







淘宝技术这十年
淘宝技术发展总结
-------------------------------------------------------------------------------------------------------------------
2003年, 从一个美国人那里买来的一个网站系统,这个系 统的名字叫做PHPAuction(其官方网站 http://www.phpauction. netAuction。 网站的 架构:LAMP(Linux+ Apache+MySQL+PHP),这是一个很常用的网站架 构模型,其优点是:无须编译,发布快速,PHP语言功能强大, 能做从页面渲染到数据访问所有的事情,而且用到的技术都是开 源、免费的。买来之后不是直接就能用的,需要很多本地化的修改,例如,修改一些数据类型,增加后台管理的功能,页面模板改得漂亮一点,页眉和页脚加上自己的站点简介等。其中最有技术含量的是对数据库进行修改,原来是从一个数据库进行所有的读写操作,现在把它拆分成一个主库、两个从库,并且读 写分离。这么做的好处有几点:存储容量增加了,有了备份,使 得安全性增加了,读写分离使得读写效率得以提升(写要比读更 加消耗资源,分开后互不干扰)。 为了不引起eBay的注意,淘宝网在2003年里一直声称自己是一个“个人网站”。由于这个创业团队强大的市场开拓和
运营能力,淘宝网的发展非常迅猛,2003年年底就吸引了注册用户23万个,每日31万个PV,从2003年5月到同年年底成交额达3371万元。
PV(Page View,页面访问量。每日每个网站的总PV量是形容一个网站规模的重要指标。淘宝网全网在平日(非促销期间)的PV大概是16~25亿个之间)。同时作为一个独立的用户,你这次访问淘宝网的所有页面均算作一UV(UniqueVisitor,用户访问)。LVS(Linux Virtual Server,世界上最流行的负载均衡系统之一)CDN(Content Delivery Network,即内容分发网络的作用)。Tair(淘宝自行研发的分布式KV存储方案)。
当时淘宝第一个版本的系统中已经包含了商品发布、管理、搜索、商品详情、出价购买、评价投诉、我的淘宝等功能(现在主流程中也是这些模块。在2003年10月增加了一个功能节点:安全交易,这是支付宝的雏形)。随着用户需求和流量的不断增长,系统做了很多日常改进,服务器由最初的一台变成了三台,一台负责发送Email、一台负责运行数据库、一台负责运行WebApp。一段时间之后,商品搜索的功能占用数据库大量资源(用like搜索的,很慢),2003年7月,多隆又把阿里巴巴中文站的搜索引擎iSearch搬了过来,isearch就是把数据库里的数据dump(倾倒)成结构化的文本文件后,放在硬盘上,提供Web应用以约定的参数和语法来查询这些数据。在2003年年底,MySQL已经撑不住了,技术的替代方案非常简单,就是换成Oracle。
数据一开始是放在本地的,DBA们对Oracle做调优,也对SQL进行调优。后来数据量变大后,本地存储无法满足了,买了NAS(Network Attached Storage,网络附属存储),NetApp(Network Appliance,美国网域存储技术有限公司)的NAS作为数据库的存储设备,加上Oracle RAC(Real ApplicationClusters,实时应用集群)来实现负载均衡。NAS的NFS(Network File System)协议传输的延迟很严重,但那时侯不懂。后来采购了Dell和EMC合作的SAN低端存储,性能一下提升了十几倍,这才比较稳定了。再后来,数据量更大了,存储的节点一拆二、二拆四,RAC又出问题了,这才踏上了购买小型机的道路。
其实在任何时候,开发语言本身都不是系统的瓶颈,业务带来的压力更多的存在于数据和存储方面。前面也说到,MySQL撑不住之后换为Oracle,Oracle的存储一开始在本机上,后来在NAS上,NAS撑不住了用EMC的SAN存储,再后来,Oracle的RAC撑不住了,数据的存储方面就不得不考虑使用小型机。,然后Oracle就运行在了小型机上,存储方面,从EMC低端CX存储到Sun oem hds高端存储,再到EMC dmx高端存储,一级一级地往上跳。
淘宝网作为个人网站发展的时间其实并不长,由于它太引人注目了,马云在2003年7月就宣布这个是阿里巴巴旗下的网站,随后在市场上展开了很成功的推广运作。
好的架构是进化来的,不是设计来的。
-------------------------------------------------------------------------------------------------------------------
2004年上半年开始,整个网站就开始了一个脱胎换骨的手术。Java是当时最成熟的网站开发语言,它有比较良好的企业开发框架,被世界上主流的大规模网站普遍采用。另外,有Java开发经验的人才也比较多,后续维护成本会比较低。要求SUN公司的工程师把一个庞大的网站从PHP语言迁移到Java,而且要求在迁移的过程中,不停止服务,原来系统的bugfix和功能改进不受影响。
大致方案是给业务分模块,一个模块一个模块地渐进式替换。如用户模块,老的member.taobao.com继续维护,不添加新功能,新功能在新的模块上开发,跟老的模块共用一个数据库,开发完毕之后放到不同的应用集群上,另开一个域名member1.taobao.com,同时再替换老的功能,替换一个,就把老的模块上的功能关闭一个,逐渐把用户引导到member1.taobao.com,等所有的功能都替换完之后,关闭member.taobao.com上。有个架构师周悦虹,他在Jakarta Turbine的基础上做了很多扩展,打造了一个阿里巴巴自己用的MVC框架WebX ( http://www.openwebx.
