









并发处理
1. 序
一个成熟的系统,往往不是将功能写好便大功告成,有些接口必不可少的便是并发会不会造成影响。
因此,在写每一个接口时一定要考虑,并发的出现会不会造成影响,用户的感受是其次的,关键是数据会不会出现错误,这是最致命的,一般来说,用户流水数据发生变化的接口均需要进行并发处理!
此时可能会想到Synchronized,但是,它是通过悲观锁来实现的,并且 Synchronized只适用于单机版,如果存在集群情况下(现在都流行分布式,这个情况也难免会遇到),它并不能保障不出现并发问题,那么,此时该使用什么方式来解决呢?只能用分布式锁。(redis或者zookeeper)
2. 探索
后续进行访问测试时均用以下该脚本
public class MyThread extends Thread {
@Override
public void run() {
UnirestTest.jml17();
}
}
public class UnirestTest {
public static void main(String[] args) {
Long time1 = System.currentTimeMillis();
for (int i = 0;i< 10;i++){
MyThread myThread = new MyThread();
myThread.start();
}
Long time2 = System.currentTimeMillis();
System.out.println(time2-time1);
}
public static void jml17() {
try {
for(int i = 0; i<100; i++) {
Unirest.setTimeouts(0, 0);
HttpResponse<String> response = Unirest.post("http://shangjietech.vip/scan/jml/consumer/consumerScanPoster5")
.asString();
System.out.println(response);
System.out.println(i);
}
}catch (Exception e){
System.out.println(e);
}
}
}
//就是一个普通的多线程进行访问。
2.1. 自创
2.1.1. 过程
@PostMapping(value = "/consumerScanPoster1", produces = "application/json;charset=utf-8")
@ApiOperation("消费者扫描海报码")
@ApiResponses(
@ApiResponse(code = 200, message = "返回结果为json格式,code=200,表示成功,其他为失败,msg 对当前结果的描述,data:查询结果数据 ")
)
@Transactional
public ResponseBean<Object> consumerScanPoster1() {
try {
String openid = RandomUtil.randomNumbers(11);
String userType = "1";
String posterQrcode = "JML17poster546488393140383744";
String prizeName = "气士系列首尝活动";
if (!StrUtil.isAllNotBlank(openid, userType, posterQrcode, prizeName)) {
return new ResponseBean<>("500", "请重新登录", null);
}
//获取海报码相关信息
JmlPcPosteractivity poster = iJmlPcPosteractivityService.getOne(new QueryWrapper<JmlPcPosteractivity>().eq("poster_qrcode", posterQrcode));
if (poster == null) {
logger.info("该海报码不存在,请核对后再试");
return new ResponseBean<>("200", "扫码成功", Common.getDataMap("201", "亲,海报码不存在!", "亲,海报码不存在!"));
}
if (poster.getQrcodeStatus() != 3) {
return new ResponseBean<>("200", "扫码成功", Common.getDataMap("202", "该派发码仅限门店参加,请绑定门店后重试", "该海报码未绑定"));
}
LocalDateTime now = LocalDateTime.now();
if (poster.getStartTime().compareTo(now) > 0) {
return new ResponseBean<>("200", "扫码成功", Common.getDataMap("203", "亲,活动未开始!", "海报活动未开始"));
}
if (poster.getEndTime().compareTo(now) < 0) {
return new ResponseBean<>("200", "扫码成功", Common.getDataMap("204", "亲,活动已结束!", "海报活动已结束"));
}
if (poster.getQrcodeUnusedNum() <= 0) {
logger.info("初次检验,奖品已领取完");
return new ResponseBean<>("200", "扫码成功", Common.getDataMap("205", "您来晚了,饮品已发完!", "您来晚了,饮品已发完!"));
}
// JmlMpWechatuser u = iJmlMpWechatuserService.getOne(new QueryWrapper<JmlMpWechatuser>().eq("open_id", openid));
// if (u == null) {
// return new ResponseBean<>("500", "请重新登录", null);
// }
// if (!(u.getType() == 0 || u.getType() == 1)) {
// return new ResponseBean<>("200", "扫码成功", Common.getDataMap("206", "该派发码仅限消费者参加,请核对后重试", "身份异常"));
// }
QueryWrapper<JmlMpPosterflowing> pfq = new QueryWrapper<>();
pfq.eq("user_openid", openid);
pfq.eq("get_prize", poster.getPrizeId());
pfq.eq("poster_shop", poster.getShopId());
List<JmlMpPosterflowing> pf = iJmlMpPosterflowingService.list(pfq);
if (pf != null && pf.size() > 0) {
return new ResponseBean<>("200", "扫码成功", Common.getDataMap("207", "您已经领取过了,不能重复领取!", "您已经领取过了,不能重复领取!"));
}
//可领取,但需要注意高并发时未领取不能小于0,微信时单点登录,不需要锁人
// String rsourkey = JmlRedisKeysConstant.LOCK_USER.concat(openid);
String posterId = poster.getId();
String rposterkey = JmlRedisKeysConstant.LOCK_POSTER_CONSUMER.concat(posterId);
Boolean rposterres = redisUtils.hasKey(rposterkey);
while (rposterres) {
Thread.sleep(sleepTime);
rposterres = redisUtils.hasKey(rposterkey);
}
redisUtils.set(rposterkey, 0, rkeyTime);
JmlPcPosteractivity posterNew = iJmlPcPosteractivityService.getOne(new QueryWrapper<JmlPcPosteractivity>().eq("poster_qrcode", posterQrcode));
if (posterNew.getQrcodeUnusedNum() <= 0) {
logger.info("二次检验,奖品已领取完");
redisUtils.del(rposterkey);
return new ResponseBean<>("200", "扫码成功", Common.getDataMap("205", "您来晚了,饮品已发完!", "您来晚了,饮品已发完"));
}
logger.info("+++++++++++++++++++++++++++++++++++++++++++++++++");
logger.info("究竟是不是走的缓存:{}",poster == posterNew);
JmlMpPosterflowing posterflowing = new JmlMpPosterflowing();
posterflowing.setUserOpenid(openid);
posterflowing.setUserType(Integer.parseInt(userType));
posterflowing.setGetTime(LocalDateTime.now());
posterflowing.setEndTime(posterNew.getEndTime());
posterflowing.setPosterId(Long.parseLong(posterId));
posterflowing.setPosterCode(posterQrcode);
posterflowing.setPosterKeepopenid(posterNew.getKeepOpenid());
posterflowing.setPosterShop(posterNew.getShopId());
posterflowing.setGetOrder(posterNew.getQrcodeUsedNum() + 1);
posterflowing.setGetPrize(posterNew.getPrizeId());
posterflowing.setGetNumber(posterNew.getPrizeRule());
posterflowing.setAwardRule(posterNew.getAwardRule());
posterflowing.setConvertStatus(0);
iJmlMpPosterflowingService.save(posterflowing);
UpdateWrapper<JmlPcPosteractivity> upPoster = new UpdateWrapper<>();
upPoster.set("qrcode_used_num", posterNew.getQrcodeUsedNum() + 1);
upPoster.set("qrcode_unused_num", posterNew.getQrcodeUnusedNum() - 1);
upPoster.set("update_time",LocalDateTime.now());
upPoster.eq("id", posterNew.getId());
iJmlPcPosteractivityService.update(upPoster);
JSONObject resp = new JSONObject();
resp.put("logid",posterflowing.getId());
resp.put("userOpenid", openid);
resp.put("keepOpenid", posterNew.getKeepOpenid());
resp.put("shopId", posterNew.getShopId());
resp.put("prizeId", posterNew.getPrizeId());
resp.put("prizeNum", posterNew.getPrizeRule());
resp.put("order", posterNew.getQrcodeUsedNum() + 1);
resp.put("endTime",df.format(posterNew.getEndTime()));
logger.info("海报奖励领取信息:{}", resp.toString());
redisUtils.del(rposterkey);
return new ResponseBean<>("200", "奖励领取成功", Common.getDataMap("200", "领取成功", resp));
} catch (Exception e) {
logger.info("消费者扫描海报码失败", e);
TransactionAspectSupport.currentTransactionStatus().setRollbackOnly();
return new ResponseBean<>(ResponseCodeEnum.OPERATION_FAILURE, "操作失败");
}
}
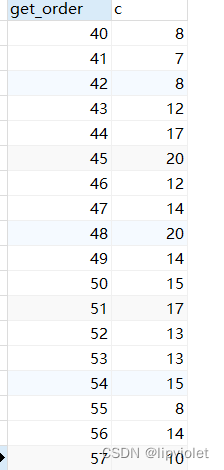
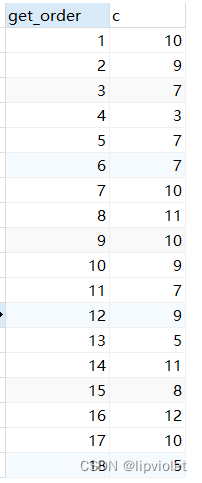
日志输出及数据库截图如下:
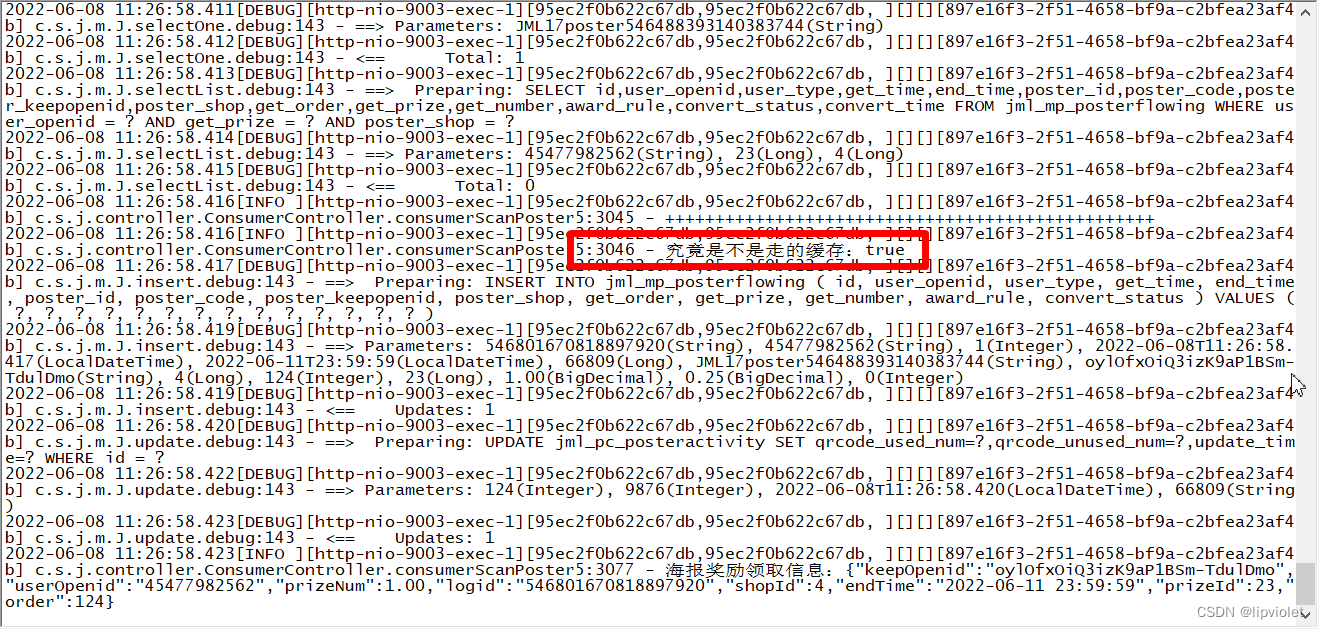

//查看是否有重复的order
SELECT pre.get_order, pre.c from
(SELECT p.get_order, count(*) as c from jml_mp_posterflowing p WHERE p.poster_code = 'JML17poster546488393140383744' GROUP BY p.get_order) pre WHERE pre .c >1;
2.1.2. 结论
2.1.2.1. 不是锁
首先说这个自创的分布式锁
String rposterkey = JmlRedisKeysConstant.LOCK_POSTER_CONSUMER.concat(posterId);
Boolean rposterres = redisUtils.hasKey(rposterkey);
while (rposterres) {
Thread.sleep(sleepTime);
rposterres = redisUtils.hasKey(rposterkey);
}
redisUtils.set(rposterkey, 0, rkeyTime);
以上就是最初上线的代码,离离原上谱,有关这个“分布式锁”,我是让经理看过的,当时说没问题,我就没细想,也许当时他没有细看吧,总之很离谱,这个东西严格来说根本不是一个锁!
因为它根本保证不了唯一性,很简单,当多个线程完全同步时,同时hasKey得到的都是false,此时多个线程便都继续进行了,程序便出现了并发。以前多计算机认识不深,觉得这种情况太过巧合,其实不然,这种情况很常见。
综上,这种操作吧,可以锁住非同步的线程,无法锁住完全同步的线程,由此导致了很离谱的现象。该方案根本就处理不了并发!!!
不过这种写法的渊源并不是单纯的放个无意义的value,是因为另一用法才出现的
ropenidkey = JmlRedisKeysConstant.LOCK_USER.concat(openid);
Boolean ropenidres = redisUtils.redLock(ropenidkey,userRLock,rkeyTime);
while (!ropenidres) {
logger.info("进入redis锁:{}", openid);
Thread.sleep(sleepTime);
ropenidres = redisUtils.redLock(ropenidkey,userRLock,rkeyTime);
}
//因为存在店员,所以使用redis分布式锁进行高并发控制。极端情况,一个码被多个人扫,最多是码被重复利用,但是一个人扫多个码,有可能会导致累计数量出错,因此优先人加锁,但是最好的情况是一人一码。
String rqrcodekey = JmlRedisKeysConstant.LOCK_QRCODE.concat(qrcode);
Boolean rqrcoderesB = redisUtils.redLock(rqrcodekey,qrcodeRlock,rkeyTime);
if(!rqrcoderesB) {
String rqrcoderes = (String) redisUtils.get(rqrcodekey);
if (rqrcoderes == null || rqrcoderes.equals(JmlConstant.Properties.FAILED)) {
redisUtils.set(rqrcodekey, JmlConstant.Properties.DOING, rkeyTime);
} else if (rqrcoderes.equals(JmlConstant.Properties.SUCCESS)) {
return new ResponseBean<>("401", "该码已使用过", "该码已使用过");
} else if (rqrcoderes.equals(JmlConstant.Properties.DOING)) {
while (rqrcoderes.equals(JmlConstant.Properties.DOING)) {
Thread.sleep(sleepTime);
rqrcoderes = (String) redisUtils.get(rqrcodekey);
if (rqrcoderes.equals(JmlConstant.Properties.SUCCESS)) {
return new ResponseBean<>("401", "该码已使用过", "该码已使用过");
}
if (rqrcoderes == null || rqrcoderes.equals(JmlConstant.Properties.FAILED)) {
redisUtils.set(rqrcodekey, JmlConstant.Properties.FAILED, rkeyTime);
}
}
} else {
logger.info("分布式锁异常,请核查:{}", userId);
}
}
// 根据value的值进行减少数据库的查询压力,直接返回该码已使用,这是那个经理给我的指导,很感谢他~~~
锁有bug,但这种根据value的值进行程序的优化还是对我很大启发。
2.1.2.2. mybitis一级缓存
再者是对mybitis缓存认识不深的问题。
mybitis的一级缓存是sqlsession级别的,它是默认开启的。
简单说就是一次事务中,如果出现了完全相同的两个sql,那么第二次便不会去数据库查询,而是直接从mybitis的缓存中获取以此来减轻数据库的压力,该缓存在并发的情况下就会导致其他线程在第二次查询之前修改了目的数据,你是拿不到了,因为你走的是mybitsi的缓存。
该问题首要的操作就是:不要在一个事务中写相同的sql!!!
