







一、示例源码
1. 引入POM
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-starter</artifactId>
<version>1.4.1</version>
</dependency>2.测试源码
try {
String resource = "mybatics-config.xml";//mybatis配置文件
InputStream inputStream = Resources.getResourceAsStream(resource);//获取配置文件中的配置信息
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);//通过配置信息创建sqlsession工厂
SqlSession sqlSession = sqlSessionFactory.openSession();
// TbAccAccount tbAccAccount = sqlSession.selectOne("com.tpw.nacosdayconsumer.mapper.TbAccAccountMapper.getByPhone",
// "18196736851");
TbAccAccountMapper tbAccAccountMapper = sqlSession.getMapper(TbAccAccountMapper.class);
// TbAccAccount tbAccAccount = tbAccAccountMapper.getByPhone("18196736851");
// System.out.println(" tbAccAccount:" + JSONUtil.toJsonStr(tbAccAccount));
PageHelper.startPage(2,2);
List<TbAccAccount> tbAccAccountList = tbAccAccountMapper.listByTenantId(2L);
PageInfo<TbAccAccount> tbAccAccountPageInfo = new PageInfo<>(tbAccAccountList);
System.out.println(" tbAccAccountList:" + JSONUtil.toJsonStr(tbAccAccountList));
sqlSession.commit();
sqlSession.close();
} catch (IOException e) {
e.printStackTrace();
}3. mybatics-config全局配置文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<settings>
<setting name="logImpl" value="STDOUT_LOGGING"/>
</settings>
<plugins>
<plugin interceptor="com.github.pagehelper.PageInterceptor">
<property name="helperDialect" value="mysql"/>
</plugin>
</plugins>
<!-- <properties resource="">-->
<!-- <property name="username" value="dev_user"/>-->
<!-- <property name="password" value="F2Fa3!33TYyg"/>-->
<!-- </properties>-->
<environments default="development"><!--默认环境-->
<environment id="development"><!--环境-->
<transactionManager type="JDBC"/><!--事务管理方式-->
<dataSource type="POOLED"><!--mybatis获取连接的方式-->
<property name="driver" value="com.mysql.cj.jdbc.Driver"/><!--驱动-->
<!--useSSL 是否使用安全连接-->
<!--useUnicode 是否使用Unicode编码-->
<!--characterEncoding 传输数据的编码方式-->
<!--mysql8及以上的版本需要设置时区-->
<property name="url" value="jdbc:mysql://localhost:3306/micro_account?useSSL=false&useUnicode=true&characterEncoding=UTF-8"/>
<property name="username" value="root"/>
<property name="password" value="123456"/>
</dataSource>
</environment>
</environments>
<!--注册mapper-->
<mappers>
<!-- <mapper class="com.tpw.nacosdayconsumer.mapper.TbAccAccountMapper"></mapper>-->
<mapper resource="mapper/TbAccAccountMapper.xml"/>
<!-- <package name="com.tpw.nacosdayconsumer.mapper"/>-->
</mappers>
</configuration>二、插件加载原理
1.我们以pageHelper的分页插件PageInterceptor为例。
public interface Interceptor {
Object intercept(Invocation invocation) throws Throwable;
default Object plugin(Object target) {
return Plugin.wrap(target, this);
}
default void setProperties(Properties properties) {
// NOP
}
}我们可以看到插件是实现上面的拦截器接口,这个接口提供三个方法。
setProperties:在初始化插件后设置属性。
intercept: 进行真正的插件拦截和增强代码。
plugin:将当前拦截器类包装成一个插件。
