







 本文详细分析了Hadoop-2.7.0中HDFS客户端写文件时DFSPacket的逻辑组织形式和实现,包括数据包的初始化、数据写入过程以及数据flush到输出流的步骤,探讨了数据包头部生成、数据校验和数据块的处理机制。
本文详细分析了Hadoop-2.7.0中HDFS客户端写文件时DFSPacket的逻辑组织形式和实现,包括数据包的初始化、数据写入过程以及数据flush到输出流的步骤,探讨了数据包头部生成、数据校验和数据块的处理机制。
一、简介
HDFS在数据传输过程中,针对数据块Block,不是整个block进行传输的,而是将block切分成一个个的数据包进行传输。而DFSPacket就是HDFS数据传输过程中对数据包的抽象。
二、实现
HDFS客户端在往DataNodes节点写数据时,会以数据包packet的形式写入,且每个数据包包含一个包头,n个连续的校验和数据块checksum chunks和n个连续的实际数据块 actual data chunks,每个校验和数据块对应一个实际数据块,被用来做数据校验,防止数据传输过程中因网络原因等发生的数据丢包。
DFSPacket内数据的逻辑组织形式如下:

DFSPacket的物理实现如下:
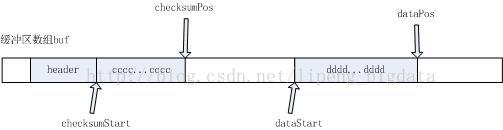
FSPacket在内部持有一个数据缓冲区buf,类型为byte[]
buf用来按顺序存储三类数据,header、checksum chunks、data chunks,分别对应上面的header区域、cccc…cccc区域和dddd…dddd区域
header、checksum chunks和data chunks都是提前分配好的,灰色代表已经写入数据区域,白色代表可以写入数据区域
Header是数据包的头部,它是在后续数据写完后才添加到数据包的头部。因为Header中包含了数据长度等信息,需要在数据写完后进行计算,故头部信息最后生成。Header内部封装了一个Protobuf对象,持有数据在Block中的位置offsetInBlock、数据包序列号seqno、是否为Block的最后一个数据包lastPacketInBlock、数据长度dataLen等信息,Header在写入DFSPacket中时,会在序列化Protobuf对象的前面追加一个数据长度大小和protobuf序列化大小,方便DataNode等进行解析。
DFSPacket内部有四个指针,分别为
1、checksumStart:标记数据校验和区域起始位置
2、checksumPos:标记数据校验和区域当前写入位置
3、dataStart:标记真实数据区域起始位置
4、dataPos:标记真实数据区域当前写入位置
数据包是按照一组组数据块写入的,先写校验和数据块,再写真实数据块,然后再写下一组校验和数据块和真实数据块,最后再写上header头部信息,至此整个数据包写完。
每个DFSPacket都对应一个序列号seqno,还存储了数据在数据块中的位置offsetInBlock、数据包中的数据块(chunks)数量numChunks、数据包中的最大数据块数maxChunks、是否为block中最后一个数据包lastPacketInBlock等信息。
三、源码分析
(一)初始化
DFSPacket的初始化分为以下几步:
1、首先计算缓冲区数据大小
1.1、首先,计算writePacketSize,即写包大小
这个是系统配置参数决定的。该大小默认是认为包含头部信息的,意即客户端自己指定的数据包大小,但是实际大小还需要后续计算得到。writePacketSize取自参数dfs.client-w
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 539
539

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