2.1.2.3. 少用java计算
不要在内存(java)中进行计算,如果你的数据是最终落地到mysql,那么能在mysql做的计算,一定要在mysql里做计算,不要在内存做计算再set,很容易错误,mysql计算的好处时,永远会拿到字段的最新值。
upPoster.set("qrcode_used_num", posterNew.getQrcodeUsedNum() + 1);
upPoster.set("qrcode_unused_num", posterNew.getQrcodeUnusedNum() - 1);
以上代码就是典型的内存计算,这种代码习惯需要改变,能用mysql计算一定mysql计算
这种计算方式是导致useUnm << count(flow) 的核心原因。(当然如果不是这种操作,也可能不会发现order重复,也不会学到这么多,咋说,祸福相依~~,所以永远不要怕遇到问题。总会有惊喜~~~~)
2.2. redis分布式锁
2.2.1. 过程
@PostMapping(value = "/consumerScanPoster1", produces = "application/json;charset=utf-8")
@ApiOperation("消费者扫描海报码")
@ApiResponses(
@ApiResponse(code = 200, message = "返回结果为json格式,code=200,表示成功,其他为失败,msg 对当前结果的描述,data:查询结果数据 ")
)
@Transactional
public ResponseBean<Object> consumerScanPoster1() {
String rposterkey = "";
String openid = "";
try {
openid = RandomUtil.randomNumbers(10);
String userType = "1";
String posterId = "66809";
String posterQrcode = "JML17poster546488393140383744";
String prizeName = "气士系列首尝活动";
if (!StrUtil.isAllNotBlank(openid, userType,posterId,posterQrcode, prizeName)) {
return new ResponseBean<>("500", "请重新登录", null);
}
//可领取,但需要注意高并发时未领取不能小于0,微信时单点登录,不需要锁人
//String rsourkey = JmlRedisKeysConstant.LOCK_USER.concat(openid);
//mybitis一级缓存,锁提前
rposterkey = JmlRedisKeysConstant.LOCK_POSTER_CONSUMER.concat(posterId);
Boolean rposterres = redisUtils.redLock(rposterkey,consumerScanPosterRLock,rkeyTime);
while (!rposterres) {
Thread.sleep(sleepTime);
rposterres = redisUtils.redLock(rposterkey,consumerScanPosterRLock,rkeyTime);
}
logger.info("1进入分布式锁{}",openid);
//获取海报码相关信息
JmlPcPosteractivity poster = iJmlPcPosteractivityService.getOne(new QueryWrapper<JmlPcPosteractivity>().eq("poster_qrcode", posterQrcode));
if (poster == null) {
logger.info("该海报码不存在,请核对后再试");
return new ResponseBean<>("200", "扫码成功", Common.getDataMap("201", "亲,海报码不存在!", "亲,海报码不存在!"));
}
logger.info("2进入分布式锁{}",poster.getQrcodeUsedNum());
if (poster.getQrcodeStatus() != 3) {
return new ResponseBean<>("200", "扫码成功", Common.getDataMap("202", "该派发码仅限门店参加,请绑定门店后重试", "该海报码未绑定"));
}
LocalDateTime now = LocalDateTime.now();
if (poster.getStartTime().compareTo(now) > 0) {
return new ResponseBean<>("200", "扫码成功", Common.getDataMap("203", "亲,活动未开始!", "海报活动未开始"));
}
if (poster.getEndTime().compareTo(now) < 0) {
return new ResponseBean<>("200", "扫码成功", Common.getDataMap("204", "亲,活动已结束!", "海报活动已结束"));
}
if (poster.getQrcodeUnusedNum() <= 0) {
logger.info("初次检验,奖品已领取完");
return new ResponseBean<>("200", "扫码成功", Common.getDataMap("205", "您来晚了,饮品已发完!", "您来晚了,饮品已发完!"));
}
// JmlMpWechatuser u = iJmlMpWechatuserService.getOne(new QueryWrapper<JmlMpWechatuser>().eq("open_id", openid));
// if (u == null) {
// return new ResponseBean<>("500", "请重新登录", null);
// }
// if (!(u.getType() == 0 || u.getType() == 1)) {
// return new ResponseBean<>("200", "扫码成功", Common.getDataMap("206", "该派发码仅限消费者参加,请核对后重试", "身份异常"));
// }
QueryWrapper<JmlMpPosterflowing> pfq = new QueryWrapper<>();
pfq.eq("user_openid", openid);
pfq.eq("get_prize", poster.getPrizeId());
pfq.eq("poster_shop", poster.getShopId());
List<JmlMpPosterflowing> pf = iJmlMpPosterflowingService.list(pfq);
if (pf != null && pf.size() > 0) {
return new ResponseBean<>("200", "扫码成功", Common.getDataMap("207", "您已经领取过了,不能重复领取!", "您已经领取过了,不能重复领取!"));
}
// JmlPcPosteractivity posterNew = iJmlPcPosteractivityService.getOne(new QueryWrapper<JmlPcPosteractivity>().eq("poster_qrcode", posterQrcode));
// if (posterNew.getQrcodeUnusedNum() <= 0) {
// logger.info("二次检验,奖品已领取完");
// return new ResponseBean<>("200", "扫码成功", Common.getDataMap("205", "您来晚了,饮品已发完!", "您来晚了,饮品已发完"));
// }
UpdateWrapper<JmlPcPosteractivity> upPoster = new UpdateWrapper<>();
upPoster.setSql("qrcode_used_num = qrcode_used_num + 1");
upPoster.setSql("qrcode_unused_num = qrcode_unused_num - 1");
upPoster.set("update_time",LocalDateTime.now());
upPoster.eq("id", posterId);
upPoster.gt("qrcode_unused_num",0);
Boolean r = iJmlPcPosteractivityService.update(upPoster);
if(!r){
logger.info("库存不足");
throw new Exception();
}
JmlMpPosterflowing posterflowing = new JmlMpPosterflowing();
posterflowing.setUserOpenid(openid);
posterflowing.setUserType(Integer.parseInt(userType));
posterflowing.setGetTime(LocalDateTime.now());
posterflowing.setEndTime(poster.getEndTime());
posterflowing.setPosterId(Long.parseLong(posterId));
posterflowing.setPosterCode(posterQrcode);
posterflowing.setPosterKeepopenid(poster.getKeepOpenid());
posterflowing.setPosterShop(poster.getShopId());
posterflowing.setGetOrder(poster.getQrcodeUsedNum() + 1);
posterflowing.setGetPrize(poster.getPrizeId());
posterflowing.setGetNumber(poster.getPrizeRule());
posterflowing.setAwardRule(poster.getAwardRule());
posterflowing.setConvertStatus(0);
iJmlMpPosterflowingService.save(posterflowing);
JSONObject resp = new JSONObject();
resp.put("logid",posterflowing.getId());
resp.put("userOpenid", openid);
resp.put("keepOpenid", poster.getKeepOpenid());
resp.put("shopId", poster.getShopId());
resp.put("prizeId", poster.getPrizeId());
resp.put("prizeNum", poster.getPrizeRule());
resp.put("order", poster.getQrcodeUsedNum() + 1);
resp.put("endTime",df.format(poster.getEndTime()));
logger.info("海报奖励领取信息:{}", resp.toString());
return new ResponseBean<>("200", "奖励领取成功", Common.getDataMap("200", "领取成功", resp));
} catch (Exception e) {
logger.info("消费者扫描海报码失败", e);
TransactionAspectSupport.currentTransactionStatus().setRollbackOnly();
return new ResponseBean<>("500","活动太火爆了,请稍后再试","操作失败");
}finally {
logger.info("3进入分布式锁{}",openid);
redisUtils.del(rposterkey);
}
}
更新了代码一的三个部分:优化redis分布式锁;一个sqlsession中避免出现用一个sql;停止java计算使用mysql计算。
最终结果:
useUnm == count(flow)
但是仍有少量的order重复
2.2.2. 结论
2.2.2.1. setNX
首先看最新的分布式锁:
public Boolean redLock(String key,Object value, Long time) {
try {
if(time <= 0){
time = 30L;
}
Boolean res = redisTemplate.opsForValue().setIfAbsent(key,value,time,TimeUnit.SECONDS);
return res == null ? false : res;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
//最初锁的缺陷是如果同时到这一步,都会has得到的是false,那么会锁不住,归根结底是因为has没有记忆。
//那么如果能紧接着has的返回值做不同的操作,对这个key进行标识那么便实现了一个锁的功效。
//比如has之后为true,则插入一个value进行再返回true;has之后为false则直接返回false,这种便有了记忆。
//但是,必须保证上述操作是连续的,一旦不连续,便会被并发趁虚而入,与单纯的has没了区别。
//因此用java显然不行,因为没有原子性了,一旦并发毫无意义;所以只要保证以上的操作是原子性就可以!
//经过核查,以上理念就是redis分布式锁的理念,无论是redission还是redis本身的命令,都是如上;前者利用lua脚本,后者redis自己操作,总之保证原子性就是锁了。
//redisson的优势是 watch dog,可以无限延长key的过期时间,setNX的优势是可以自定义value的值
//此处使用了redis自带的锁: xx和nx
NX – Only set the key if it does not already exist.
XX – Only set the key if it already exist.
2.2.2.2. 避免相同sql
避免同一个sqlsession中出现同样的sql语句,将 poster和posterNew对象合并,然后将锁的位置提前。
之前考虑的是,加锁之后分布式就变成了串行,如果能在加锁之前处理一些请求,那就做到了安全的同时性能最高。之所以出现了poster和posterNew就是因为考虑到了数据库的前后更改,先用poster过滤一些请求,然后加锁,进入锁以后再用posterNew进行处理, 但是事与愿违,受限于mybitis的一级缓存无法这样使用。
2.2.2.3. mysql计算
使用mysql计算,禁止使用java计算。
upPoster.setSql("qrcode_used_num = qrcode_used_num + 1");
upPoster.setSql("qrcode_unused_num = qrcode_unused_num - 1");
2.2.2.4. mysql处理延迟
分布式锁肯定是生效了,因为重复的order很少了,但是很奇怪,高并发时还是会有重复的order,虽然几率不高,此时离成功就只有最后一步了,要么程序发生了并发,要么数据库发生了并发。
前者理论极低,因为setNx是公认的分布式锁。
后者概率稍大,数据库默认的为可重复读隔离级别,会产生幻读,虽然按理说幻读不会导致该问题,但是只要不是串行化隔离级别,就可能数据库同时处理commit,即java已经提交了,但是数据库处理数据时发生了延迟,导致先处理了第二个提交的事务后处理了第一个提交的事务。
所以解决起来只有两种方案
1, 修改隔离级别为串行化
2, for update,表锁(这种方案是刚知道的,很好用,作用就是锁行/表)
肯定是不能改隔离级别,串行化对性能影响太大了。
2.3. for update
2.3.1. 过程
显然是使用 for update,因为这样只涉及到一个表。串行化是整个mysql级别的影响。
@PostMapping(value = "/consumerScanPoster1", produces = "application/json;charset=utf-8")
@ApiOperation("消费者扫描海报码")
@ApiResponses(
@ApiResponse(code = 200, message = "返回结果为json格式,code=200,表示成功,其他为失败,msg 对当前结果的描述,data:查询结果数据 ")
)
@Transactional
public ResponseBean<Object> consumerScanPoster1() {
String rposterkey = "";
String openid = "";
try {
// HttpSession session = getSession();
// String openid = getValueFromSession(session, JmlConstant.SeesionKey.OPEN_ID);
// String userType = getValueFromSession(session, JmlConstant.SeesionKey.TYPE);
// String posterId = getValueFromSession(session,JmlConstant.SeesionKey.POSTER_ID);
// String posterQrcode = getValueFromSession(session, JmlConstant.SeesionKey.POSTER_QRCODE);
// String prizeName = getValueFromSession(session, JmlConstant.SeesionKey.PRIZE_NAME);
openid = RandomUtil.randomNumbers(10);
String userType = "1";
String posterId = "66809";
String posterQrcode = "JML17poster546488393140383744";
String prizeName = "气士系列首尝活动";
if (!StrUtil.isAllNotBlank(openid, userType,posterId,posterQrcode, prizeName)) {
return new ResponseBean<>("500", "请重新登录", null);
}
//可领取,但需要注意高并发时未领取不能小于0,微信时单点登录,不需要锁人
//String rsourkey = JmlRedisKeysConstant.LOCK_USER.concat(openid);
//mybitis一级缓存,锁提前
rposterkey = JmlRedisKeysConstant.LOCK_POSTER_CONSUMER.concat(posterId);
Boolean rposterres = redisUtils.redLock(rposterkey,consumerScanPosterRLock,rkeyTime);
while (!rposterres) {
Thread.sleep(sleepTime);
rposterres = redisUtils.redLock(rposterkey,consumerScanPosterRLock,rkeyTime);
}
logger.info("1进入分布式锁{}",openid);
//获取海报码相关信息
JmlPcPosteractivity poster = iJmlPcPosteractivityService.getOne(new QueryWrapper<JmlPcPosteractivity>().eq("poster_qrcode", posterQrcode).last("for update"));
if (poster == null) {
logger.info("该海报码不存在,请核对后再试");
return new ResponseBean<>("200", "扫码成功", Common.getDataMap("201", "亲,海报码不存在!", "亲,海报码不存在!"));
}
logger.info("2进入分布式锁{}",poster.getQrcodeUsedNum());
if (poster.getQrcodeStatus() != 3) {
return new ResponseBean<>("200", "扫码成功", Common.getDataMap("202", "该派发码仅限门店参加,请绑定门店后重试", "该海报码未绑定"));
}
LocalDateTime now = LocalDateTime.now();
if (poster.getStartTime().compareTo(now) > 0) {
return new ResponseBean<>("200", "扫码成功", Common.getDataMap("203", "亲,活动未开始!", "海报活动未开始"));
}
if (poster.getEndTime().compareTo(now) < 0) {
return new ResponseBean<>("200", "扫码成功", Common.getDataMap("204", "亲,活动已结束!", "海报活动已结束"));
}
if (poster.getQrcodeUnusedNum() <= 0) {
logger.info("初次检验,奖品已领取完");
return new ResponseBean<>("200", "扫码成功", Common.getDataMap("205", "您来晚了,饮品已发完!", "您来晚了,饮品已发完!"));
}
// JmlMpWechatuser u = iJmlMpWechatuserService.getOne(new QueryWrapper<JmlMpWechatuser>().eq("open_id", openid));
// if (u == null) {
// return new ResponseBean<>("500", "请重新登录", null);
// }
// if (!(u.getType() == 0 || u.getType() == 1)) {
// return new ResponseBean<>("200", "扫码成功", Common.getDataMap("206", "该派发码仅限消费者参加,请核对后重试", "身份异常"));
// }
QueryWrapper<JmlMpPosterflowing> pfq = new QueryWrapper<>();
pfq.eq("user_openid", openid);
pfq.eq("get_prize", poster.getPrizeId());
pfq.eq("poster_shop", poster.getShopId());
List<JmlMpPosterflowing> pf = iJmlMpPosterflowingService.list(pfq);
if (pf != null && pf.size() > 0) {
return new ResponseBean<>("200", "扫码成功", Common.getDataMap("207", "您已经领取过了,不能重复领取!", "您已经领取过了,不能重复领取!"));
}
// JmlPcPosteractivity posterNew = iJmlPcPosteractivityService.getOne(new QueryWrapper<JmlPcPosteractivity>().eq("poster_qrcode", posterQrcode));
// if (posterNew.getQrcodeUnusedNum() <= 0) {
// logger.info("二次检验,奖品已领取完");
// return new ResponseBean<>("200", "扫码成功", Common.getDataMap("205", "您来晚了,饮品已发完!", "您来晚了,饮品已发完"));
// }
UpdateWrapper<JmlPcPosteractivity> upPoster = new UpdateWrapper<>();
upPoster.setSql("qrcode_used_num = qrcode_used_num + 1");
upPoster.setSql("qrcode_unused_num = qrcode_unused_num - 1");
upPoster.set("update_time",LocalDateTime.now());
upPoster.eq("id", posterId);
upPoster.gt("qrcode_unused_num",0);
Boolean r = iJmlPcPosteractivityService.update(upPoster);
if(!r){
logger.info("库存不足");
throw new Exception();
}
JmlMpPosterflowing posterflowing = new JmlMpPosterflowing();
posterflowing.setUserOpenid(openid);
posterflowing.setUserType(Integer.parseInt(userType));
posterflowing.setGetTime(LocalDateTime.now());
posterflowing.setEndTime(poster.getEndTime());
posterflowing.setPosterId(Long.parseLong(posterId));
posterflowing.setPosterCode(posterQrcode);
posterflowing.setPosterKeepopenid(poster.getKeepOpenid());
posterflowing.setPosterShop(poster.getShopId());
posterflowing.setGetOrder(poster.getQrcodeUsedNum() + 1);
posterflowing.setGetPrize(poster.getPrizeId());
posterflowing.setGetNumber(poster.getPrizeRule());
posterflowing.setAwardRule(poster.getAwardRule());
posterflowing.setConvertStatus(0);
iJmlMpPosterflowingService.save(posterflowing);
JSONObject resp = new JSONObject();
resp.put("logid",posterflowing.getId());
resp.put("userOpenid", openid);
resp.put("keepOpenid", poster.getKeepOpenid());
resp.put("shopId", poster.getShopId());
resp.put("prizeId", poster.getPrizeId());
resp.put("prizeNum", poster.getPrizeRule());
resp.put("order", poster.getQrcodeUsedNum() + 1);
resp.put("endTime",df.format(poster.getEndTime()));
logger.info("海报奖励领取信息:{}", resp.toString());
return new ResponseBean<>("200", "奖励领取成功", Common.getDataMap("200", "领取成功", resp));
} catch (Exception e) {
logger.info("消费者扫描海报码失败", e);
TransactionAspectSupport.currentTransactionStatus().setRollbackOnly();
return new ResponseBean<>("500","活动太火爆了,请稍后再试","操作失败");
}finally {
logger.info("3进入分布式锁{}",openid);
redisUtils.del(rposterkey);
}
}
只需修改一行代码:.last(“for update”)
JmlPcPosteractivity poster = iJmlPcPosteractivityService.getOne(new QueryWrapper<JmlPcPosteractivity>().eq("poster_qrcode", posterQrcode).last("for update"));
2.3.2. 结论
此时,大功告成。order再也没有重复的了。
最后再说一句:
虽然依赖mysql也能做到满足需求,但是不依赖reids,只能是牺牲时间(性能)换取数据正确。
最好的方案就是使用redis,也就是说做成秒杀那种架构,后续可以进行优化。
根本目的就是如何在性能最高的情况下还能保证数据正确,redis无意就是最快的选择(基于内存)。
3. 拓展
3.1. mysql事务控制
有人跟我说,@Transactional这个注解只能写在service层,并且我查了很多资料都这么说,在此澄清,springboot中@Transactional注解可以放在任何地方,作用就是事务管理。
但是需要注意的是,@Transactional只涉及mysql的事务管理,底层就是jdbc。使用该注解再加@EnableTransactionManagement注解,便可以方便的额为一个方法(类)开发事务。
使用begin或者start transcation,配套的提交语句是commit,回滚语句为rollback
3.1.1. 过程
-
代码一