public class Plugin implements InvocationHandler {
private final Object target;
private final Interceptor interceptor;
private final Map<Class<?>, Set<Method>> signatureMap;
private Plugin(Object target, Interceptor interceptor, Map<Class<?>, Set<Method>> signatureMap) {
this.target = target;
this.interceptor = interceptor;
this.signatureMap = signatureMap;
}
public static Object wrap(Object target, Interceptor interceptor) {
Map<Class<?>, Set<Method>> signatureMap = getSignatureMap(interceptor);
Class<?> type = target.getClass();
Class<?>[] interfaces = getAllInterfaces(type, signatureMap);
if (interfaces.length > 0) {
return Proxy.newProxyInstance(
type.getClassLoader(),
interfaces,
new Plugin(target, interceptor, signatureMap));
}
return target;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
Set<Method> methods = signatureMap.get(method.getDeclaringClass());
if (methods != null && methods.contains(method)) {
return interceptor.intercept(new Invocation(target, method, args));
}
return method.invoke(target, args);
} catch (Exception e) {
throw ExceptionUtil.unwrapThrowable(e);
}
}从这个插件包装的代码可以看到,就是对目标对象的所有接口生成JDK动态代理,在目标对象的所有接口调用前,拦截植入拦截器的代码。
2.我们具体来看分页插件的实现和初始化。
@Intercepts(
{
@Signature(type = Executor.class, method = "query", args = {MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class}),
@Signature(type = Executor.class, method = "query", args = {MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class, CacheKey.class, BoundSql.class}),
}
)
public class PageInterceptor implements Interceptor {
private volatile Dialect dialect;
private String countSuffix = "_COUNT";
protected Cache<String, MappedStatement> msCountMap = null;
private String default_dialect_class = "com.github.pagehelper.PageHelper";
@Override
public Object intercept(Invocation invocation) throws Throwable {
try {
Object[] args = invocation.getArgs();
MappedStatement ms = (MappedStatement) args[0];
Object parameter = args[1];
RowBounds rowBounds = (RowBounds) args[2];
ResultHandler resultHandler = (ResultHandler) args[3];
Executor executor = (Executor) invocation.getTarget();
CacheKey cacheKey;
BoundSql boundSql;
//由于逻辑关系,只会进入一次
if (args.length == 4) {
//4 个参数时
boundSql = ms.getBoundSql(parameter);
cacheKey = executor.createCacheKey(ms, parameter, rowBounds, boundSql);
} else {
//6 个参数时
cacheKey = (CacheKey) args[4];
boundSql = (BoundSql) args[5];
}
checkDialectExists();
List resultList;
//调用方法判断是否需要进行分页,如果不需要,直接返回结果
if (!dialect.skip(ms, parameter, rowBounds)) {
//判断是否需要进行 count 查询
if (dialect.beforeCount(ms, parameter, rowBounds)) {
//查询总数
Long count = count(executor, ms, parameter, rowBounds, resultHandler, boundSql);
//处理查询总数,返回 true 时继续分页查询,false 时直接返回
if (!dialect.afterCount(count, parameter, rowBounds)) {
//当查询总数为 0 时,直接返回空的结果
return dialect.afterPage(new ArrayList(), parameter, rowBounds);
}
}
