







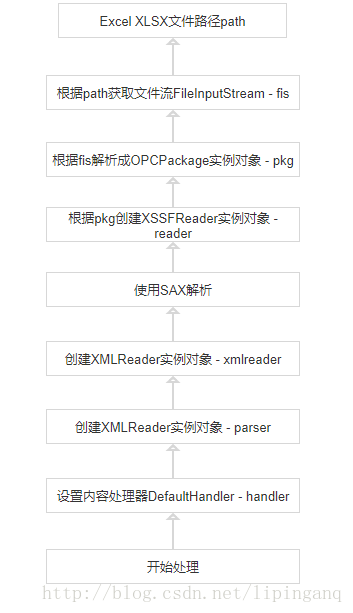
一. 解析步骤
二. OPCPackage
当使用POI事件模式解析Excel XLSX文档时:
- POI根据xlsx文档的路径path获取到文件File - file
- 使用java.util.zip.ZipFile打开file文件 - zip
- 从zip中获取到[Content_Types].xml
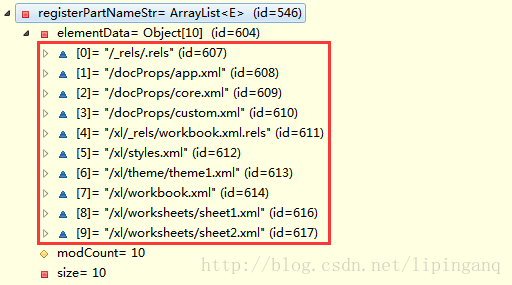
- 解析[Content_Types].xml,记录解析出Excel各个xml名称:ArrayList
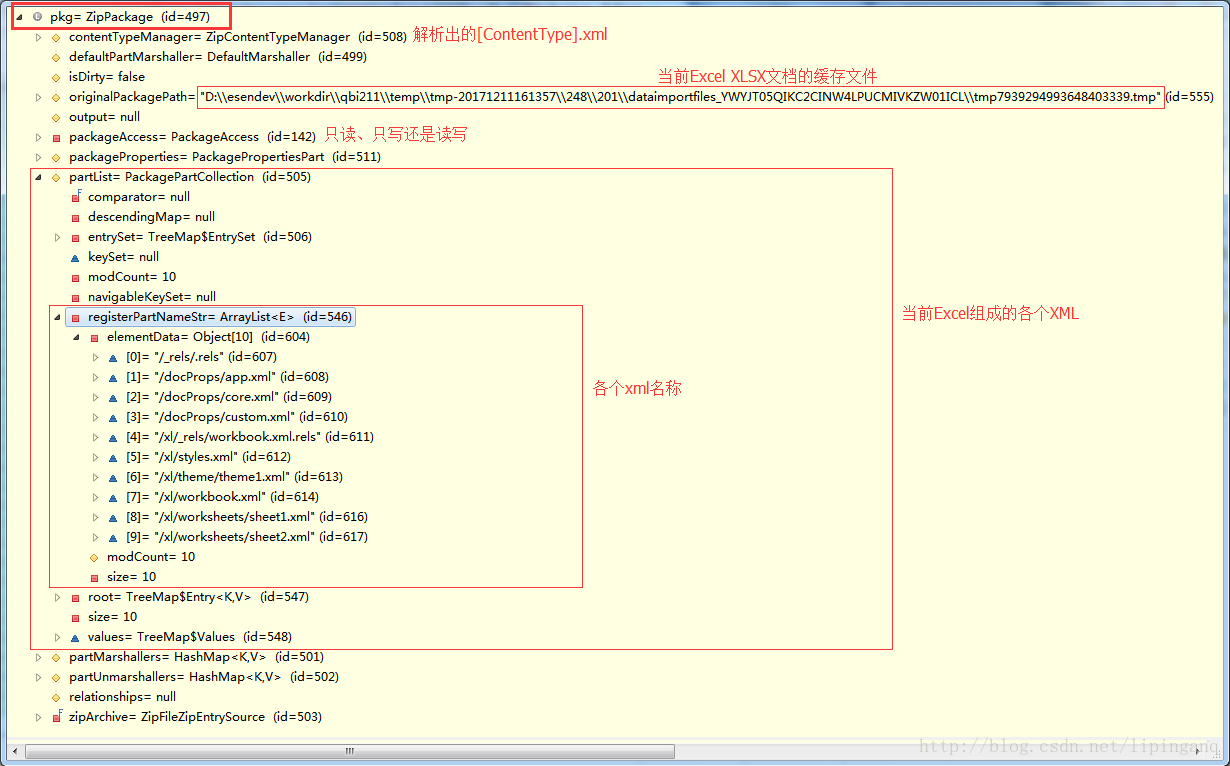
- Excel解析成ZipPackage实例对象
首先把xlsx文档解析包装成ZipPackage实例对象