public ResponseBean<Object> consumerScanPoster2 () { String rposterkey = ""; String openid = ""; try{ openid = RandomUtil.randomNumbers(10); String userType = "1"; String posterId = "66809"; String posterQrcode = "JML17poster546488393140383744"; String prizeName = "气士系列首尝活动"; //mybitis一级缓存,锁提前 rposterkey = JmlRedisKeysConstant.LOCK_POSTER_CONSUMER.concat(posterId); Boolean rposterres = redisUtils.redLock(rposterkey,consumerScanPosterRLock,rkeyTime); while (!rposterres) { Thread.sleep(sleepTime); rposterres = redisUtils.redLock(rposterkey,consumerScanPosterRLock,rkeyTime); } logger.info("1进入分布式锁{}",openid); //获取海报码相关信息 JmlPcPosteractivity poster = iJmlPcPosteractivityService.getOne(new QueryWrapper<JmlPcPosteractivity>().eq("poster_qrcode", posterQrcode)); UpdateWrapper<JmlPcPosteractivity> upPoster = new UpdateWrapper<>(); upPoster.setSql("qrcode_used_num = qrcode_used_num + 1"); upPoster.setSql("qrcode_unused_num = qrcode_unused_num - 1"); upPoster.set("update_time",LocalDateTime.now()); upPoster.eq("id", posterId); upPoster.gt("qrcode_unused_num",0); Thread.sleep(5000); Boolean r = iJmlPcPosteractivityService.update(upPoster); if(!r){ logger.info("库存不足"); System.out.println(2/0); } //等待 Thread.sleep(5000); JmlMpPosterflowing posterflowing = new JmlMpPosterflowing(); posterflowing.setUserOpenid(openid); posterflowing.setUserType(Integer.parseInt(userType)); posterflowing.setGetTime(LocalDateTime.now()); posterflowing.setEndTime(poster.getEndTime()); posterflowing.setPosterId(Long.parseLong(posterId)); posterflowing.setPosterCode(posterQrcode); posterflowing.setPosterKeepopenid(poster.getKeepOpenid()); posterflowing.setPosterShop(poster.getShopId()); posterflowing.setGetOrder(poster.getQrcodeUsedNum() + 1); posterflowing.setGetPrize(poster.getPrizeId()); posterflowing.setGetNumber(poster.getPrizeRule()); posterflowing.setAwardRule(poster.getAwardRule()); posterflowing.setConvertStatus(0); iJmlMpPosterflowingService.save(posterflowing); Thread.sleep(5000); JSONObject resp = new JSONObject(); resp.put("logid",posterflowing.getId()); resp.put("userOpenid", openid); resp.put("keepOpenid", poster.getKeepOpenid()); resp.put("shopId", poster.getShopId()); resp.put("prizeId", poster.getPrizeId()); resp.put("prizeNum", poster.getPrizeRule()); resp.put("order", poster.getQrcodeUsedNum() + 1); resp.put("endTime",df.format(poster.getEndTime())); if(2==2){ logger.info("抛异常"); System.out.println(2/0); } logger.info("海报奖励领取信息:{}", resp.toString()); return new ResponseBean<>("200", "奖励领取成功", Common.getDataMap("200", "领取成功", resp)); } catch (Exception e) { logger.info("消费者扫描海报码失败", e); return new ResponseBean<>("500","活动太火爆了,请稍后再试","操作失败"); }finally { logger.info("3进入分布式锁{}",openid); redisUtils.del(rposterkey); } } //以上代码涉及两个表中的两个更新语句,两个语句依次执行,一个5s时更改了,一个10s时更改了,15s时系统返回。 //不可能是事务,因为连原子性都不符合。 -
代码二
@Transactional public ResponseBean<Object> consumerScanPoster2 () { String rposterkey = ""; String openid = ""; try{ openid = RandomUtil.randomNumbers(10); String userType = "1"; String posterId = "66809"; String posterQrcode = "JML17poster546488393140383744"; String prizeName = "气士系列首尝活动"; //mybitis一级缓存,锁提前 rposterkey = JmlRedisKeysConstant.LOCK_POSTER_CONSUMER.concat(posterId); Boolean rposterres = redisUtils.redLock(rposterkey,consumerScanPosterRLock,rkeyTime); while (!rposterres) { Thread.sleep(sleepTime); rposterres = redisUtils.redLock(rposterkey,consumerScanPosterRLock,rkeyTime); } logger.info("1进入分布式锁{}",openid); //获取海报码相关信息 JmlPcPosteractivity poster = iJmlPcPosteractivityService.getOne(new QueryWrapper<JmlPcPosteractivity>().eq("poster_qrcode", posterQrcode)); UpdateWrapper<JmlPcPosteractivity> upPoster = new UpdateWrapper<>(); upPoster.setSql("qrcode_used_num = qrcode_used_num + 1"); upPoster.setSql("qrcode_unused_num = qrcode_unused_num - 1"); upPoster.set("update_time",LocalDateTime.now()); upPoster.eq("id", posterId); upPoster.gt("qrcode_unused_num",0); Boolean r = iJmlPcPosteractivityService.update(upPoster); if(!r){ logger.info("库存不足"); System.out.println(2/0); } //等待 Thread.sleep(5000); JmlMpPosterflowing posterflowing = new JmlMpPosterflowing(); posterflowing.setUserOpenid(openid); posterflowing.setUserType(Integer.parseInt(userType)); posterflowing.setGetTime(LocalDateTime.now()); posterflowing.setEndTime(poster.getEndTime()); posterflowing.setPosterId(Long.parseLong(posterId)); posterflowing.setPosterCode(posterQrcode); posterflowing.setPosterKeepopenid(poster.getKeepOpenid()); posterflowing.setPosterShop(poster.getShopId()); posterflowing.setGetOrder(poster.getQrcodeUsedNum() + 1); posterflowing.setGetPrize(poster.getPrizeId()); posterflowing.setGetNumber(poster.getPrizeRule()); posterflowing.setAwardRule(poster.getAwardRule()); posterflowing.setConvertStatus(0); iJmlMpPosterflowingService.save(posterflowing); Thread.sleep(5000); JSONObject resp = new JSONObject(); resp.put("logid",posterflowing.getId()); resp.put("userOpenid", openid); resp.put("keepOpenid", poster.getKeepOpenid()); resp.put("shopId", poster.getShopId()); resp.put("prizeId", poster.getPrizeId()); resp.put("prizeNum", poster.getPrizeRule()); resp.put("order", poster.getQrcodeUsedNum() + 1); resp.put("endTime",df.format(poster.getEndTime())); if(2==2){ logger.info("抛异常"); System.out.println(2/0); } logger.info("海报奖励领取信息:{}", resp.toString()); return new ResponseBean<>("200", "奖励领取成功", Common.getDataMap("200", "领取成功", resp)); } catch (Exception e) { logger.info("消费者扫描海报码失败", e); return new ResponseBean<>("500","活动太火爆了,请稍后再试","操作失败"); }finally { logger.info("3进入分布式锁{}",openid); redisUtils.del(rposterkey); } } //相比于代码一只增加了一个注解,两个语句在15s后随着返回值同时更新。有异常,但未回滚。 //因此是事务,但遇见异常之后未回滚。 -
代码三
@Transactional public ResponseBean<Object> consumerScanPoster2 () { String rposterkey = ""; String openid = ""; try{ openid = RandomUtil.randomNumbers(10); String userType = "1"; String posterId = "66809"; String posterQrcode = "JML17poster546488393140383744"; String prizeName = "气士系列首尝活动"; //mybitis一级缓存,锁提前 rposterkey = JmlRedisKeysConstant.LOCK_POSTER_CONSUMER.concat(posterId); Boolean rposterres = redisUtils.redLock(rposterkey,consumerScanPosterRLock,rkeyTime); while (!rposterres) { Thread.sleep(sleepTime); rposterres = redisUtils.redLock(rposterkey,consumerScanPosterRLock,rkeyTime); } logger.info("1进入分布式锁{}",openid); //获取海报码相关信息 JmlPcPosteractivity poster = iJmlPcPosteractivityService.getOne(new QueryWrapper<JmlPcPosteractivity>().eq("poster_qrcode", posterQrcode)); UpdateWrapper<JmlPcPosteractivity> upPoster = new UpdateWrapper<>(); upPoster.setSql("qrcode_used_num = qrcode_used_num + 1"); upPoster.setSql("qrcode_unused_num = qrcode_unused_num - 1"); upPoster.set("update_time",LocalDateTime.now()); upPoster.eq("id", posterId); upPoster.gt("qrcode_unused_num",0); Boolean r = iJmlPcPosteractivityService.update(upPoster); if(!r){ logger.info("库存不足"); System.out.println(2/0); } //等待 Thread.sleep(5000); JmlMpPosterflowing posterflowing = new JmlMpPosterflowing(); posterflowing.setUserOpenid(openid); posterflowing.setUserType(Integer.parseInt(userType)); posterflowing.setGetTime(LocalDateTime.now()); posterflowing.setEndTime(poster.getEndTime()); posterflowing.setPosterId(Long.parseLong(posterId)); posterflowing.setPosterCode(posterQrcode); posterflowing.setPosterKeepopenid(poster.getKeepOpenid()); posterflowing.setPosterShop(poster.getShopId()); posterflowing.setGetOrder(poster.getQrcodeUsedNum() + 1); posterflowing.setGetPrize(poster.getPrizeId()); posterflowing.setGetNumber(poster.getPrizeRule()); posterflowing.setAwardRule(poster.getAwardRule()); posterflowing.setConvertStatus(0); iJmlMpPosterflowingService.save(posterflowing); Thread.sleep(5000); JSONObject resp = new JSONObject(); resp.put("logid",posterflowing.getId()); resp.put("userOpenid", openid); resp.put("keepOpenid", poster.getKeepOpenid()); resp.put("shopId", poster.getShopId()); resp.put("prizeId", poster.getPrizeId()); resp.put("prizeNum", poster.getPrizeRule()); resp.put("order", poster.getQrcodeUsedNum() + 1); resp.put("endTime",df.format(poster.getEndTime())); if(2==2){ logger.info("抛异常"); System.out.println(2/0); } logger.info("海报奖励领取信息:{}", resp.toString()); return new ResponseBean<>("200", "奖励领取成功", Common.getDataMap("200", "领取成功", resp)); } catch (Exception e) { logger.info("消费者扫描海报码失败", e); TransactionAspectSupport.currentTransactionStatus().setRollbackOnly(); return new ResponseBean<>("500","活动太火爆了,请稍后再试","操作失败"); }finally { logger.info("3进入分布式锁{}",openid); redisUtils.del(rposterkey); } } //相比于代码二,只是在catch中加上了TransactionAspectSupport.currentTransactionStatus().setRollbackOnly(); //数据库两个表一直到15s后return返回值没有任何改变,也就是说数据进行了回滚。 //是事务,且随着异常出现了回滚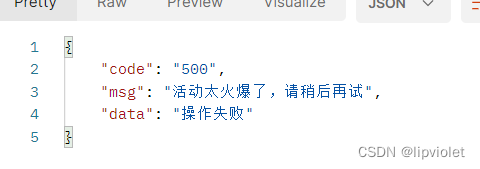
-
代码四
public ResponseBean<Object> consumerScanPoster2 () { String rposterkey = ""; String openid = ""; try{ openid = RandomUtil.randomNumbers(10); String userType = "1"; String posterId = "66809"; String posterQrcode = "JML17poster546488393140383744"; String prizeName = "气士系列首尝活动"; //mybitis一级缓存,锁提前 rposterkey = JmlRedisKeysConstant.LOCK_POSTER_CONSUMER.concat(posterId); Boolean rposterres = redisUtils.redLock(rposterkey,consumerScanPosterRLock,rkeyTime); while (!rposterres) { Thread.sleep(sleepTime); rposterres = redisUtils.redLock(rposterkey,consumerScanPosterRLock,rkeyTime); } logger.info("1进入分布式锁{}",openid); //获取海报码相关信息 JmlPcPosteractivity poster = iJmlPcPosteractivityService.getOne(new QueryWrapper<JmlPcPosteractivity>().eq("poster_qrcode", posterQrcode)); UpdateWrapper<JmlPcPosteractivity> upPoster = new UpdateWrapper<>(); upPoster.setSql("qrcode_used_num = qrcode_used_num + 1"); upPoster.setSql("qrcode_unused_num = qrcode_unused_num - 1"); upPoster.set("update_time",LocalDateTime.now()); upPoster.eq("id", posterId); upPoster.gt("qrcode_unused_num",0); Boolean r = iJmlPcPosteractivityService.update(upPoster); if(!r){ logger.info("库存不足"); System.out.println(2/0); } //等待 Thread.sleep(5000); JmlMpPosterflowing posterflowing = new JmlMpPosterflowing(); posterflowing.setUserOpenid(openid); posterflowing.setUserType(Integer.parseInt(userType)); posterflowing.setGetTime(LocalDateTime.now()); posterflowing.setEndTime(poster.getEndTime()); posterflowing.setPosterId(Long.parseLong(posterId)); posterflowing.setPosterCode(posterQrcode); posterflowing.setPosterKeepopenid(poster.getKeepOpenid()); posterflowing.setPosterShop(poster.getShopId()); posterflowing.setGetOrder(poster.getQrcodeUsedNum() + 1); posterflowing.setGetPrize(poster.getPrizeId()); posterflowing.setGetNumber(poster.getPrizeRule()); posterflowing.setAwardRule(poster.getAwardRule()); posterflowing.setConvertStatus(0); iJmlMpPosterflowingService.save(posterflowing); Thread.sleep(5000); JSONObject resp = new JSONObject(); resp.put("logid",posterflowing.getId()); resp.put("userOpenid", openid); resp.put("keepOpenid", poster.getKeepOpenid()); resp.put("shopId", poster.getShopId()); resp.put("prizeId", poster.getPrizeId()); resp.put("prizeNum", poster.getPrizeRule()); resp.put("order", poster.getQrcodeUsedNum() + 1); resp.put("endTime",df.format(poster.getEndTime())); if(2==2){ logger.info("抛异常"); System.out.println(2/0); } logger.info("海报奖励领取信息:{}", resp.toString()); return new ResponseBean<>("200", "奖励领取成功", Common.getDataMap("200", "领取成功", resp)); } catch (Exception e) { logger.info("消费者扫描海报码失败", e); TransactionAspectSupport.currentTransactionStatus().setRollbackOnly(); return new ResponseBean<>("500","活动太火爆了,请稍后再试","操作失败"); }finally { logger.info("3进入分布式锁{}",openid); redisUtils.del(rposterkey); } } //最后详细解释一下:TransactionAspectSupport.currentTransactionStatus().setRollbackOnly(); //该注解的作用就是查询方法体内的事务,进行回滚,只有方法内存在事务时该注解才有意义,否则会报错。 //以上代码中,数据库依次更改,有异常也未回滚,且报错。
也就是说,只用TransactionAspectSupport.currentTransactionStatus().setRollbackOnly();
毫无意义!!!

该注解就是首先检查事务信息,而后回滚。无事务即抛异常。

3.1.2. 结论
3.1.2.1. 如何开启事务
springboot中的事务控制:
- 开启事务:首先在启动类上标注,标示spring自动管理事务,该注解会自动开启数据库的事务提交
@EnableTransactionManagement - 标注事务:标注在类或者方法上,标识类中的所有方法或者该方法开启事务管理。
@Transactional - 手动回滚:@Transactional只能处理运行时异常回滚,遇到try/catch这种自己吞掉异常,无法自动回滚,此时就需要手动回滚。 该注解只能配合事务使用,若无事务则报错 TransactionAspectSupport.currentTransactionStatus().setRollbackOnly();
3.1.2.2. @Transactional注解使用位置
@Transactional 是声明式事务管理。
package org.springframework.transaction.annotation;
该注解可以出现在项目的任何层级,并不局限于所谓的service层,同样可以用在contoller层,标注在类中则代表该类中的任何方法都是事务控制,标注在某个方法上则代表该方法是事务控制
3.1.2.3. 配置文件
基于 tx 和 aop 名字空间的 xml 配置文件
// 基本配置
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context"
xmlns:mvc="http://www.springframework.org/schema/mvc" xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:task="http://www.springframework.org/schema/task" xmlns:jms="http://www.springframework.org/schema/jms"
xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="http://www.springframework.org/schema/mvc http://www.springframework.org/schema/mvc/spring-mvc-4.1.xsd
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.1.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-4.1.xsd
http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-4.1.xsd
http://www.springframework.org/schema/task http://www.springframework.org/schema/task/spring-task-4.1.xsd
http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-4.1.xsd
http://www.springframework.org/schema/jms http://www.springframework.org/schema/jms/spring-jms-4.1.xsd">
<bean name="transactionManager"
class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="shardingDataSource"></property>
</bean>
<tx:annotation-driven transaction-manager="transactionManager" proxy-target-class="true" />
// MyBatis 自动参与到 spring 事务管理中,无需额外配置,
只要 org.mybatis.spring.SqlSessionFactoryBean 引用的数据源与
DataSourceTransactionManager 引用的数据源一致即可,否则事务管理会不起作用。
// <annotation-driven> 标签的声明,
是在 Spring 内部启用 @Transactional 来进行事务管理,使用 @Transactional 前需要配置。
在springboot项目中基本不需要上述配置,只需标注注解则可以进行事务管理。
3.1.2.4. @Transactional原理
- 首先它是基于Spring的动态代理机制,Spring进行管理连接类
- 它的本质还是使用了数据库本身的事务管理机制,也就是jdbc的事务管理
@Transactional 实现原理:
1) 事务开始时,通过AOP机制,生成一个代理connection对象,
并将其放入 DataSource 实例的某个与 DataSourceTransactionManager 相关的某处容器中。
在接下来的整个事务中,客户代码都应该使用该 connection 连接数据库,
执行所有数据库命令。
不使用该 connection 连接数据库执行的数据库命令,在本事务回滚的时候无法回滚
DataSource 与 TransactionManager 配置的数据源不同时,事务管理无效
2) 事务结束时,提交在第1步骤中得到的代理 connection 对象上执行的数据库命令,
然后关闭该代理 connection 对象。
3.1.2.5. 声明式事务的管理实现本质
@Transactional 是一种声明式事务,换言之,@Transactional 只是声明式事务中的一种,声明式事务的本质如下。
mysql的事务控制有两种方式实现:
- 开启数据库自动提交的情况下显示调用,通过start transaction | begin 开始事务,通过commit | rollback 结束事务。
- 关闭数据库中自动提交 autocommit set autocommit = 0,通过手动提交或执行回滚操作来结束事务(MySQL 默认开启自动提交)。
事务虽说是两种方式,其实本质都一样,那就是将多个命令打包提交,让数据库以原子性行为处理多条命令,且可以回滚。
声明式事务使用的是第二种方式,但是只是在connection期间修改提交方式。Spring 关闭数据库中自动提交:在方法执行前关闭自动提交,方法执行完毕后再开启自动提交
// org.springframework.jdbc.datasource.DataSourceTransactionManager.java 源码实现
// switch to manual commit if necessary. this is very expensive in some jdbc drivers,
// so we don't want to do it unnecessarily (for example if we've explicitly
// configured the connection pool to set it already).
if (con.getautocommit()) {
txobject.setmustrestoreautocommit(true);
if (logger.isdebugenabled()) {
logger.debug("switching jdbc connection [" + con + "] to manual commit");
}
con.setautocommit(false);
}
问题:关闭自动提交后,若事务一直未完成,即未手动执行 commit 或 rollback 时如何处理已经执行过的SQL操作?