resultList = ExecutorUtil.pageQuery(dialect, executor,
ms, parameter, rowBounds, resultHandler, boundSql, cacheKey);
} else {
//rowBounds用参数值,不使用分页插件处理时,仍然支持默认的内存分页
resultList = executor.query(ms, parameter, rowBounds, resultHandler, cacheKey, boundSql);
}
return dialect.afterPage(resultList, parameter, rowBounds);
} finally {
if(dialect != null){
dialect.afterAll();
}
}
}
@Override
public Object plugin(Object target) {
return Plugin.wrap(target, this);
}
@Override
public void setProperties(Properties properties) {
//缓存 count ms
msCountMap = CacheFactory.createCache(properties.getProperty("msCountCache"), "ms", properties);
String dialectClass = properties.getProperty("dialect");
if (StringUtil.isEmpty(dialectClass)) {
dialectClass = default_dialect_class;
}
try {
Class<?> aClass = Class.forName(dialectClass);
dialect = (Dialect) aClass.newInstance();
} catch (Exception e) {
throw new PageException(e);
}
dialect.setProperties(properties);
String countSuffix = properties.getProperty("countSuffix");
if (StringUtil.isNotEmpty(countSuffix)) {
this.countSuffix = countSuffix;
}
}
}我们可以看到PageInterceptor分页插件针对mybatics的执行器组件的查询方法进行增强。
3.接下来我们查看插件初始化过程,就是加载mybatics的全局配置XML和解析过程。
public class XMLConfigBuilder extends BaseBuilder {
private void pluginElement(XNode parent) throws Exception {
if (parent != null) {
for (XNode child : parent.getChildren()) {
String interceptor = child.getStringAttribute("interceptor");
Properties properties = child.getChildrenAsProperties();
Interceptor interceptorInstance = (Interceptor) resolveClass(interceptor).getDeclaredConstructor().newInstance();
interceptorInstance.setProperties(properties);
configuration.addInterceptor(interceptorInstance);
}
}
}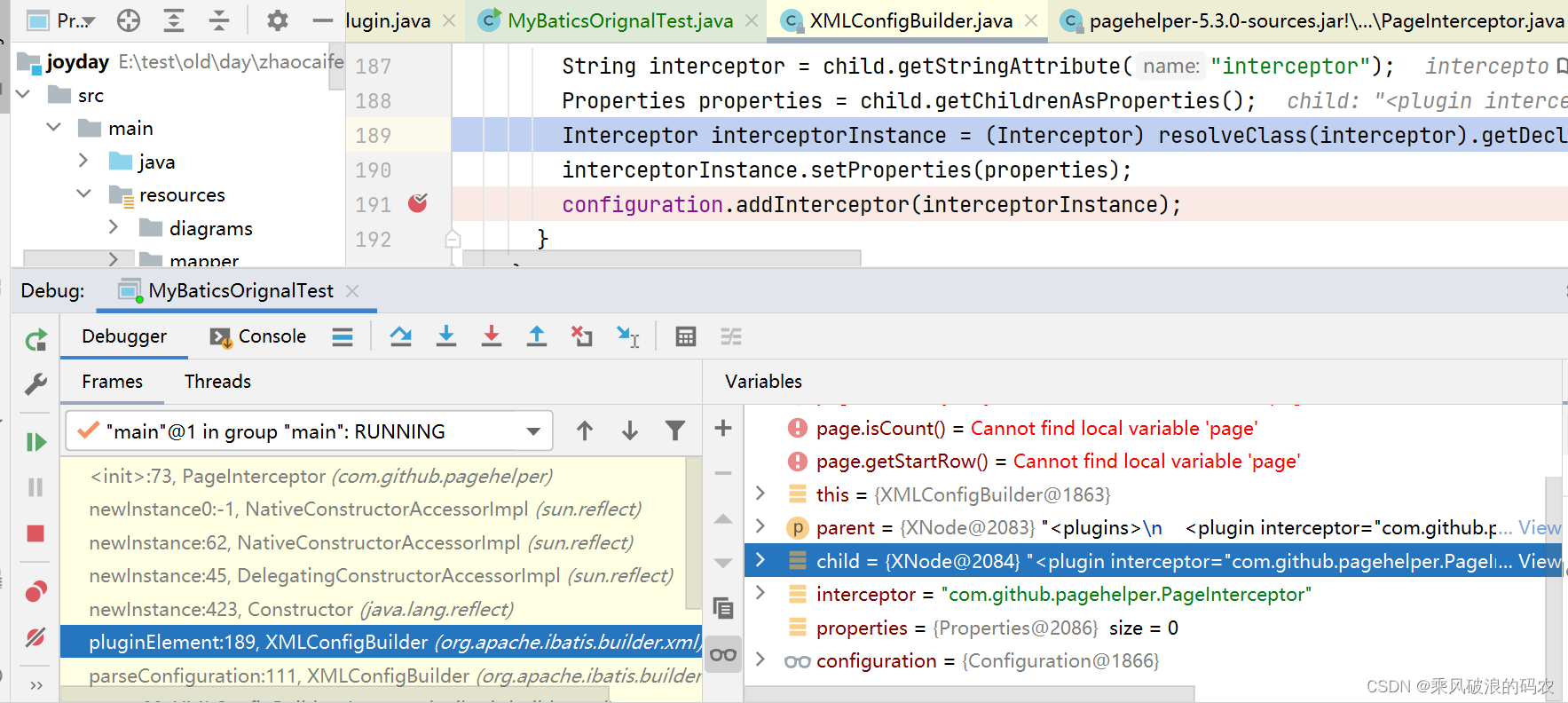
在解析全局配置的plugin节点时,会逐个插件进行实例化对象。
然后在实例完后,会设置插件的属性对象。

通过dialect对象的各个方法结合实现分页功能,Dialect是一个接口,他有不同的子类实现,对应不同的数据库方言。如果我们没有在配置中指定具体的实现类的话,默认的实现类是PageHelper。而PageHelper相当于一个大管家,他内部有一个PageAutoDialect自动方言类来自动的选择对应的数据库方言
4.然后开始初始化方言。
PageAutoDialect识别数据库的实现原理是通过获取DataSource对象继而获取jdbcUrl,然后通过jdbcUrl来识别的,也就是通过识别jdbc:mysql://实现
public class PageAutoDialect {
private static Map<String, Class<? extends Dialect>> dialectAliasMap = new HashMap<String, Class<? extends Dialect>>();
private static Map<String, Class<? extends AutoDialect>> autoDialectMap = new HashMap<String, Class<? extends AutoDialect>>();
public static void registerDialectAlias(String alias, Class<? extends Dialect> dialectClass) {
dialectAliasMap.put(alias, dialectClass);
}
static {
//注册别名
registerDialectAlias("hsqldb", HsqldbDialect.class);
registerDialectAlias("h2", HsqldbDialect.class);
registerDialectAlias("phoenix", HsqldbDialect.class);
registerDialectAlias("postgresql", PostgreSqlDialect.class);
registerDialectAlias("mysql", MySqlDialect.class);
registerDialectAlias("mariadb", MySqlDialect.class);
registerDialectAlias("sqlite", MySqlDialect.class);