package org.apache.poi.openxml4j.opc;
public enum PackageAccess {
READ, // 只读
WRITE, // 只写
READ_WRITE // 读写
}
// 只读取xlsx文档
OPCPackage pkg = OPCPackage.open("C:\Users\Administrator\Desktop\测试.xlsx", PackageAccess.READ)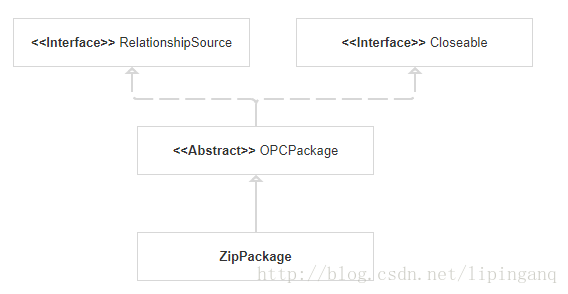
2.1 XLSX文档组成
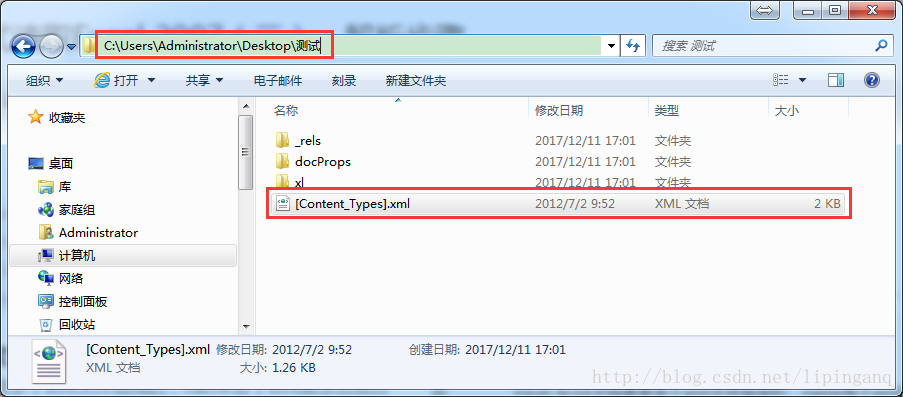
Excel XLSX文档是有多个xml文件组成的,name各个xml是怎么组合在一起?POI是怎么来解析的呢?