C3P0 默认的策略是回滚任何未提交的事务
C3P0 是一个开源的JDBC连接池,它实现了数据源和 JNDI 绑定,支持 JDBC3 规范和 JDBC2 的标准扩展。目前使用它的开源项目有 Hibernate,Spring等
JNDI(Java Naming and Directory Interface,Java命名和目录接口)是SUN公司提供的一种标准的Java命名系统接口,JNDI提供统一的客户端API,通过不同的访问提供者接口JNDI服务供应接口(SPI)的实现,由管理者将JNDI API映射为特定的命名服务和目录系统,使得Java应用程序可以和这些命名服务和目录服务之间进行交互
3.1.2.6. spring 事务特性
spring 所有的事务管理策略类都继承自 org.springframework.transaction.PlatformTransactionManager接口
public interface PlatformTransactionManager {
TransactionStatus getTransaction(TransactionDefinition definition)
throws TransactionException;
void commit(TransactionStatus status) throws TransactionException;
void rollback(TransactionStatus status) throws TransactionException;
}
事务的隔离级别:指若干个并发的事务之间的隔离程度
1. @Transactional(isolation = Isolation.READ_UNCOMMITTED):读取未提交数据(会出现脏读,
不可重复读) 基本不使用
2. @Transactional(isolation = Isolation.READ_COMMITTED):读取已提交数据(会出现不可重复读和幻读)
3. @Transactional(isolation = Isolation.REPEATABLE_READ):可重复读(会出现幻读)
4. @Transactional(isolation = Isolation.SERIALIZABLE):串行化
mysql默认存储引擎为innodb,默认的事务等级为可重复读
事务传播行为:如果在开始当前事务之前,一个事务上下文已经存在,此时有若干选项可以指定一个事务性方法的执行行为
1. TransactionDefinition.PROPAGATION_REQUIRED:
如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。这是默认值。
2. TransactionDefinition.PROPAGATION_REQUIRES_NEW:
创建一个新的事务,如果当前存在事务,则把当前事务挂起。
3. TransactionDefinition.PROPAGATION_SUPPORTS:
如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。
4. TransactionDefinition.PROPAGATION_NOT_SUPPORTED:
以非事务方式运行,如果当前存在事务,则把当前事务挂起。
5. TransactionDefinition.PROPAGATION_NEVER:
以非事务方式运行,如果当前存在事务,则抛出异常。
6. TransactionDefinition.PROPAGATION_MANDATORY:
如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。
7. TransactionDefinition.PROPAGATION_NESTED:
如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;
如果当前没有事务,则该取值等价于TransactionDefinition.PROPAGATION_REQUIRED。
除特殊场景,取默认值即可,目前未用到过取非默认值情况
3.1.2.7. @Transactional属性配置

1. value :主要用来指定不同的事务管理器;
主要用来满足在同一个系统中,存在不同的事务管理器。
比如在Spring中,声明了两种事务管理器txManager1, txManager2.然后,
用户可以根据这个参数来根据需要指定特定的txManager.
2. value 适用场景:在一个系统中,需要访问多个数据源或者多个数据库,
则必然会配置多个事务管理器的
3. REQUIRED_NEW:内部的事务独立运行,在各自的作用域中,可以独立的回滚或者提交;
而外部的事务将不受内部事务的回滚状态影响。
4. ESTED 的事务,基于单一的事务来管理,提供了多个保存点。
这种多个保存点的机制允许内部事务的变更触发外部事务的回滚。
而外部事务在混滚之后,仍能继续进行事务处理,即使部分操作已经被混滚。
由于这个设置基于 JDBC 的保存点,所以只能工作在 JDB C的机制。
5. rollbackFor:让受检查异常回滚;即让本来不应该回滚的进行回滚操作。
6. noRollbackFor:忽略非检查异常;即让本来应该回滚的不进行回滚操作。
3.1.2.8. 嵌套事务
带有事务的方法调用其他带有事务的方法,此时执行的情况取决配置的事务的传播属性
- PROPAGATION_REQUIRED:变成一个事务
- PROPAGATION_REQUIRES_NEW :两个事务互不影响
启动一个新的,不依赖于环境的“内部”事务.这个事务将被完全commited 或rolled back而不依赖于外部事务,它拥有自己的隔离范围,自己的锁等等,当内部事务开始执行时,外部事务将被挂起,内务事务结束时,外部事务将继续执行。 - PROPAGATION_NESTED:相当于一个事务。
如果外部事务commit,嵌套事务也会被commit;如果外部事务roll back,嵌套事务也会被roll back。
开始一个“嵌套的”事务,它是已经存在事务的一个真正的子事务.嵌套事务开始执行时,它将取得一个savepoint.如果这个嵌套事务失败,我们将回滚到此savepoint.嵌套事务是外部事务的一部分,只有外部事务结束后它才会被提交 - 等等情况,依赖于TransactionDefinition的配置
3.1.2.9. spring事务回滚规则
指示spring事务管理器回滚一个事务的指令是在当前事务的上下文内抛出了异常,spring事务管理器会捕捉任何未处理的异常,然后依据规则决定是否回滚抛出异常的事务。
- 默认配置下,spring只有在抛出的异常为运行时unchecked异常时才回滚该事务,也就是抛出的异常为RuntimeException的子类
(Errors也会导致事务回滚),而抛出checked异常则不会导致事务回滚。用spring 事务管理器,由spring来负责数据库的打开,提交,回滚。 - 默认遇到运行期异常(throw new RuntimeException(“注释”);)会回滚,
即遇到不受检查(unchecked)的例外时回滚;而遇到需要捕获的例外(throw new Exception(“注释”);)不会回滚。 - 遇到受检查的例外(就是非运行时抛出的异常,编译器会检查到的异常叫受检查例外或说受检查异常)时,需我们指定方式来让事务回滚要想所有异常
都回滚,要加上@Transactional(rollbackFor={Exception.class,其它异常}).如果让unchecked例外不回滚:@Transactional(notRollbackFor=Run TimeException.class)
3.1.2.10. java异常分类
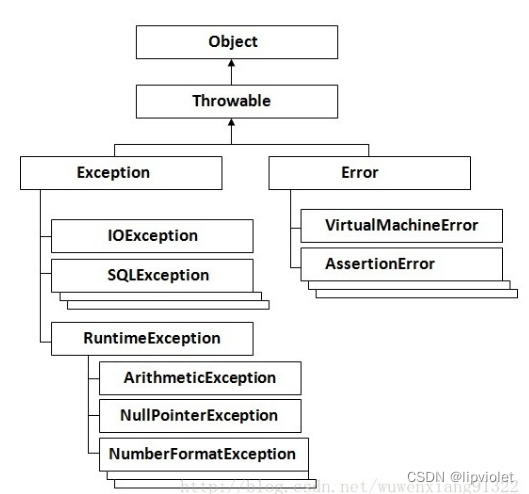
代码分为编译期和运行期:
- 编译期失败有二:语法错误和jar找不到,例如idea的标红。
- 运行期失败有二:Error 和 Exception。
详解一下运行期,Error不常见,例如死锁导致的内存泄露或者内存不足等等。常见的是Exception,也就是常说的异常,Exception分为Checked异常与Unchecked异常。
-
Unchecked异常
Unchecked异常即RuntimeException异常,也就是从RuntimeException派生出子类型,空指针、运算错误等等。代码不需要处理它们的异常也能通过编译,但执行时出现就导致程序失败,代表程序中的潜在bug,类似于编程语言中的 dynamic type checking。如果客户端对出现的异常无能为力,采用unchecked exception。
应使用unchecked exception来处理编程错误:因为unchecked exception不用使客户端代码显式的处理它们,它们自己会在出现的地方挂起程序并打印出异常信息。 充分利用Java API中提供的丰富unchecked exception,如 NullPointerException , IllegalArgumentException和 IllegalStateException等,使用这些标准的异常类而不需亲自创建新的异常类,使代码易于理解并避免过多消耗内存。 -
Checked异常
Checked异常即继承自Exception类是而又不属于RuntimeException类的异常。代码需要处理 API 抛出的 checked exception,要么用 catch 语句,要么直接用 throws 语句抛出去。Checked异常需要从Exception派生出子类型,必须捕获并指定错误处理器handler,否则编译无法通过类似于编程语言中的static type checking。如果客户端可以通过其他的方法恢复异常,那么采用checked exception。
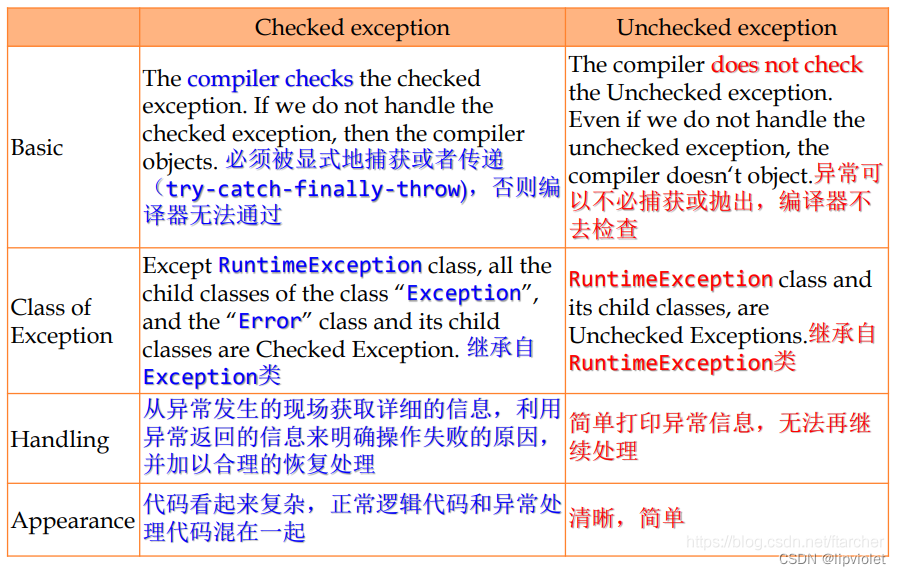
如果不对运行时异常进行处理,那么出现运行时异常之后,要么是线程中止,要么是主程序终止。
如果不想终止,则必须捕获所有的运行时异常,决不让这个处理线程退出。队列里面出现异常数据了,正常的处理应该是把异常数据舍弃,然后记录日志。不应该由于异常数据而影响下面对正常数据的处理。
3.1.2.11. 注意事项
-
@Transactional使用位置为类上方、方法上方
在接口或者接口方法上使用该注解无效,因为这只有在使用基于接口的代理时它才会生效
当作用于类上时,该类的所有public方法将都具有该类型的事务属性,同时,我们也可以在方法级别使用该标注来覆盖类级别的定义。 -
方法的访问权限必须为public
@Transactional 注解应该只被应用到public方法上,这是由Spring AOP的本质决定的。在protected、private 或者默认可见性的方法上使用时将被忽略,也不会抛出任何异常 -
默认情况下,只有来自外部的方法调用才会被AOP代理捕获,也就是,类内部方法调用本类内部的其他方法并不会引起事务行为,即使被调用方法使用@Transactional注解进行修饰
例如一:同一个类中方法,A方法未使用此标签,B使用了,C未使用,A调用B,B调用C;则外部调用A之后,B的事务是不会起作用的
例如二:若是有上层(按照Controller层、Service层、DAO层的顺序)由Action调用Service直接调用,发生异常会发生回滚;若间接调用,Action调用Service中的A方法,A无@Transactional注解,B有,A调用B,B的注解无效 -
事务方法的嵌套调用会产生事务传播。
-
spring 的事务管理是线程安全的
-
父类的声明的@Transactional 会对子类的所有方法进行事务增强;子类覆盖重写父类方式可覆盖其 @Transactional 中的声明配置。
-
类名上方使用 @Transactional,类中方法可通过属性配置来覆盖类上的 @Transactional 配置;
比如:类上配置全局是可读写,可在某个方法上改为只读。
3.1.2.12. 多线程事务管理
- 因为线程不属于spring托管,故线程不能够默认使用spring的事务,也不能获取spring注入的bean,所以在被spring声明式事务管理的方法内开启多线程,多线程内的方法不被事务控制。
-
解决方法
如果方法中调用多线程,方法主题的事务不会传递到线程中,线程中可以单独调用Service接口,接口的实现方法使用@Transactional,保证线程内部的事务即使用异步注解@Async的方法上再加上注解@Transactional,保证新线程调用的方法是有事务管理的
-
原理
Spring中事务信息存储在ThreadLocal变量中,变量是某个线程上进行的事务所特有的(这些变量对于其他线程中发生的事务来讲
是不可见的,无关的,线程隔离的)
所以单线程的情况下,一个事务会在层级式调用的Spring组件之间传播,在@Transactional注解的服务方法会产生一个新的线程的情况下,事务是不会从调用者线程传播到新建线程的
-
3.1.2.13. @Transactional源码分析
先说三种事务失效的场景,即可明了其源码逻辑
- @Transactional注解标注方法的修饰符为非public时,无效
- 在类内部调用调用类内部@Transactional标注的方法时, 无效
- 事务方法内部捕捉了异常,没有抛出新的异常,无效
第一种:
@Transactional也是基于动态代理实现的。在bean初始化过程中,对所有含有@Transactional标注的bean实例创建代理对象。
根据spring创建好一个aop切点BeanFactoryTransactionAttributeSourceAdvisor实例,遍历当前bean的class的方法对象,判断方法上面的注解信息是否包含@Transactional,如果bean任何一个方法包含@Transactional注解信息,那么就是适配这个BeanFactoryTransactionAttributeSourceAdvisor切点,则需要创建代理对象,然后代理逻辑为我们管理事务开闭逻辑。
然而若@Transactional标注的方法如果修饰符不是public,那么就默认方法的@Transactional信息为空,那么将不会对bean进行代理对象创建或者不会对方法进行代理调用象。
第二种
其实还是上述原理,既然事务管理是基于动态代理对象的代理逻辑实现的,那么如果在类内部调用类内部的事务方法,这个调用事务方法的过程并不是通过代理对象来调用的,而是直接通过this对象来调用方法,绕过的代理对象,肯定就是没有代理逻辑了。
第三种
protected Object invokeWithinTransaction(Method method, Class<?> targetClass, final InvocationCallback invocation)
throws Throwable {
// If the transaction attribute is null, the method is non-transactional.
final TransactionAttribute txAttr = getTransactionAttributeSource().getTransactionAttribute(method, targetClass);
final PlatformTransactionManager tm = determineTransactionManager(txAttr);
final String joinpointIdentification = methodIdentification(method, targetClass);
if (txAttr == null || !(tm instanceof CallbackPreferringPlatformTransactionManager)) {
// Standard transaction demarcation with getTransaction and commit/rollback calls.
//开启事务
TransactionInfo txInfo = createTransactionIfNecessary(tm, txAttr, joinpointIdentification);
Object retVal = null;
try {
// This is an around advice: Invoke the next interceptor in the chain.
// This will normally result in a target object being invoked.
//反射调用业务方法
retVal = invocation.proceedWithInvocation();
}
catch (Throwable ex) {
// target invocation exception
//异常时,在catch逻辑中回滚事务
completeTransactionAfterThrowing(txInfo, ex);
throw ex;
}
finally {
cleanupTransactionInfo(txInfo);
}
//提交事务
commitTransactionAfterReturning(txInfo);
return retVal;
}
else {
//....................
}
}
事务方法内部捕捉了异常,没有抛出新的异常,没有异常则自然无法回滚。
3.1.2.14. @Transactional对方法调用的影响
首先说明最重要的一点:方法之间的调用,无论什么层什么层,都是java最基本的封装,jvm转化之后其实都是一个方法,springboot的层是人为的划分,与jvm无关。
所以,无论什么什么注解,什么框架,它都是交给JVM执行,因为看代码一定不能迷路,要记住代码的基准,@Transactional注解也不例外。现在,我们以此为准考虑一下该注解对方法调用的影响

结论:
- A调用B时,无论同类与否,当A有注解时,无论B是否有默认注解,其结果都是一样的,原因就是JVM执行机制,方法之间的调用本质上是整合成一个方法!
- A调用B时,当A无注解,只有B有默认注解时,此时需要根据是否异类判断,因为同类调用时,被动用者的事务会失效!