registerDialectAlias("herddb", HerdDBDialect.class);
registerDialectAlias("oracle", OracleDialect.class);
registerDialectAlias("oracle9i", Oracle9iDialect.class);
registerDialectAlias("db2", Db2Dialect.class);
registerDialectAlias("informix", InformixDialect.class);
//解决 informix-sqli #129,仍然保留上面的
registerDialectAlias("informix-sqli", InformixDialect.class);
registerDialectAlias("sqlserver", SqlServerDialect.class);
registerDialectAlias("sqlserver2012", SqlServer2012Dialect.class);
registerDialectAlias("derby", SqlServer2012Dialect.class);
//达梦数据库,https://github.com/mybatis-book/book/issues/43
registerDialectAlias("dm", OracleDialect.class);
//阿里云PPAS数据库,https://github.com/pagehelper/Mybatis-PageHelper/issues/281
registerDialectAlias("edb", OracleDialect.class);
//神通数据库
registerDialectAlias("oscar", OscarDialect.class);
registerDialectAlias("clickhouse", MySqlDialect.class);
//瀚高数据库
registerDialectAlias("highgo", HsqldbDialect.class);
//虚谷数据库
registerDialectAlias("xugu", HsqldbDialect.class);
registerDialectAlias("impala", HsqldbDialect.class);
registerDialectAlias("firebirdsql", FirebirdDialect.class);
//注册 AutoDialect
//想要实现和以前版本相同的效果时,可以配置 autoDialectClass=old
registerAutoDialectAlias("old", DefaultAutoDialect.class);
registerAutoDialectAlias("hikari", HikariAutoDialect.class);
registerAutoDialectAlias("druid", DruidAutoDialect.class);
registerAutoDialectAlias("tomcat-jdbc", TomcatAutoDialect.class);
registerAutoDialectAlias("dbcp", DbcpAutoDialect.class);
registerAutoDialectAlias("c3p0", C3P0AutoDialect.class);
//不配置时,默认使用 DataSourceNegotiationAutoDialect
registerAutoDialectAlias("default", DataSourceNegotiationAutoDialect.class);
}
public void setProperties(Properties properties) {
//初始化自定义AutoDialect
initAutoDialectClass(properties);
//使用 sqlserver2012 作为默认分页方式,这种情况在动态数据源时方便使用
String useSqlserver2012 = properties.getProperty("useSqlserver2012");
if (StringUtil.isNotEmpty(useSqlserver2012) && Boolean.parseBoolean(useSqlserver2012)) {
registerDialectAlias("sqlserver", SqlServer2012Dialect.class);
registerDialectAlias("sqlserver2008", SqlServerDialect.class);
}
initDialectAlias(properties);
//指定的 Helper 数据库方言,和 不同
String dialect = properties.getProperty("helperDialect");
//运行时获取数据源
String runtimeDialect = properties.getProperty("autoRuntimeDialect");
//1.动态多数据源
if (StringUtil.isNotEmpty(runtimeDialect) && "TRUE".equalsIgnoreCase(runtimeDialect)) {
this.autoDialect = false;
this.properties = properties;
}
//2.动态获取方言
else if (StringUtil.isEmpty(dialect)) {
autoDialect = true;
this.properties = properties;
}
//3.指定方言
else {
autoDialect = false;
this.delegate = instanceDialect(dialect, properties);
}
} 
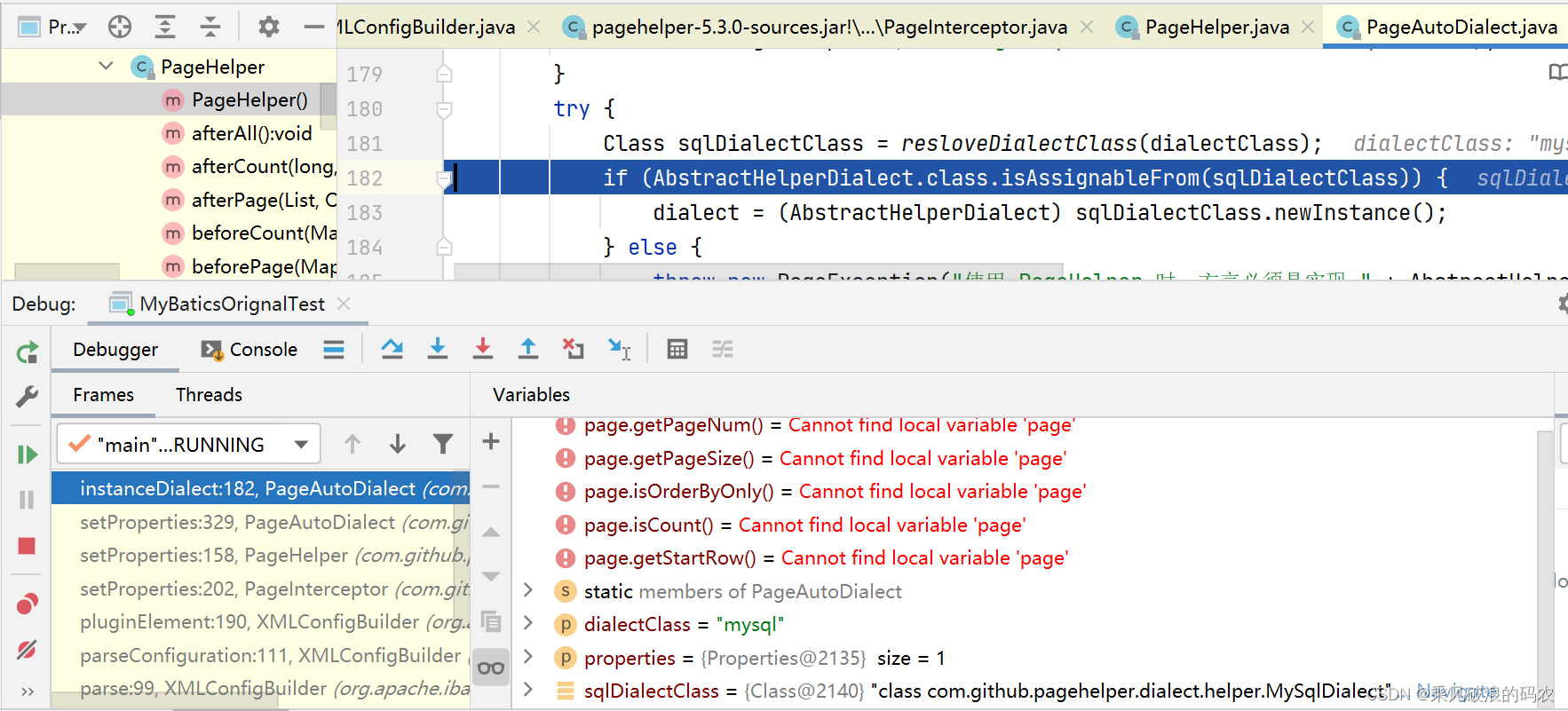 可以看到是创建一个mysqlDialect的方言对象,来构建分页和统计总数SQL。
可以看到是创建一个mysqlDialect的方言对象,来构建分页和统计总数SQL。
5.初始化完,可以看到全局配置的拦截器链中多了一个分页的拦截器。