org/docs/Webx3_Guide_Book.html ),这个框架易于扩展,方便组件化开发,它的页面模板支持JSP和Velocity等,持久层支持ibatis和hibernate等,控制层可以用EJB和Spring(Spring是后来才有的)。后来我们在开源软件的基础上进行自主研发,一步一步地把IOE(IBM小型机、Oracle、EMC存储)这几个“神器”都去掉了。
到2004年底,淘宝网已经有4百多万种商品了,日均4千多万个PV,注册会员达400万个,全网成交额达10亿元。
任何牛B的人物,都有一段苦B的经历。
-------------------------------------------------------------------------------------------------------------------
随着数据量的继续增长,到了2005年,商品数有1663万个,PV有8931万个,注册会员有1390万个,这给数据存储带来的压力依然很大,数据量大,速度就慢。除了搜索引擎、分库分表,还有就是缓存和CDN(内容分发网络)。
架构师多隆做了一个基于 Berkeley DB 的缓存系统,把很多不太变动的只读信息放了进去。其实最初这个缓存系统还比较弱,并不敢把所有能缓存的信息都往里面放,一开始先把卖家的信息放里面,然后把商品属性放里面,再把店铺信息放里面,但是像商品详情这类字段太大的放进去受不了。商品详情先是放入了缓存系统,到现在是放进了文件系统TFS中。
2005年5月,微软的MSN门户大张旗鼓地进入中国,淘宝网成为它的购物频道。2005年中,盛大进军机顶盒业务,其电视购物的功能也是淘宝网开发的。在2005年底,淘宝网和湖南卫视合作推出了一档节目,叫做“超级Buyer秀”。
-------------------------------------------------------------------------------------------------------------------
在2006年,把浏览量写入数据库,发布上线1个小时后,数据库就挂掉了,每天几亿次的写入,数据库承受不了。一般的缓存策略是不支持实时更新的,这时候多隆想了个办法,在Pache上面写了一个模块,这个数字根本不经过下层的WebApp容器(只经过Apache)就写入一个集中式的缓存区了,这个缓存区的数据再异步更新到数据库。这就是前面提到的,整个商品详情的页面都在缓存中了,把缓存用到了极致。架构师多隆再一次出手写了一个缓存系统,叫TBstore,这是一个分布式的基于Berkeley DB的缓存系统,推出之后,在阿里巴巴集团内部使用非常广泛,特别是对于淘宝,TBstore上应用了ESI(Edge Side Includes)、Checkcode(验证码)、Description(商品详情)、Story(心情故事,商品信息里面的一个大字段,长度仅次于商品详情)、用户信息等内容。TBstore的分布式算法实现:根据保存的Key(关键字),对key进行Hash算法,取得Hash值,再对Hash值与总Cache服务器数据取模。然后根据取模后的值,找到服务器列表中下标为此值的Cache服务器。由Java Client API封装实现,应用无须关心。后面讲到缓存Tair的时候再说。
淘宝网开发了很多优秀的产品,例如,商品的类目属性、支付宝认证系统、招财进宝项目、淘宝旅行、淘宝彩票、淘宝论坛等,甚至在团购网站风起云涌之前,淘宝网在2006年就推出了“团购”的功能。一直采用商用存储系统,应用NetApp公司的文件存储系统。随着淘宝网的图片文件数量以每年3倍的速度增长,淘宝网后端NetApp公司的存储系统也从低端到高端不断迁移,直至2006年,即使是NetApp公司最高端的产品也不能满足淘宝网存储的要求。从2006年开始,我们决定自己开发一套针对海量小文件存储的文件系统,用于解决自身图片存储的难题。这标志着淘宝网从使用技术到了创造技术的阶段。
到2006年,淘宝网已经有了1.5亿个的日均PV,商品数达5千多万个,注册用户3千多万个,全网成交额达169亿元。
-------------------------------------------------------------------------------------------------------------------