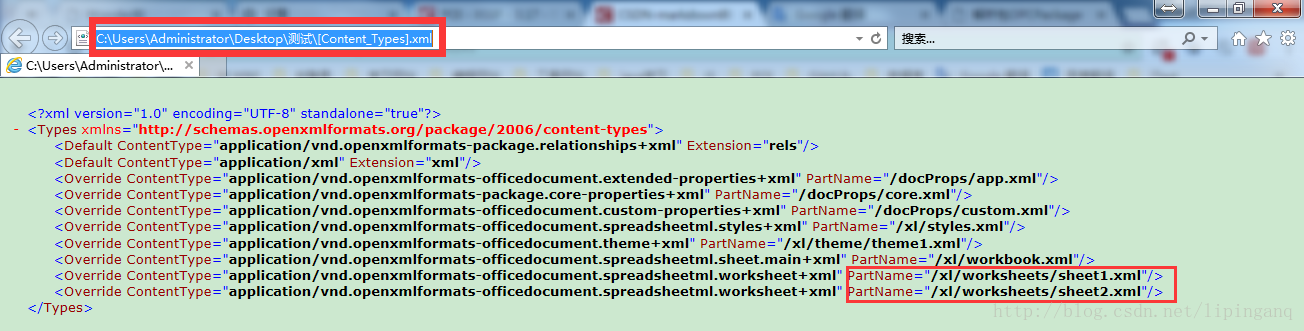
在Excel文档中,存在一个[Content_Types].xml文档,这个文档记录了整个Excel文档中所有xml:
2.2 解析[Content_Types].xml
org.apache.poi.openxml4j.opc.internal.ContentTypeManager类用于解析[Content_Types].xml文档,记录解析出的结果
// ContentTypeManager解析方法
parseContentTypesFile(InputStream in)<?xml version="1.0" encoding="UTF-8" standalone="true"?>
-<Types xmlns="http://schemas.openxmlformats.org/package/2006/content-types">
<Default ContentType="application/vnd.openxmlformats-package.relationships+xml" Extension="rels"/>
<Default ContentType="application/xml" Extension="xml"/>
<Override ContentType="application/vnd.openxmlformats-officedocument.extended-properties+xml" PartName="/docProps/app.xml"/>
<Override ContentType="application/vnd.openxmlformats-package.core-properties+xml" PartName="/docProps/core.xml"/>
<Override ContentType="application/vnd.openxmlformats-officedocument.custom-properties+xml" PartName="/docProps/custom.xml"/>
<Override ContentType="application/vnd.openxmlformats-officedocument.spreadsheetml.styles+xml" PartName="/xl/styles.xml"/>
<Override ContentType="application/vnd.openxmlformats-officedocument.theme+xml" PartName="/xl/theme/theme1.xml"/>
<Override ContentType="application/vnd.openxmlformats-officedocument.spreadsheetml.sheet.main+xml" PartName="/xl/workbook.xml"/>
<Override ContentType="application/vnd.openxmlformats-officedocument.spreadsheetml.worksheet+xml" PartName="/xl/worksheets/sheet1.xml"/>
<Override ContentType="application/vnd.openxmlformats-officedocument.spreadsheetml.worksheet+xml" PartName="/xl/worksheets/sheet2.xml"/>
</Types>
解析结果:
2.3 解析出ZipPackage
Excel XLSX文档会被POI解析出ZipPackage实例对象:
3. XSSFReader
XSSFReader这个类可以很容易地获得OOXML .xlsx文件的各个部分,适用于低内存sax解析或类似的情况
XSSFReader构成了XSSF的事件模式的核心部分
org.apache.poi.xssf.eventusermodel.XSSFReader
// 获取当前Excel所有Sheet中字符串
public SharedStringsTable getSharedStringsTable()
// 获取当前Excel所有Sheet中单元格样式
public StylesTable getStylesTable()
// 获取sharedStrings.xml的输入流
public InputStream getSharedStringsData()
// 获取styles.xml输入流
public InputStream getStylesData()
// 获取theme1.xml输入流
public InputStream getThemesData()
// 获取workbook.xml输入流
public InputStream getWorkbookData()
// 根据Sheet的id获取Sheet输入流
public InputStream getSheet(String relId)
// 获取Excel中所有SHeet的输入流的迭代器
public Iterator<InputStream> getSheetsData()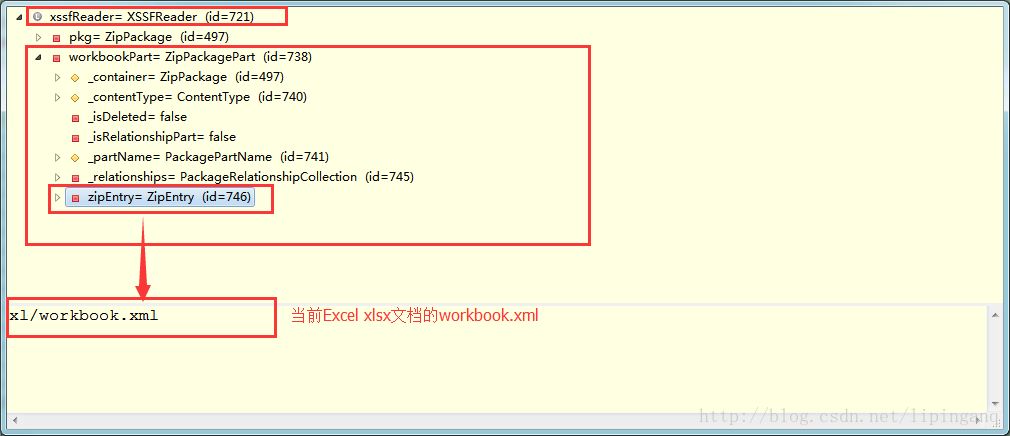