3.2. 事务的隔离级别
事务的四大特性分别是:原子性、一致性、隔离性、持久性
幻读和不可重复读都是在同一个事务中多次读取了其他事务已经提交的事务的数据导致每次读取的数据不一致,所不同的是不可重复读读取的是同一条数据,而幻读针对的是一批数据整体的统计(比如数据的个数)
-
第一种隔离级别:Read uncommitted(读未提交)
如果一个事务已经开始写数据,则另外一个事务不允许同时进行写操作,但允许其他事务读此行数据,该隔离级别可以通过“排他写锁”,但是不排斥读线程实现。这样就避免了更新丢失,却可能出现脏读,也就是说事务B读取到了事务A未提交的数据解决了更新丢失,但还是可能会出现脏读
-
第二种隔离级别:Read committed(读提交)
如果是一个读事务(线程),则允许其他事务读写,如果是写事务将会禁止其他事务访问该行数据,该隔离级别避免了脏读,但是可能出现不可重复读。事务A事先读取了数据,事务B紧接着更新了数据,并提交了事务,而事务A再次读取该数据时,数据已经发生了改变。解决了更新丢失和脏读问题
-
第三种隔离级别:Repeatable read(可重复读取)
可重复读取是指在一个事务内,多次读同一个数据,在这个事务还没结束时,其他事务不能访问该数据(包括了读写),这样就可以在同一个事务内两次读到的数据是一样的,因此称为是可重复读隔离级别,读取数据的事务将会禁止写事务(但允许读事务),写事务则禁止任何其他事务(包括了读写),这样避免了不可重复读和脏读,但是有时可能会出现幻读。(读取数据的事务)可以通过“共享读镜”和“排他写锁”实现。解决了更新丢失、脏读、不可重复读、但是还会出现幻读
-
第四种隔离级别:Serializable(可序化)
提供严格的事务隔离,它要求事务序列化执行,事务只能一个接着一个地执行,但不能并发执行,如果仅仅通过“行级锁”是无法实现序列化的,必须通过其他机制保证新插入的数据不会被执行查询操作的事务访问到。序列化是最高的事务隔离级别,同时代价也是最高的,性能很低,一般很少使用,在该级别下,事务顺序执行,不仅可以避免脏读、不可重复读,还避免了幻读解决了更新丢失、脏读、不可重复读、幻读(虚读)
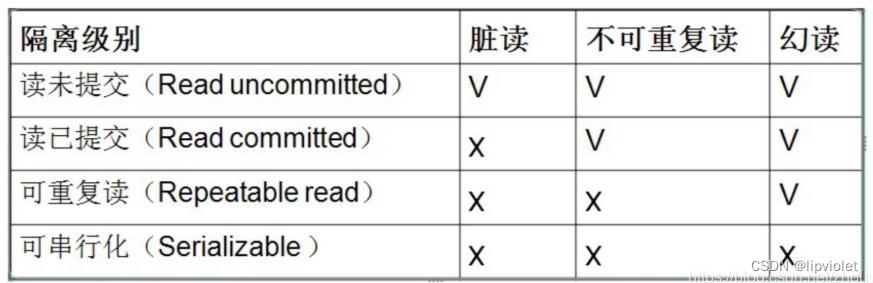
以上四种隔离级别最高的是Serializable级别,最低的是Read uncommitted级别,当然级别越高,执行效率就越低,像Serializeble这样的级别,就是以锁表的方式(类似于Java多线程中的锁)使得其他线程只能在锁外等待,所以平时选用何种隔离级别应该根据实际情况来,在MYSQL数据库中默认的隔离级别是Repeatable read(可重复读)。
在MYSQL数据库中,支持上面四种隔离级别,默认的为Repeatable read(可重复读);而在Oracle数据库中,只支持Serializeble(串行化)级别和Read committed(读已提交)这两种级别,其中默认的为Read committed级别
3.3. java创建多线程的四种方式
-
继承Thread类创建多线程
① 创建一个继承于Thread类的子类。 ② 重写Thread类中的run()方法,在run()方法中实现线程需要完成的功能。 ③ 创建Thread类的子类的对象,并调用这个对象的start()方法,调用start()后会自动启动当前线程,并调用当前线程的run()方法。 class MyThread extends Thread{ @Override public void run() { System.out.println("继承Tread类创建多线程"); } } public class ThreadCreate1 { public static void main(String[] args) { MyThread myThread = new MyThread(); myThread.start(); } } -
实现Runnable接口创建多线程
① 创建一个实现Runnable接口的类。 ② 在这个实现类中实现Runnable接口的run()方法。 ③ 创建这个实现类的对象,并将这个对象作为参数传入Thread类的构造器中,然后创建Tread类的对象,调用Tread类对象的start()方法。 class MyRunnable implements Runnable{ @Override public void run() { System.out.println("实现Runnable接口创建多线程"); } } public class ThreadCreate2 { public static void main(String[] args) { MyRunnable myRunnable = new MyRunnable(); Thread thread = new Thread(myRunnable); thread.start(); } } -
实现Callable接口创建多线程(jdk5.0后新增的方法)
① 创建一个实现Callable接口的类。 ② 在这个实现类中实现Callable接口的call()方法,并创建这个类的对象。 ③ 将这个Callable接口实现类的对象作为参数传递到FutureTask类的构造器中,创建FutureTask类的对象。 ④ 将这个FutureTask类的对象作为参数传递到Thread类的构造器中,创建Thread类的对象,并调用这个对象的start()方法。 class MyCallable implements Callable{ @Override public Object call() throws Exception { System.out.println("实现Callable接口创建多线程"); return null; } } public class ThreadCreate3 { public static void main(String[] args) { MyCallable myCallable = new MyCallable(); FutureTask futureTask = new FutureTask(myCallable); Thread thread = new Thread(futureTask); thread.start(); } } -
通过线程池创建多线程(jdk5.0后新增的方法)
① 创建提供指定线程数量的线程池,即创建ExecutorService对象。 ② 调用execute()方法执行指定的线程的操作。需要提供实现Runnable接口或Callable接口实现类的对象。 ③ 关闭线程池。 class MyRunnable implements Runnable{ @Override public void run() { System.out.println("通过线程池创建多线程"); } } public class ThreadCreate4 { public static void main(String[] args) { //1、创建线程池对象 ExecutorService service = Executors.newFixedThreadPool(100); //2、这里传入的参数是Runnable接口实现类的对象,并调用execute()方法 service.execute(new MyRunnable()); //3、关闭线程池 service.shutdown(); } }
3.4. Mybatis的缓存机制
3.4.1. 为什么使用缓存
在计算机的世界里面缓存无处不在,操作系统有操作系统的缓存、数据库有数据库的缓存,各种中间件如Redis也用来充当缓存的作用,编程语言又利用内存作为缓存。
计算机CPU的处理速度可谓是一马当先,远远甩开了其他操作,尤其是远超I/O操作,除了那种CPU密集型的系统,其余大部分的业务系统性能瓶颈最后或多或少都会出现在I/O操作上,所以为了减少磁盘的I/O次数,那么缓存是必不可少的,通过缓存的使用我们可以大大减少I/O操作次数,从而在一定程度上弥补了I/O操作和CPU处理速度之间的鸿沟。ORM框架中的缓存的目的也在于此,其对应的操作便减少读取数据库的次数,从而提升查询的效率。
3.4.2. mybatis缓存机制
mybatis的缓存相关类都在cache包里面,在包里定义了一个顶级接口Cache,这个接口默认有一个实现类PerpetualCache,而PerpetualCache中是维护了一个HashMap来实现缓存。
这里需要注意的是,虽然decorators包下的类也实现了Cache接口,那为什么还要说Cache接口只有一个默认实现类呢?
其实从包名decorator就可以得知,这个包里的类全都是装饰器,也就是说这是装饰器模式的实现。
随意打开一个装饰器,可以最终都是调用delegate来实现,只是将部分功能做了增强,其本身都需要依赖Cache的唯一实现类PerpetualCache(因为装饰器内需要传入Cache对象,故而只能传入PerpetualCache对象,因为接口是无法直接new出来传进去的)。
在mybatis中,缓存分为一级缓存和二级缓存。

-
一级缓存是SQLSession级别缓存,在操作数据库时都需要构造SQLSession对象,在对象中有一个数据结构(HashMap)用于存储缓存数据,不同的SQLSession之间的缓存数据区域是互不影响的。
一级缓存的作用于是在同一个SQLSession,在同一个SQLSession中执行相同的两次SQL,第一次执行完毕在后会将数据写到缓存中,第二次从缓存中进行后去就不在数据库中查询,从而提高了效率。
当一个SQLSession结束后该SQLSession中的一级缓存也就不存在了,mybatis默认开启一级缓存。 -
二级缓存是mapper级别缓存,多个SQLSession去操作同一个mapper的SQL语句,多个SQLSession操作都会存在二级缓存中,多个SQLSession共用二级缓存,二级缓存是跨SQLSession的。
二级缓存是多个SQLSession共享的,作用域是mapper下的同一个namespace。不同的SQLSession两次执行相同的namespace下的SQL最终能获取相同的SQL语句结果。
mybatis默认是没有开启二级缓存的,需要在全局配置文件中配置开启二级缓存。
3.4.2.1. 一级缓存(会话级别)
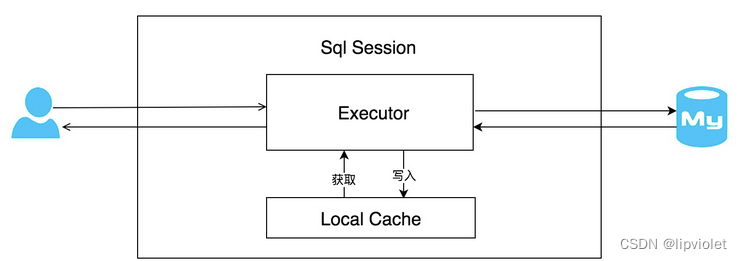 每个SqlSession中持有一个执行器Executor,每个执行器中有一个Local Cache,当用户发起查询时,mybatis根据当前执行的语句生成mapperStatement,在Local Cache中进行查询,如果缓存命中的话,直接返回给用户,如果没有命中,查询数据库,结果写入Local Cache中,最后返回给用户。
每个SqlSession中持有一个执行器Executor,每个执行器中有一个Local Cache,当用户发起查询时,mybatis根据当前执行的语句生成mapperStatement,在Local Cache中进行查询,如果缓存命中的话,直接返回给用户,如果没有命中,查询数据库,结果写入Local Cache中,最后返回给用户。
测试代码:
//同一个SQLSession连续进行查询操作
SqlSession sqlSession = sqlSessionFactory.openSession();
StudentMapper studentMapper = sqlSession.getMapper(StudentMapper.class);
//第一次查询
Student student = studentMapper.selectStudentById(4);
//第二次查询
Student student1 = studentMapper.selectStudentById(4);
//测试是否是同一个对象,如何是则说明走的缓存,压根没读数据库。
System.out.println(student==student1);
//对数据进行变更操作,任何的增删改都可以
studentMapper.updateNameById(4,"test");
sqlSession.commit();
//第三次查询
Student student2 = studentMapper.selectStudentById(4);
//测试是否是同一个对象,如何是则说明走的缓存,压根没读数据库。
System.out.println(student==student2);
System.out.println(student1==student2);
//创建新的SQLsession看是否命中缓存,也就是看是否有隔离
SqlSession sqlSession1 = sqlSessionFactory.openSession();
StudentMapper studentMapper1 = sqlSession1.getMapper(StudentMapper.class);
//第四次查询
Student student3 = studentMapper1.selectStudentById(4);
//测试是否是同一个对象,如何是则说明走的缓存,压根没读数据库。
System.out.println(student==student3);
System.out.println(student1==student3);
System.out.println(student2==student3);
输出分析
true
//说明,同一个sqlSession中同样的sql语句不会再去查询数据库,而是读取缓存
false
false
//说明,任何修改数据表的操作都会导致缓存清空。
false
false
false
//说明,不同的sqlsession之前的缓存是隔离的。
一级缓存总结
- 缓存生效时机:如果是连续的查询同一个数据操作,在第一次查询之后,且后续未对数据库进行过更改,查询都可以命中缓存。原理:在同一个 SqlSession 中, Mybatis 会把执行的方法和参数通过算法生成缓存的键值, 将键值和结果存放在一个 Map 中, 如果后续的键值一样, 则直接从 Map 中获取数据
- 缓存失效时机:任何的 UPDATE, INSERT, DELETE 语句都会清空缓存,并且是清空sqlSession的所有缓存,而不仅仅是只清空某个键和值。
- 即使查询之前没有更新,也可以通过配置使得在查询前清空缓存。
- 不同的 SqlSession 之间的缓存是相互隔离的。不同的SQLSession的一级缓存是无法共享的。
- 一级缓存是默认开启的
3.4.2.2. SqlSession详解
一个sqlSession就是一次事务,随着事务开启产生,随着事务提交消亡,在以及缓存中开始并不理解Sqlsession是什么意思,才详细了解一下,其实就是一次事务提交。
mapper就是sqlSession
- SqlSession是Mybatis最重要的构建之一,可以简单的任务Mybatis一系列的配置目的是生成类似JDBC生成的Connection对象的SqlSession,这样才能和数据库开启“沟通的桥梁”,通过SqlSession可以实现增删改查,sqlSession提供select、insert、update、delete方法,在旧版本中使用sqlsession接口的这些方法,但是在新版本中Mybatis是直接使用Mapper接口,但其本质还是调用了sqlSession。
- mapper就是一个映射器,映射器其实就是一个动态代理对象,进入到MapperMethod的execute方法就能简单找打sqlsession的删除,更新、查询、选择方法,从底层实现来说:通过动态代理技术,让接口跑起来,之后采用命令模式,最后还是采用了sqlsession的接口方法(getMapper()方法等到Mapper)执行sql查询(也就是说Mapper接口方法的底层实现还是采用了Sqlsession的接口方法实现的)。
selsession的四个重要对象
-
Execute:调度执行StatementHandler、ParmmeterHandler、ResultHandler执行相应的SQL语句;
-
StatementHandler:使用数据库中的Statement(PrepareStatement)执行操作,即底层是封装好的PrepareStatement;
-
ParammeterHandler:处理SQL参数;
-
ResultHandler:结果集ResultSet封装处理放回。
在 MyBatis 中,SqlSession 是其核心接口,实现了两个实现类,DefaultSqlSession 和 SqlSessionManager。
DefaultSqlSession 是单线程使用的,而 SqlSessionManager 在多线程环境下使用。SqlSession 的作用类似于一个 JDBC 中的 Connection 对象,代表着一个连接资源的启用。具体而言,它的作用有 3 个:
- 获取 Mapper 接口。
- 发送 SQL 给数据库。
- 控制数据库事务。
//定义 SqlSession
SqlSession sqlSession = null;
try {
// 打开 SqlSession 会话
sqlSession = SqlSessionFactory.openSession();
// some code...
sqlSession.commit(); // 提交事务
} catch (IOException e) {
sqlSession.rollback(); // 回滚事务
}finally{
// 在 finally 语句中确保资源被顺利关闭
if(sqlSession != null){
sqlSession.close();
}
}
//SqlSession 只是一个门面接口,它有很多方法,可以直接发送 SQL。它就好像一家软件公司的商务人员,是一个门面,而实际干活的是软件工程师。在 MyBatis 中,真正干活的是 Executor,我们会在底层看到它
这里使用 commit 方法提交事务,或者使用 rollback 方法回滚事务。因为它代表着一个数据库的连接资源,使用后要及时关闭它,如果不关闭,那么数据库的连接资源就会很快被耗费光,整个系统就会陷入瘫痪状态,所以用 finally 语句保证其顺利关闭。
commit之后sqlsession就会消亡
3.4.2.3. 二级缓存(Mapper级别)
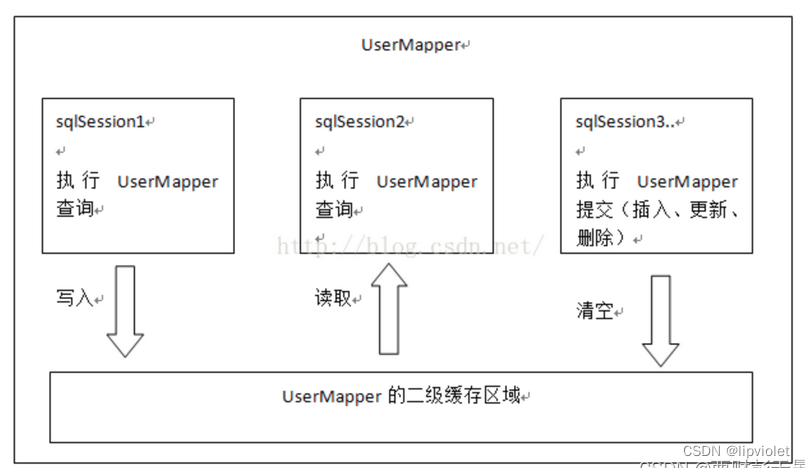
一级缓存因为只能在同一个SqlSession中共享,所以会存在一个问题,在分布式或者多线程的环境下,不同会话之间对于相同的数据可能会产生不同的结果,因为跨会话修改了数据是不能互相感知的,所以就有可能存在脏数据的问题,正因为一级缓存存在这种不足,所以我们需要一种作用域更大的缓存,这就是二级缓存。
一级缓存的作用域是在同一个sqlSession级别,所以它是存储在SqlSession中的BaseExecutor之中。
二级缓存设计的目的就是要使缓存的作用范围更广,就肯定是要实现跨会话共享的,在Mybatis中二级缓存的作用域是namespace,即作用范围在同一个命名空间。
在MyBatis中为了实现二级缓存,专门用了一个装饰器来维护:CachingExecutor。
3.4.2.3.1. 开启二级缓存
二级缓存的配置有3个地方:
- mybatis-config中有一个全局配置属性,这个不配置也行,因为默认就是true
<settings>
<!--开启Mybatis的缓存机制-->
<setting name="cacheEnabled" value="true"/>
</settings>
- 在Mapper映射文件内需要配置缓存标签:
<!--
cache和二级缓存相关标签
eviction属性:代表缓存的回收策略,mybatis提供了回收策略如下:
LRU:最近最少使用,对于最长时间不用的对象进行回收
FIFO:先进先出,按照帝乡进入缓存的顺序来进行回收
SOFT:软引用,移除基于垃圾回收器状态和软引用规则的对象
WEAK:弱引用,基于垃圾回收器状态和弱引用规则的对象
flushInterval属性:刷新间隔时间,单位是毫秒
size属性:引用数目,代表缓存可以存储最多多少个对象
readOnly属性:只读,意味着缓存数据只能读取不能修改
-->
<cache eviction="FIFO" flushInterval="1000" size="1024" readOnly="false"/>
<!--开启二级缓存-->
<cache/>
或者
<cache-ref namespace="loong.mapper.UserMapper"/>
以上配置第1点是默认开启的,也就是说我们只要配置第2点就可以打开二级缓存了,当我们需要针对某一条语句来配置二级缓存时候则可以使用下面的第3点。
- 在select查询语句标签上配置useCache属性,如下:
<select id="findByPage" resultMap="userMap" useCache="true">
select * from student limit ${(curPage - 1)*pageSize}, #{pageSize}
</select>
注意事项
1. 需要commit事务或关闭会话之后才会生效
2. 如果使用的是默认缓存,那么结果集对象需要实现序列化接口(Serializable)
3. 在select查询导致上使用属性:
useCache=“true” 缓存的使用和禁止
flushCache=“true” 刷新缓存
测试代码
//二级缓存的测试
@Test
public void testCache2() {
//不同的SQLSession会话进行相同的SQL查询操作
//SQLSession1实例
SqlSession sqlSession = sessionFactory.openSession();
Student23Mapper student23Mapper = sqlSession.getMapper(Student23Mapper.class);
//SQLSession2实例
SqlSession sqlSession1 = sessionFactory.openSession();
Student23Mapper student23Mapper1 = sqlSession1.getMapper(Student23Mapper.class);
//sqlsession实例3
SqlSession sqlSession2 = sessionFactory.openSession();
Student23Mapper student23Mapper2 = sqlSession2.getMapper(Student23Mapper.class);
//第一次查询id为1的用户
Student23 student23 = student23Mapper.selectStudentByUid(1L);
Student23 student24 = student23Mapper1.selectStudentByUid(1L);
System.out.println(student23==student24);
//这里执行关闭操作,将SQLSession中的数据写入到二级缓存区域
sqlSession.close();
//第二次查询id为1的用户
Student23 student25 = student23Mapper1.selectStudentByUid(1L);
System.out.println(student25==student23);
sqlSession1.close();
}
输出分析
false
//需要commit事务或关闭会话之后二级缓存才会刷新。
true
//不同的SQLSession可以共享一个二级缓存
 二级缓存是一个Cache接口的实现类,一级缓存是一个localCache是一个HashMap的属性,
二级缓存是一个Cache接口的实现类,一级缓存是一个localCache是一个HashMap的属性,
执行过程先经过二级缓存,在二级缓存未命中时才会走一级缓存。
3.4.2.3.2. 二级缓存应该开启吗
-
因为所有的update操作(insert,delete,uptede)都会触发缓存的刷新,从而导致二级缓存失效,所以二级缓存适合在读多写少的场景中开启。
-
因为二级缓存针对的是同一个namespace,所以建议是在单表操作的Mapper中使用,或者是在相关表的Mapper文件中共享同一个缓存。
一级缓存可能存在脏读情况,二级缓存同样存在脏读的情况。
因为默认的二级缓存毕竟也是存储在本地缓存,所以对于微服务下是可能出现脏读的情况的,所以这时候我们可能会需要自定义缓存,比如利用redis来存储缓存,而不是存储在本地内存当中。
3.4.3. mybatis的代理详解
3.4.3.1. 源码
Java中动态代理主要是JDK动态代理(接口),CGLib动态代理(类继承)
SqlSession sqlSession = sqlSessionFactory.openSession();
/**
*在通过sqlSession.getMapper可以获取一个代理对象
* 对于StudentMapper并没有显性的实现该接口的实现类,
* 该对象是在运行时动态产生的,该对象就是动态代理对象
*
* JDK动态代理
* 1、首先存在接口(StudentMapper.java)
* 2、必须存在该接口的实现类(sqlSession.selectOne)
* 3、实现invocationHandler辅助类
* 4、通过Proxy类来产生代理对象
*/
//单个对象原始调用方式
//Student student = sqlSession.selectOne("com.tulun.Mybatis.mapper.StudentMapper.selectStudentById", 4);
StudentMapper studentMapper = sqlSession.getMapper(StudentMapper.class);
Student student = studentMapper.selectStudentById(4);
System.out.println(student);
mybatis亦同,同样使用了JDK动态代理相关的接口和类,产生代理对象使用了一个HashMap进行add和get
mapper接口是如何添加进去的?