在2007年,我们把淘宝的用户信息独立出来,形成一个中心系统UIC(User Information Center),因为淘宝所有的功能都要依赖于用户信息,所以这个模块必须单独拿出来,否则以后的系统无法扩展。把UIC拿出来以后,应用系统访问UIC,UIC访问数据库取得用户信息,粗算一下,每天要取几十亿条的用户信息,若直接查询数据库,数据库肯定会崩溃,这里必须要用缓存。于是多隆专门为UIC写了一个缓存系统,取名叫做TDBM。TDBM抛弃了Berkeley DB的持久功能,数据全部存放在内存中。
2007年6月,适合淘宝使用的集群图片文件存储系统(TaoBao File System,TFS)正式上线运营,在TFS前端,还部署着200多台图片文件服务器,用Apache实现,用于生成缩略图的运算。在生产环境中应用的集群规模达到了200台PC Server(146GB×6 SAS 15KB Raid5),文件数量达到上亿级别;系统部署存储容量为140TB;实际使用存储容量为50TB;单台支持随机IOPS 200+,流量为3MB/s。
说到TFS的系统架构,首先要描述清楚业务需求,淘宝对图片存储的需求大概可以描述如下:文件比较小;并发量高;读操作远大于写操作;访问随机;没有文件修改的操作;要求存储成本低;能容灾,能备份。显然,应对这种需求时要用分布式存储系统;由于文件大小比较统一,可以采用专有文件系统;由于并发量高,读写随机性强,需要更少的I/O操作;考虑到成本和备份,需要用廉价的存储设备;考虑到容灾,需要能平滑扩容。TFS 1.0版的架构图如下。
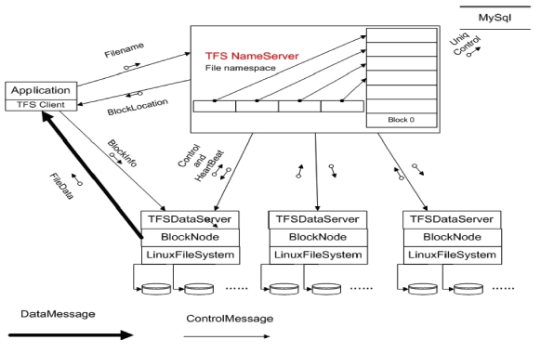
参照GFS并做了大量的优化之后,TFS 1.0版的架构图如下。从上面的架构图可看出:集群由一对Name Server和多台DataServer构成,Name Server的两台服务器互为双机,这就是集群文件系统中管理节点的概念。由于大量的文件信息都隐藏在文件名中,整个系统完全抛弃了传统的目录树结构,因为目录树开销最大。仅仅只需要一个FileID就能够准确定位文件在什么地方。在TFS上线后,商品展示图片开放到5张,商品描述里面的图片也可以使用淘宝的图片服务,到现在为止,淘宝网给每个用户提供了1GB的图片空间。技术和业务就是这么互相借力推动着的,业务满足不了的时候,技术必须创新,技术创新之后,业务有了更大的发展空间。
到2007年,淘宝网日均PV达到2.5亿个,商品数超过1亿个,注册会员数达5千多万个,全网成交额达433亿元。
-------------------------------------------------------------------------------------------------------------------
到2008年初,整个主站系统(有了机票、彩票系统之后,把原来的系统叫做主站)的容量已经到了瓶颈,商品数在1亿个以上,PV在2.5亿个以上,会员数超过了5000万个。这时Oracle的连接池数量都不够用了,数据库的容量到了极限,即使上层系统加机器也无法继续扩容,只有把底层的基础服务继续拆分,从底层开始扩容,上层才能扩展,这才能容纳以后三五年的增长。拆分核心业务模块,类目属性、用户中心、交易中心,随着这些模块的逐步拆分和服务化改造,在系统架构方面也积累了不少经验。到2008年年底就做了一个更大的项目,把淘宝所有的业务都模块化,这
是继2004年从LAMP架构到Java架构之后的第二次脱胎换骨。把淘宝的系统拆分成了如下架构。
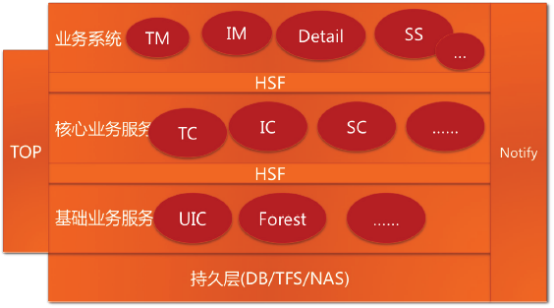
其中,UIC和Forest在上文已说过,TC、IC、SC分别是交易中心(Trade Center)、商品中心(Item Center)、店铺中心(Shop Center),这些中心级别的服务只提供原子级的业务逻辑,如根据ID查找商品、创建交易、减少库存等操作。再往上一层是业务系统TM(Trade Manager,交易业务)、IM(ItemManager,商品业务)、SM(Shop Manager,后来改名叫SS,即Shop System,店铺业务)、Detail(商品详情)。
到此为止,应用服务切分了(TM、IM)、核心服务切分了(TC、IC)、基础服务切分了(UIC、Forest)、数据存储切分了(DB、TFS、Tair),通过高性能服务框架(HSF)、分布式数据层(TDDL)、消息中间件(Notify)和Session框架支持了这些切分。一个美好的时代到来了,高度稳定、可扩展、低成本、快速迭代、产品化管理,淘宝的3.0系统走上了历史的舞台。