6.在新建执行器时,会对缓存执行器进行插件加强,生成新的插件代理对象执行器。并拦截了执行器的两个查询方法进行增强。
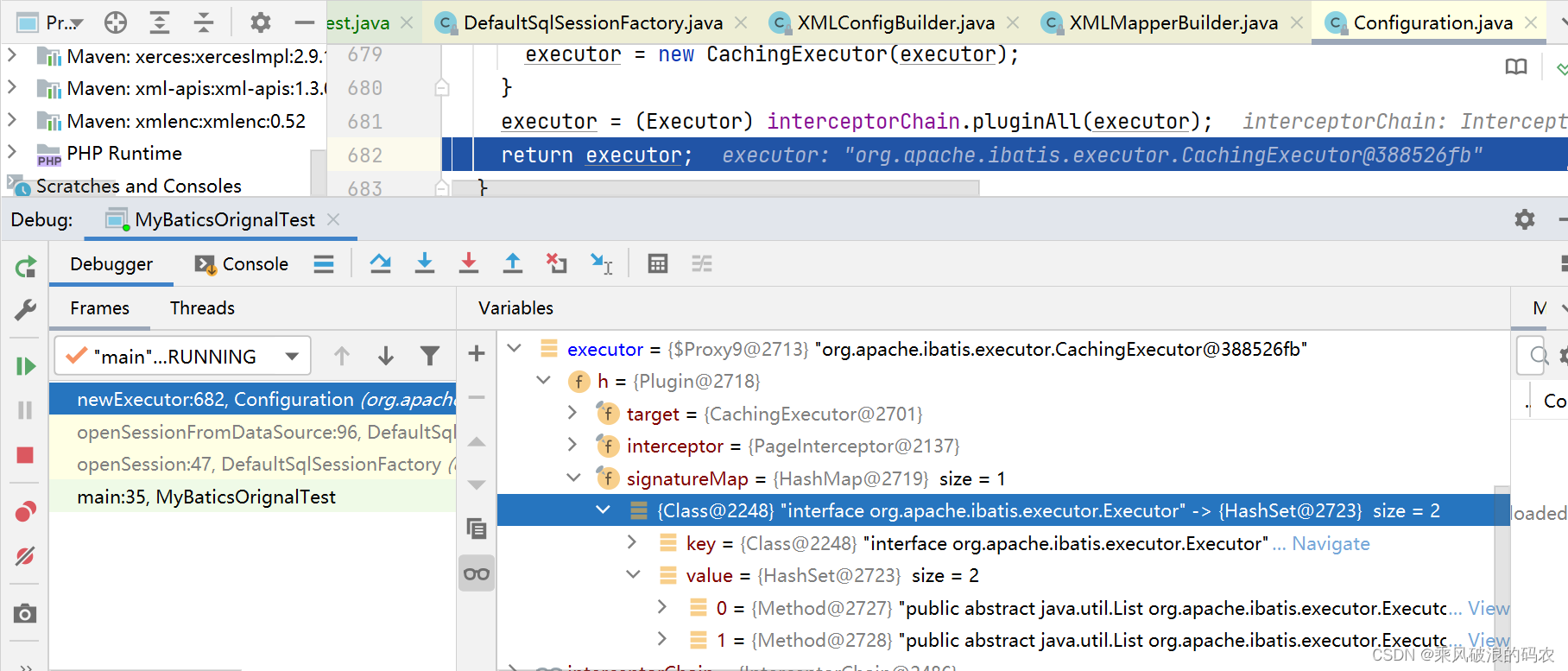
三、实际执行分页操作拦截过程。
1.首先执行设置分页参数,其实就是通过线程LOCAL变量存储当前的分页参数,然后执行完拦截后就自动清除当前线程变量,所以设置分页只是当次有效。
public class PageHelper extends PageMethod implements Dialect, BoundSqlInterceptor.Chain {
private PageParams pageParams;
private PageAutoDialect autoDialect;
private PageBoundSqlInterceptors pageBoundSqlInterceptors;
}
public abstract class PageMethod {
protected static final ThreadLocal<Page> LOCAL_PAGE = new ThreadLocal<Page>();
protected static boolean DEFAULT_COUNT = true;
public static <E> Page<E> startPage(int pageNum, int pageSize, boolean count, Boolean reasonable, Boolean pageSizeZero) {
Page<E> page = new Page<E>(pageNum, pageSize, count);
page.setReasonable(reasonable);
page.setPageSizeZero(pageSizeZero);
//当已经执行过orderBy的时候
Page<E> oldPage = getLocalPage();
if (oldPage != null && oldPage.isOrderByOnly()) {
page.setOrderBy(oldPage.getOrderBy());
}
setLocalPage(page);
return page;
}
protected static void setLocalPage(Page page) {
LOCAL_PAGE.set(page);
}
}
PageHelper.startPage(2,2);

可以看到pageHelper继承于pageMethod,所以设置分页参数由基类实现了,最终存储到线程LOCAL变量中。
2.mapper接口都是使用MapperProxy代理,而mapperProxy代理最终都是sqlsession的selectList方法,sqlsession是一个门面模式,最终的实现类为执行器。
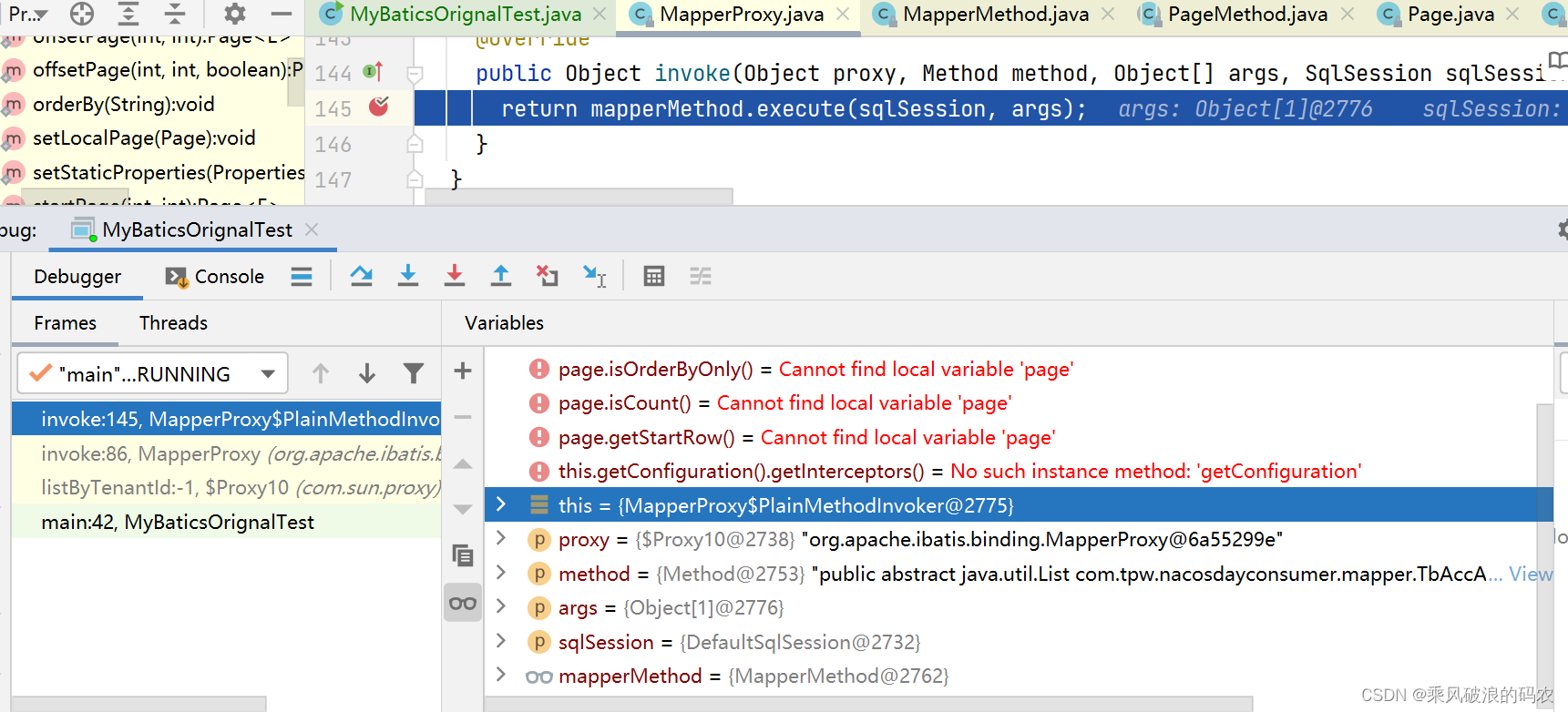
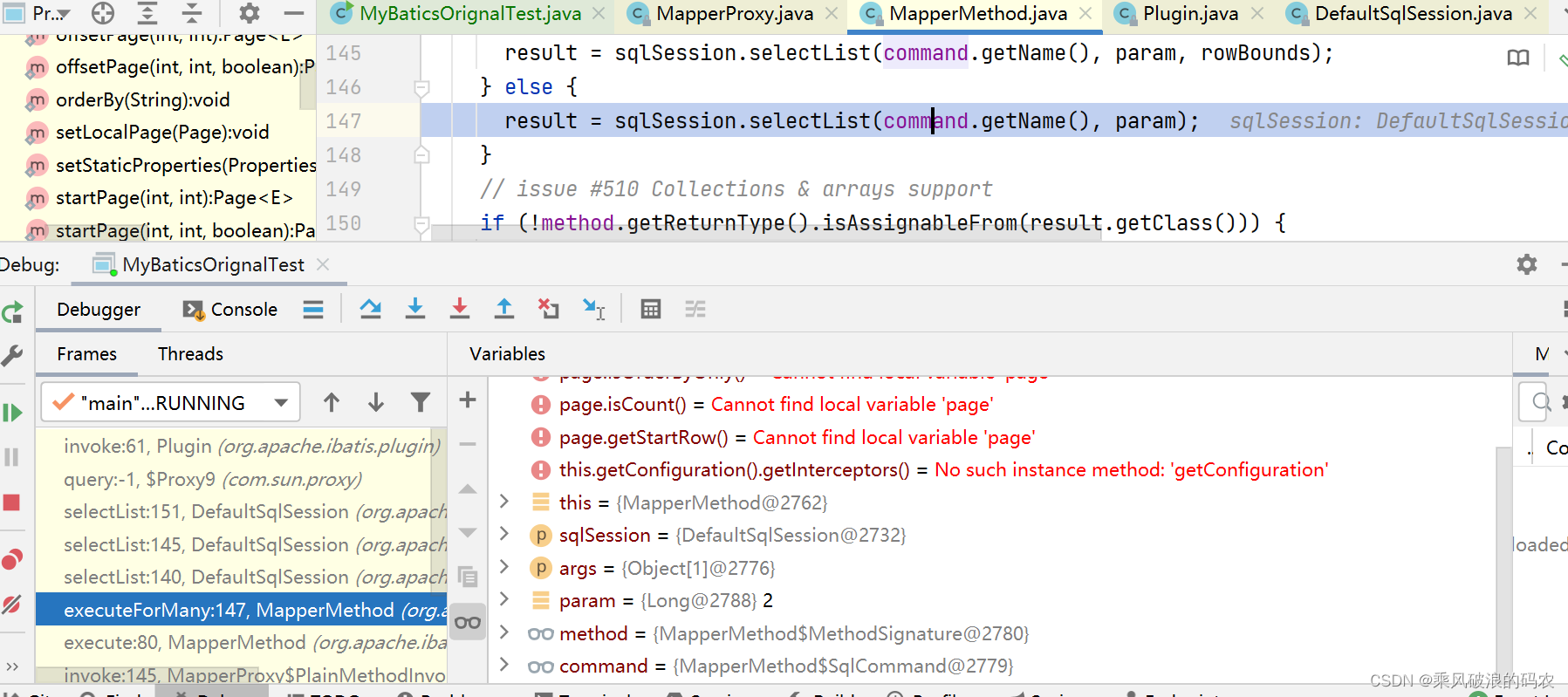
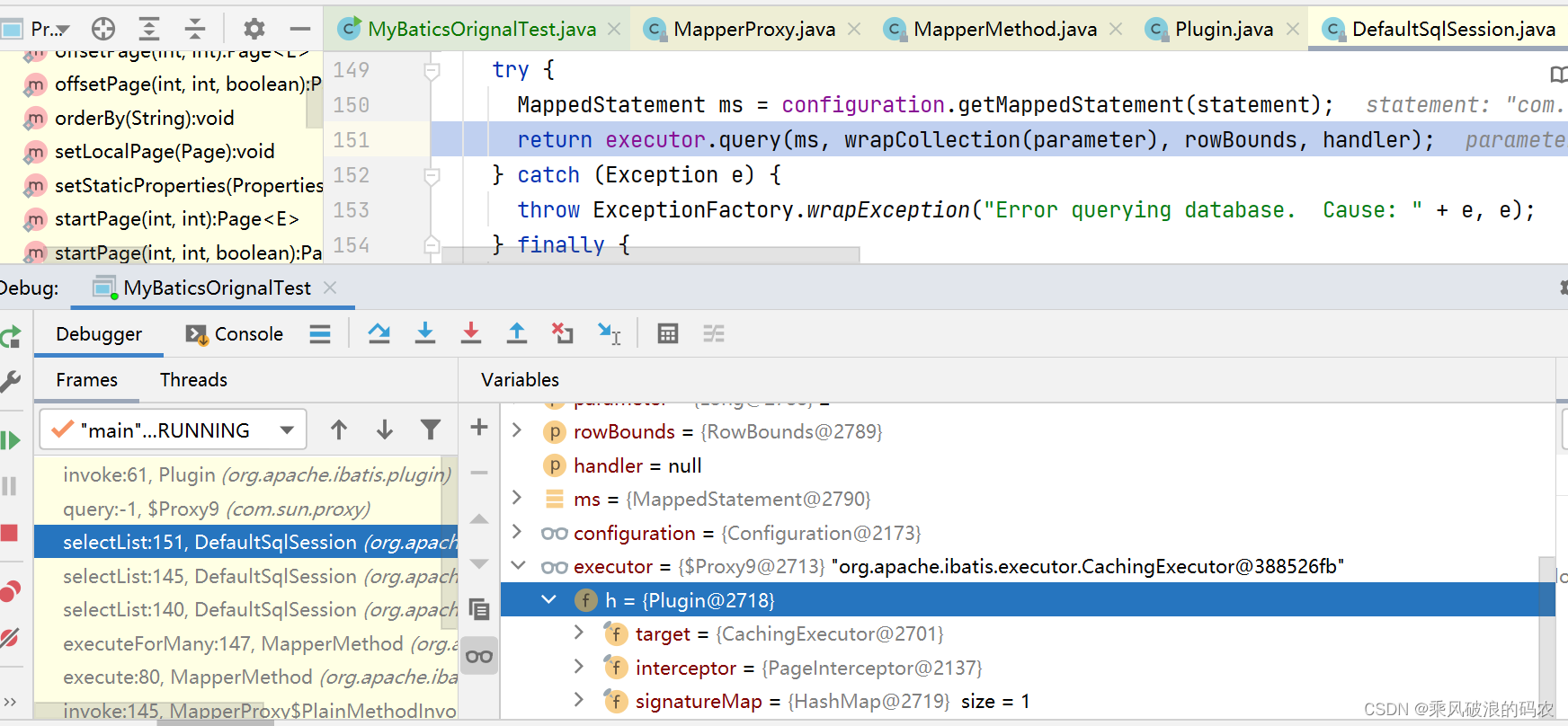
而我们的执行器代理已经为带上分页拦截器的插件所代理了。所以最终执行到插件,然后到分页拦截器。


3.接下来进行分页拦截插件的代码分析
回到intercept方法看分页的主流程,流程主要是:是否需要分页(skip)->分页前是否要count查询(beforeCount)->count查询(count)->查询分页数据(ExecutorUtil.pageQuery)->处理分页结果(afterPage)->清理数据(afterAll)
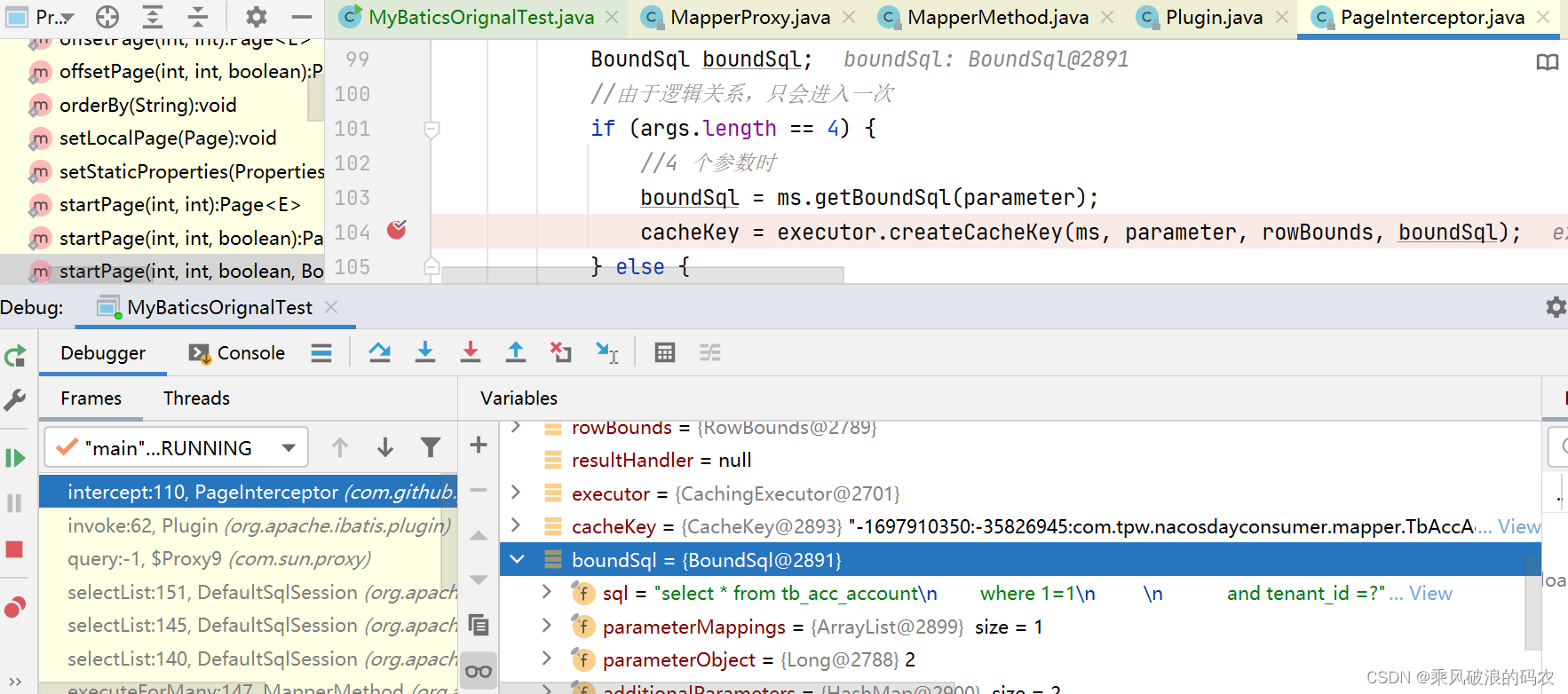
3.1 因为我们的参数为4个,所以就生成了boundSql,cacheKey
3.2 skip方法:逻辑就是判断线程变量LOCAL_PAGE是否有page对象,如果没有的话看是否有原始的rowBounds对象,调用方法判断是否需要进行分页,如果不需要,直接返回结果

因为我们当前线程变量有设置分页参数,用户是需要分页,所以不会跳过。
3.3 beforeCount方法:page对象中的count属性判断,默认是true

因为mysqlDialect方言继承于抽象辅助方言类,所以触发到
AbstractHelperDialect.beforeCount 方法。

由上可以看到,默认isCount=true,所以要算总数。
3.3 查询总数
count方法:会通过主语句的id+_COUNT后缀的形式查找是否有自定义的count查询语句,如果没有的话则会自动创建一个;自动创建的count语句是在com.github.pagehelper.parser.CountSqlParser#getSmartCountSql(java.lang.String, java.lang.String)方法中,大部分是通过创建简单的count子查询实现
//查询总数
Long count = count(executor, ms, parameter, rowBounds, null, boundSql);
private Long count(Executor executor, MappedStatement ms, Object parameter,
RowBounds rowBounds, ResultHandler resultHandler,
BoundSql boundSql) throws SQLException {
String countMsId = ms.getId() + countSuffix;
Long count;
//先判断是否存在手写的 count 查询
MappedStatement countMs = ExecutorUtil.getExistedMappedStatement(ms.getConfiguration(), countMsId);
if (countMs != null) {
count = ExecutorUtil.executeManualCount(executor, countMs, parameter, boundSql, resultHandler);
} else {
if (msCountMap != null) {
countMs = msCountMap.get(countMsId);
}
//自动创建
if (countMs == null) {
//根据当前的 ms 创建一个返回值为 Long 类型的 ms