//通过Java代码形式来进行数据源、映射文件的配置形式如下:
//1.将mapper文件读取到配置文件
Configuration configuration = new Configuration();
PooledDataSourceFactory dataSourceFactory = new PooledDataSourceFactory();
DataSource dataSource = dataSourceFactory.getDataSource();
JdbcTransactionFactory jdbcTransactionFactory = new JdbcTransactionFactory();
//设置环境
Environment environment = new Environment("test", jdbcTransactionFactory, dataSource);
configuration.setEnvironment(environment);
//设置mapper接口
configuration.addMapper(StudentMapper.class);
new SqlSessionFactoryBuilder().build(configuration);
//2.重点在于接口的添加形式,在Configuration类中,mapper在Configuration类中没有做任何事,只是添加到mapperRegistry类中。
configuration.addMapper(StudentMapper.class);
//调用方法
public <T> void addMapper(Class<T> type) {
mapperRegistry.addMapper(type);
}
//实现类
public <T> void addMapper(Class<T> type) {
if (type.isInterface()) {//只允许添加接口
if (hasMapper(type)) {//不允许重复添加
throw new BindingException("Type " + type + " is already known to the MapperRegistry.");
}
boolean loadCompleted = false;
try {
knownMappers.put(type, new MapperProxyFactory<T>(type));
MapperAnnotationBuilder parser = new MapperAnnotationBuilder(config, type);
parser.parse();
loadCompleted = true;
} finally {
if (!loadCompleted) {
knownMappers.remove(type);
}
}
}
}
//执行的configuration.addMapper(StudentMapper.class),实际上最终被放入HashMap中,其命名knownMappers,它是mapperRegistry类中的私有属性,是一个HashMap对象,key是接口class对象,value是MapperProxyFactory的对象实例。
//3. 通过getMapper获取代理对象。
//DefaultSqlSession类:
public <T> T getMapper(Class<T> type) {
return configuration.<T>getMapper(type, this);
}
//configuration类中存放所有的mybatis全局配置信息,从参数上可以知道class类型。
//configuration类:
public <T> T getMapper(Class<T> type, SqlSession sqlSession) {
return mapperRegistry.getMapper(type, sqlSession);
}
//configuration类中getmapper调用了mapperRegistry.getMapper,mapperRegistry中存放一个HashMap。
//mapperRegistry类:
private final Map<Class<?>, MapperProxyFactory<?>> knownMappers = new HashMap<Class<?>, MapperProxyFactory<?>>();
public <T> T getMapper(Class<T> type, SqlSession sqlSession) {
final MapperProxyFactory<T> mapperProxyFactory = (MapperProxyFactory<T>) knownMappers.get(type);
if (mapperProxyFactory == null) {
throw new BindingException("Type " + type + " is not known to the MapperRegistry.");
}
try {
return mapperProxyFactory.newInstance(sqlSession);
} catch (Exception e) {
throw new BindingException("Error getting mapper instance. Cause: " + e, e);
}
}
//调用mapperRegistry类中的getMapper方法,该方法中会到hashmap中通过类名获取对应的value值,是MapperProxyFactory对象,然后调用newInstance方法,该方法是创建了一个对象。
public class MapperProxyFactory<T> {//映射器代理工厂
private final Class<T> mapperInterface;
private final Map<Method, MapperMethod> methodCache = new ConcurrentHashMap<Method, MapperMethod>();
@SuppressWarnings("unchecked")
protected T newInstance(MapperProxy<T> mapperProxy) {
//使用的是JDK自带的动态代理对象生成代理类对象
return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[] { mapperInterface }, mapperProxy);
}
public T newInstance(SqlSession sqlSession) {
final MapperProxy<T> mapperProxy = new MapperProxy<T>(sqlSession, mapperInterface, methodCache);
return newInstance(mapperProxy);
}
}
public class MapperProxy<T> implements InvocationHandler, Serializable {
//实现了InvocationHandler接口
@Override
//代理之后,所有的mapper的方法调用,都会调用这个invoke方法
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
if (Object.class.equals(method.getDeclaringClass())) {
try {
return method.invoke(this, args); //该位置就调用了原始的调用方法:SQLSession.selectOne
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}
final MapperMethod mapperMethod = cachedMapperMethod(method);
//执行CURD操作
return mapperMethod.execute(sqlSession, args);
}
}
3.4.3.2. 总结
以上其实过于详细了,其实就是看一遍源码,总结起来并不复杂。
mybatis中getmapper的代理对象的获取,使用的是JDK动态代理,在MapperRegistry类中的HashMap中存放了所有的mapper接口,key是接口的类名信息,value是MapperProxyFactory类型实例,getmapper操作会是当前对象调用newInstance操作,该操作会调用Proxy.newProxyInstance核心在于调用InvocationHandler接口,实现了invoke方法,除了调用原始的接口调用,而且还对调用进行增强,进行了方法缓存,且最终会执行增删改查操作。
总结Mapper接口方法执行的几个点:
- Mapper接口初始在SQLSessionFactory注册的。
- Mapper接口注册在MapperRegistry类的HashMap中,key是mapper的接口类名,value是创建当前代理工厂。
- Mapper注册之后,可以从过SQLSession来获取get对象。
- SQLSession.getMapper运用了JDK动态代理,产生了目标Mapper接口的代理对象,动态代理的代理类是MapperProxy,实现了增删改查调用。
3.5. 分布式锁详解
3.5.1. 为什么使用分布式锁
与分布式锁相对应的是「单机锁」,我们在写多线程程序时,避免同时操作一个共享变量产生数据问题,通常会使用一把锁来「互斥」,以保证共享变量的正确性,其使用范围是在「同一个进程」中。
如果换做是多个进程,需要同时操作一个共享资源,如何互斥呢? 例如,现在的业务应用通常都是微服务架构,这也意味着一个应用会部署多个进程,那这多个进程如果需要修改 MySQL 中的同一行记录时,为了避免操作乱序导致数据错误,此时,我们就需要引入「分布式锁」来解决这个问题了。
最常见的就是使用分布式锁避免mysql数据出现错误。
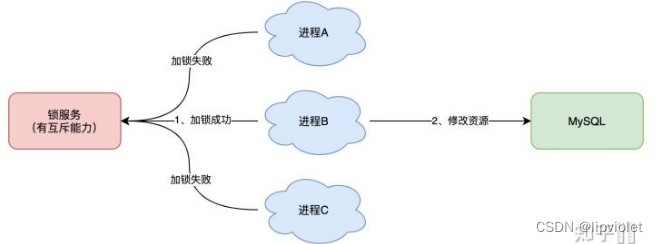
想要实现分布式锁,必须借助一个外部系统,所有进程都去这个系统上申请「加锁」。 而这个外部系统,必须要实现「互斥」的能力,即两个请求同时进来,只会给一个进程返回成功,另一个返回失败(或等待)。 这个外部系统,可以是 MySQL,也可以是 Redis 或 Zookeeper。但为了追求更好的性能,我们通常会选择使用 Redis 或 Zookeeper 来做。
也就是说,分布式锁其实只要是一个当前服务之外的外部系统,都可以,本质就是进行注册,保证串行。只是处于速度选择了redis和zookeeper,能实现该作用的任何逻辑或者服务都可以的。
无论任何分布式锁,其原理都是锁!!!也就是串行化操作数据,拿到锁进行业务处理,拿不到锁进行等待。
如何实现一个锁,无非就是进入之后做个标识,让后续的人知道前面已经有人了。
3.5.2. redis实现
借助redis实现分布式锁,是最常见的一种方法,也是最简单的操作。
想要实现分布式锁,必须要求 Redis 有「互斥」的能力,也就是说借助redis实现原子性的互斥逻辑,告诉用户,到底拿没拿到锁。
3.5.2.1. 使用INCR加锁
key 不存在,那么 key 的值会先被初始化为 0 ,然后再执行 INCR 操作进行加一。然后其它用户在执行 INCR 操作进行加一时,如果返回的数大于 1 ,说明这个锁正在被使用当中。
/***
1、 客户端A请求服务器获取key的值为1表示获取了锁
2、 客户端B也去请求服务器获取key的值为2表示获取锁失败
3、 客户端A执行代码完成,删除锁
4、 客户端B在等待一段时间后在去请求的时候获取key的值为1表示获取锁成功
5、 客户端B执行代码完成,删除锁
**/
$res = $redis->incr($key); // 自增1
$redis->expire($key, $ttl); // 设置锁的有效期
if($res == 1){
// 获取资源成功
}else{
// 资源被其他请求占用
}
3.5.2.2. 使用SET加锁
key不存在,将 key 设置为想要的值,如果 key已存在,则不做任何动作。这就是SETNX,还有一个相反的逻辑是SETXX;二者都是借助set命令实现互斥逻辑,都可以作为分布式锁。
/***
1、 客户端A请求服务器设置key的值,如果设置成功就表示加锁成功
2、 客户端B也去请求服务器设置key的值,如果返回失败,那么就代表加锁失败
3、 客户端A执行代码完成,删除锁
4、 客户端B在等待一段时间后在去请求设置key的值,设置成功
5、 客户端B执行代码完成,删除锁
**/
$res = $redis->setNX($key, $value); // 当key不存在时设置key=value
$redis->expire($key, $ttl); // 设置锁的有效期
if($res){
// 获取资源成功
}else{
// 资源被其他请求占用
}
上面两种方法都有一个问题,会发现,都需要设置 key 过期时间。那么为什么要设置key过期时间呢?如果请求执行因为某些原因意外退出了,导致创建了锁但是没有删除锁,那么这个锁将一直存在(redis不设置key的过期时间,默认是永久的),以至于一直处于加锁状态。于是乎我们需要给锁加一个过期时间以防不测。
但是借助 Expire 来设置就不是原子性操作了。所以还可以通过redis事务来确保原子性。那上面的代码就要优化成:
// 第一种方式的加锁
$redis->multi(); // 标记一个事务块的开始
$res = $redis->incr($key);
$redis->expire($key, $ttl);
$redis->exec(); // 提交事务
if($res == 1){
// 获取资源成功
}else{
// 资源被其他请求占用
}
// 第二种方式的加锁
$redis->multi(); // 标记一个事务块的开始
$res = $redis->setNX($key, $value);
$redis->expire($key, $ttl);
$redis->exec(); // 提交事务
if($res){
// 获取资源成功
}else{
// 资源被其他请求占用
}
如上,是低版本的redis锁的方式,需要自己控制原子性。自从2.6.12redis版本开始SET 命令本身已经包含了设置过期时间的功能。并且官网(Set 命令页)也同时提及,“SETNX,SETEX,PSETEX 可能在未来的版本中,会弃用并永久删除”。因为set命令的多个参数已经足以满足需求。
所以目前的主流redis锁就是 :
SET key value [EX seconds|PX milliseconds] [NX|XX] [KEEPTTL]
使用set命令基本上可以满足分布式锁的需求,但是有一个弊端不得不考虑,为了防止死锁,我们一般都会设置一个锁的有效时间,A进程拿到锁之后,GC或者不可控的原因导致程序阻塞,阻塞时间超过了锁的有效时间,锁释放后客户端B获取到了锁,此时这时候客户端A和客户端B同时执行了!!!
出现这种现象时,分布式锁已然失效, 并且A执行完毕会删掉锁,并行度进一步提升,B执行完再删,无限套娃!!
这还是个特喵的der分布式锁。
3.5.2.3. setNx的隐患
可以通过以下示例了解该问题的严重性
我们项目中的抢购订单采用的是分布式锁来解决的,有一次,运营做了一个飞天茅台的抢购活动,库存100瓶,但是却超卖了100瓶!要知道,这个地球上飞天茅台的稀缺性啊!!!
经过一番了解后,得知这个抢购活动接口以前从来没有出现过这种情况,但是这次为什么会超卖呢?