4. SAX解析XML
使用SAX解析XML,需要实现自己的处理类,需要继承DefaultHandler
public class SheetHandler extends DefaultHandler {
/**
* 解析到XML的开始标签触发此方法
*
* @param uri 如"http://schemas.openxmlformats.org/spreadsheetml/2006/main"
* @param localName 当前开始标签的名字
* @param name 标签名
* @param attributes 当前标签的属性对象
* */
@Override
public void startElement(String uri, String localName, String name, Attributes attributes) throws SAXException {
if ("row".equals(name)) {// <row>:开始处理某一行
//
} else if ("c".equals(name)) {// <c>:一个单元格
//
} else if (isTextTag(name)) {// <v>:单元格值
//
} else if ("f".equals(name)) {// <f>:公式表达式标签
//
} else if ("is".equals(name)) {// 内联字符串外部标签
//
} else if ("col".equals(name)) {// 处理隐藏列
//
}
}
/**
* 返回单元格的值
* */
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
StringBuffer sb = new StringBuffer();
sb.append(ch, start, length);
}
/**
* 解析到XML的结束标签触发此方法
* 如:</row>
* @param uri
* @param localName
* @param name
* */
@Override
public void endElement(String uri, String localName, String name) throws SAXException {
if ("c".equals(name)) {// <c>标签结束
//
} else if (isTextTag(name)) {// 文本单元格结束标签
//
} else if ("row".equals(name)) {// 行结束标签
//
} else if ("f".equals(name)) {// </f>标签
//
} else if ("is".equals(name)) {// </is>标签
//
} else if ("worksheet".equals(name)) {// Sheet读取完成
//
}
}
}处理模型:
public class ExcelParser {
public void parse () {
OPCPackage pkg = OPCPackage.open("C:\\Users\\Administrator\\Desktop\\测试.xlsx", PackageAccess.READ);
try {
XSSFReader reader = new XSSFReader(pkg);
SharedStringsTable sst = reader.getSharedStringsTable();
StylesTable st = reader.getStylesTable();
XMLReader parser = XMLReaderFactory.createXMLReader();
// 处理公共属性:Sheet名,Sheet合并单元格
parser.setContentHandler(new SheetHandler());
/**
* 返回一个迭代器,此迭代器会依次得到所有不同的sheet。
* 每个sheet的InputStream只有从Iterator获取时才会打开。
* 解析完每个sheet时关闭InputStream。
* */
XSSFReader.SheetIterator sheets = (XSSFReader.SheetIterator) reader.getSheetsData();
while (sheets.hasNext()) {
InputStream sheetstream = sheets.next();
InputSource sheetSource = new InputSource(sheetstream);
try {
// 解析sheet: com.sun.org.apache.xerces.internal.jaxp.SAXParserImpl:522
parser.parse(sheetSource);
} finally {
sheetstream.close();
}
}
} finally {
pkg.close();
}
}
}














 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