countMs = MSUtils.newCountMappedStatement(ms, countMsId);
if (msCountMap != null) {
msCountMap.put(countMsId, countMs);
}
}
count = ExecutorUtil.executeAutoCount(this.dialect, executor, countMs, parameter, boundSql, rowBounds, resultHandler);
}
return count;
}3.3.1 这里就是判断在MAPPER接口对象类是否有当前MAPPERSTATEMENT的总数SQL查询方法,没有就自动新建一个。
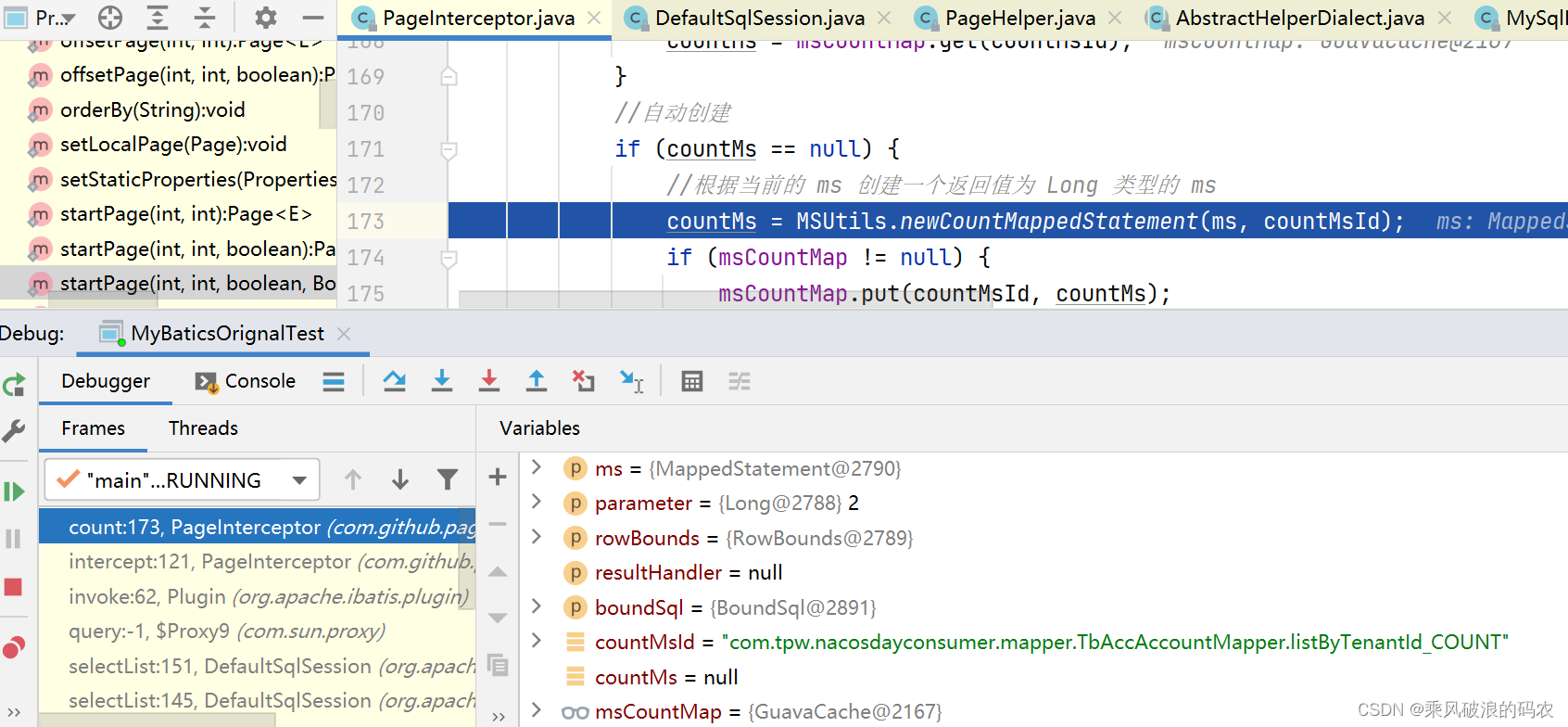
3.3.2 这里没有,所以会新建一个mapperStatement,countMs就是从原始的ms中复制一份过来。
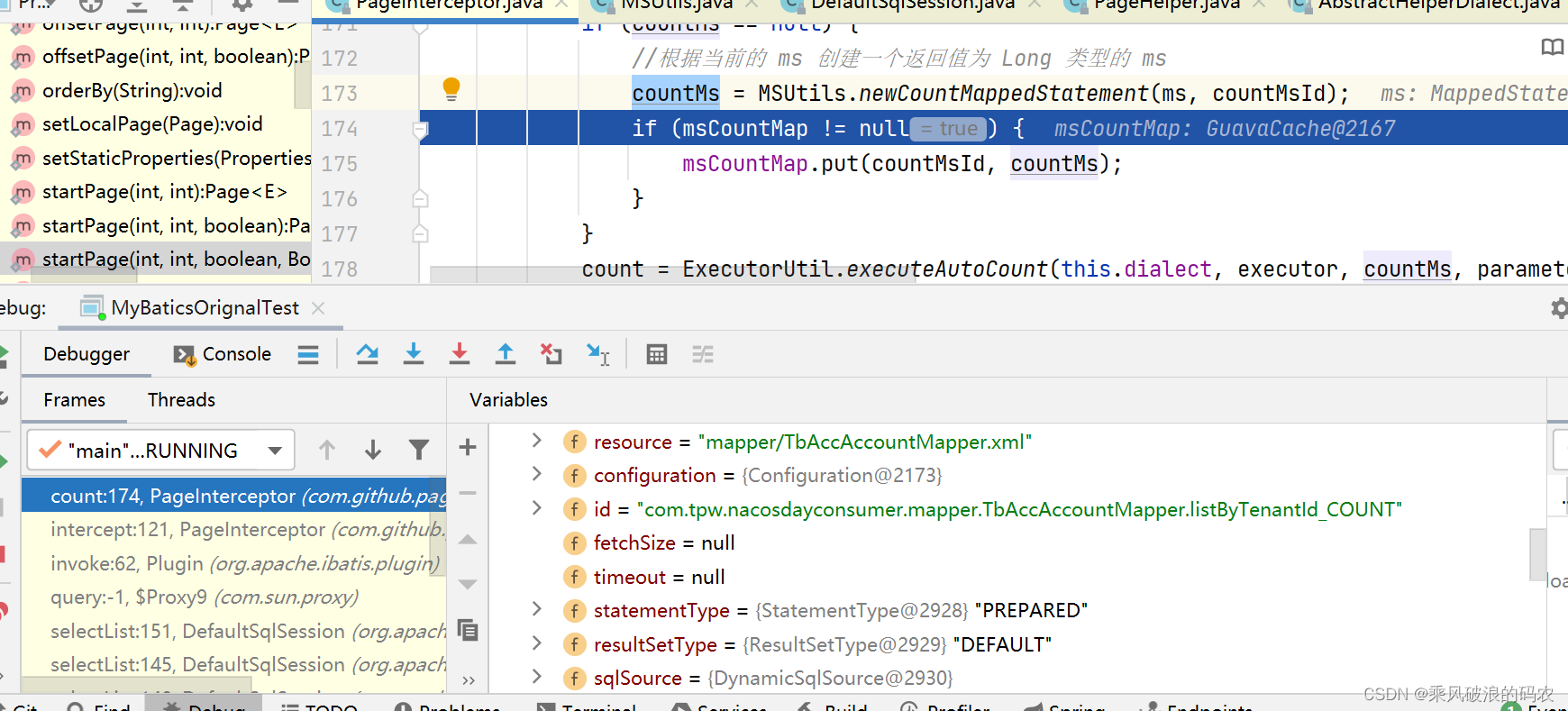
3.3.3 接下来进行真正的COUNT数量的SQL语句构建。
public abstract class ExecutorUtil {
public static Long executeAutoCount(Dialect dialect, Executor executor, MappedStatement countMs,
Object parameter, BoundSql boundSql,
RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
Map<String, Object> additionalParameters = getAdditionalParameter(boundSql);
//创建 count 查询的缓存 key
CacheKey countKey = executor.createCacheKey(countMs, parameter, RowBounds.DEFAULT, boundSql);
//调用方言获取 count sql
String countSql = dialect.getCountSql(countMs, boundSql, parameter, rowBounds, countKey);
//countKey.update(countSql);
BoundSql countBoundSql = new BoundSql(countMs.getConfiguration(), countSql, boundSql.getParameterMappings(), parameter);
//当使用动态 SQL 时,可能会产生临时的参数,这些参数需要手动设置到新的 BoundSql 中
for (String key : additionalParameters.keySet()) {
countBoundSql.setAdditionalParameter(key, additionalParameters.get(key));
}
//对 boundSql 的拦截处理
if (dialect instanceof BoundSqlInterceptor.Chain) {
countBoundSql = ((BoundSqlInterceptor.Chain) dialect).doBoundSql(BoundSqlInterceptor.Type.COUNT_SQL, countBoundSql, countKey);
}
//执行 count 查询
Object countResultList = executor.query(countMs, parameter, RowBounds.DEFAULT, resultHandler, countKey, countBoundSql);
//某些数据(如 TDEngine)查询 count 无结果时返回 null
if (countResultList == null || ((List) countResultList).isEmpty()) {
return 0L;
}
return ((Number) ((List) countResultList).get(0)).longValue();
} 
3.3.4 调用方言构建COUNT的SQL语句。
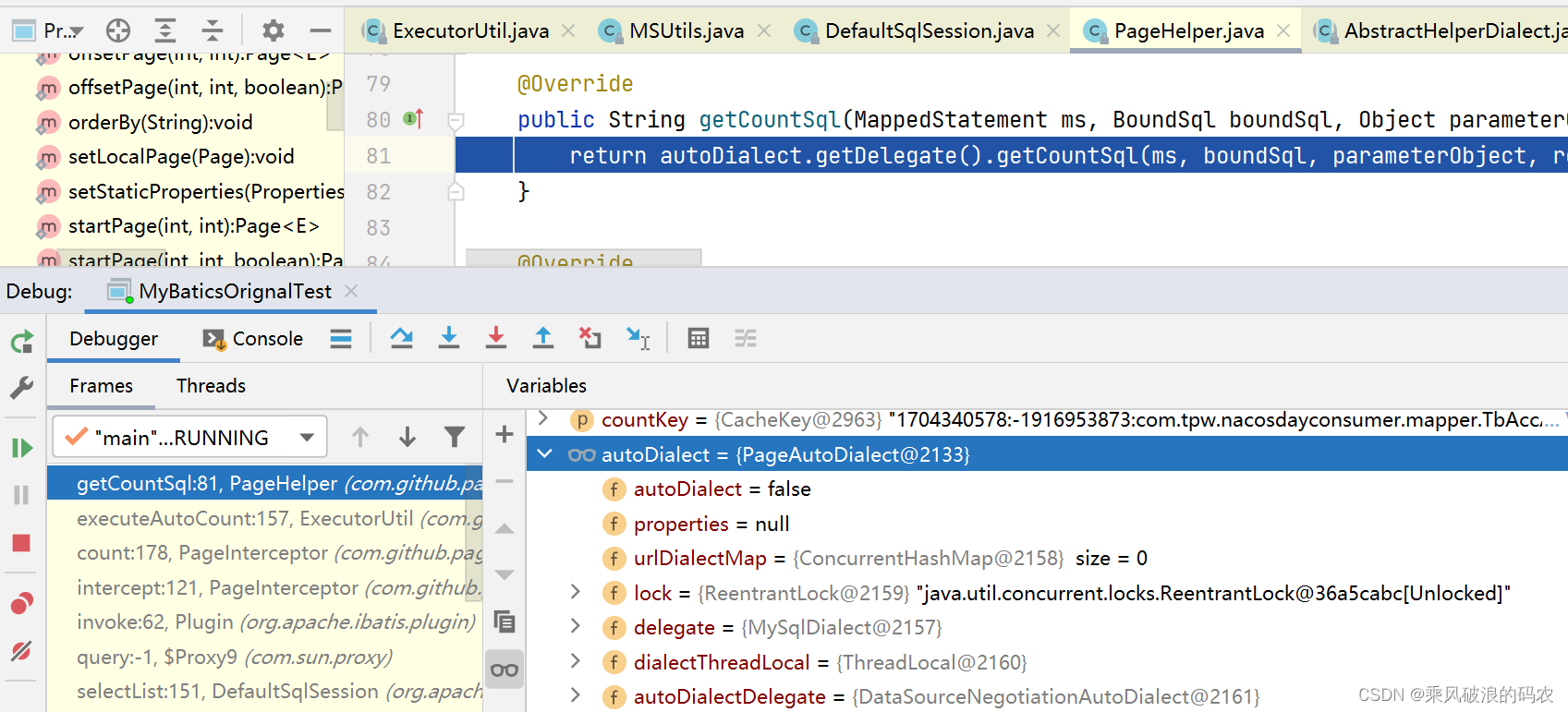
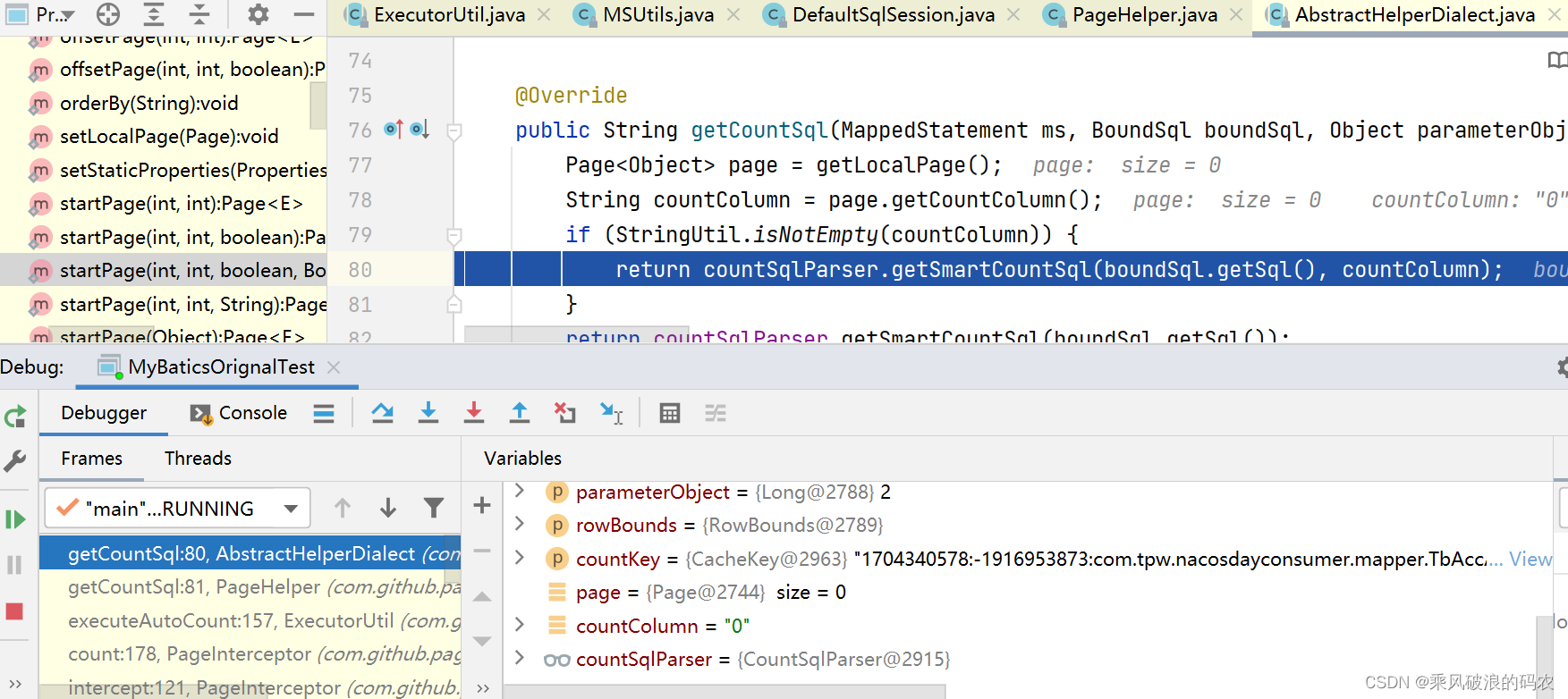
最终落到mysqlDialet的生成COUNT的SQL
public abstract class AbstractHelperDialect extends AbstractDialect implements Constant {
@Override
public String getCountSql(MappedStatement ms, BoundSql boundSql, Object parameterObject, RowBounds rowBounds, CacheKey countKey) {
Page<Object> page = getLocalPage();
String countColumn = page.getCountColumn();
if (StringUtil.isNotEmpty(countColumn)) {
return countSqlParser.getSmartCountSql(boundSql.getSql(), countColumn);
}
return countSqlParser.getSmartCountSql(boundSql.getSql());
} 
最终落到countSqlParser来生成COUNT的SQL,其实就是把SELECT中的字段换成count列名。
这里使用了一个SQLPARSER的语法包来进行解析。
public class CountSqlParser {
public String getSmartCountSql(String sql, String countColumn) {
//解析SQL
Statement stmt = null;
//特殊sql不需要去掉order by时,使用注释前缀
if(sql.indexOf(KEEP_ORDERBY) >= 0){
return getSimpleCountSql(sql, countColumn);
}
try {
stmt = CCJSqlParserUtil.parse(sql);
} catch (Throwable e) {