原因在于:之前的抢购商品都不是什么稀缺性商品,而这次活动居然是飞天茅台,通过埋点数据分析,各项数据基本都是成倍增长,活动热烈程度可想而知!话不多说,直接上核心代码,机密部分做了伪代码处理。。。
public SeckillActivityRequestVO seckillHandle(SeckillActivityRequestVO request) {
SeckillActivityRequestVO response;
String key = "key:" + request.getSeckillId;
try {
Boolean lockFlag = redisTemplate.opsForValue().setIfAbsent(key, "val", 10, TimeUnit.SECONDS);
if (lockFlag) {
// HTTP请求用户服务进行用户相关的校验
// 用户活动校验
// 库存校验
Object stock = redisTemplate.opsForHash().get(key+":info", "stock");
assert stock != null;
if (Integer.parseInt(stock.toString()) <= 0) {
// 业务异常
} else {
redisTemplate.opsForHash().increment(key+":info", "stock", -1);
// 生成订单
// 发布订单创建成功事件
// 构建响应VO
}
}
} finally {
// 释放锁
stringRedisTemplate.delete("key");
// 构建响应VO
}
return response;
}
以上代码,通过分布式锁过期时间有效期10s来保障业务逻辑有足够的执行时间;采用try-finally语句块保证锁一定会及时释放。业务代码内部也对库存进行了校验。看起来很安全啊~ 别急,继续分析。。。
飞天茅台抢购活动吸引了大量新用户下载注册我们的APP,其中,不乏很多羊毛党,采用专业的手段来注册新用户来薅羊毛和刷单。当然我们的用户系统提前做好了防备,接入阿里云人机验证、三要素认证以及自研的风控系统等各种十八般武艺,挡住了大量的非法用户。此处不禁点个赞~ 但也正因如此,让用户服务一直处于较高的运行负载中。
抢购活动开始的一瞬间,大量的用户校验请求打到了用户服务。导致用户服务网关出现了短暂的响应延迟,有些请求的响应时长超过了10s,但由于HTTP请求的响应超时我们设置的是30s,这就导致接口一直阻塞在用户校验那里,10s后,分布式锁已经失效了,此时有新的请求进来是可以拿到锁的,也就是说锁被覆盖了。这些阻塞的接口执行完之后,又会执行释放锁的逻辑,这就把其他线程的锁释放了,导致新的请求也可以竞争到锁~这真是一个极其恶劣的循环。这个时候只能依赖库存校验,但是偏偏库存校验不是非原子性的,采用的是get and compare 的方式,超卖的悲剧就这样发生了~~~
究其原因就是阻塞导致的锁超时自动释放。,当然也有客观原因,1)没有其他系统风险容错处理,由于用户服务吃紧,网关响应延迟,但没有任何应对方式,这是超卖的导火索。2)非原子性的库存校验,非原子性的库存校验导致在并发场景下,库存校验的结果不准确。这是超卖的根本原因。以上代码库存校验严重依赖了分布式锁。当分布式锁正常set、del的情况下,库存校验是没有问题的。然而,当分布式锁不安全可靠的时候,库存校验也同时失效了。
实现相对安全的分布式锁
相对安全的定义:set、del是一一映射的,不会出现把其他现成的锁del的情况。从实际情况的角度来看,即使能做到set、del一一映射,也无法保障业务的绝对安全。因为锁的过期时间始终是有界的,除非不设置过期时间或者把过期时间设置的很长,但这样做也会带来其他问题。故没有意义。要想实现相对安全的分布式锁,必须依赖key的value值。在释放锁的时候,通过value值的唯一性来保证不会勿删。我们基于LUA脚本实现原子性的get and compare,如下:
//我们通过LUA脚本来实现安全地解锁。
public void safedUnLock(String key, String val) {
String luaScript = "local in = ARGV[1] local curr=redis.call('get', KEYS[1]) if in==curr then redis.call('del', KEYS[1]) end return 'OK'"";
RedisScript<String> redisScript = RedisScript.of(luaScript);
redisTemplate.execute(redisScript, Collections.singletonList(key), Collections.singleton(val));
}
实现安全的库存校验
如果我们对于并发有比较深入的了解的话,会发现想 get and compare/ read and save 等操作,都是非原子性的。如果要实现原子性,我们也可以借助LUA脚本来实现。但就我们这个例子中,由于抢购活动一单只能下1瓶,因此可以不用基于LUA脚本实现而是基于redis本身的原子性。原因在于:
// redis会返回操作之后的结果,这个过程是原子性的
Long currStock = redisTemplate.opsForHash().increment("key", "stock", -1);
改进之后的代码
//经过以上的分析之后,我们决定新建一个DistributedLocker类专门用于处理分布式锁。
public SeckillActivityRequestVO seckillHandle(SeckillActivityRequestVO request) {
SeckillActivityRequestVO response;
String key = "key:" + request.getSeckillId();
String val = UUID.randomUUID().toString();
try {
Boolean lockFlag = distributedLocker.lock(key, val, 10, TimeUnit.SECONDS);
if (!lockFlag) {
// 业务异常
}
// 用户活动校验
// 库存校验,基于redis本身的原子性来保证
Long currStock = stringRedisTemplate.opsForHash().increment(key + ":info", "stock", -1);
if (currStock < 0) { // 说明库存已经扣减完了。
// 业务异常。
log.error("[抢购下单] 无库存");
} else {
// 生成订单
// 发布订单创建成功事件
// 构建响应
}
} finally {
distributedLocker.safedUnLock(key, val);
// 构建响应
}
return response;
}
其实通过这个例子我们可以发现,我们借助于redis本身的原子性扣减库存,也是可以保证不会超卖的。
确实如此,但是如果没有这一层锁的话,那么所有请求进来都会走一遍业务逻辑,由于依赖了其他系统,此时就会造成对其他系统的压力增大。这会增加的性能损耗和服务不稳定性,得不偿失。基于分布式锁可以在一定程度上拦截一些流量。
基于以上代码上线后,如愿以偿的没有了超卖事件,那还能不能继续优化呢?可以!由于服务是集群部署,我们可以将库存均摊到集群中的每个服务器上,通过广播通知到集群的各个服务器。网关层基于用户ID做hash算法来决定请求到哪一台服务器。这样就可以基于应用缓存来实现库存的扣减和判断。性能又进一步提升了!
// 通过消息提前初始化好,借助ConcurrentHashMap实现高效线程安全
private static ConcurrentHashMap<Long, Boolean> SECKILL_FLAG_MAP = new ConcurrentHashMap<>();
// 通过消息提前设置好。由于AtomicInteger本身具备原子性,因此这里可以直接使用HashMap
private static Map<Long, AtomicInteger> SECKILL_STOCK_MAP = new HashMap<>();
...
public SeckillActivityRequestVO seckillHandle(SeckillActivityRequestVO request) {
SeckillActivityRequestVO response;
Long seckillId = request.getSeckillId();
if(!SECKILL_FLAG_MAP.get(requestseckillId)) {
// 业务异常
}
// 用户活动校验
// 库存校验
if(SECKILL_STOCK_MAP.get(seckillId).decrementAndGet() < 0) {
SECKILL_FLAG_MAP.put(seckillId, false);
// 业务异常
}
// 生成订单
// 发布订单创建成功事件
// 构建响应
return response;
}
通过以上的改造,我们就完全不需要依赖redis了。性能和安全性两方面都能进一步得到提升!当然,此方案没有考虑到机器的动态扩容、缩容等复杂场景,如果还要考虑这些话,则不如直接考虑分布式锁的解决方案。
----RedLock、Redisson、Zookeeper
RedLock、Zookeeper的可靠性更高,但其代价是牺牲一定的性能。目前的主流就是Redisson。
3.5.2.4. Lua脚本(Redisson)
Lua 是一种轻量小巧的脚本语言,用标准 C 语言编写并以源代码形式开放,其设计目的是为了嵌入应用程序中,从而为应用程序提供灵活的扩展和定制功能。Lua 可以应用在游戏开发、独立应用脚本、Web 应用脚本、扩展和数据库插件、安全系统等场景。
Lua脚本体积很小,运行速度很快,并且每次的执行都是作为一个原子事务来执行的,也就是说可以使用lua实现你想要的任何事务操作。 Redis 2.6.0 版本开始内置的 Lua 解释器来支持lua脚本,redis客户端可以使用lua脚本,直接在服务器原子地执行多个redis命令。
redis集成lua的原因:
-
减少网络开销: 在Redis操作需求需要向Redis发送5次请求,而使用脚本功能完成同样的操作只需要发送一个请求即可,减少了网络往返时延。
-
原子操作: Redis会将整个脚本作为一个整体执行,中间不会被其他命令插入。换句话说在编写脚本的过程中无需担心会出现竞态条件,也就无需使用事务。事务可以完成的所有功能都可以用脚本来实现。
-
复用: 客户端发送的脚本会永久存储在Redis中,这就意味着其他客户端(可以是其他语言开发的项目)可以复用这一脚本而不需要使用代码完成同样的逻辑。
-
速度快:见 与其它语言的性能比较, 还有一个 JIT编译器可以显著地提高多数任务的性能; 对于那些仍然对性能不满意的人, 可以把关键部分使用C实现, 然后与其集成, 这样还可以享受其它方面的好处。
回到之前的问题,可以使用lua脚本进行解决。
- 锁过期:客户端 1 操作共享资源耗时太久,导致锁被自动释放,之后被客户端 2 持有
- 释放别人的锁:客户端 1 操作共享资源完成后,却又释放了客户端 2 的锁。
第一个问题,加长过期时间只是治标不治本,一劳永逸就是加守护进程,定时去检测这个锁的失效时间,如果锁快要过期了,操作共享资源还未完成,那么就自动对锁进行「续期」,重新设置过期时间。
第二个问题,客户端在加锁时,设置一个只有自己知道的「唯一标识」进去。
//例如,可以设置value为自己的线程 ID,也可以是一个 UUID(随机且唯一)
127.0.0.1:6379> SET lock $uuid EX 20 NX
//之后,在释放锁时,要先判断这把锁是否还归自己持有,伪代码如下:
if redis.get("lock") == $uuid:
redis.del("lock")
这里释放锁使用的是 GET + DEL 两条命令,这时,又会遇到我们前面讲的原子性问题了。 客户端 1 执行 GET,判断锁是自己的 客户端 2 执行了 SET 命令,强制获取到锁(虽然发生概率很低很低,但我们需要严谨地考虑锁的安全性模型) 客户端 1 执行 DEL,却释放了客户端 2 的锁
由此可见,这两个命令还是必须要原子执行才行。Lua脚本,因为 Redis 处理每一个请求是「单线程」执行的,在执行一个 Lua 脚本时,其它请求必须等待,直到这个 Lua 脚本处理完成,这样一来,GET + DEL 之间就不会插入其它命令了。
//安全释放锁的 Lua 脚本如下:
// 判断锁是自己的,才释放
if redis.call("GET",KEYS[1]) == ARGV[1]
then
return redis.call("DEL",KEYS[1])
else
return 0
end
是用lua脚本的目的只是为了原子性操作redis,但是守护线程便不是那么容易自己写了,如果你是 Java 技术栈,幸运的是,已经有一个库把这些工作都封装好了:Redisson。它不仅有看门狗的功能,而且对主从,哨兵,集群等模式都支持。源码中加锁/释放锁操作都是用 Lua 脚本完成的,封装的非常完善,开箱即用。
的确用起来像 JDK 的 ReentrantLock 一样丝滑。除此之外,这个 SDK 还封装了很多易用的功能:
- 可重入锁
- 乐观锁
- 公平锁
- 读写锁
- Redlock(红锁,下面会详细讲)
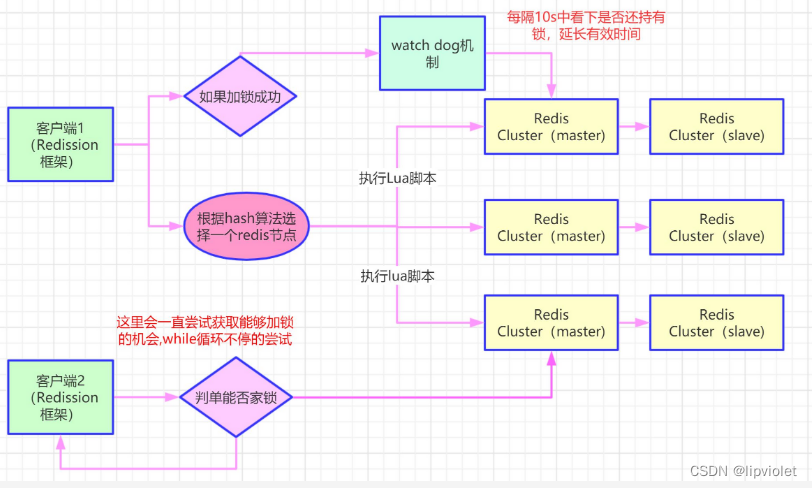
加锁过程
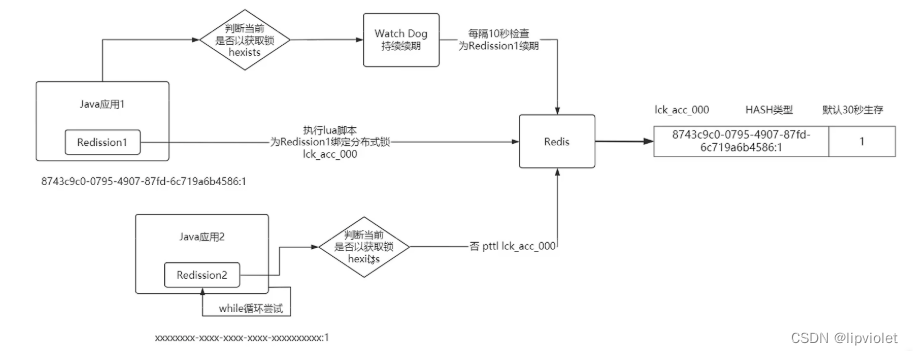
解锁过程
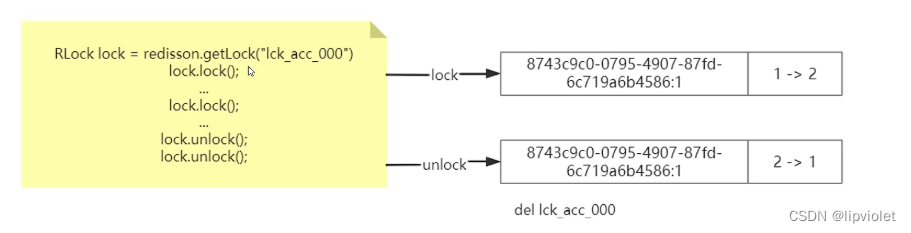
3.5.2.5. 红锁(RedLock)
RedLock的中文是直译过来的,就叫红锁。红锁并非是一个工具,而是 Redis 官方提出的一种分布式锁的算法。
目前的Redisson中,就已经实现了 RedLock 版本的锁。也就是说除了 getLock 方法,还有 getRedLock 方法。
Redission其实已经比较完善了,那还有会危害Redis锁的情况吗?有的!
之前分析的场景都是,锁在「单个」Redis 实例中可能产生的问题,并没有涉及到 Redis 的部署架构细节。
而我们在使用 Redis 时,一般会采用主从集群 + 哨兵的模式部署,这样做的好处在于,当主库异常宕机时,哨兵可以实现「故障自动切换」,把从库提升为主库,继续提供服务,以此保证可用性。 那当「主从发生切换」时,这个分布锁会依旧安全吗?
试想这样的场景:
- 客户端 1 在主库上执行 SET 命令,加锁成功
- 此时,主库异常宕机,SET 命令还未同步到从库上(主从复制是异步的)
- 从库被哨兵提升为新主库,这个锁在新的主库上,丢失了!
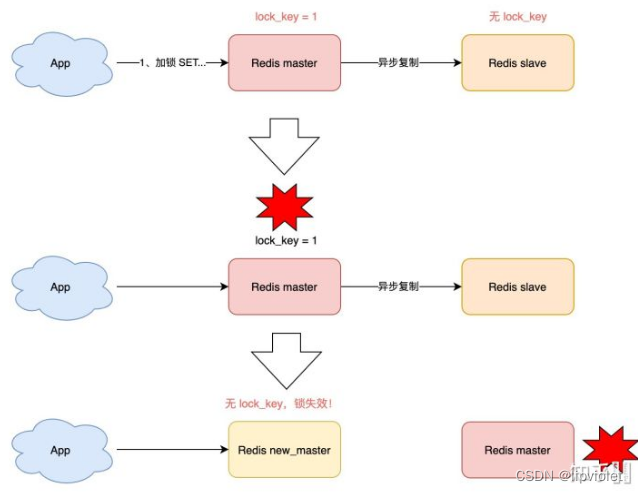
可见,当引入 Redis 副本后,分布锁还是可能会受到影响。
为此,Redis 的作者提出一种解决方案,就是我们经常听到的 Redlock(红锁)。其实就是集群算法,采用多节点组成集群,只要 2N+1 个节点加锁成功,那么就认为获取了锁, 解锁时将所有实例解锁。

有些人是不是觉得大佬们都是杠精啊,天天就想着极端情况。其实高可用嘛,拼的就是 99.999…% 中小数点后面的位数。
现在我们来看,Redis 作者提出的 Redlock 方案,是如何解决主从切换后,锁失效问题的。
— 多个redis实例,且为奇数,
注意:不是部署 Redis Cluster,就是部署 5 个简单的 Redis 实例。它们之间没有任何关系,都是一个个孤立的实例。
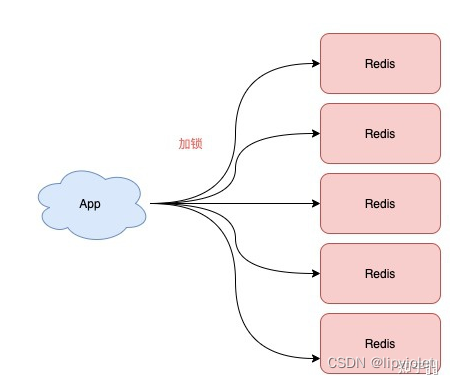
Redlock的整体流程是这样的,一共分为 5 步:
- 客户端先获取「当前时间戳T1」
- 客户端依次向这 5 个 Redis 实例发起加锁请求(用前面讲到的 SET 命令),且每个请求会设置超时时间(毫秒级,要远小于锁的有效时间),如果某一个实例加锁失败(包括网络超时、锁被其它人持有等各种异常情况),就立即向下一个 Redis 实例申请加锁
- 如果客户端从 >=3 个(大多数)以上 Redis 实例加锁成功,则再次获取「当前时间戳T2」,如果 T2 - T1 < 锁的过期时间,此时,认为客户端加锁成功,否则认为加锁失败
- 加锁成功,去操作共享资源(例如修改 MySQL 某一行,或发起一个 API 请求)
- 加锁失败,向「全部节点」发起释放锁请求(前面讲到的 Lua 脚本释放锁)
重点有四个:
1) 为什么要在多个实例上加锁?
本质上是为了「容错」,部分实例异常宕机,剩余的实例加锁成功,整个锁服务依旧可用。
2) 为什么大多数加锁成功,才算成功? 多个 Redis 实例一起来用,其实就组成了一个「分布式系统」。目的就是避免单点故障,在分布式系统中,总会出现「异常节点」,所以,在谈论分布式系统问题时,需要考虑异常节点达到多少个,也依旧不会影响整个系统的「正确性」。 这是一个分布式系统「容错」问题,这个问题的结论是:如果只存在「故障」节点,只要大多数节点正常,那么整个系统依旧是可以提供正确服务的。 这个问题的模型,就是我们经常听到的「拜占庭将军」问题。
3) 为什么步骤 3 加锁成功后,还要计算加锁的累计耗时?
因为操作的是多个节点,所以耗时肯定会比操作单个实例耗时更久,而且,因为是网络请求,网络情况是复杂的,有可能存在延迟、丢包、超时等情况发生,网络请求越多,异常发生的概率就越大。 所以,即使大多数节点加锁成功,但如果加锁的累计耗时已经「超过」了锁的过期时间,那此时有些实例上的锁可能已经失效了,这个锁就没有意义了。
4) 为什么释放锁,要操作所有节点? 在某一个 Redis 节点加锁时,可能因为「网络原因」导致加锁失败。 例如,客户端在一个 Redis 实例上加锁成功,但在读取响应结果时,网络问题导致读取失败,那这把锁其实已经在 Redis 上加锁成功了。 所以,释放锁时,不管之前有没有加锁成功,需要释放「所有节点」的锁,以保证清理节点上「残留」的锁。
好了,明白了 Redlock 的流程和相关问题,看似 Redlock 确实解决了 Redis 节点异常宕机锁失效的问题,保证了锁的「安全性」。但事实真的如此吗?