HSF框架以SAR包的方式部署到Jboss、Jetty或Tomcat下,在应用启动的时候,HSF(High-Speed Service Framework,在开发团队内部有一些人称HSF为“好舒服”)服务随之启动。HSF旨在为淘宝的应用提供一个分布式的服务框架,HSF从分布式应用层面以及统一的发布/调用方式层面为大家提供支持,从而可以很容易地开发分布式的应用以及提供或使用公用功能模块,而不用考虑分布式领域中的各种细节技术,例如,远程通讯、性能损耗、调用的透明化、同步/异步调用方式的实现等问题。Notify是一个分布式的消息中间件系统,支持消息的订阅、发送和消费。数据查询的中间件TDDL(Taobao Distributed Data layer)实现了下面三个主要的特性:数据访问路由——将针对数据的读写请求发送到最合适的地方;数据的多向非对称复制——一次写入,多点读取;数据存储的自由扩展——不再受限于单台机器的容量瓶颈与速度瓶颈,平滑迁移。
-------------------------------------------------------------------------------------------------------------------
到2009年,多隆又参考了memcached的内存结构,改进了TDBM的集群分布方式,在内存利用率和吞吐量方面又做了大幅提升,推出了TDBM 2.0系统。由于TDBM、TBstore的数据接口和用途都很相似,开发团队把二者合并,推出了淘宝自创的Key-Value缓存系统——Tair(TaoBao Pair的意思,Pair即Key-Value数据对)。Tair包括缓存和持久化两种存储功能。目前,Tair支撑了淘宝几乎所有系统的缓存信息。Tair已开源,地址为code.taobao.org。2009年6月,TFS 1.3版本上线,集群规模大大扩展,部署到淘宝的图片生产系统上,整个系统已经从原有200台PC服务器扩增至440台PC服务器(300B×12 SAS 15KB RPM)+30台PC服务器(600B×12 SAS 15KB RPM )。支持文件数量也扩容至百亿级别;系统部署存储容量为1800TB;当前实际存储容量为995TB;单台DataServer支持随机IOPS900+,流量为15MB+;目前NameServer运行的物理内存是217MB(服务器使用千兆网卡)。TFS 1.3版本逻辑结构图如下图所示。
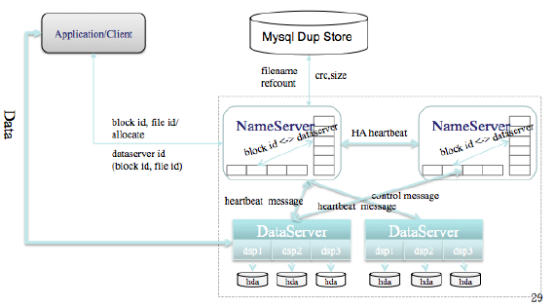
在TFS 1.3版本中,工程师们重点改善了心跳和同步的性能,最新版本的心跳和同步在几秒钟之内就可完成切换,同时进行了一些新的优化,包括元数据存储在内存中、清理磁盘空间等。
淘宝网将图片处理与缓存编写成基于Nginx的模块,我们认为Nginx是目前性能最高的HTTP服务器(用户空间),淘宝网使用GraphicsMagick进行图片处理,采用了面向小对象的缓存文件系统,前端有LVS+Haproxy将原图和其所有的缩略图请求都调度到同一台Image Server(图片服务器)。目前淘宝网的TFS已经开源(见code.taobao.org),业界可以一起使用和完善这个系统。
目前,淘宝已经变成了一个生态体系,包含C2C、B2C、导购、团购、社区等各种电子商务相关的业务。到2009年年底,平台开放淘宝服务100多个,每天调用量为4000次,这一年开放平台的开发者面对的主要是淘宝C店卖家,卖家工具成为服务市场的主流。(参看Blog,地址为http://blog.csdn.net/cenwenchu79,根据时间轴可以看到各种结构优化和性能优化的过程)这个系统三台虚拟机撑住了8亿次的日志即时分析,MySQL日志分析就此结束。
-------------------------------------------------------------------------------------------------------------------
2010年年中对Jetty7做了一次压测,发现Continuations的效果已经可以上正式的环境了,于是开始在Jetty7