//无法解析的用一般方法返回count语句
return getSimpleCountSql(sql, countColumn);
}
Select select = (Select) stmt;
SelectBody selectBody = select.getSelectBody();
try {
//处理body-去order by
processSelectBody(selectBody);
} catch (Exception e) {
//当 sql 包含 group by 时,不去除 order by
return getSimpleCountSql(sql, countColumn);
}
//处理with-去order by
processWithItemsList(select.getWithItemsList());
//处理为count查询
sqlToCount(select, countColumn);
String result = select.toString();
return result;
}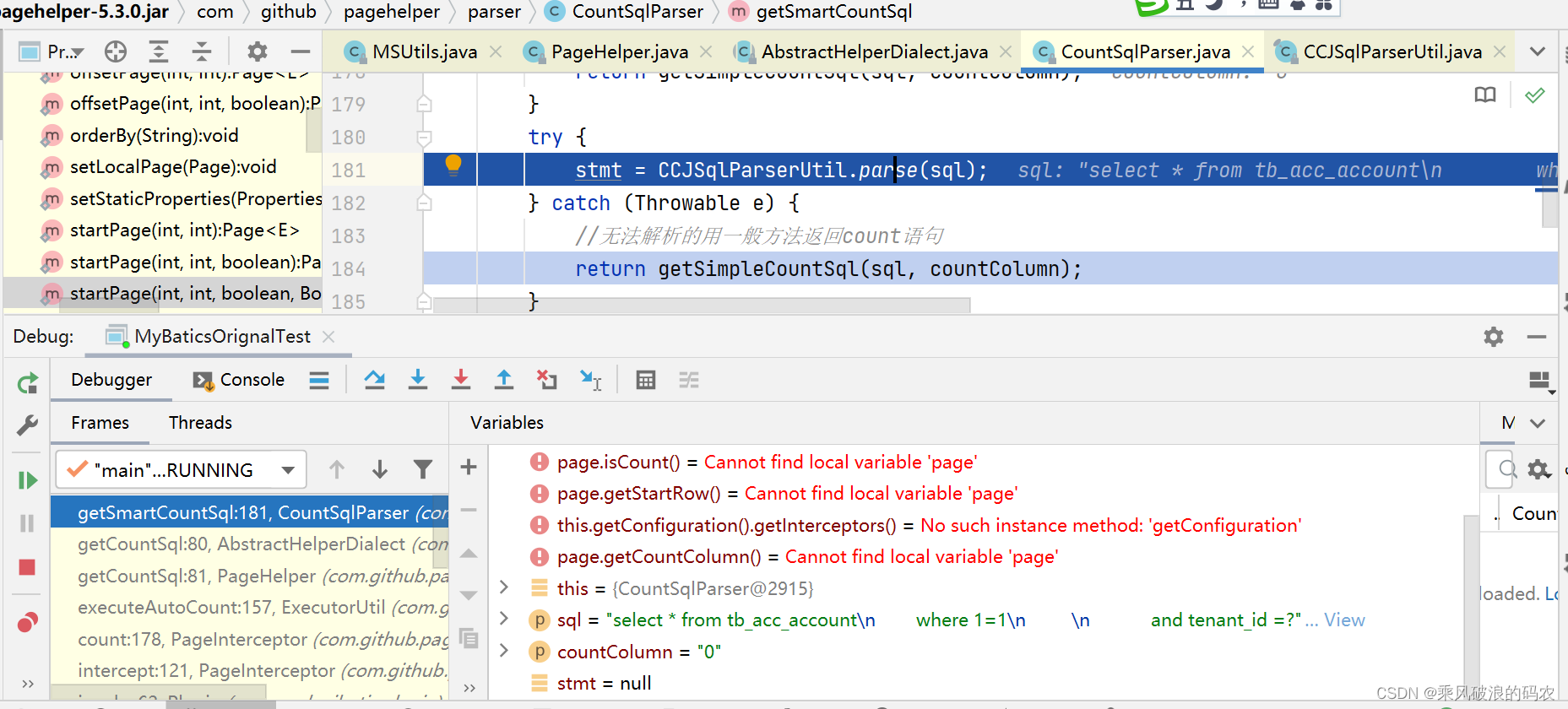
这里用到了sqlparser的解析SQL
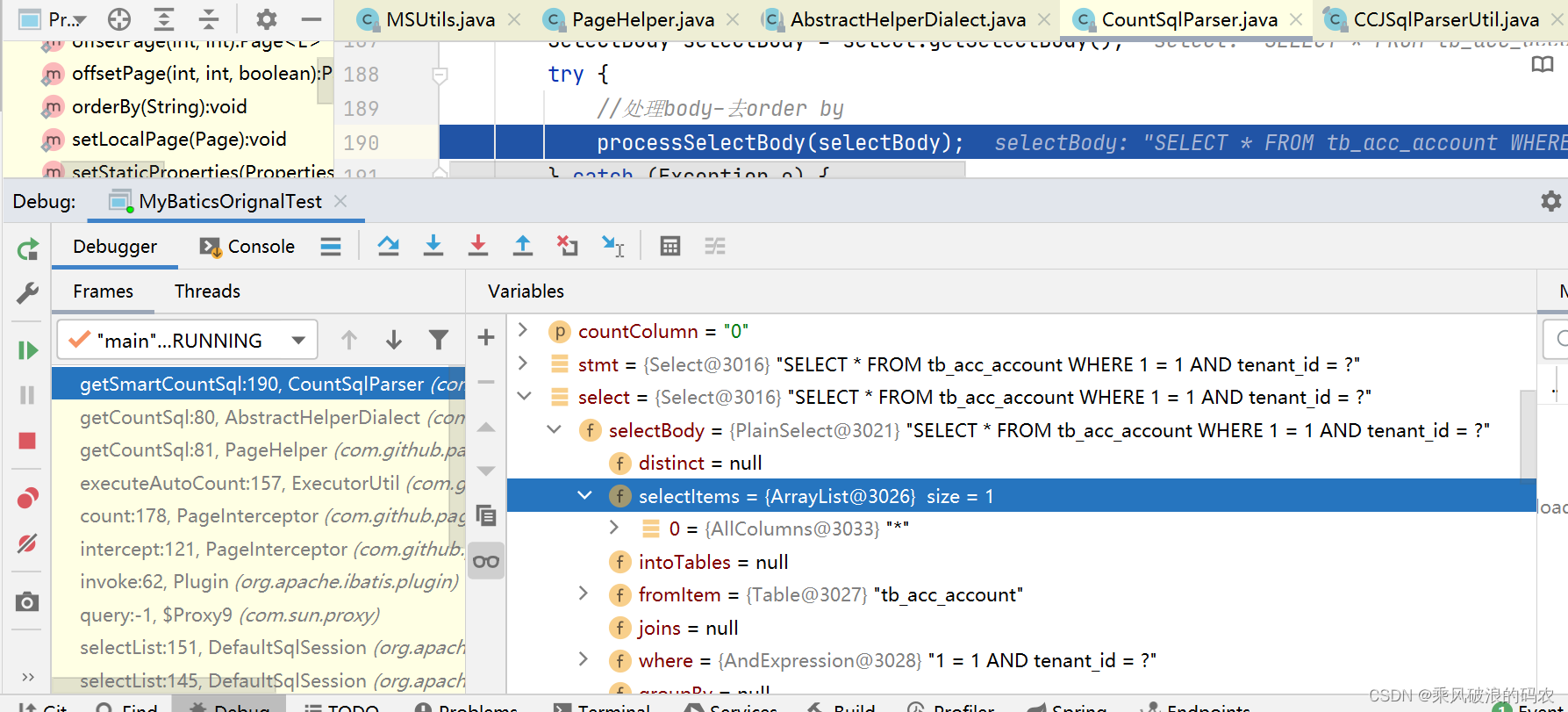
将sql转换为count查询
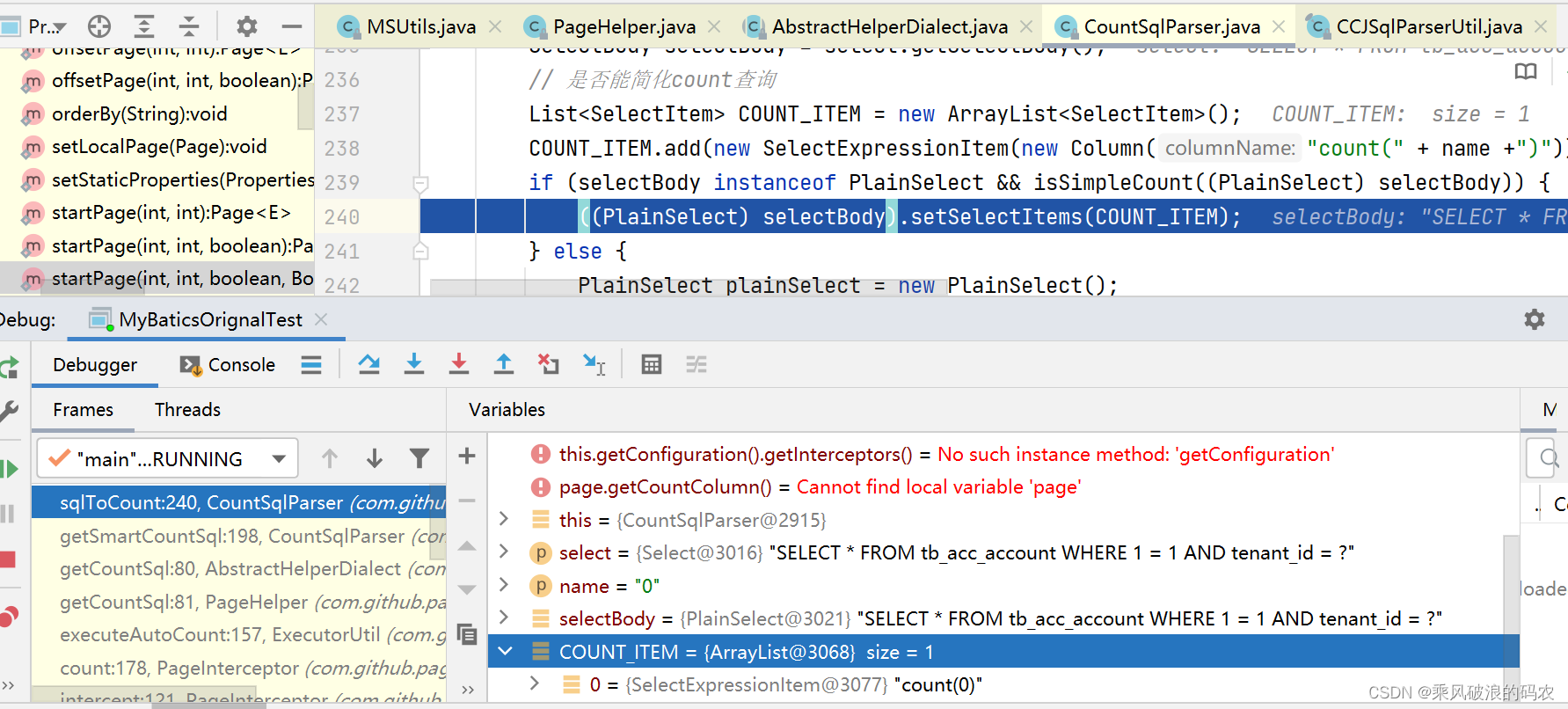
public class CountSqlParser {
/**
* 将sql转换为count查询
*
* @param select
*/
public void sqlToCount(Select select, String name) {
SelectBody selectBody = select.getSelectBody();
// 是否能简化count查询
List<SelectItem> COUNT_ITEM = new ArrayList<SelectItem>();
COUNT_ITEM.add(new SelectExpressionItem(new Column("count(" + name +")")));
if (selectBody instanceof PlainSelect && isSimpleCount((PlainSelect) selectBody)) {
((PlainSelect) selectBody).setSelectItems(COUNT_ITEM);
} else {
PlainSelect plainSelect = new PlainSelect();
SubSelect subSelect = new SubSelect();
subSelect.setSelectBody(selectBody);
subSelect.setAlias(TABLE_ALIAS);
plainSelect.setFromItem(subSelect);
plainSelect.setSelectItems(COUNT_ITEM);
select.setSelectBody(plainSelect);
}
} 
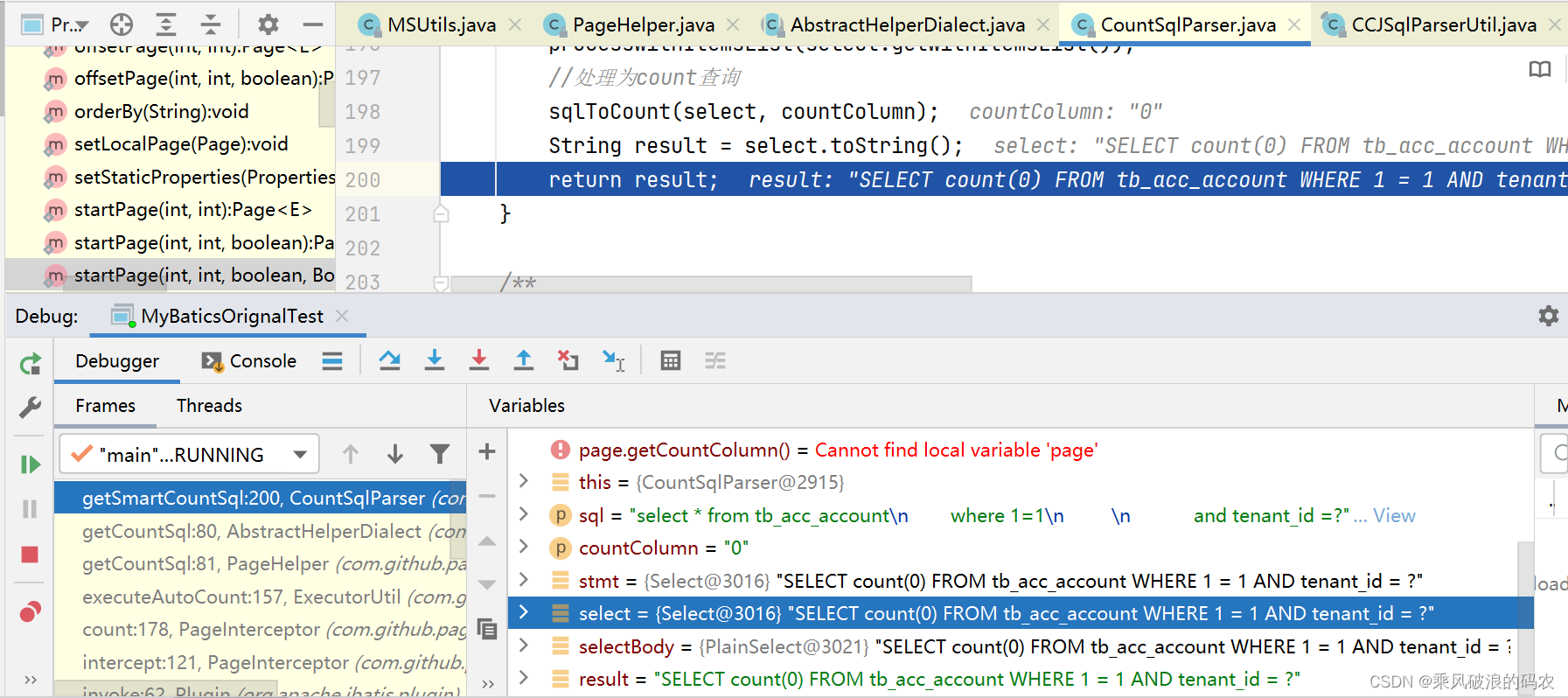 替换完看到生成了COUNT语句。
替换完看到生成了COUNT语句。
3.3.5 生成COUNT的SQL语句的boundSql,然后调用缓存执行器的查询语法来进行进行的COUNT查询获取总数。
BoundSql countBoundSql = new BoundSql(countMs.getConfiguration(), countSql, boundSql.getParameterMappings(), parameter);
//执行 count 查询
Object countResultList = executor.query(countMs, parameter, RowBounds.DEFAULT, resultHandler, countKey, countBoundSql);
//某些数据(如 TDEngine)查询 count 无结果时返回 null
if (countResultList == null || ((List) countResultList).isEmpty()) {
return 0L;
}
return ((Number) ((List) countResultList).get(0)).longValue(); 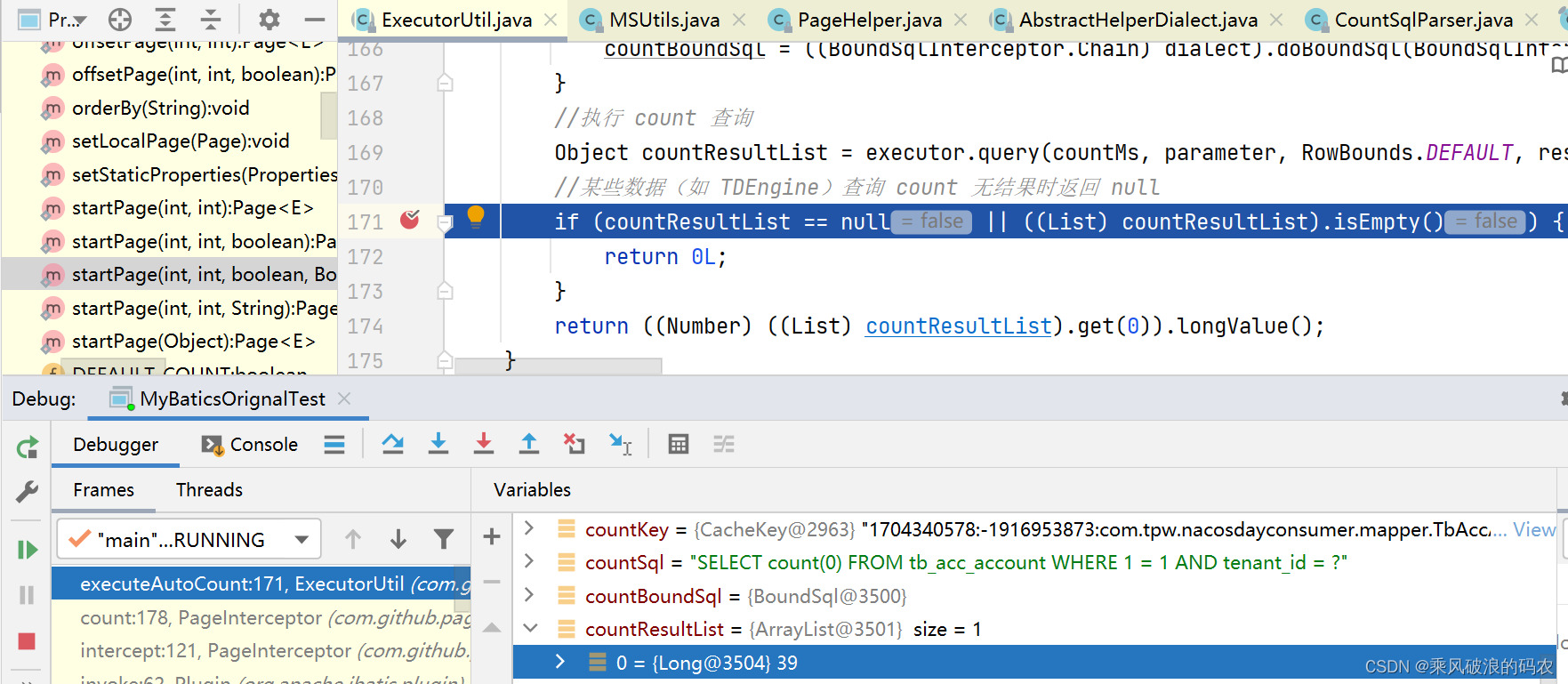
可以看到是39条记录。
3.3.6 接下来执行afterCount方法
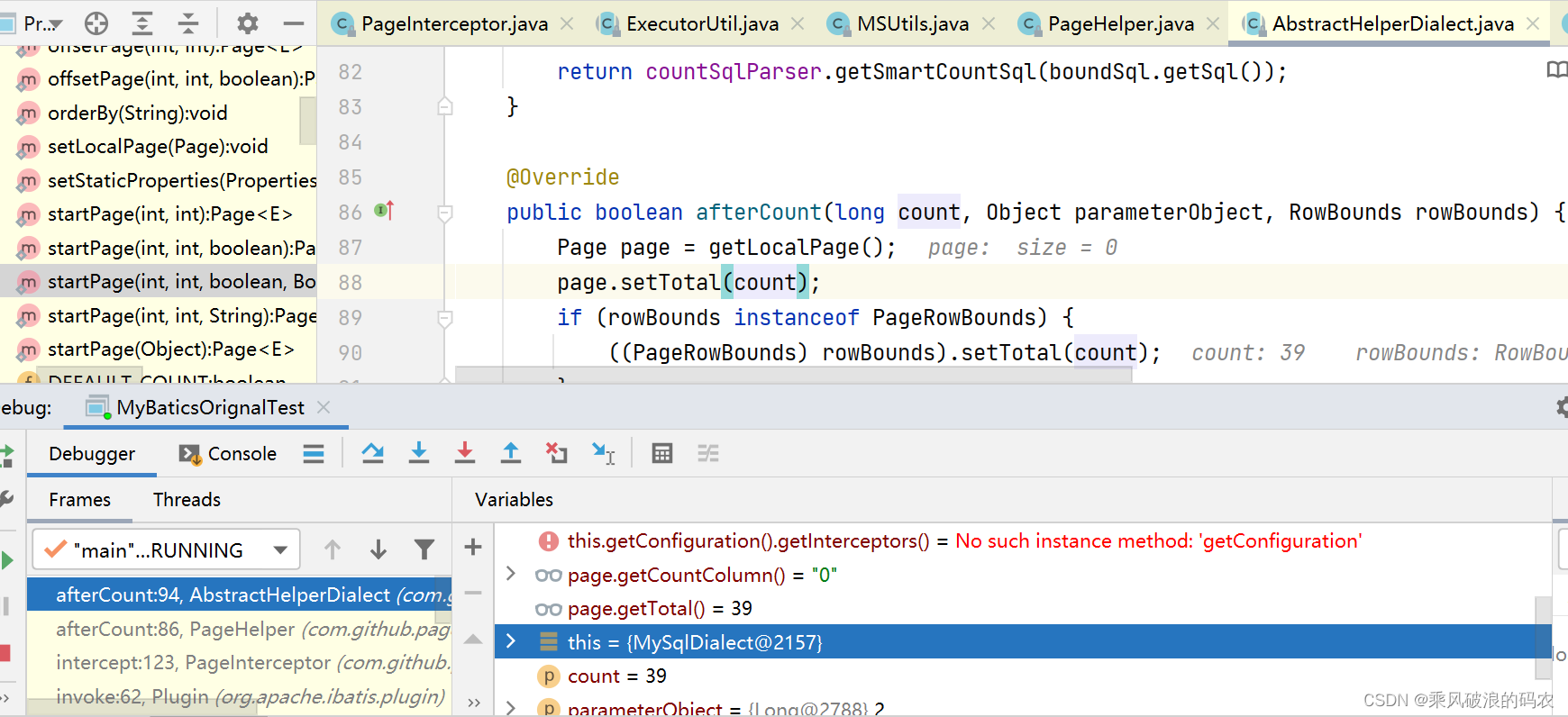
这里把总数存储到当前线程变量的PAGE对象中去。
 看到只要没超出总数,就是要分页的。
看到只要没超出总数,就是要分页的。
3.3.7 接下来ExecutorUtil.pageQuery方法进行真正的分页查询。
ExecutorUtil.pageQuery方法:这个方法比较复杂,是实现最终数据查询的地方,主要的逻辑是获取对应数据库方言的分页语句形式,MySql的话是在com.github.pagehelper.dialect.helper.MySqlDialect#getPageSql方法中,通过添加limit实现
public abstract class ExecutorUtil {
public static <E> List<E> pageQuery(Dialect dialect, Executor executor, MappedStatement ms, Object parameter,
RowBounds rowBounds, ResultHandler resultHandler,
BoundSql boundSql, CacheKey cacheKey) throws SQLException {
//判断是否需要进行分页查询
if (dialect.beforePage(ms, parameter, rowBounds)) {
//生成分页的缓存 key
CacheKey pageKey = cacheKey;
//处理参数对象
parameter = dialect.processParameterObject(ms, parameter, boundSql, pageKey);
//调用方言获取分页 sql