—有关Redlock的著名争论,即 Martin Kleppmann 和 Antirez 的 RedLock 辩论。一个是业界著名的分布式系统专家,一个是 Redis 之父。
3.5.2.6. RedLock辩论
二人思路清晰,论据充分,这是一场高手过招,也是分布式系统领域非常好的一次思想的碰撞!双方都是分布式系统领域的专家,却对同一个问题提出很多相反的论断,究竟是怎么回事?
3.5.2.6.1. 分布式专家 Martin 对于 Redlock 的质疑
在他的文章中,主要阐述了 4 个论点:
1)分布式锁的目的是什么?
他认为有两个目的。
-
效率
使用分布式锁的互斥能力,是避免不必要地做同样的两次工作(例如一些昂贵的计算任务)。如果锁失效,并不会带来「恶性」的后果,例如发了 2 次邮件等,无伤大雅。 -
正确性。
使用锁用来防止并发进程互相干扰。如果锁失效,会造成多个进程同时操作同一条数据,产生的后果是数据严重错误、永久性不一致、数据丢失等恶性问题,就像给患者服用重复剂量的药物一样,后果严重。
他认为,如果你是为了前者——效率,那么使用单机版 Redis 就可以了,即使偶尔发生锁失效(宕机、主从切换),都不会产生严重的后果。而使用 Redlock 太重了,没必要。
而如果是为了正确性,Martin 认为 Redlock 根本达不到安全性的要求,也依旧存在锁失效的问题!
2) 锁在分布式系统中会遇到的问题
Martin 表示,一个分布式系统,更像一个复杂的「野兽」,存在着你想不到的各种异常情况。 这些异常场景主要包括三大块,这也是分布式系统会遇到的三座大山:NPC。
- N:Network Delay,网络延迟
- P:Process Pause,进程暂停(GC)
- C:Clock Drift,时钟漂移
Martin 用一个进程暂停(GC)的例子,指出了 Redlock 安全性问题:
- 客户端 1 请求锁定节点 A、B、C、D、E
- 客户端 1 的拿到锁后,进入 GC(时间比较久)
- 所有 Redis 节点上的锁都过期了
- 客户端 2 获取到了 A、B、C、D、E 上的锁
- 客户端 1 GC 结束,认为成功获取锁
- 客户端 2 也认为获取到了锁,发生「冲突」
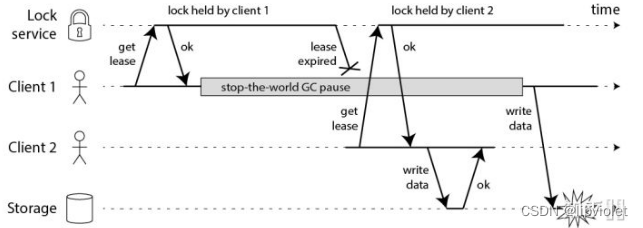
Martin 认为,GC 可能发生在程序的任意时刻,而且执行时间是不可控的。 当然,即使是使用没有 GC 的编程语言,在发生网络延迟、时钟漂移时,也都有可能导致 Redlock 出现问题,这里 Martin 只是拿 GC 举例。
3) 假设时钟正确的是不合理的
又或者,当多个 Redis 节点「时钟」发生问题时,也会导致 Redlock 锁失效
- 客户端 1 获取节点 A、B、C 上的锁,但由于网络问题,无法访问 D 和 E
- 节点 C 上的时钟「向前跳跃」,导致锁到期
- 客户端 2 获取节点 C、D、E 上的锁,由于网络问题,无法访问 A 和 B
- 客户端 1 和 2 现在都相信它们持有了锁(冲突)
Martin 觉得,Redlock 必须「强依赖」多个节点的时钟是保持同步的,一旦有节点时钟发生错误,那这个算法模型就失效了。
即使 C 不是时钟跳跃,而是「崩溃后立即重启」,也会发生类似的问题。
Martin 继续阐述,机器的时钟发生错误,是很有可能发生的:
- 系统管理员「手动修改」了机器时钟
- 机器时钟在同步 NTP 时间时,发生了大的「跳跃」
Martin 认为,Redlock 的算法是建立在「同步模型」基础上的,有大量资料研究表明,同步模型的假设,在分布式系统中是有问题的。 在混乱的分布式系统的中,你不能假设系统时钟就是对的,所以,你必须非常小心你的假设。
4) 提出 fencing token 的方案,保证正确性
相对应的,Martin 提出一种被叫作 fencing token 的方案,保证分布式锁的正确性,这个模型流程如下:
- 客户端在获取锁时,锁服务可以提供一个「递增」的 token
- 客户端拿着这个 token 去操作共享资源
- 共享资源可以根据 token 拒绝「后来者」的请求
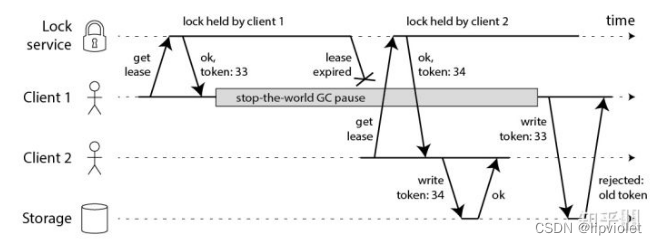 这样一来,无论 NPC 哪种异常情况发生,都可以保证分布式锁的安全性,因为它是建立在「异步模型」上的。
这样一来,无论 NPC 哪种异常情况发生,都可以保证分布式锁的安全性,因为它是建立在「异步模型」上的。
而 Redlock 无法提供类似 fencing token 的方案,所以它无法保证安全性。
他还表示,一个好的分布式锁,无论 NPC 怎么发生,可以不在规定时间内给出结果,但并不会给出一个错误的结果。也就是只会影响到锁的「性能」(或称之为活性),而不会影响它的「正确性」。
Martin 的结论:
- Redlock 不伦不类:它对于效率来讲,Redlock 比较重,没必要这么做,而对于正确性来说,Redlock 是不够安全的。
- 时钟假设不合理:该算法对系统时钟做出了危险的假设(假设多个节点机器时钟都是一致的),如果不满足这些假设,锁就会失效。
- 无法保证正确性:Redlock 不能提供类似 fencing token 的方案,所以解决不了正确性的问题。为了正确性,请使用有「共识系统」的软件,例如 Zookeeper。
3.5.2.6.2. Redis 作者 Antirez 的反驳
在 Redis 作者的文章中,重点有 3 个:
1) 解释时钟问题
首先,Redis 作者一眼就看穿了对方提出的最为核心的问题:时钟问题。
Redis 作者表示,Redlock 并不需要完全一致的时钟,只需要大体一致就可以了,允许有「误差」。 例如要计时 5s,但实际可能记了 4.5s,之后又记了 5.5s,有一定误差,但只要不超过「误差范围」锁失效时间即可,这种对于时钟的精度的要求并不是很高,而且这也符合现实环境。
对于对方提到的「时钟修改」问题,Redis 作者反驳到:
- 手动修改时钟:不要这么做就好了,否则你直接修改 Raft 日志,那 Raft 也会无法工作…
- 时钟跳跃:通过「恰当的运维」,保证机器时钟不会大幅度跳跃(每次通过微小的调整来完成),实际上这是可以做到的
这里有一个重点,为什么 Redis 作者优先解释时钟问题?因为在后面的反驳过程中,需要依赖这个基础做进一步解释。
2) 解释网络延迟、GC 问题
之后,Redis 作者对于对方提出的,网络延迟、进程 GC 可能导致 Redlock 失效的问题,也做了反驳:认为对方的假设其实是有问题的,Redlock 是可以保证锁安全的。
基于Redlock流程的那5步,
- 客户端先获取「当前时间戳T1」
- 客户端依次向这 5 个 Redis 实例发起加锁请求(用前面讲到的 SET 命令),且每个请求会设置超时时间(毫秒级,要远小于锁的有效时间),如果某一个实例加锁失败(包括网络超时、锁被其它人持有等各种异常情况),就立即向下一个 Redis 实例申请加锁
- 如果客户端从 3 个(大多数)以上 Redis 实例加锁成功,则再次获取「当前时间戳T2」,如果 T2 - T1 < 锁的过期时间,此时,认为客户端加锁成功,否则认为加锁失败
- 加锁成功,去操作共享资源(例如修改 MySQL 某一行,或发起一个 API 请求)
- 加锁失败,向「全部节点」发起释放锁请求(前面讲到的 Lua 脚本释放锁)
Redis 作者强调:如果在 1-3 发生了网络延迟、进程 GC 等耗时长的异常情况,那在第 3 步 T2 - T1,是可以检测出来的,如果超出了锁设置的过期时间,那这时就认为加锁会失败,之后释放所有节点的锁就好了!
Redis 作者继续论述,如果对方认为,发生网络延迟、进程 GC 是在步骤 3 之后,也就是客户端确认拿到了锁,去操作共享资源的途中发生了问题,导致锁失效,那这不止是 Redlock 的问题,任何其它锁服务例如 Zookeeper,都有类似的问题,这不在讨论范畴内。
妈的,岂不是说,所有系统NPC目前压根没有避免的办法???!!!
3) 质疑 fencing token 机制
Redis 作者对于对方提出的 fencing token 机制,也提出了质疑,主要分为 2 个问题。
-
第一,这个方案必须要求要操作的「共享资源服务器」有拒绝「旧 token」的能力。 例如,要操作 MySQL,从锁服务拿到一个递增数字的 token,然后客户端要带着这个 token 去改 MySQL 的某一行,这就需要利用 MySQL 的「事物隔离性」来做。
// 两个客户端必须利用事物和隔离性达到目的 // 注意 token 的判断条件 UPDATE table T SET val = $new_val, current_token = $token WHERE id = $id AND current_token < $token但如果操作的不是 MySQL 呢?例如向磁盘上写一个文件,或发起一个 HTTP 请求,那这个方案就无能为力了,这对要操作的资源服务器,提出了更高的要求。 也就是说,大部分要操作的资源服务器,都是没有这种互斥能力的。
再者,既然资源服务器都有了「互斥」能力,那还要分布式锁干什么?
-
第二,退一步讲,即使 Redlock 没有提供 fencing token 的能力,但 Redlock 已经提供了随机值(就是前面讲的 UUID),利用这个随机值,也可以达到与 fencing token 同样的效果。
Redis 作者只是提到了可以完成 fencing token 类似的功能,但却没有展开相关细节,根据我查阅的资料,大概流程应该如下,如有错误,欢迎交流~
- 客户端使用 Redlock 拿到锁
- 客户端在操作共享资源之前,先把这个锁的 VALUE,在要操作的共享资源上做标记
- 客户端处理业务逻辑,最后,在修改共享资源时,判断这个标记是否与之前一样,一样才修改(类似 CAS 的思路)
还是以 MySQL 为例,举个例子就是这样的:
- 客户端使用 Redlock 拿到锁
- 客户端要修改 MySQL 表中的某一行数据之前,先把锁的 VALUE 更新到这一行的某个字段中(这里假设为 current_token 字段)
- 客户端处理业务逻辑
- 客户端修改 MySQL 的这一行数据,把 VALUE 当做 WHERE 条件,再修改
- UPDATE table T SET val = $new_val WHERE id = $id AND current_token = $redlock_value
这种方案依赖 MySQL 的事务机制,也达到对方提到的 fencing token 一样的效果。
但这里还有个小问题,是网友参与问题讨论时提出的:两个客户端通过这种方案,先「标记」再「检查+修改」共享资源,那这两个客户端的操作顺序无法保证啊?
而用 Martin 提到的 fencing token,因为这个 token 是单调递增的数字,资源服务器可以拒绝小的 token 请求,保证了操作的「顺序性」!
Redis 作者对于这个问题做了不同的解释,我觉得很有道理,他解释道:分布式锁的本质,是为了「互斥」,只要能保证两个客户端在并发时,一个成功,一个失败就好了,不需要关心「顺序性」。
前面 Martin 的质疑中,一直很关心这个顺序性问题,但 Redis 的作者的看法却不同。我觉得顺序性在分布式锁中并不重要,其目的是控制并发保证串行,但在分布式系统中很重要,尤其和mysql交互,顺序很重要,滞后的操作往往会导致数据的混乱。
综上,Redis作者的结论
- 1、作者同意对方关于「时钟跳跃」对 Redlock 的影响,但认为时钟跳跃是可以避免的,取决于基础设施和运维。
- 2、Redlock 在设计时,充分考虑了 NPC 问题,在 Redlock 步骤 3 之前出现 NPC,可以保证锁的正确性,但在步骤 3 之后发生 NPC,不止是 Redlock 有问题,其它分布式锁服务同样也有问题,所以不在讨论范畴内。
3.5.3. Zookeeper实现
Zookeeper实现分布式锁的大概流程如下:
- 客户端 1 和 2 都尝试创建「临时节点」,例如 /lock
- 假设客户端 1 先到达,则加锁成功,客户端 2 加锁失败
- 客户端 1 操作共享资源
- 客户端 1 删除 /lock 节点,释放锁
Zookeeper 不像 Redis 那样,需要考虑锁的过期时间问题,它是采用了「临时节点」,保证客户端 1 拿到锁后,只要连接不断,就可以一直持有锁。
而且,如果客户端 1 异常崩溃了,那么这个临时节点会自动删除,保证了锁一定会被释放。不错,没有锁过期的烦恼,还能在异常时自动释放锁,是不是觉得很完美?
其实不然,依旧没有避免NPC的问题。
客户端 1 创建临时节点后,Zookeeper 是如何保证让这个客户端一直持有锁呢? 原因就在于,客户端 1 此时会与 Zookeeper 服务器维护一个 Session,这个 Session 会依赖客户端「定时心跳」来维持连接。 如果 Zookeeper 长时间收不到客户端的心跳,就认为这个 Session 过期了,也会把这个临时节点删除。
同样地,基于此问题,我们也讨论一下 GC 问题对 Zookeeper 的锁有何影响:
- 客户端 1 创建临时节点 /lock 成功,拿到了锁
- 客户端 1 发生长时间 GC
- 客户端 1 无法给 Zookeeper 发送心跳,Zookeeper 把临时节点「删除」
- 客户端 2 创建临时节点 /lock 成功,拿到了锁
- 客户端 1 GC 结束,它仍然认为自己持有锁(冲突)
可见,即使是使用 Zookeeper,也无法保证进程 GC、网络延迟异常场景下的安全性。这也是目前分布式锁的通病。
Zookeeper 的优点:
- 不需要考虑锁的过期时间
- watch 机制,加锁失败,可以 watch 等待锁释放,实现乐观锁
Zookeeper的劣势:
- 性能不如Redis
- 部署和运维成本高
- 客户端与 Zookeeper 的长时间失联,锁被释放问题
3.5.4. 分布式锁总结
1) 到底要不要用 Redlock?
前面也分析了,Redlock 只有建立在「时钟正确」的前提下,才能正常工作,如果你可以保证这个前提,那么可以拿来使用。 但保证时钟正确,我认为并不是你想的那么简单就能做到的。 第一,从硬件角度来说,时钟发生偏移是时有发生,无法避免的。 例如,CPU 温度、机器负载、芯片材料都是有可能导致时钟发生偏移。 第二,从我的工作经历来说,曾经就遇到过时钟错误、运维暴力修改时钟的情况发生,进而影响了系统的正确性,所以,人为错误也是很难完全避免的。 所以,我对 Redlock 的个人看法是,尽量不用它,而且它的性能不如单机版 Redis,部署成本也高,我还是会优先考虑使用 Redis「主从+哨兵」的模式,实现分布式锁。
2) 如何正确使用分布式锁?
在分析 Martin 观点时,它提到了 fencing token 的方案,给我了很大的启发,虽然这种方案有很大的局限性,但对于保证「正确性」的场景,是一个非常好的思路。 所以,我们可以把这两者结合起来用:
1、使用分布式锁,在上层完成「互斥」目的,虽然极端情况下锁会失效,但它可以最大程度把并发请求阻挡在最上层,减轻操作资源层的压力。
2、但对于要求数据绝对正确的业务,在资源层一定要做好「兜底」,设计思路可以借鉴 fencing token 的方案来做。
两种思路结合,我认为对于大多数业务场景,已经可以满足要求了。
看了这么多,是不是发现如何实现,都不能保证 100% 的稳定。程序就是这样,基于NPC之下,没有绝对的稳定,所以做好人工补偿环节也是重要的一环,毕竟:技术不够,人工来凑!
以下为目前主流实现分布式锁的一张思维导图,共勉!
4. 跋
- 1、在分布式系统环境下,看似完美的设计方案,可能并不是那么「严丝合缝」,如果稍加推敲,就会发现各种问题。所以,在思考分布式系统问题时,一定要谨慎再谨慎。
- 2、从 Redlock 的争辩中,我们不要过多关注对错,而是要多学习大神的思考方式,以及对一个问题严格审查的严谨精神。
很喜欢Martin在对于Redlock争论过后写下的感悟: “前人已经为我们创造出了许多伟大的成果:站在巨人的肩膀上,我们可以才得以构建更好的软件。无论如何,通过争论和检查它们是否经得起别人的详细审查,这是学习过程的一部分。但目标应该是获取知识,而不是为了说服别人,让别人相信你是对的。有时候,那只是意味着停下来,好好地想一想。”
还有我自己的日常感悟:对于一个技术点,知道怎么做远远不够,还要知道为什么这么做!理解之后不断尝试把这些思考过程,提炼成通用的方法论,让你可以应用在其它领域中,做到举一反三。
参考:https://www.zhihu.com/question/300767410/answer/1931519430?utm_source=wechat_session&utm_medium=social&utm_oi=822391742442655744&utm_content=group2_Answer&utm_campaign=shareopn

















 507
507











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











