
|> unique(column:"ip")
|> drop(columns:["ip"])
|> aggregateWindow(every: 5m, fn: sum, createEmpty: false)
|> yield(name: "sum")统计group
from(bucket: "trial_bucket")
|> range(start: -15m)
|> filter(fn: (r) => r._measurement == "http_api_request_duration_seconds")默认其实就有group,是按‘start’ 和 ‘end’ 来分组的
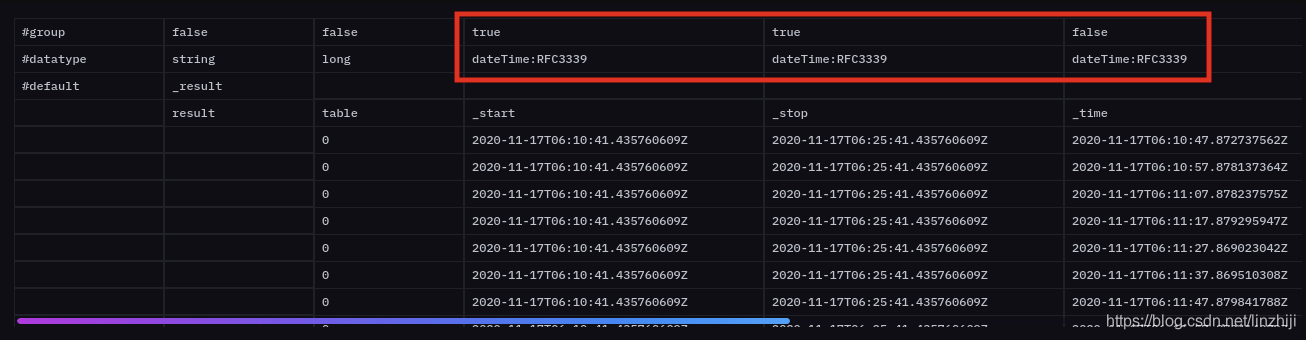
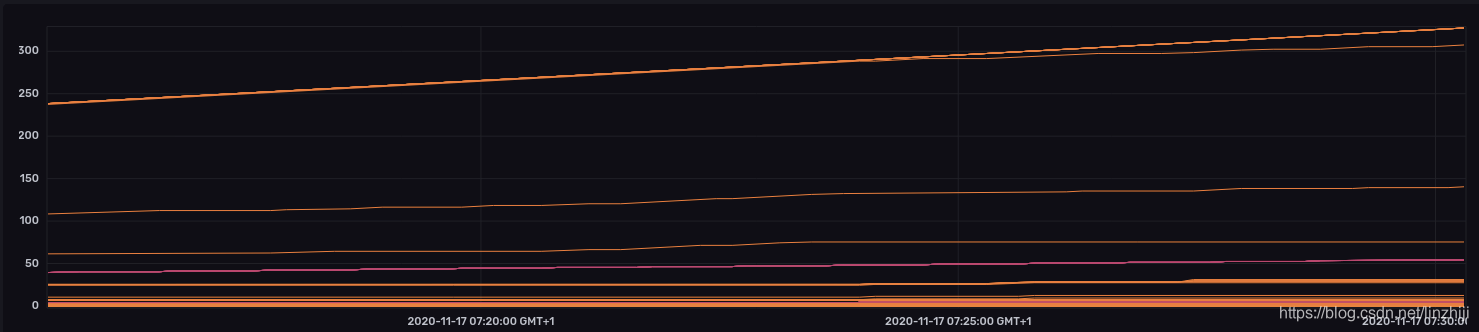 进一步
进一步
from(bucket: "trial_bucket")
|> range(start: -15m)
|> filter(fn: (r) => r._measurement == "http_api_request_duration_seconds")
|> group(columns: ["_measurement", "_field"]) 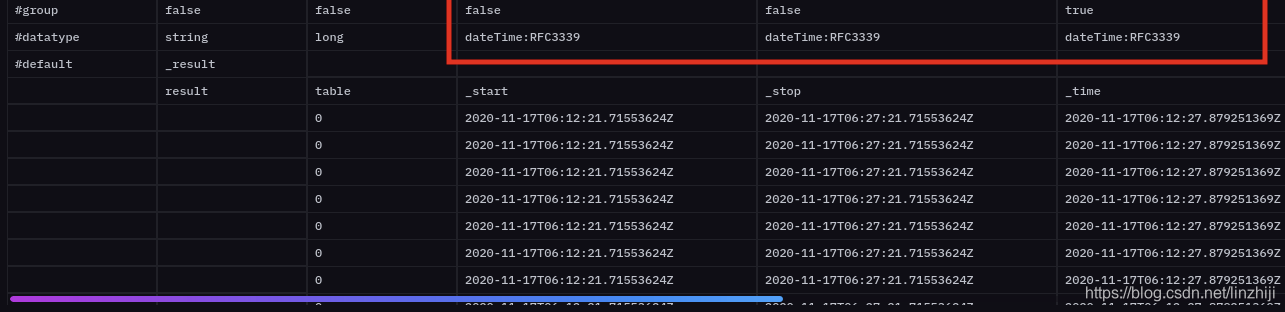
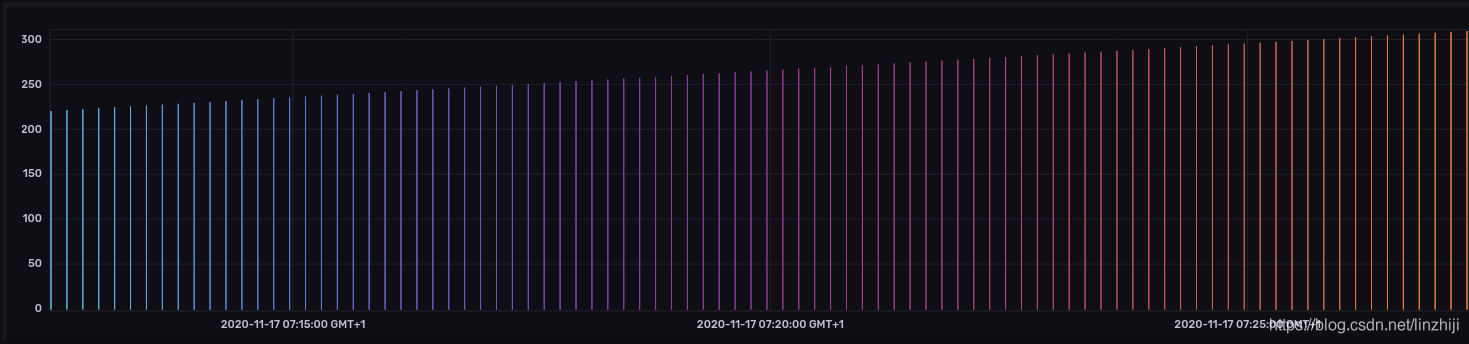
第三步
from(bucket: "trial_bucket")
|> range(start: -15m)
|> filter(fn: (r) => r._measurement == "http_api_request_duration_seconds")
|> group(columns: ["_time"])
|> mean()
|> group() 
参数 mode
group有个参数mode,2个值
by: 默认值,根据前面的参数排序except: 除了前面的参数,剩下的都参与group
Accordingly, we can modify the above code to get the same result:
from(bucket: "trial_bucket")
|> range(start: -15m)
|> filter(fn: (r) => r._measurement == "http_api_request_duration_seconds")
|> group(columns: ["_time"])
|> mean()
|> group(columns: ["_time", "_value"], mode: "except")参考:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