String pageSql = dialect.getPageSql(ms, boundSql, parameter, rowBounds, pageKey);
BoundSql pageBoundSql = new BoundSql(ms.getConfiguration(), pageSql, boundSql.getParameterMappings(), parameter);
Map<String, Object> additionalParameters = getAdditionalParameter(boundSql);
//设置动态参数
for (String key : additionalParameters.keySet()) {
pageBoundSql.setAdditionalParameter(key, additionalParameters.get(key));
}
//对 boundSql 的拦截处理
if (dialect instanceof BoundSqlInterceptor.Chain) {
pageBoundSql = ((BoundSqlInterceptor.Chain) dialect).doBoundSql(BoundSqlInterceptor.Type.PAGE_SQL, pageBoundSql, pageKey);
}
//执行分页查询
return executor.query(ms, parameter, RowBounds.DEFAULT, resultHandler, pageKey, pageBoundSql);
} else {
//不执行分页的情况下,也不执行内存分页
return executor.query(ms, parameter, RowBounds.DEFAULT, resultHandler, cacheKey, boundSql);
}
}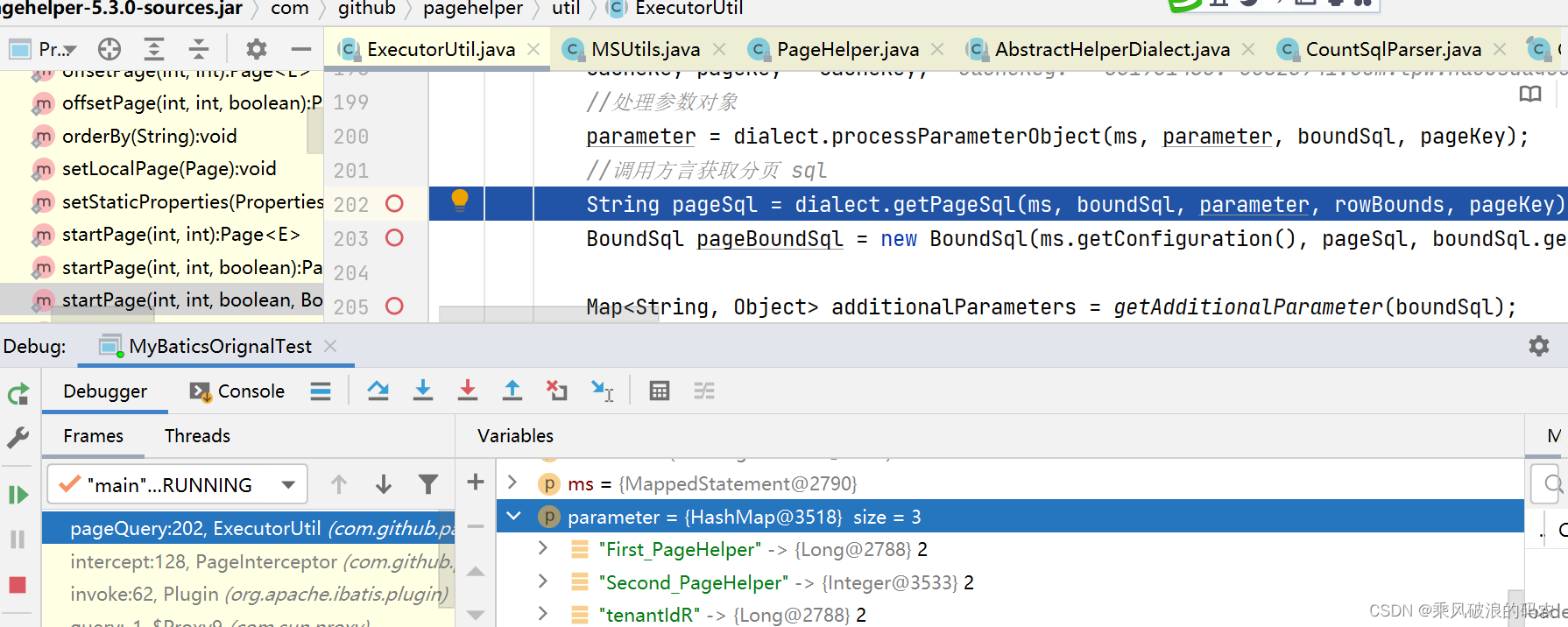
接下来调用MYSQL的方言生成分页的SQL
public abstract class AbstractHelperDialect extends AbstractDialect implements Constant {
@Override
public String getPageSql(MappedStatement ms, BoundSql boundSql, Object parameterObject, RowBounds rowBounds, CacheKey pageKey) {
String sql = boundSql.getSql();
Page page = getLocalPage();
//支持 order by
String orderBy = page.getOrderBy();
if (StringUtil.isNotEmpty(orderBy)) {
pageKey.update(orderBy);
sql = OrderByParser.converToOrderBySql(sql, orderBy);
}
if (page.isOrderByOnly()) {
return sql;
}
return getPageSql(sql, page, pageKey);
} 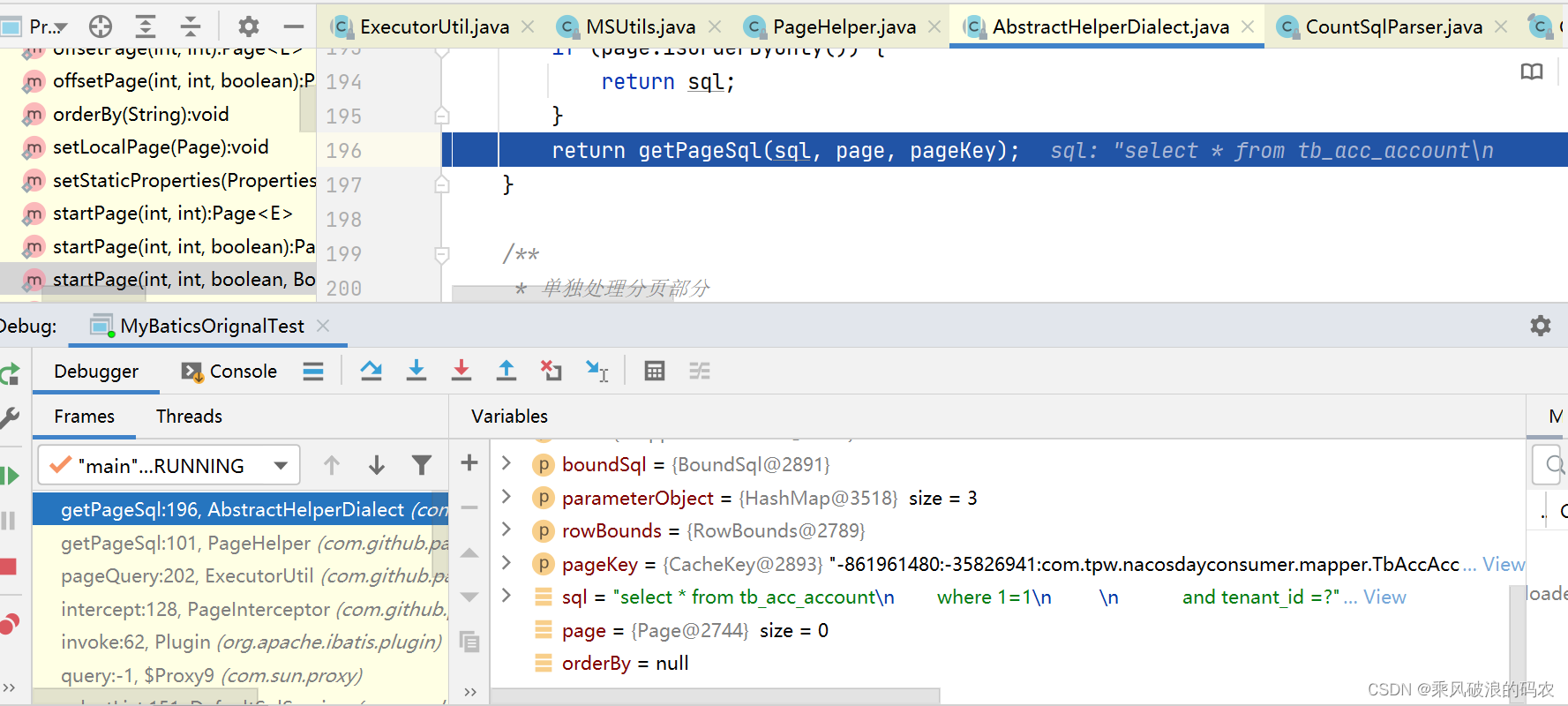
上面是抽象基类的生成PAGESQL方法,接着进入MYSQL的生成PAGE SQL。
public class MySqlDialect extends AbstractHelperDialect {
@Override
public String getPageSql(String sql, Page page, CacheKey pageKey) {
StringBuilder sqlBuilder = new StringBuilder(sql.length() + 14);
sqlBuilder.append(sql);
if (page.getStartRow() == 0) {
sqlBuilder.append("\n LIMIT ? ");
} else {
sqlBuilder.append("\n LIMIT ?, ? ");
}
return sqlBuilder.toString();
} 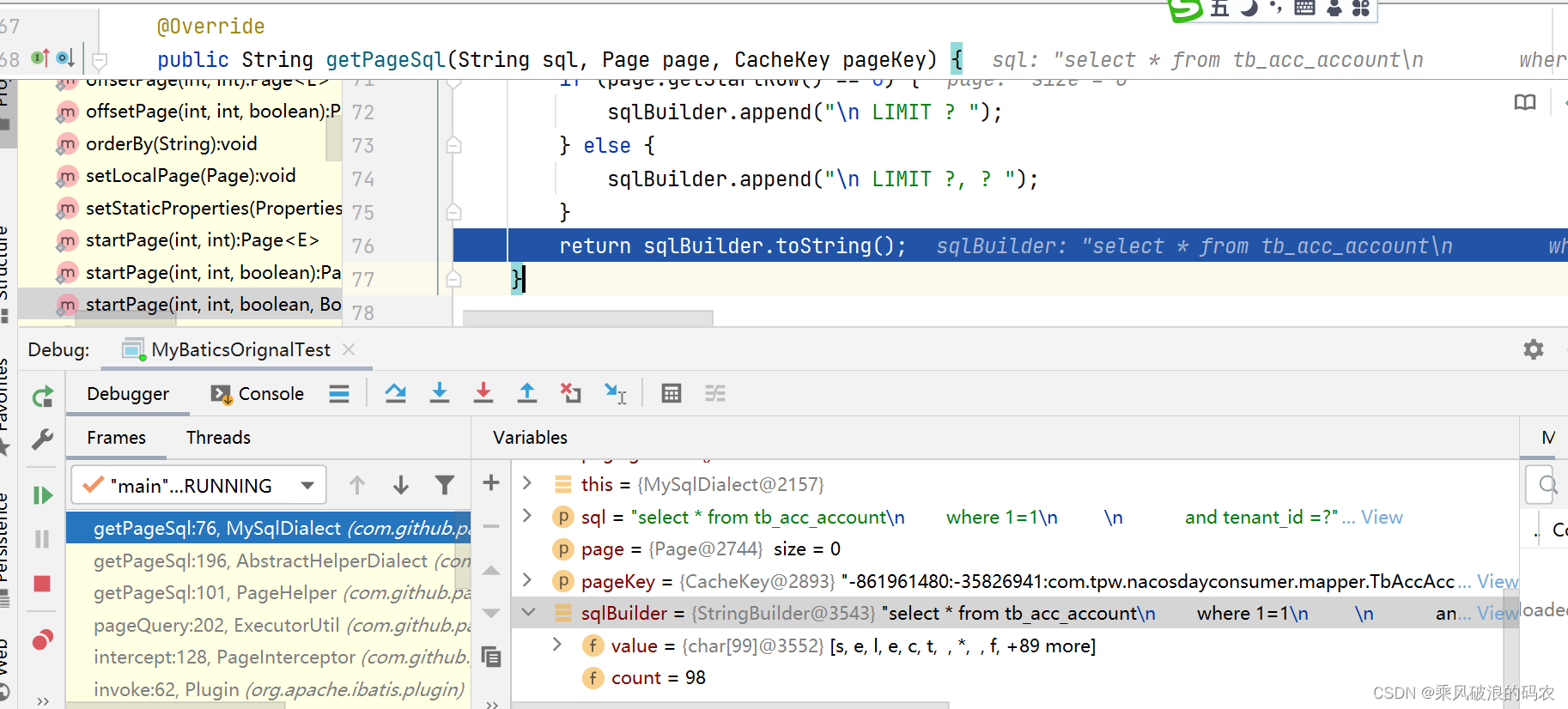
可以看到就是添加了LIMIT而 已。
BoundSql pageBoundSql = new BoundSql(ms.getConfiguration(), pageSql, boundSql.getParameterMappings(), parameter);
Map<String, Object> additionalParameters = getAdditionalParameter(boundSql);
//设置动态参数
for (String key : additionalParameters.keySet()) {
pageBoundSql.setAdditionalParameter(key, additionalParameters.get(key));
}
//对 boundSql 的拦截处理
if (dialect instanceof BoundSqlInterceptor.Chain) {
pageBoundSql = ((BoundSqlInterceptor.Chain) dialect).doBoundSql(BoundSqlInterceptor.Type.PAGE_SQL, pageBoundSql, pageKey);
}
//执行分页查询
return executor.query(ms, parameter, RowBounds.DEFAULT, resultHandler, pageKey, pageBoundSql);接下来构建boundSql,设置参数,执行分页查询。
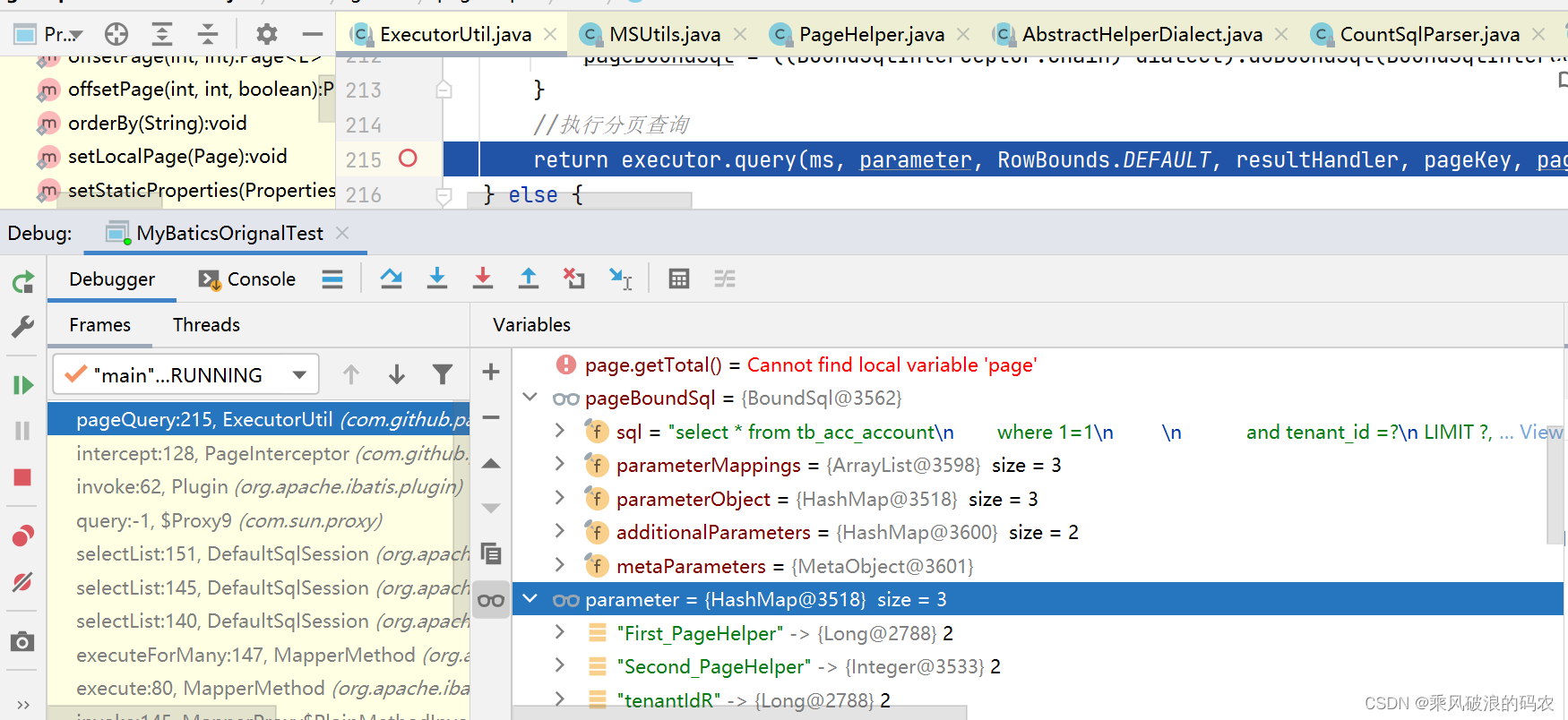
3.3.8 可以看到执行结果。
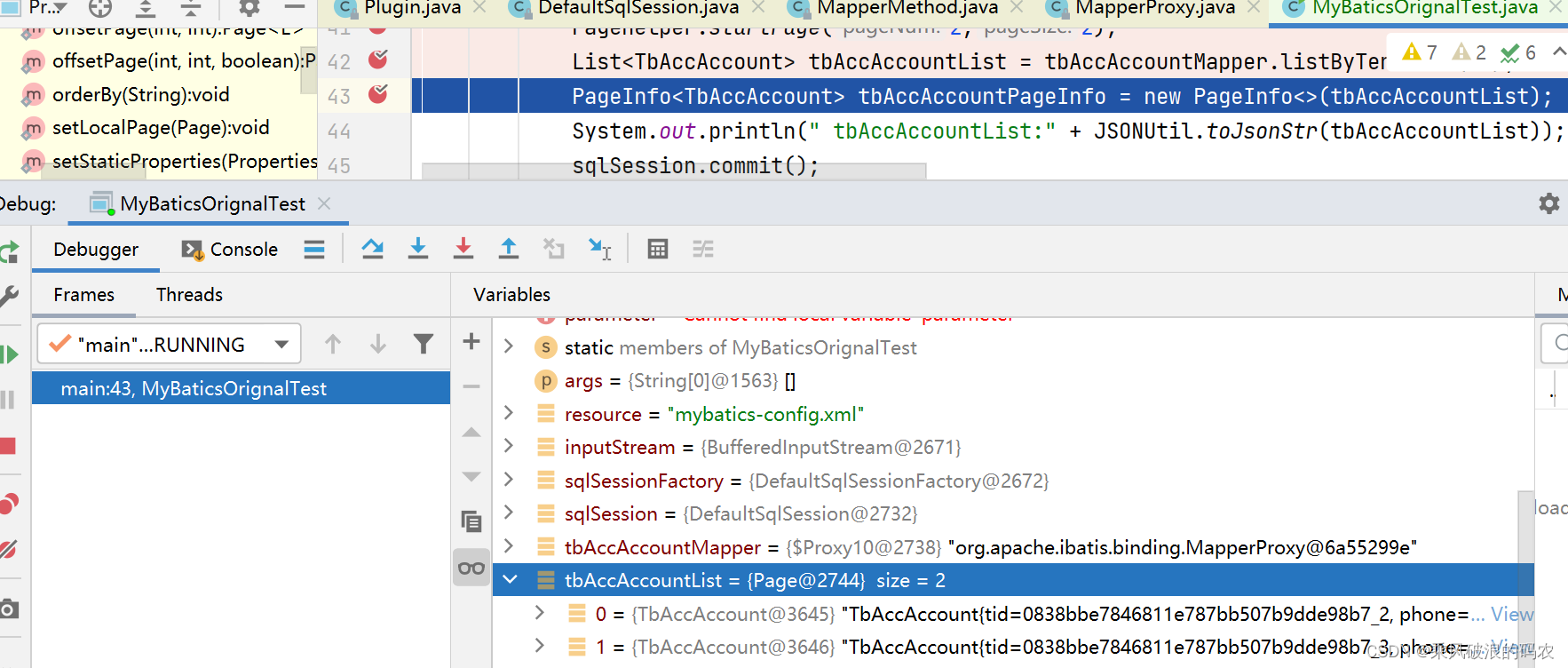
3.3. 9 afterPage方法:返回结果的整理,将查询的数据结果以及分页的信息(总数总页数等)统一聚合设置到page对象中
afterAll方法:清理线程变量中的page对象,避免影响下一个sql的执行















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