的基础上做HTTP服务异步化+事件驱动的封装,同时也实现了一个虚拟隔离线程池做配合。到2010年年底,平台开放淘宝服务300多个,每天调用量为8亿次,这一年淘宝正式开始对外宣传开放,淘宝开放年赢在淘宝,目前很多年收入上千万的TP在这个时候成了先锋(2010年以前的可以叫做先烈),产品层面上,这一年除了卖家工具的继续发展,SNS热潮的兴起带动了淘江湖的买家应用,游戏应用的淘金者蜂蛹而入,开放的服务也继续保持300%的增速,覆盖面从卖家类延伸到了买家类,从简单的API提供,到了淘宝网站支持深度集成应用到店铺和社区。
-------------------------------------------------------------------------------------------------------------------
到2011年年底,平台开放淘宝服务758个,每天调用量19亿次 。至2011年年底,淘宝网拥有全国最大的Hadoop分布式计算集群之一(2000多个节点,CPU:24000 core,Memory:48000GB,Disk:24000块),日新增数据50TB,有40PB海量数据存储,分布在全国各地80多个节点的CDN网络,支撑的流量超过800Gbps。淘宝的搜索引擎能够对数十亿的商品数据进行实时搜索,另外,还拥有自主研发的文件存储系统和缓存系统,以及Java中间件和消息中间件系统,这一切组成了一个庞大的电子商务操作系统。
为了快速存取海量的宝贝图片等静态文件,淘宝开发了分布式文件系统TFS(TaoBao File System)来处理这类问题。为了快速、及时、同步地传输日志数据,淘宝研发了TimeTunnel,用于进行实时的数据传输,然后交给后端系统进行计算报表等操作。
由于业务量的增长以及分析需求到用户纬度,因此,在2011年年底启动了流式分析集群重构升级的项目,将新的分
析集群项目命名为Beatles,做了一次完整的重构,将那么多年的补丁经验和老代码重新设计和实现,并且将Mater根据业务可垂直切分,最终解决Master归并压力的问题,当然期间的技术优化点也不少,统计纬度细化到了用户纬度。2011年年底启动了社区电子商务化的项目,也就是现在所说的轻电商(XTao)项目。
钱能解决的问题,就不是问题。
-------------------------------------------------------------------------------------------------------------------
2012年,平台开放淘宝服务900多个,每天调用量为25亿次,这一年淘宝客由于公司方向转变热潮消退,无线乘势而起,新业务(机彩票、酒店、理财等)、P4P、数据类服务都开始运营API,开放平台开发者的客户群体也从C店卖家增加到了B的品牌商和渠道商等。另一方面,开放平台安全体系的构建成为2012年的重点,从两个角度对安全做了全方位的控制。第一,用户。用户授权更细化了授权操作范围(细粒度到了数据范畴),授权时长。所有的信息可监控、归档、快速定位,我们内部叫做Top Ocean,简单说来就是对所有的访问日志做归档,归档的载体是块状文件,归档时对块状文件的所有记录按照需求建立索引,然后保留索引,上传本地文件到远端分布式文件系统备份。实时的监控服务调用和应用访问,授权异动。第二,第三方应用。采用监控集群对所有ISV的服务器做安全扫描,对普通的Web安全漏洞做扫描,对应用的可用性和响应时间做监控。同时,正式启动“聚石塔”项目,提供弹性计算和存储能力及可靠的安全网络环境给ISV,帮助ISV提供自身应用的安全性。
今天,淘宝的格局为:集市(C2C)、天猫(B2C)、一淘(电商搜索返利入口)、无线、新业务、O2O(本地生活)、团购平台(聚划算),这些平台的价值是什么?如何找到自身定位?如何借助外力发展?如何面对流量入口的兴起、传统互联网企业的电商化、电商平台的竞争?这些才是开放平台2012年及下一个5年的精彩所在。
兴趣+执著,看准一个方向后,无论是顺境还是逆境,都要不断努力,把握时间和机会
-------------------------------------------------------------------------------------------------------------------














 400
400











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









